 夜雨聆风
夜雨聆风不只是一个工程师用 AI 提效,而是整支固件团队——从架构师到新人——如何在同一套流程上协同。当 OpenSpec、Superpowers、gstack、MELD 四大工具组合在一起,UFS 固件开发会变成什么样子?这是一篇融合理论、架构、实操与教训的长文,建议收藏。

一、UFS 固件开发,为什么需要 AI 工程化?
UFS(Universal Flash Storage)固件开发是典型的高壁垒、长周期、重积累领域。一个成熟的 UFS 固件工程师,需要同时驾驭:
NAND Flash 物理特性:Program/Erase 行为、阈值电压分布、误码率模型、Read Retry 策略 FTL 核心算法:地址映射(L2P Table)、垃圾回收(GC)、磨损均衡(WL)、坏块管理 UFS 协议层:UTP 传输协议、UFS HCI 主机控制接口、RPMB 安全存储、Write Booster 性能加速 系统级问题:功耗管理、热节流、异常掉电保护、命令队列调度
这些领域的知识碎片化严重,很多时候依赖工程师的个人经验和口头传承。新人上手周期通常 6-12 个月,老工程师离职带走的不仅是人,还有大量未文档化的设计决策。
AI 编程工具的出现,理论上能让固件开发效率大幅提升。但现实是:AI 能写代码,却不知道项目的上下文;能改 Bug,却可能顺手引入三个新问题;能生成方案,但方案的正确性全靠开发者自己把关。这在固件开发中尤其危险——一行时序参数的误改,可能导致 NAND 批量报废。
1.1 AI 编程的三种层次
在深入框架之前,我们先厘清 AI 编程的三种主流范式:
| 范式 | 代表模式 | 适用场景 | 固件开发适用度 |
|---|---|---|---|
| Vibe Coding | 自然语言驱动,想到哪写到哪 | 原型验证、一次性脚本 | 危险:不可重现,无规范约束 |
| Agent 驱动 | AI 自主拆任务、写代码、提交 | 标准 CRUD、Web 开发 | 谨慎:固件的领域知识 AI 不具备 |
| SDD 规格驱动 | 先定规范,再驱动开发 | 复杂业务、长期项目 | 最佳:符合固件开发的高正确性要求 |
UFS 固件不是 CRUD——它运行在资源受限的嵌入式控制器上,一个错误可能导致设备变砖。SDD(Specification-Driven Development)+ TDD 的双重约束,是这个领域 AI 辅助开发的最低安全基线。
1.2 团队引入 AI 的五个典型断层
过去两年,单个工程师用 AI 工具开发 UFS 固件模块,效率提升肉眼可见。但当整支团队试图引入 AI 时,以下问题立刻浮出水面:
| 断层 | 表现 | 如果不管会怎样 |
|---|---|---|
| 环境断层 | 张工的 AI 知道 FTL 架构,李工的 AI 只会重复造轮子 | 同样的功能写出两套完全不兼容的实现 |
| 知识断层 | 专家脑中的 NAND 参数调优经验都在聊天记录里 | 新人用 AI 把已知 Bug 重新"创造"了一遍 |
