 夜雨聆风
夜雨聆风人工智能训练师-职业技能等级证书考试学习

什么是AI模型训练?
训练人工智能模型,是教计算机系统从实例中学习,而非给它一系列规则让其遵循。我们不采用给与其固定模式的方式,而是通过展示大量数据,让它自行发现模式。
这一过程的核心包含三个协同工作的关键部分:数据集、算法和训练过程。数据集是模型研究的信息,算法是帮助它从数据中学习的方法,训练过程则是它不断练习、进行预测、找出错误并持续改进的过程。
训练中,训练数据和验证数据的使用至关重要。训练数据帮助模型学习模式,而验证数据(数据集的独立部分)用于测试模型的学习效果。验证能确保模型不只是记住示例,还能对未见过的新数据做出可靠预测。
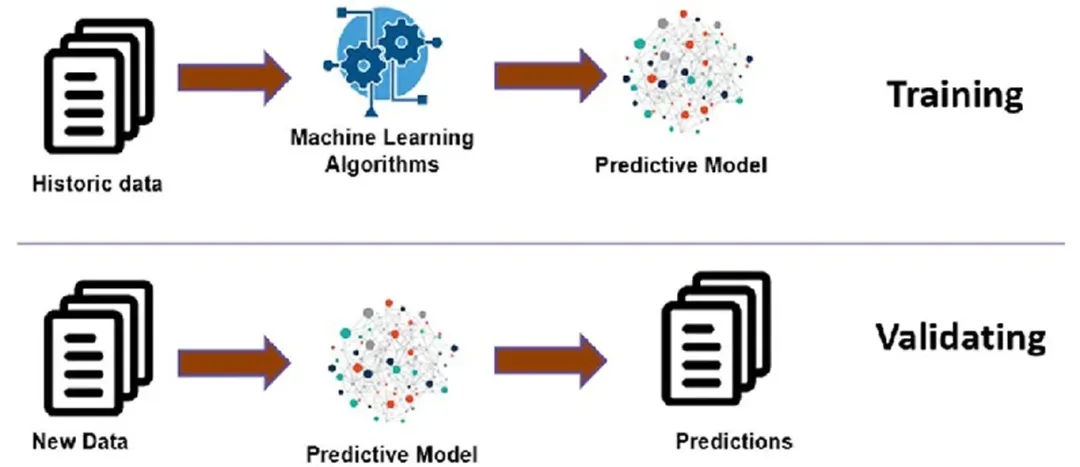
图 1. 训练数据和验证数据是开发人工智能模型的关键组成部分。
例如,一个训练有素的房价模型,可能会利用位置、面积、房间数量和社区趋势等细节预测房产价值。该模型研究历史数据、识别模式,进而了解这些因素对价格的影响。
同样,计算机视觉模型可能需要在数千张标注图像上训练,以区分猫和狗。每张图像都能让模型识别出猫和狗的形状、纹理及特征,如耳朵、毛皮图案或尾巴。在这两种情况下,模型都是通过分析训练数据、在未见过的示例上验证性能、随时间完善预测来学习的。
如何训练AI模型?
让我们深入了解模型训练的具体过程。
当训练有素的人工智能模型用于预测时,它会接收新数据(如一张图片、一句话或一组数字),然后基于已学知识输出结果。这就是所谓的推理,简单来说,就是模型运用训练中学到的知识,对新信息做出决策或预测。
然而,模型要有效执行推理,首先需经过训练。训练是模型从示例中学习,从而能识别模式并在日后做出准确预测的过程。
训练过程中,我们向模型输入带标签的示例,比如一张标注为“猫”的猫的图像。模型处理输入后生成预测,随后将其输出与正确标签对比,并通过损失函数计算两者的差值。损失值代表模型的预测误差,即输出与预期结果的偏差程度。
为减少这种误差,模型需依靠优化器,如随机梯度下降(SGD)或亚当。优化器会朝着最小化损失的方向,调整模型的内部参数(称为权重)。这些权重决定了模型对数据中不同特征的响应程度。
这一过程包括预测、计算损失、更新权重,并不断重复,需要多次迭代和多个周期。每个循环中,模型都会加深对数据的理解,逐渐降低预测误差。若训练有效,损失最终会趋于稳定,这通常表明模型已掌握训练数据中的主要模式。
训练AI模型的具体步骤
训练人工智能模型起初看似复杂,但将其拆分为简单步骤后,整个过程会更容易理解。每个阶段都以前一阶段为基础,助力你从想法转化为可行的解决方案。
接下来,我们将探讨初学者需关注的关键步骤:定义用例、收集和准备数据、选择模型和算法、设置环境、训练、验证和测试,以及最后的部署和迭代。
第 1 步:定义用例
训练人工智能模型的第一步,是明确你希望人工智能解决方案解决的问题。没有清晰的目标,训练过程容易偏离重点,模型也可能无法得出有意义的结果。用例指的是你希望模型进行预测或分类的具体场景。
例如,计算机视觉是人工智能的一个分支,能让机器解读和理解视觉信息,其应用广泛,如识别货架上的产品、监控道路交通或检测制造过程中的缺陷。
