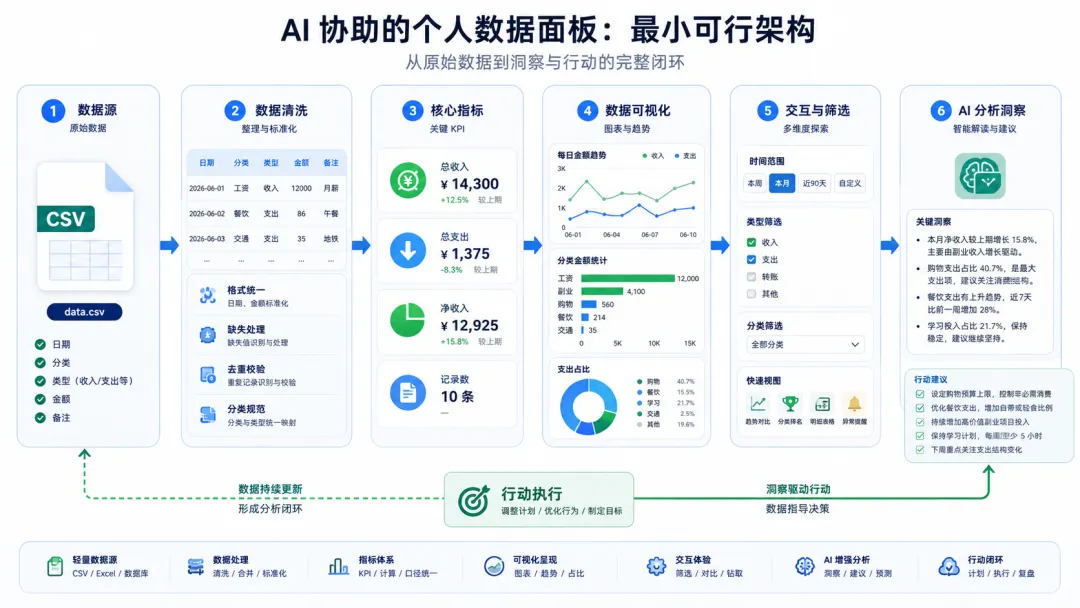
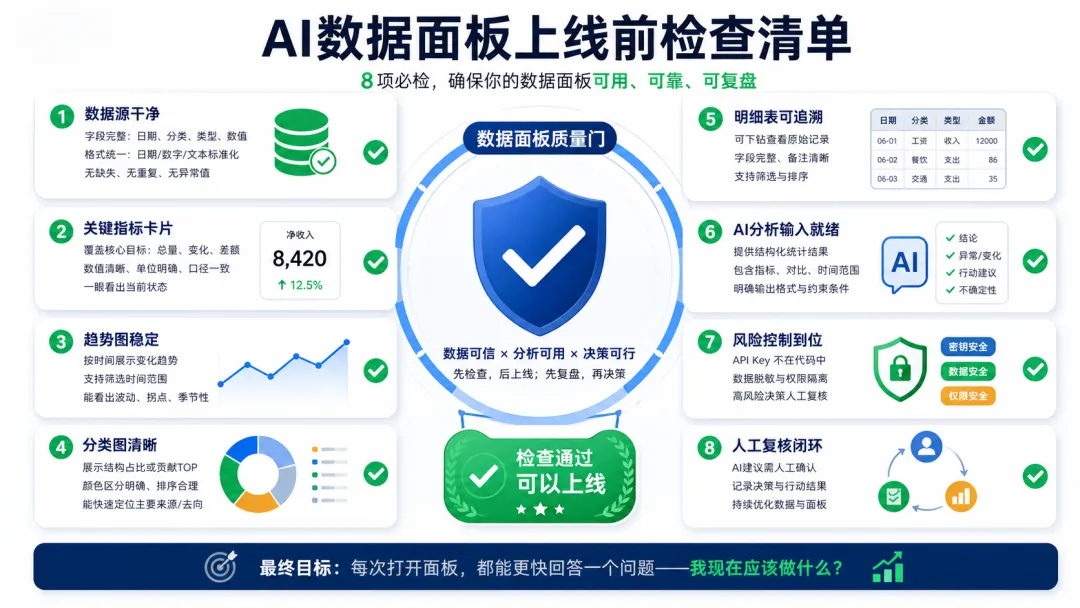
AI数据面板真正的价值不是多画几张图,而是把个人数据变成可筛选、可解释、可行动的闭环。本文用 Streamlit、pandas、Plotly 和 AI 提示词,带你从一个 CSV 搭出个人数据驾驶舱。第六步:可选接入 AI API,但先别跳过人工复核很多人不是没有数据,而是数据一直躺在 Excel、记账软件、销售导出表、学习打卡表和项目清单里。你每个月可能都会打开一次表格,手工看收入、支出、订单、阅读量、客户跟进、学习时间。但看完以后,真正能带走的结论很少:哪里异常?哪里变好?下周先改什么?哪些指标值得继续追?这就是 AI数据面板 值得普通人动手搭建的原因。它的核心不是把图表做得更花,而是让数据从“存档”变成“判断”,再变成下一步行动。本文给你一套最小可行路线:只用 1 个 CSV、1 个 Python 文件,先搭出能运行的个人数据驾驶舱。它能显示关键指标、趋势图、分类统计、数据明细,还会自动生成一段结构化 AI 分析提示词。等这个闭环跑通,再接入数据库、模型 API、自动日报和权限管理。一个个人数据面板最怕变成“什么都想放”的信息墙。看起来很高级,实际每次打开都不知道该看哪里。正确做法是先选 3 个问题,让所有指标、图表和 AI 分析都围绕它们展开。先把问题写清楚,后面字段设计就不会跑偏。本文用一个“个人收支 + 学习投入”的混合数据表做例子,因为它足够简单,也能迁移到销售、运营、健身和项目管理。ai-data-dashboard ├─ app.py └─ data.csv
然后在 data.csv 里写入下面这份样例数据:date,category,type,amount,remark 2026-06-01,工资,收入,12000,月薪 2026-06-02,餐饮,支出,86,午餐 2026-06-03,交通,支出,35,地铁和打车 2026-06-04,副业,收入,1800,咨询服务 2026-06-05,购物,支出,560,电子产品 2026-06-06,学习,支出,299,线上课程 2026-06-07,餐饮,支出,128,朋友聚餐 2026-06-08,副业,收入,2300,数据整理项目 2026-06-09,健康,支出,199,健身月卡 2026-06-10,工具,支出,68,软件订阅
这个表可以替换成你的真实数据。销售数据可以把 amount 改成订单金额,公众号数据可以改成阅读量,学习数据可以改成小时数。关键是:日期、分类、类型、数值这四类信息要稳定。打开命令行,进入 ai-data-dashboard 文件夹,安装三个组件:pip install streamlit pandas plotly
streamlit:把 Python 脚本变成可交互网页。这里不要急着接 AI。先把本地网页跑起来,才知道数据字段、图表和筛选逻辑有没有问题。很多面板失败,不是 AI 不会分析,而是前面的数据结构太乱。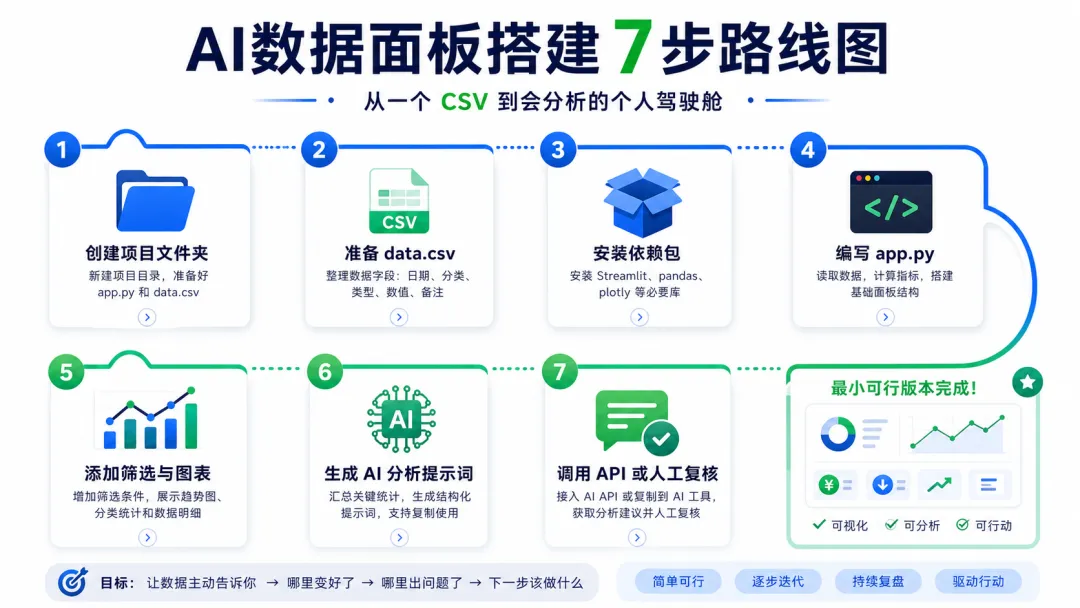