| 规范断层 | 有人用 OpenSpec、有人 Vibe Coding、有人靠 prompt 贴 | AI 产出质量随人波动,代码审查成本飙升 |
| 角色断层 | 没人做架构审查、没人做 QA——AI 写了就合 | 上线后才发现竞态条件、时序越界、栈溢出 |
| 反馈断层 | 一个人踩了坑,其他人一定会在同一处再踩一遍 | 同一个 NAND GC 优化方案被 AI 写出三个有缺陷的版本 |
解决这些问题的关键,不是给每个人装更多插件,而是建立一套团队级 AI 协作工作流——把需求管理、规格驱动、工程纪律、角色分工、知识沉淀串联成可共享、可执行、可持续的体系。
二、四大工具全景:各司其职的 AI 开发武器库

2.1 OpenSpec — 需求规格层
来源:Fission-AI 开源 | 定位:SDD(Specification-Driven Development)框架
核心命令流程:/opsx:explore → /opsx:propose → /opsx:verify → /opsx:archive
产出物:proposal.md(变更提案)→ specs/(结构化需求)→ design.md(技术方案)→ tasks.md(任务清单)
在固件团队中的角色:需求与变更的"宪法"。所有 AI 协助的代码改动,必须对齐 specs 中的 Scenario。
一个典型的需求可能是:"优化 GC 策略,降低写放大"。传统做法:工程师脑中想清楚,然后让 AI 直接写代码。问题是——AI 并不知道你的 NAND 用了什么颗粒、PE Cycle 余量多少、WAF 目标值是多少、是否要考虑 QoS 抖动。
重要原则:proposal 里一定要写"不会发生什么"。这些"反范围"往往比功能点本身更能防止 AI 跑偏:
不改变已有的 Power Loss Protection 逻辑 不修改 NAND Command Queue 的优先级策略 不调整现有 WL 算法的权重参数 不改动 UFS LUN 的并发调度策略
2.2 Superpowers — 工程纪律层
来源:Jesse Vincent (obra) 开源 | GitHub Stars:14 万+ | 定位:子代理驱动开发(Subagent-Driven Development)
核心能力:TDD 强制 → 子代理(Implementer + Spec Reviewer + Code Quality Reviewer)→ 双重审查 → 6 项验证门禁
在固件团队中的角色:AI 写的每一行代码,必须经过 TDD 循环 + 代码质量审查 + 规范合规审查。不写测试就删代码——这不是理念倡导,而是机械强制执行。
TDD 六步循环(RED → GREEN → REFACTOR):
写失败测试 → 定义期望行为 运行测试 RED → 确认测试确实失败(保证测试有效) 最小代码实现 → 让测试变 GREEN(不写多余的代码) 运行测试 GREEN → 确认实现正确 代码重构 → 改善结构,不改变行为 提交代码 → 原子化提交,一条 commit 一个关注点