同样,在金融和供应链管理领域,预测模型有助于预测趋势、需求或未来业绩。此外,在自然语言处理(NLP)领域,文本分类能让系统对电子邮件进行分类、分析客户反馈或检测评论中的情感。
总体而言,有了明确目标,选择合适的数据集、学习方法和最佳模型会容易得多。
步骤 2:收集和准备训练数据
确定用例后,下一步是收集数据。训练数据是每个人工智能模型的基础,其质量直接影响模型性能。必须牢记,数据是模型训练的根基,人工智能系统的优劣取决于它所学习的数据。数据中的偏差或漏洞,难免会影响其预测结果。
你收集的数据类型取决于具体用例。例如,医学图像分析需要高分辨率扫描,而情感分析则使用评论或社交媒体中的文本。这些数据可来自研究社区共享的开放数据集、公司内部数据库,也可通过不同收集方法(如抓取或传感器数据)获取。
收集数据后,需对其进行预处理,包括清理错误、规范格式和标注信息,以便算法从中学习。数据清理或预处理能确保数据集的准确性和可靠性。
步骤 3:选择合适的模型或算法类型
数据准备就绪后,下一步是选择合适的模型和学习方法。机器学习方法大致分为三类:监督学习、无监督学习和强化学习。
监督学习中,模型从标记数据中学习,适用于价格预测、图像识别或电子邮件分类等任务。与之相反,无监督学习使用无标签数据寻找隐藏模式或分组,如对客户进行聚类或发现趋势。强化学习通过反馈和奖励训练智能体,常用于机器人、游戏和自动化领域。
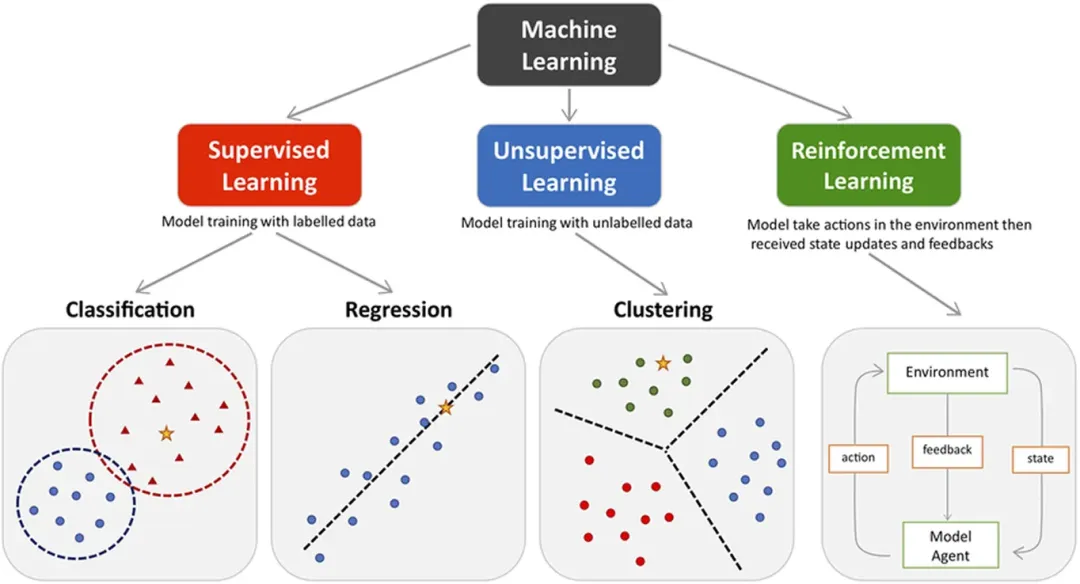
图 2. 机器学习算法的类型
实际上,这一步与数据收集密切相关,因为模型的选择往往取决于现有数据,而收集的数据通常也由模型的要求决定。
这就像典型的“先有鸡还是先有蛋”的问题,孰先孰后取决于具体应用。有时,你已拥有数据,希望找到最佳利用方式;有时,你需要解决某个问题,需收集或创建新数据来有效训练模型。
在此,我们假设你已有数据集,并希望为监督学习选择最合适的模型。如果数据由数字组成,你可能会训练回归模型来预测价格、销售额或趋势等结果。
同样,若处理图像,可使用Ultralytics YOLO11或Ultralytics YOLO26等计算机视觉模型,它们支持实例分割和对象检测等任务。
另一方面,当数据为文本时,语言模型可能是最佳选择。那么,如何决定使用哪种学习方法或算法呢?这取决于多个因素,包括数据集的大小和质量、任务的复杂程度、可用的计算资源以及所需的准确度。
步骤 4:配置训练环境
设置合适的环境是训练人工智能模型前的重要一步,正确的设置有助于确保实验顺利高效地进行。
以下是需要考虑的主要方面:
计算资源:小型项目通常可在标准笔记本电脑上运行,但大型项目往往需要 GPU 或专为机器学习和人工智能设计的云平台。云服务还能轻松扩展或缩减资源规模,通常包含仪表盘,用于实时监控实验和结果。
编程语言和框架:Python 是人工智能开发中最常用的语言,拥有庞大的社区和丰富的库与框架生态系统,如 TensorFlow、PyTorch 和Ultralytics。这些工具简化了实验、模型构建和训练过程,让开发人员能专注于提高性能,而非从头编写所有代码。
开发工具:Google Colab、Jupyter Notebooks 和 VS Code 等平台便于以交互方式编写和测试代码,还支持云端集成,以实现更大规模的工作流程。