import pandas as pd import plotly.express as px import streamlit as st st.set_page_config(page_title="个人 AI 数据驾驶舱", layout="wide") st.title("个人 AI 数据驾驶舱") st.caption("用一个 CSV 跑通指标、图表、筛选和 AI 分析提示词。") df = pd.read_csv("data.csv") df["date"] = pd.to_datetime(df["date"]) st.sidebar.header("筛选条件") type_options = df["type"].unique().tolist() selected_types = st.sidebar.multiselect( "选择类型", options=type_options, default=type_options, ) category_options = df["category"].unique().tolist() selected_categories = st.sidebar.multiselect( "选择分类", options=category_options, default=category_options, ) filtered = df[ df["type"].isin(selected_types) & df["category"].isin(selected_categories) ].copy() income = filtered.loc[filtered["type"] == "收入", "amount"].sum() expense = filtered.loc[filtered["type"] == "支出", "amount"].sum() balance = income - expense record_count = len(filtered) col1, col2, col3, col4 = st.columns(4) col1.metric("总收入", f"¥{income:,.0f}") col2.metric("总支出", f"¥{expense:,.0f}") col3.metric("净收入", f"¥{balance:,.0f}") col4.metric("记录数", record_count) st.divider() daily = ( filtered.groupby(["date", "type"], as_index=False)["amount"] .sum() .sort_values("date") ) fig_trend = px.line( daily, x="date", y="amount", color="type", markers=True, title="每日金额趋势", ) st.plotly_chart(fig_trend, use_container_width=True) category_sum = ( filtered.groupby("category", as_index=False)["amount"] .sum() .sort_values("amount", ascending=False) ) fig_bar = px.bar( category_sum, x="category", y="amount", text_auto=True, title="分类金额统计", ) st.plotly_chart(fig_bar, use_container_width=True) st.subheader("数据明细") st.dataframe(filtered, use_container_width=True)
浏览器打开后,你会看到 4 个指标卡、1 张趋势图、1 张分类柱状图和 1 张明细表。左侧还能筛选类型和分类。这一步只要能跑通,就已经完成了 60%。因为你已经把数据从静态表格变成了可交互面板。进入 ai-data-dashboard 后再运行到这里,面板只是“会展示”。要让它“会分析”,最稳的方式不是直接让 AI 读整张表,而是先由程序汇总关键统计,再把统计结果喂给 AI。st.subheader("AI 分析提示词") summary_prompt = f""" 你是我的个人数据分析助手。请基于以下数据统计结果,给出简洁、具体、可执行的分析。 基础指标: - 总收入:{income} - 总支出:{expense} - 净收入:{balance} - 记录数量:{record_count} 分类统计: {category_sum.to_string(index=False)} 请按下面格式输出: 1. 三句话总结当前数据状态 2. 找出最值得关注的一个异常或变化 3. 给出下周最应该做的 3 个动作 4. 标出还需要补充哪些数据,才能让判断更准确 要求: - 不要泛泛而谈 - 每个建议都要对应一个数据现象 - 如果数据不足,请明确说明不确定性 """ st.code(summary_prompt, language="text") st.info("复制上方提示词到 AI 工具里,就能得到结构化分析建议。")
很多人用 AI 分析数据时,会直接问:“帮我看看这张表。” 这种问法得到的通常是空话。更好的方式是给 AI 固定输入:角色、指标、时间范围、对比对象、输出格式和不确定性约束。你可以先不接任何 API,直接复制提示词到 ChatGPT 或其他 AI 工具里。这样更安全,也更容易检查 AI 有没有胡说。等你确认提示词稳定,再考虑自动接入。第六步:可选接入 AI API,但先别跳过人工复核如果你希望面板里直接显示 AI 分析,可以接入模型 API。思路是:程序把 summary_prompt 发给模型,模型返回分析文本,再在面板里展示。