2.3 gstack — 角色分工层
来源:Y Combinator CEO Garry Tan 开源 | GitHub Stars:16,000+ | 定位:将 AI 变为虚拟工程团队
gstack 提供了 17 个 slash command,覆盖从产品审视到发布的完整链条:
| 命令 | 角色 | 在固件团队中的作用 |
|---|---|---|
/plan-ceo-review |
Founder 视角 | 质疑"你在解决正确的问题吗?" |
/plan-eng-review |
Tech Lead 视角 | 画架构图、找失败模式 |
/review |
偏执高级工程师 | 预判生产环境爆炸点 |
/ship |
发布工程师 | 处理机械性发布流程 |
/qa |
QA 主管 | 找 bug → 修 bug → 验证 |
/investigate |
根因调试 | 修三次失败就停 |
/guard |
安全护栏 | 限制 AI 修改范围 |
/retro |
自动复盘 | 数据驱动改进 |
Garry Tan 的设计哲学:"Planning is not review. Review is not shipping. If you blur all of that together, you usually get a mediocre blend. I want explicit gears."
在固件团队中的角色:让 AI 在不同阶段"切换大脑"。你需要的不是 AI 在写 FTL 时也关心 UI,而是在做 GC 优化时像架构师一样审查数据一致性。
2.4 MELD — 方法论编排层
来源:Solomon James 开源 (solomonjames/meld) | 定位:Methodology for Engineering Lifecycle & Development
三核心命令:/quick-spec(对话式 Spec Engineering)→ /quick-dev(实现流程)→ /assess-complexity(复杂度路由)
MELD 的独特价值:对抗性代码审查(adversarial review)——信息不对称的子代理审查,一个只看 spec 的审查员 vs 一个只看代码的审查员,在对话中辩论,比传统 CR 更可能发现偏差。
在固件团队中的角色:轻量化方法论的"粘合剂"。它不像 gstack 那样重量级,但提供了 quick-spec、quick-dev、复杂度路由等实用能力,适合固件团队从小处开始、逐步加深。
2.5 四工具的分工矩阵
| 维度 | OpenSpec | Superpowers | gstack | MELD |
|---|---|---|---|---|
| 管什么 | 需求与规格 | 工程纪律 | 团队角色 | 方法论流程 |
| 核心命令数 | 4 | 6 | 17 | 3+ |
| 复杂度 | 中 | 高 | 高 | 低-中 |
| 固件适用度 | 必需 | 必需 | 推荐 | 推荐 |