步骤 5:训练AI模型
环境准备就绪后,即可开始训练。此阶段,模型通过识别数据集中的模式进行学习,并随时间不断改进。
训练包括反复向模型展示数据并调整其内部参数,直至预测变得更为准确。对数据集的每一次完整遍历称为一个周期。
要提高性能,可采用超参数调整等优化技术。调整学习率、批量大小或周期次数等设置,能显著改善模型的学习效果。
在整个训练过程中,通过性能指标监控进展至关重要。准确率、精确度、召回率和损失率等指标,能表明模型是在改进还是需要调整。大多数机器学习和人工智能库都包含仪表盘和可视化工具,便于实时跟踪这些指标,及早发现潜在问题。
步骤 6:验证和测试AI模型
模型训练完成后,需对其进行评估和验证。这包括在未见过的数据上测试,检查它能否应对真实世界的场景。你可能会好奇这些新数据的来源。
多数情况下,数据集在训练前会分为三部分:训练集、验证集和测试集。训练集用于教模型识别数据中的模式;验证集在训练过程中用于微调参数,防止过拟合(即模型过于依赖训练数据,在新的未见过数据上表现不佳);测试集则用于衡量模型在完全未见过数据上的表现。若模型在验证集和测试集上的表现始终良好,就充分说明它已掌握有意义的模式,而非仅仅记住了示例。
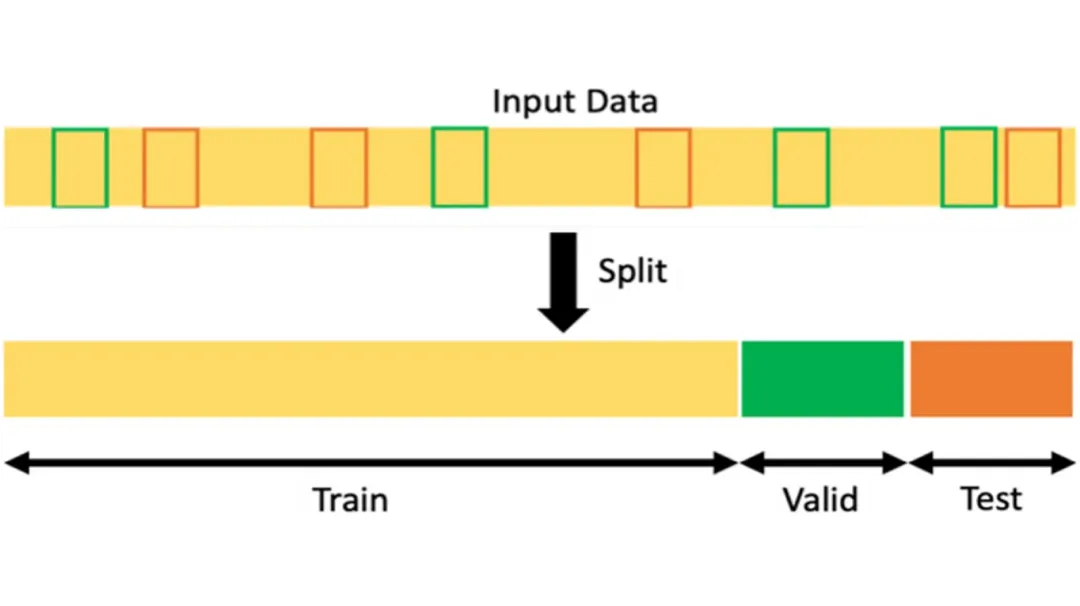
图 3. 将数据集拆分为训练数据、验证数据和测试数据。
步骤 7:部署和维护AI模型
模型经过验证和测试后,就可部署到现实世界中实际使用。简单来说,就是将模型投入应用,使其能在现实场景中进行预测。例如,训练好的模型可集成到网站、应用程序或机器中,处理新数据并自动给出结果。
根据不同应用,部署模型的方式也有所不同。有些模型通过应用程序接口共享,这是一种简单的软件连接,允许其他应用程序获取模型的预测结果;有些模型托管在云平台上,便于扩展和在线管理;还有些模型在摄像头或传感器等边缘设备上运行,可在本地进行预测,无需依赖互联网连接。最佳部署方法取决于用例和可用资源。
定期监控和更新模型也很关键。随着时间推移,新数据或不断变化的条件会影响模型性能。持续评估、重新训练和优化,能确保模型在实际应用中保持准确、可靠和有效。
模型训练的相关原则
训练人工智能模型涉及多个步骤,遵循一些原则能让过程更顺利,结果更可靠。以下是几种有助于建立更好、更准确模型的关键做法。
首先,使用平衡的数据集,以公平代表所有类别或等级。若某一类别比其他类别出现更频繁,模型会产生偏差,难以做出准确预测。
其次,利用超参数调整等技术,如调整学习率或批量大小等设置来提高准确性。即使是微小的变化,也可能对模型的学习效率产生重大影响。
在整个训练过程中,监控关键性能指标,如精确度、召回率和损失。这些数值能帮助你判断模型是在学习有意义的模式,还是仅在记忆数据。
最后,务必养成记录工作流程的习惯。记录使用的数据、进行的实验和取得的结果。清晰的文档能让你更易复现成功结果,并随时间完善训练流程。
训练不同领域的AI模型
人工智能是一项在不同行业和应用中被广泛采用的技术。从文本、图像到声音和基于时间的数据,使用数据、算法和迭代学习的核心原则适用于各个领域。
以下是训练和使用人工智能模型的一些关键领域:
自然语言处理:模型从文本数据中学习,以理解和生成人类语言。例如,大型语言模型(LLM)(如 OpenAI 的 GPT 模型)用于客户支持聊天机器人、虚拟助手和内容生成工具,助力实现自动交流。
计算机视觉:像 YOLO11 和 YOLO26 这样的模型在有标记的图像上训练,用于图像分类、物体检测和分割等任务。它们广泛应用于医疗保健领域的医疗扫描分析、零售业的库存跟踪,以及自动驾驶汽车的行人和交通标志检测。
语音和音频处理:基于录音训练的模型,可用于转录语音、识别说话者并检测语气或情感。它们应用于 Siri 和 Alexa 等语音助手、呼叫中心分析以及自动字幕等无障碍工具。
预测和预测性分析:这些模型利用时间序列或历史数据预测未来趋势和结果。企业用它们预测销售额,气象学家用它们预测天气模式,供应链经理依靠它们预测产品需求。
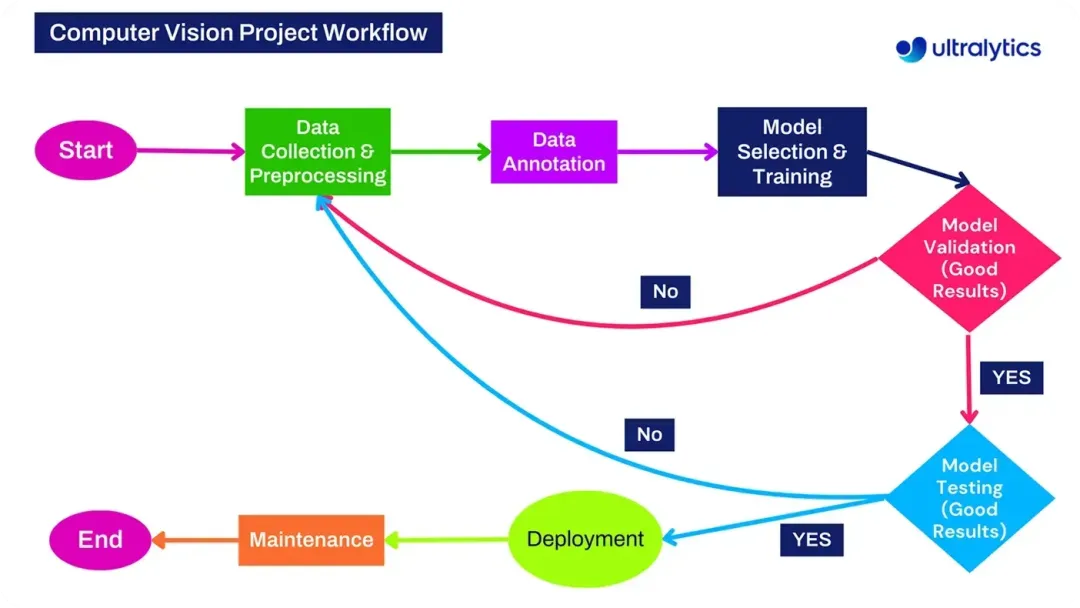
图 4. 计算机视觉项目工作流程概览
训练AI模型的相关挑战
尽管近年来技术不断进步,但人工智能模型的训练仍面临一些可能影响性能和可靠性的挑战。以下是建立和完善模型时需要注意的一些关键限制:
数据质量和数量:模型需要大量、多样且高质量的数据集才能有效学习。现实中,数据不足、存在偏差或标记不清,往往会导致预测不准确和泛化能力有限。
计算资源:训练现代人工智能模型,尤其是深度学习系统和大型语言模型,需要强大的计算能力。使用 GPU、TPU 或基于云的基础设施可能成本高昂,有时还难以有效扩展。
偏见和伦理考虑:若训练数据包含隐藏偏差,模型可能会无意中产生不公平或歧视性结果。确保数据集设计符合道德规范、定期进行偏差审计以及保证模型决策的透明度,对于降低这些风险至关重要。
持续优化:人工智能模型并非一成不变。它们需要定期根据新数据进行微调和更新,以保持准确性。若不进行持续的重新训练和监控,随着时间推移,数据模式或现实条件发生变化,模型性能也会随之下降。
训练AI模型的便捷工具
传统上,训练人工智能模型需要庞大的团队、强大的硬件和复杂的基础设施。但如今,先进的工具和平台已使这一过程更简单、快捷和方便。
这些解决方案降低了对高深技术专业知识的需求,让个人、学生和企业能轻松构建和部署定制模型。事实上,开始人工智能培训从未像现在这样简单。
例如,Ultralytics Python 软件包就是一个不错的起点。它为你提供了使用 Ultralytics YOLO 模型进行训练、验证和运行推理所需的一切,并能将其导出以部署到各种应用中。
其他流行工具,如 Roboflow、TensorFlow、Hugging Face 和 PyTorch Lightning,也简化了从数据准备到部署的人工智能训练工作流程的不同环节。有了这些平台,人工智能开发比以往任何时候都更易实现,让开发人员、企业甚至初学者都有能力进行实验和创新。
一、单项选择题
1. 在人工智能训练中,以下哪项属于结构化数据?( )
•A. 社交媒体文本
•B. 医学影像图片
•C. 关系型数据库表
•D. 语音录音文件
答案:C
解析:结构化数据是指具有固定格式或有限长度的数据,如
关系型数据库中的表格数据;非结构化数据(如文本、图像、
音频)无固定格式,需额外处理。
2. 解决模型过拟合问题时,以下哪种方法效果最差?