import os from openai import OpenAI client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY")) def get_ai_summary(prompt: str) -> str: response = client.responses.create( model="gpt-4.1-mini", input=prompt, ) return response.output_text if st.button("生成 AI 分析"): with st.spinner("AI 正在分析数据..."): ai_summary = get_ai_summary(summary_prompt) st.markdown(ai_summary)
第一,不要把 API Key 写进代码。把它放在系统环境变量里,或者用 Streamlit 的 secrets 管理方式。代码可以公开,密钥不能公开。第二,AI 分析结果不能直接替代决策。尤其是财务、投资、医疗、法律、合同和客户数据场景,AI 只能给你分析草稿,最后一定要人工复核。第三,先控制成本。按钮触发比自动刷新安全。否则每次筛选、每次页面重载都可能调用一次模型,账单会悄悄上涨。如果你是第一次搭,建议先做到 1 级。能稳定跑 2 周,再接 API。你只需要换掉 data.csv 和少量字段,就可以变成不同类型的面板。目标完成率:比如预算 5000 元、收入目标 20000 元、学习目标 40 小时。异常提醒:单笔支出超过阈值,或者某个分类环比增长过快。数据上传:用 st.file_uploader 让用户上传自己的 CSV。自动报告:每周生成一份总结,保存成 Markdown 或发送到邮箱。但不要一上来就做所有功能。先用固定 CSV 跑通,再做上传;先人工复制 AI 提示词,再接 API;先自己用 2 周,再考虑给团队用。高级面板不是功能越多越好,而是每次打开都能更快回答一个问题:我现在应该做什么?先不要追求“企业级数据中台”。先做一个你自己真的会打开、会更新、会用来复盘的小面板。当 data.csv 能稳定更新,app.py 能稳定运行,AI 提示词能稳定给出有用建议,你就已经拥有了一个个人数据分析系统的雏形。从今天开始,不要只是保存数据。让数据主动告诉你:哪里变好了,哪里出问题了,下一步该做什么。本文实现思路参考了 Streamlit、pandas、Plotly 和 OpenAI 官方文档。实际使用时,请以你本地安装版本和具体数据安全要求为准。AI数据面板真正值得讨论的,不是图表好不好看,而是你愿不愿意把日常数据交给一个固定流程持续复盘。你最想先把哪类个人数据做成 AI数据面板:收支、销售、学习、健身还是项目?你会先接受 AI 生成分析建议,还是希望它直接改预算、排计划、发报告?下一篇要不要继续拆“如何把公众号、小红书或销售数据接进这个面板”?留言里如果有具体数据场景,我会继续把模板扩展成可直接复用的行业版本。 夜雨聆风
夜雨聆风