| 上手时间 | 1 天 | 3 天 | 1 周 | 半天 |
| 团队属性 | 共享规范 | 共享纪律 | 共享角色 | 共享方法 |
三、五层架构:团队级 AI 工作流设计
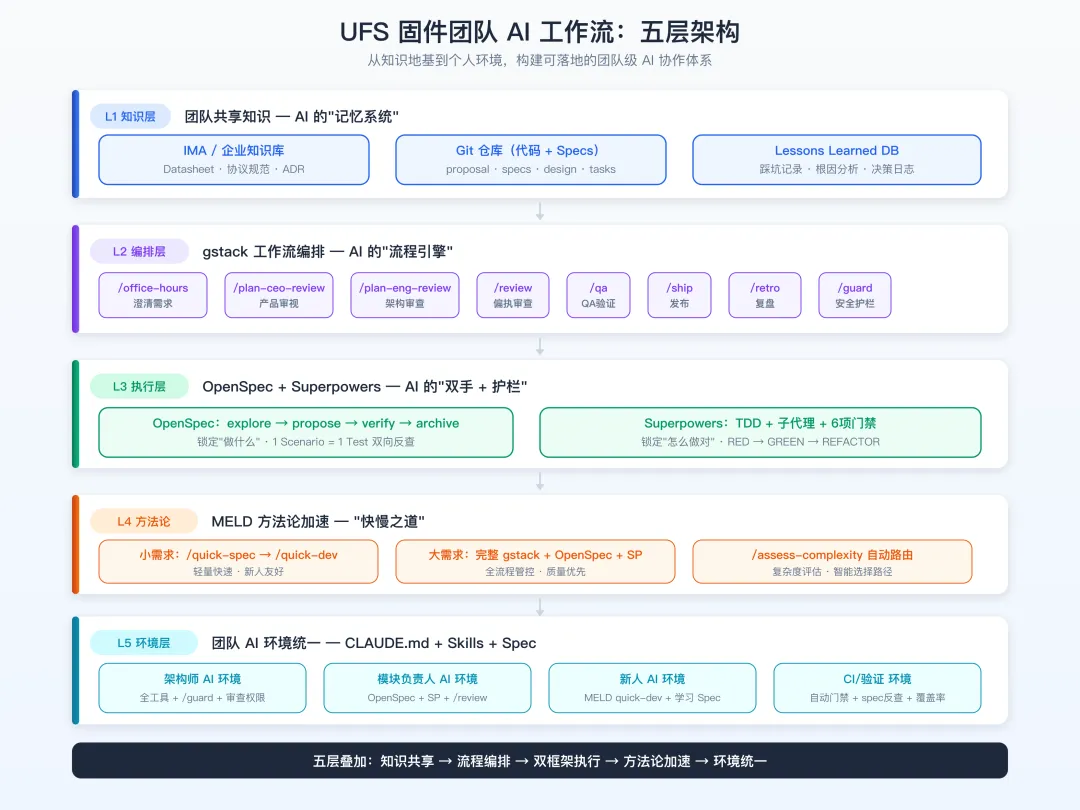
综合四工具的定位,我们设计一个面向 UFS 固件团队的完整 AI 工作流架构,自下而上五层叠加:
第一层:团队共享知识层 — AI 的"记忆系统"
这是团队 AI 工作流的地基。没有共享知识,AI 就是"失忆的聪明人"。
知识库 / 企业知识库:存储芯片 Datasheet、协议规范(JEDEC UFS)、架构文档、设计决策记录(ADR) Git 仓库:代码 + OpenSpec 生成的 specs/、proposals/、design/——这是 AI 每次对话的规范来源 Lessons Learned DB:踩坑记录(如 " 颗粒在 85°C 时需调整 Read Retry 偏移量")、根因分析、修复历史
第二层:工作流编排层(gstack 主导)— AI 的"流程引擎"
新功能开发的标准路径:/office-hours(澄清需求)→ /plan-ceo-review(产品审视)→ /plan-eng-review(架构审查)→ [开发实现] → /review(偏执审查)→ /qa(QA 验证)→ /ship(发布)→ /retro(复盘)
第三层:双框架执行层(OpenSpec + Superpowers)— AI 的"双手 + 护栏"
OpenSpec 锁定"该做什么" Superpowers 锁定"怎么做好" 每个 task 严格走 RED → GREEN → REFACTOR 每个 task 完成触发 spec-compliance-check + code-quality-review
第四层:方法论加速层(MELD)— AI 的"快慢之道"
小需求/Bug 修复:走 MELD quick-spec→quick-dev,轻量高效大需求/模块重构:走完整 gstack + OpenSpec + Superpowers 路径 MELD 的 assess-complexity帮你自动判断走快线还是慢线
第五层:团队 AI 环境层 — CLAUDE.md + Skills + Spec 三统一
不同角色的 AI 环境配置不同,但 CLAUDE.md、Skills 集合、Spec 规范、知识库四个层面必须统一。
四、完整开发工作流:从需求到归档
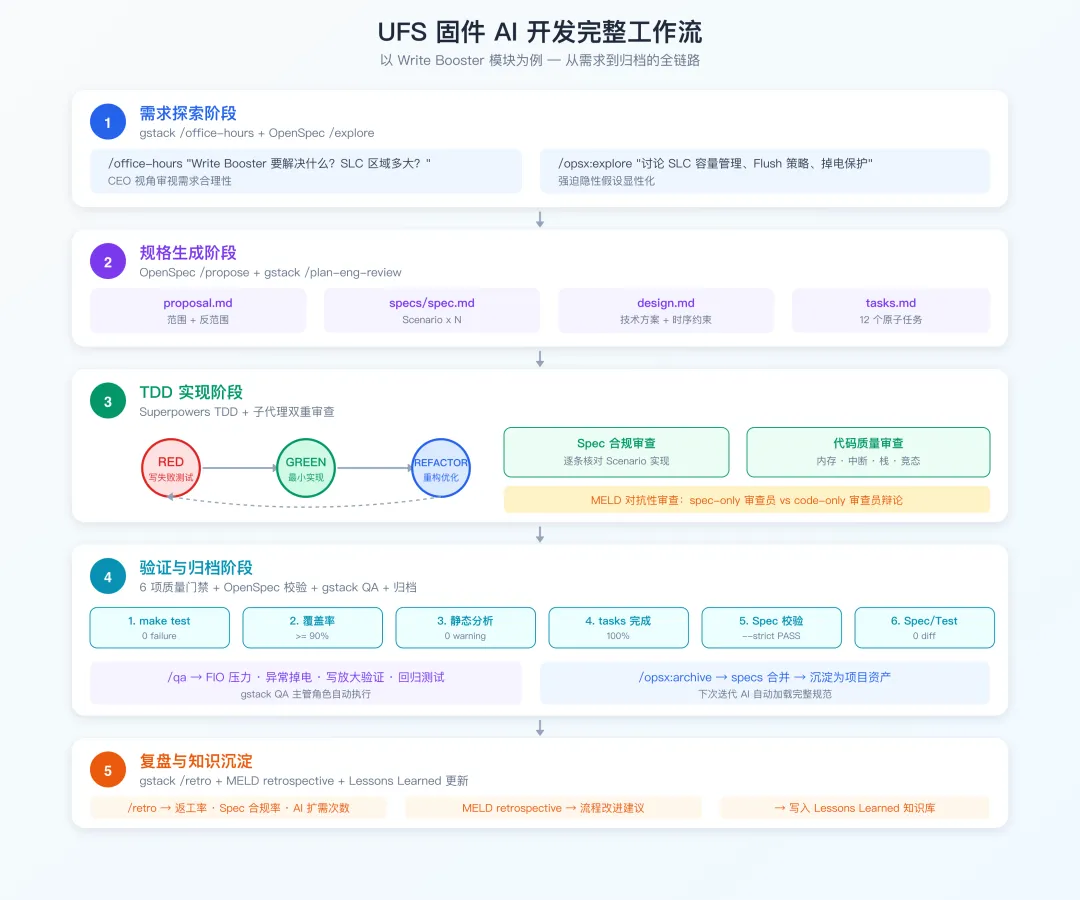
以 UFS 3.1 的 Write Booster 功能为例,演示从零到一的全链路。Write Booster 利用 SLC Cache 区域暂存写入数据,提升小数据块随机写入性能 3-5 倍。
4.1 第一阶段:需求探索
# gstack: CEO 视角审视需求合理性
/office-hours "Write Booster 要解决什么?SLC 区域多大?"