( )
•A. 增加L2正则化参数
•B. 减少神经网络层数
•C. 对训练数据进行数据增强
•D. 降低批量梯度下降的Batch Size
答案:D
解析:过拟合的核心原因是模型对训练数据过度学习。增加
正则化、简化模型(减少层数)、扩大数据量(数据增强)均
可缓解过拟合;而降低Batch Size主要影响训练稳定性,对
过拟合无直接抑制作用。
3. 以下哪项是自然语言处理(NLP)中常用的预训练模
型?( )
•A. ResNet
•B. YOLO
•C. BERT
•D. GAN
答案:C
解析:BERT(Bidirectional Encoder Representations
from Transformers)是NLP领域经典预训练模型;ResNet
(图像分类)、YOLO(目标检测)、GAN(生成对抗网络)均
属于计算机视觉或通用生成模型。
4. 标注图像中“交通信号灯”的具体颜色(红/黄/
绿)时,应选择的标注类型是?( )
•A. 边界框标注(Bounding Box)
•B. 关键点标注(Keypoint)
•C. 语义分割(Semantic Segmentation)
•D. 属性标注(Attribute Annotation)
答案:D
解析:属性标注用于描述对象的额外特征(如颜色、类别细
分类);边界框标注用于定位对象位置,关键点标注用于标记
关键坐标,语义分割用于像素级分类。
5. 评估分类模型性能时,“精确率(Precision)”的
计算公式是?( )
•A. 真阳性/(真阳性+假阳性)
•B. 真阳性/(真阳性+假阴性)
•C. 真阴性/(真阴性+假阳性)
•D. (真阳性+真阴性)/(总样本数)
答案:A
解析:精确率衡量“预测为正的样本中实际为正的比例”,
公式为TP/(TP+FP);召回率(Recall)为TP/(TP+FN),准确
率(Accuracy)为(TP+TN)/(TP+TN+FP+FN)。

6. 以下哪种数据预处理操作不属于“数据清洗”范
畴?( )
•A. 填充缺失的年龄值(用均值)
•B. 将“2023-10-01”转换为时间戳
•C. 纠正文本中的错别字(如“模形”改为“模型”)
•D. 剔除重复的用户交易记录
答案:B
解析:数据清洗主要处理缺失值、异常值、重复值、错误
值;格式转换(如时间格式转时间戳)属于数据标准化,是特
征工程的一部分。
7. 训练目标检测模型时,若输入图像尺寸为640×
640,输出特征图尺寸为40×40,其下采样倍数为?
( )
•A. 4倍
•B. 8倍
•C. 16倍
•D. 32倍
答案:C
解析:下采样倍数=输入尺寸/输出尺寸=640/40=16倍。
8. 以下哪项是强化学习(RL)的核心要素?( )
•A. 损失函数
•B. 奖励信号
•C. 预训练权重
•D. 数据标注
答案:B
解析:强化学习通过“智能体-环境”交互,基于奖励信号
(Reward)优化策略;损失函数是监督学习核心,预训练权重
是迁移学习要素,数据标注是监督学习基础。
9. 在对话系统训练中,“意图识别”的主要任务是?
( )
•A. 生成符合语境的回答
•B. 提取用户问题中的关键实体
•C. 判断用户请求的类别(如查询、投诉、预订)
•D. 纠正用户输入中的语法错误
答案:C
解析:意图识别(Intent Recognition)负责分类用户需求
类型(如“查询天气”“预订酒店”);实体提取(Entity
Extraction)负责提取关键信息(如“北京”“明天”),生
成回答是对话生成模块的任务。
10. 以下哪种场景最适合使用迁移学习?( )
•A. 训练一个全新领域的图像分类模型(无预训练权重)
•B. 用100万张猫的图片训练猫品种分类模型
•C. 基于ImageNet预训练模型微调医疗影像分类模型
•D. 用随机初始化的神经网络训练大规模语言模型
答案:C
解析:迁移学习通过复用预训练模型的通用特征(如
ImageNet训练的视觉特征),快速适配目标任务(如医疗影
像),尤其适用于目标任务数据量少的场景。
二、多项选择题
1. 以下属于计算机视觉(CV)任务的有?( )
•A. 情感分析
•B. 目标检测
•C. 图像风格迁移
•D. 机器翻译
答案:B、C
解析:目标检测(定位并分类图像中的对象)、图像风格迁
移(将图像风格转换为艺术风格)属于CV任务;情感分析、
机器翻译属于NLP任务。
2. 数据标注质量控制的常用方法包括?( )
•A. 人工交叉校验(不同标注员重复标注)
•B. 设定标注一致性阈值(如IoU≥0.7)
•C. 使用标注工具自动审核(如检查边界框是否闭合)
•D. 对标注员进行岗前培训
答案:A、B、C、D
解析:质量控制需从人员(培训)、流程(交叉校验)、工
具(自动审核)、标准(一致性阈值)多维度保障。
3. 以下哪些操作可能导致模型欠拟合?( )
•A. 模型复杂度过低(如用线性模型拟合非线性数据)
•B. 训练数据量远小于模型参数数量
•C. 正则化参数设置过大
•D. 训练轮次(Epoch)不足
答案:A、C、D
解析:欠拟合因模型无法捕捉数据规律,常见于模型过简
单、正则化过强(抑制模型表达)、训练不充分;数据量小可
能导致过拟合(模型记忆数据)。
4. 自然语言处理中的“词嵌入(Word Embedding)”
作用包括?( )
•A. 将文本转换为计算机可处理的向量
•B. 保留词语的语义信息(如“苹果”与“水果”语义相
关)
•C. 消除文本中的语法错误
•D. 减少文本数据的维度
答案:A、B、D
解析:词嵌入通过向量表示词语,保留语义关联(如相似词
向量距离近),并降低维度(如将One-Hot的高维稀疏向量转
为低维稠密向量);消除语法错误属于数据清洗或纠错模型任
务。
5. 以下关于“混淆矩阵(Confusion Matrix)”的描
述正确的有?( )
•A. 对角线元素表示正确分类的样本数
•B. 适用于多分类任务性能分析
•C. 可直接计算精确率、召回率等指标
•D. 仅能评估二分类模型
答案:A、B、C
解析:混淆矩阵通过TP、TN、FP、FN(二分类)或多分类的
对应值,直观展示分类结果;对角线为正确分类数(如类别A
预测为A的数量),支持多分类分析,并可推导精确率、召回
率等。
三、填空题
1. 数据标注中,为图像中的每个像素分配类别标签的
标注类型称为____。
答案:语义分割标注
2. 模型训练时,用于衡量预测值与真实值差异的函数
称为____。
答案:损失函数(或目标函数)
3. 自然语言处理中,将文本拆分为独立词语的过程称
为____。
答案:分词(或分词处理)
4. 计算机视觉中,常用____指标衡量目标检测边界框
与真实框的重叠程度。
答案:交并比(IoU,Intersection over Union)
5. 强化学习中,智能体(Agent)通过与____交互获取
奖励信号。
答案:环境(Environment)
6. 为解决长序列依赖问题,循环神经网络(RNN)的改
进模型是____。
答案:LSTM(长短期记忆网络)或GRU(门控循环单元)
7. 数据预处理中,将不同量纲的特征(如身高cm、体
重kg)转换为同一尺度的操作称为____。
答案:归一化(或标准化)
8. 标注文本情感倾向(如积极/消极/中性)的任务属
于____标注。
答案:情感分析(或情感倾向)
9. 模型评估时,将数据集划分为训练集、验证集和
____是常见做法。
答案:测试集
10. 生成对抗网络(GAN)由生成器(Generator)和
____两部分组成。
答案:判别器(Discriminator)
四、判断题
1. 数据增强仅适用于图像数据,文本和语音数据无法
进行增强。( )
答案:×
解析:文本可通过同义词替换、回译等增强,语音可通过添
加噪声、调整语速等增强。
2. 过拟合的模型在训练集和测试集上的准确率均较
高。( )
答案:×
解析:过拟合模型在训练集上准确率高,但测试集上因泛化
能力差,准确率显著低于训练集。
3. 标注工具的“自动标注”功能可完全替代人工标
注。( )
答案:×
解析:自动标注(如基于预训练模型的初步标注)需人工校
验修正,无法完全替代人工。