# OpenSpec: 深入讨论方案利弊
/opsx:explore
"为 UFS 3.1 固件新增 Write Booster 功能。
讨论:
1. SLC Cache 区域容量管理策略(固定分区 vs 动态分配)
2. Flush 触发条件(SLC 满触发 vs Idle 主动迁移 vs 混合策略)
3. 异常掉电如何保证数据原子性
4. 对现有 Read Path 的影响评估"
AI 会和你深入讨论每个选项的利弊。这个过程的价值不在于 AI 替你决策,而在于强迫你把隐性的设计假设显性化。
4.2 第二阶段:规格生成
/opsx:propose add-write-booster
AI 自动生成四类文档:
proposal.md 节选(范围 + 反范围):
实现 UFS 3.1 Write Booster SLC Cache 机制 支持 SLC→TLC 后台 Flush 迁移 异常掉电场景的数据一致性保护 不修改已有 Read Path 的 L2P 查找逻辑 不改变Write Buffer 的大小分配策略
specs/write-booster/spec.md 节选:
#### Scenario: normal_write_to_slc
GIVEN Write Booster 已开启且 SLC 空间充足
WHEN 主机发起 4KB 随机写请求
THEN 数据写入 SLC Cache 区域
AND 更新 SLC L2P 映射表
#### Scenario: slc_full_triggers_flush
GIVEN SLC 区域使用率 ≥ 95%
WHEN 新的 Write Booster 写入请求到达
THEN 触发后台 Flush,迁移最旧 SLC block 到 TLC
AND 单个 Flush 批次不超过 16 blocks
#### Scenario: power_loss_during_flush
GIVEN Flush 过程中发生异常掉电
WHEN 系统恢复上电
THEN 通过 Journal Log 回放恢复 Flush 断点
AND 不出现数据丢失或双写
4.3 第三阶段:TDD 实现
启动 Superpowers 前,强制加载 OpenSpec 全套规范:
"基于 openspec/changes/add-write-booster/ 的规范文档,
用 TDD 实现 Write Booster 功能。每个 task 严格走 RED→GREEN→REFACTOR"
一个 task 的完整 TDD 循环示例(Task 3: SLC Flush 触发逻辑):
// Step 1: AI 先写测试
void test_slc_full_triggers_flush(void) {
slc_init(3000); // 3GB SLC
fill_slc_to(0.95); // 填充到 95%
int ret = wb_write(test_data, 4096);
ASSERT_EQ(ret, WB_FLUSH_TRIGGERED);
}
// Step 2: make test → FAIL (RED)
// Step 3: AI 实现最小逻辑
int wb_write(void *data, size_t len) {
if (slc_usage_pct() >= 0.95) {
trigger_background_flush();
return WB_FLUSH_TRIGGERED;
}
return slc_direct_write(data, len);
}
// Step 4: make test → PASS (GREEN)
// Step 5: AI 重构提取公共函数
// Step 6: git commit "feat(ftl): add slc flush trigger (Sc: slc_full)"
每个 task 完成后触发双重审查:Spec 合规审查(逐条核对 Scenario 实现)+ 代码质量审查(内存、中断、栈、竞态)。MELD 的对抗性审查让 spec-only 审查员和 code-only 审查员辩论,比传统 CR 更可能发现偏差。
4.4 第四阶段:验证与归档
全部 task 完成后,6 项质量门禁全部通过才能归档:
| # | 检查项 | 门禁标准 | 失败后果 |
|---|---|---|---|
| 1 | make test 全量 |
0 failure | 禁止归档 |
| 2 | 代码覆盖率 | ≥ 90% | 标记警告 |
| 3 | 静态分析 | clean(0 warning) | 禁止归档 |
| 4 | tasks 完成度 | 100% 完成 | 禁止归档 |
| 5 | openspec validate --strict |
PASS | 禁止归档 |
| 6 | spec ⇌ test 双向反查 | 0 diff | 禁止归档 |
gstack 的 /qa 自动执行 FIO 压力测试、异常掉电测试、写放大验证和回归测试。通过后 /opsx:archive 将 specs 合并到主规范,沉淀为项目资产——下一次固件迭代时 AI 自动加载这份 spec,不需要重新解释。
4.5 第五阶段:复盘与知识沉淀
/retro 分析提交历史、编码会话、发布速度,生成数据驱动的复盘报告。MELD 的 retrospective 提供流程改进建议。所有踩坑写入 Lessons Learned 知识库。
五、灵魂契约:1 Scenario = 1 Test
整个融合架构中最重要的机制,是 spec Scenario 与 test 用例的 1:1 双向反查:
OpenSpec spec.md 中写的: Superpowers TDD 写的:
#### Scenario: normal_gc_trigger ⇌ test('normal_gc_trigger', ...)
用一行 shell 命令就能验证对齐:
diff <(grep '^#### Scenario:' specs/*/spec.md | sed 's/.*Scenario: //') \
<(grep "test('" tests/ | sed -E "s/.*test\('([^']+)'.*/\1/")
# 预期输出:0 行差异 = 完全对齐
spec 或 test 任一改名,diff 立刻变红,CI 可阻断 PR。不靠口头约定,不靠 review 自觉——这是机器可断言的硬契约。
关键设计决策:桥接层不改源码
桥接层用 slash command 实现,不改 OpenSpec 和 Superpowers 任何源码。理由很务实:两个开源项目各自独立升级时定制不会被冲掉;桥接层是团队的 git 资产,可以根据固件项目特点自由调整。
六、工程师如何发挥作用?

在 AI 辅助的 UFS 固件开发中,工程师的角色不是"给 AI 下指令",而是定义边界、验证输出、沉淀知识。
6.1 专家工程师的杠杆作用
专家工程师(10年+ NAND/FTL 经验)在 AI 工作流中不是被替代,而是被放大:
1. 把隐性知识显性化
不是:"GC 阈值我凭经验设 15%" 而是:写入 Spec
#### Scenario: gc_threshold_calculation
GIVEN NAND 为 KLUEG8U1EM-B0C1
AND PE Cycle 在 0-3000 范围
WHEN 计算 GC 触发阈值
THEN 阈值为 15%(基于该颗粒在 85°C 下 3000 PE 的 RBER 曲线)
2. 审核 AI 的设计方案:用 /plan-eng-review 生成架构方案,专家把关技术决策。AI 可能不知道 NAND Command Queue 优先级对 QoS 的影响——专家在审核时补上,经验变成 Spec 中的约束条件。
3. 构建团队的 AI 知识资产:把关键设计决策写成 ADR,把调试心得写入 Lessons Learned,编写团队专属的 AI Skill(如 "nand-parameter-validator")。
6.2 新人如何快速融入 AI 工作流
第一周:安装四工具,用 MELD /quick-spec"理解 FTL 地址映射模块" 生成学习 Spec,跑通第一个 TDD 循环第二周:用 /quick-dev完成第一个小 Bug 修复,学习阅读团队 Spec 库第一个月:独立完成一个中等复杂度需求(如新增 SMART Log 字段),走完整流程,输出一份 Lessons Learned
上手周期从 6-12 月缩短到 1-2 月——这是 AI 工作流对团队最大的价值之一。
七、如何拉通团队 AI 环境差异?
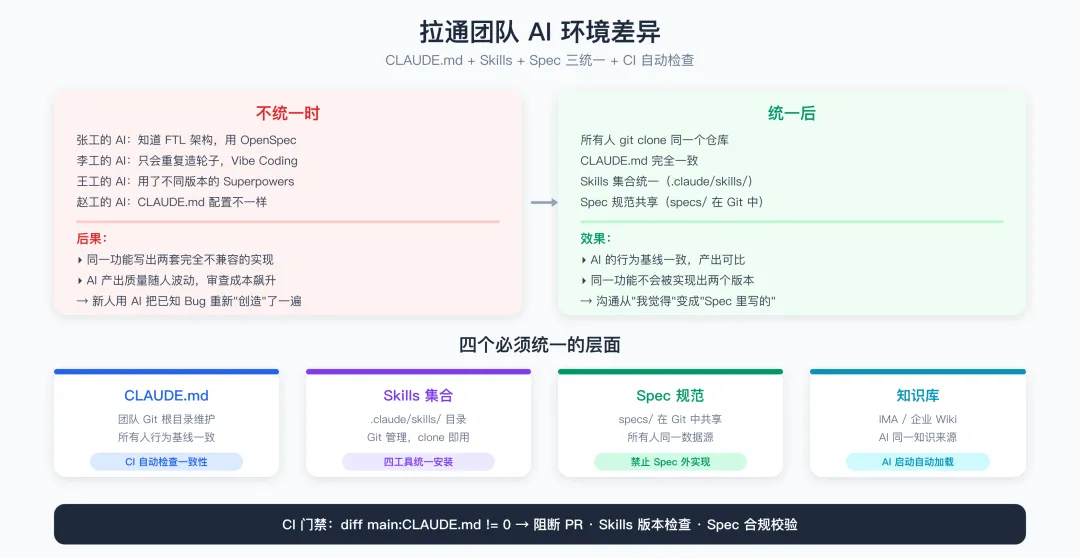
这是团队引入 AI 时最容易被忽视、后果却最严重的问题。
7.1 必须统一的四个层面
| 层面 | 统一方式 | 不统一的后果 |
|---|---|---|
| CLAUDE.md | 团队 Git 仓库根目录维护,所有人一致 | AI 的行为基线不一致,产出不可比 |
| Skills 集合 | Git 管理的 .claude/skills/ 目录 |
有人用 gstack 有人不用,流程混乱 |
| Spec 规范 | OpenSpec 生成的 specs/ 目录在 Git 中 | 同一功能被 AI 实现出两个版本 |
| 知识库 | 知识库或企业 Wiki,同一数据源 | AI 掌握的知识量不同,方案质量差异大 |
7.2 实操:建立团队基础环境仓库
mkdir team-ai-workflow && cd team-ai-workflow && git init
# 安装四大工具
git clone https://github.com/fission-ai/openspec.git .claude/skills/openspec
git clone https://github.com/garrytan/gstack.git .claude/skills/gstack
# 编写团队 CLAUDE.md
cat > CLAUDE.md << 'EOF'
## UFS Firmware Team AI Workflow
### 知识源
- 优先读取 IMA 知识库中的芯片 datasheet 和协议规范
- 优先读取仓库 specs/ 目录下的已有 Spec
- 不了解的 NAND 参数必须标注为 UNKNOWN,禁止猜测
### 必须遵守
- 任何功能开发必须先 /opsx:explore → /opsx:propose
- Superpowers 启动前必须加载 OpenSpec 全套规范
- 修改 NAND 操作相关代码必须先 /guard
- Archive 前必须通过 6 项质量门禁
### 禁止行为
- 禁止修改已有 NAND Command Queue 优先级
- 禁止在 ISR 中调用阻塞函数
- 禁止运行时 malloc(仅允许初始化阶段分配)
EOF
git add -A && git commit -m "init: team AI workflow environment"
CI 中添加环境一致性检查:diff main:CLAUDE.md 不为 0 则阻断 PR。
八、如何降低沟通成本?