4. 分类模型的准确率(Accuracy)越高,模型性能一
定越好。( )
答案:×
解析:若数据类别不平衡(如99%为负类),仅提高负类预测
准确率即可达到高Accuracy,但可能忽略正类(关键类)的
预测效果。
5. 深度学习模型的参数量越大,性能一定越强。( )
答案:×
解析:模型性能受数据量、任务复杂度、参数量共同影响;
参数量过大可能导致过拟合或计算资源浪费。
6. 自然语言处理中的“命名实体识别(NER)”任务需
标注文本中的人名、地名、机构名等实体。( )
答案:√
解析:NER的核心是识别并分类文本中的特定实体(如“张
三”(人名)、“北京”(地名))。
7. 训练模型时,学习率(Learning Rate)设置越大,
模型收敛速度一定越快。( )
答案:×
解析:学习率过大会导致参数震荡,无法收敛;需通过学习
率衰减(如从0.1逐步降至0.001)平衡速度与稳定性。
8. 数据标注的一致性(Agreement)是指不同标注员对
同一数据的标注结果的相似程度。( )
答案:√
解析:一致性通常用Kappa系数、IoU等指标衡量,是评估标
注质量的关键。
9. 强化学习中的“策略(Policy)”是指智能体在特
定状态下选择动作的规则。( )
答案:√
解析:策略(π)定义为状态到动作的映射(π(a|s)),是
强化学习的核心优化目标。
10. 迁移学习只能在同模态数据间应用(如图像→图
像,文本→文本)。( )
答案:×
解析:跨模态迁移(如图像→文本,如生成图像描述)也是
迁移学习的应用场景。
五、简答题
1. 简述数据标注的主要流程。
•(1). 需求分析:明确标注目标(如分类、检测、分
割)、标注标准(如边界框精度、标签类别)。
•(2). 工具选择:根据数据类型(图像/文本/语音)选择
标注工具(如LabelMe、Label Studio)。
•(3). 标注培训:对标注员进行标准培训,确保理解标签
定义和操作规范。
•(4). 执行标注:标注员按标准完成数据标注,工具自动
保存标注结果(如JSON、XML文件)。
•(5). 质量校验:通过人工交叉检查、工具自动审核(如
检查标签完整性)筛选不合格数据。
•(6). 数据输出:清洗后的标注数据导出为模型可读取格
式(如COCO、VOC数据集格式)。
2. 列举3种常见的过拟合解决方法,并简要说明原
理。
•(1). 数据增强:通过对训练数据进行变换(如图像旋
转、翻转,文本同义词替换)增加数据多样性,避免模
型仅记忆原始数据。
•(2). 正则化:在损失函数中添加正则项(如L1/L2正
则),限制模型参数的大小,降低模型复杂度。
•(3). 早停(Early Stopping):在验证集性能不再提升
时停止训练,避免模型过度拟合训练数据。
3. 对比监督学习与无监督学习的核心区别。
•(1). 数据标签:监督学习需要带标签的训练数据(如
“猫”“狗”的图像标签),无监督学习使用无标签数
据(如仅图像无类别)。
•(2). 任务目标:监督学习目标是学习输入到标签的映射
(如分类、回归),无监督学习目标是发现数据内在结
构(如聚类、降维)。
•(3). 应用场景:监督学习适用于目标明确、标签易获取
的任务(如图像分类);无监督学习适用于探索数据模
式(如用户分群)。
4. 说明自然语言处理中“词袋模型(Bag-of-
Words)”的局限性。
•(1). 丢失顺序信息:仅统计词频,忽略词语在句子中的
顺序(如“猫追狗”与“狗追猫”被视为相同)。
•(2). 无法捕捉语义关联:无法表示词语间的语义相似性
(如“汽车”与“轿车”被视为不同特征)。
•(3). 高维稀疏性:词汇表庞大时,特征向量维度极高且
稀疏,增加计算复杂度。
5. 简述目标检测模型中“锚框(Anchor Box)”的作
用。
•(1). 适应多尺度目标:预定义不同长宽比(如1:1、
2:1、1:2)和大小的锚框,覆盖图像中不同尺寸的目
标。
•(2). 提升检测效率:通过锚框与真实框的IoU匹配,减
少模型需预测的边界框数量,降低计算量。
•(3). 优化训练目标:模型只需预测锚框的偏移量(而非
绝对坐标),简化回归任务,提高收敛速度。
六、论述题
1. 结合实际场景(如医疗影像诊断),论述数据标注
对人工智能模型性能的影响。
•(1). 标注准确性直接影响模型泛化能力:医疗影像(如
X光片)需精准标注病灶位置(如肿瘤边界),若标注偏
差大(如边界框遗漏部分病灶),模型会学习错误特
征,导致诊断漏检或误检。
•(2). 标注一致性决定模型稳定性:不同医生标注同一影
像时,若对“早期肿瘤”的定义不一致(如有的标注为
“阳性”,有的为“阴性”),模型训练时会接收矛盾
信号,无法收敛到稳定决策边界。
•(3). 标注覆盖度影响模型鲁棒性:若训练数据仅标注常
见病灶(如大肿瘤),未覆盖罕见病灶(如微小肿
瘤),模型在实际应用中遇到罕见病例时将无法正确识
别,导致性能下降。
•(4). 标注标准化推动模型落地:医疗领域需遵循国际标
准(如DICOM影像格式、SNOMED CT术语),统一标注规
范(如病灶大小用毫米标注),才能保证模型在不同医
院数据上的通用性,避免“数据孤岛”问题。
2. 论述深度学习模型训练中“批量大小(Batch
Size)”对训练过程的影响,并给出合理选择建议。
•(1). 对训练速度的影响:大Batch Size可充分利用GPU
并行计算,减少迭代次数(如Batch Size=1024比64更
快完成单轮训练),但可能因内存限制无法使用过大
值。
•(2). 对梯度稳定性的影响:小Batch Size的梯度估计
噪声大(因仅用少量样本计算梯度),可能导致训练震
荡,但有助于跳出局部最优;大Batch Size的梯度更平
滑,训练更稳定,但可能陷入尖锐极小值(泛化性
差)。
•(3). 对模型泛化的影响:研究表明,小Batch Size训
练的模型通常泛化性更好(因梯度噪声相当于正则
化);大Batch Size需配合学习率衰减(如线性缩放规
则)避免过拟合。
•(4). 合理选择建议:
o硬件限制:根据GPU显存调整(如12GB显存的
GPU,图像任务Batch Size通常设为16-32)。
o任务类型:小样本任务(如医疗影像)用小Batch
Size(8-16),大样本任务(如ImageNet)可用大
Batch Size(128-256)。
o结合学习率:大Batch Size需增大初始学习率(如
Batch Size×2,学习率×2),并在训练后期衰
减。
3. 结合对话系统开发,论述“意图识别”与“实体提
取”的关系及协同作用。
•(1). 关系定位:意图识别是“分类问题”(判断用户需
求类型),实体提取是“序列标注问题”(提取关键信
息),二者是对话系统的“理解层”核心模块,共同支
撑后续的“生成层”。
•(2). 协同作用示例:用户输入“帮我订明天去上海的高
铁票”。
o意图识别:确定意图为“预订高铁票”,触发预订
流程。
o实体提取:提取“时间”(明天)、“目的地”
(上海)、“交通类型”(高铁),这些实体作为
参数传递给下游模块(如调用票务接口)。
•(3). 相互依赖:意图识别需实体辅助(如“订”+“高
铁票”明确为预订意图),实体提取需意图引导(如意
图为“查询天气”时,重点提取“地点”“时间”实
体)。
•(4). 误差传递风险:若意图识别错误(如将“取消订
单”误判为“查询订单”),即使实体提取正确,后续
生成的响应也会偏离用户需求;同理,实体漏提(如遗
漏“明天”)会导致预订时间错误。
•(5). 优化策略:可采用联合建模(如用多任务学习同时
训练意图识别和实体提取),共享底层语义表示(如
BERT编码),提升二者的协同准确性。
4. 论述计算机视觉中“数据增强”的常用方法及选择
依据。
•(1). 常用方法:
o几何变换:旋转(±15°)、翻转(水平/垂直)、
缩放(0.8-1.2倍)、裁剪(随机位置裁剪),用
于增强模型对目标位置、角度的鲁棒性。
o颜色变换:调整亮度(±20%)、对比度(±
15%)、饱和度(±10%)、添加高斯噪声(σ
=0.01),模拟不同光照条件下的图像。
o高级增强:MixUp(将两张图像按比例融合,标签加
权)、CutOut(随机遮挡图像区域)、AutoAugment
(自动搜索最优增强策略),用于提升模型抗干扰
能力。
•(2). 选择依据:
o任务类型:目标检测需保留目标完整性(避免过度
裁剪),语义分割需同步变换图像与标签(如旋转
后分割掩码同步旋转)。
o数据特点:医学影像(如X光片)对亮度敏感,需
谨慎调整颜色;自然图像(如风景照)可采用更激
进的几何变换。
o模型容量:小模型(如MobileNet)需更多增强
(如翻转、缩放)弥补表达能力不足;大模型(如
ResNet-152)可适当减少增强(避免过平滑)。
o实际场景:若模型将部署在光线变化大的环境(如
户外监控),需重点增强亮度、对比度;若部署在
固定角度(如工业质检摄像头),可减少旋转类增
强。
5. 论述人工智能训练师在模型迭代优化中的核心职
责。
•(1). 数据质量把控:分析训练数据分布(如类别平衡、
异常值占比),设计标注方案(如增加小样本类别的标
注量),通过数据清洗(去重、填充缺失值)和增强
(如文本回译)提升数据质量。
•(2). 模型问题诊断:通过验证集指标(如精确率下
降)、混淆矩阵(某类别误分率高)、可视化(如特征
图激活情况)定位问题(如过拟合、数据偏差)。
•(3). 优化策略制定:
o若过拟合:调整正则化参数、增加数据增强、简化
模型结构(如减少卷积层)。
o若欠拟合:增加模型复杂度(如添加全连接层)、
降低正则化强度、延长训练轮次。
o若数据偏差:收集更多缺失类别的数据、调整样本
权重(如对小样本类别加权损失)。
•(4). 协同开发支持:与算法工程师协作(如反馈标注需
求)、与产品经理沟通(如明确模型落地场景的核心指
标)、与测试人员配合(如设计边界测试用例)。
•(5). 效果持续跟踪:上线后监控模型性能(如线上准确
率、延迟),分析用户反馈(如误识别案例),驱动新
一轮数据标注和模型迭代(如针对高频误例补充标注数
据)。