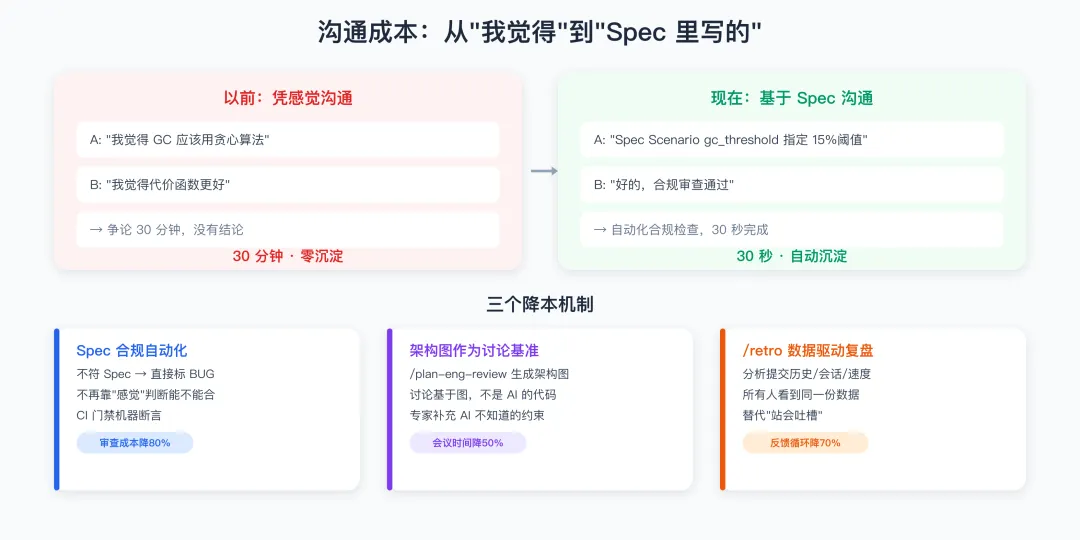
AI 引入后的团队沟通成本,如果处理不好反而会上升——不是因为 AI 写不好代码,而是因为人对 AI 产出的信任度不一致。
8.1 三个核心沟通问题及解法
| 问题 | 传统解法 | AI 时代的解法 |
|---|---|---|
| "这段 AI 写的代码能合吗?" | 凭感觉/凭关系 | Spec 合规审查自动化——不符 Spec 直接标 BUG |
| "AI 的设计方案对不对?" | 开会争论 | /plan-eng-review 的架构图作为讨论基准 |
| "上次那个坑我明明说过" | 翻聊天记录 | Lessons Learned 知识库 + AI 启动时自动加载 |
8.2 建立基于 Spec 的沟通语言
团队沟通从"我觉得"变成"Spec 里写的是":
以前:A 说"我觉得 GC 应该用贪心算法",B 说"我觉得代价函数更好"→ 争论 30 分钟,没有结论。
现在:A 说"Spec Scenario gc_threshold_calculation 指定了 15% 阈值,基于 KLUEG8U1EM-B0C1 在 85°C 的测试数据"→ B 说"好的,review 通过"→ 30 秒。
8.3 用 /retro 替代"站会吐槽"
/retro 会分析提交历史、编码会话、发布速度,生成数据驱动的复盘报告。关键是——所有人都看到同一份数据,而不是各自凭印象。
九、必须建立公共知识库吗?

答案是:必须在第一天就建立。没有共享知识库的团队 AI 工作流,就像没有 git 的多人编程。
9.1 知识库的六大分类
芯片资料:NAND Datasheet、JEDEC UFS 规范、控制器编程手册、温度-RBER 特性曲线(AI 启动时自动加载) 架构文档:FTL 总体架构、模块边界与接口契约、ADR、数据流图(架构师维护) Spec 规范:OpenSpec specs/ 目录、团队 Spec 编写规范、硬件约束写法模板(Git 版本管理) Lessons Learned:NAND 踩坑、FTL Bug 记录、AI 使用技巧(每次迭代后更新) 测试用例:FIO 压力配置、回归测试套件、异常掉电测试脚本、Mock HAL 层(QA 维护) AI 工作流:CLAUDE.md 团队约定、Skills 使用指南、新人 Onboarding 清单(Tech Lead 维护)
9.2 Lessons Learned 模板
## LL-2026-001: KLUEG8U1EM-B0C1 高温 Read Retry 偏移
**发现人**:张工 | **日期**:2026-03-15 | **影响模块**:FTL / Read Retry
### 问题
AI 生成 Read Retry 代码时,使用了默认阈值电压偏移量。
在 85°C 环境测试中,该颗粒的 RBER 比 25°C 时高 3.2 倍,默认偏移量导致 Read Retry 失败率 12%。
### 根因
AI 不知道 KLUEG8U1EM-B0C1 颗粒的温度-RBER 特性曲线。
### 解决方案
在 NAND HAL 层添加温度感知的偏移量计算,已在 Spec `nand-read-retry-temp-comp` 中记录。
### AI 预防
将此信息写入 NAND_Parameters 知识库,AI 启动时自动加载。
十、UFS 固件开发的特殊考量
10.1 嵌入式测试环境适配
| 测试层级 | 运行环境 | 覆盖内容 | 工具 |
|---|---|---|---|
| 单元测试 | PC Host(x86) | FTL 算法逻辑、状态机 | gtest / unity |
| 集成测试 | 目标板 + NAND | 硬件交互、时序 | 自定义 test harness |
| 压力测试 | 目标板 | 长期稳定性、GC 行为 | FIO / 自定义 workload |
Mock 策略:NAND 芯片操作封装为 HAL(硬件抽象层),单元测试时用 mock 替代真实 NAND 操作。
10.2 代码审查的固件专项规则
内存分配是否在初始化阶段完成(禁止运行时 malloc) 中断上下文中是否有耗时操作(禁止在 ISR 中调用阻塞函数) 是否有潜在的栈溢出风险(递归调用、大数组局部变量) 电源管理状态机的完整性(每个状态都有超时保护) NAND 操作超时后的回滚策略(不能留下半写状态的 block)
10.3 硬件相关的 Spec 怎么写
#### Scenario: nand_program_timeout
GIVEN NAND Program 操作已发出
WHEN 超过 5ms 未收到 Ready/Busy 确认
THEN 标记该 Page 为可疑
AND 将数据重写到备选 Page
AND 记录超时事件到 SMART Log
## 时序约束
- NAND Read 操作:max 80μs(SLC)/ 120μs(TLC)
- GC 后台迁移:单次迁移不超过 500μs(避免影响主机 IO)
## 资源约束
- SLC Cache 元数据:≤ 64KB SRAM
- Flush 状态机栈深度:≤ 512 bytes
十一、7 个高频踩坑与避坑指南
| 坑 | 问题 | 根因 | 解法 |
|---|---|---|---|
| 坑 1 | AI 方案与硬件不匹配 | 跳过 Explore 直接 Propose | 铁律:永远先 Explore 再 Propose |
| 坑 2 | AI 擅自改已有模块 | proposal 缺少排除范围 | 标注"不改动范围",纳入合规审查 |
| 坑 3 | tasks 与 TDD 粒度错位 | OpenSpec 需求视角 ≠ 实现视角 | 桥接层自动拆解任务粒度 |
| 坑 4 | 实现背离 design 方案 | Superpowers 未加载规范 | 启动前强制导入 OpenSpec 全套文档 |
| 坑 5 | CR 查不出规范偏差 | 原生审查只检代码质量 | 新增 spec-compliance-check Skill |
| 坑 6 | 只做代码审查或只做校验 | 混淆代码质量与规范合规 | 代码 CR + 合规审查 + Verify 三步全走 |
| 坑 7 | 归档后暴露隐藏 Bug | 归档前无强制全量测试 | Archive 前置全量测试门禁 |
坑 2 和坑 4 在固件开发中危害最大。AI 很可能"顺手"改掉你精心调校的 NAND 时序参数或中断优先级,而这些问题在代码审查层面极难发现。
关键教训:
Explore 不是可选项,是必选项:固定 Explore→Propose 顺序后,返工率降低 80% Superpowers 空跑比不用更危险:没有加载 OpenSpec 规范就给 AI 下指令,相当于给了 AI 一辆没有导航的跑车 测试不通过禁止归档是底线:必须通过桥接 Skill 强制归档前跑全量测试
5 个坑可通过配置自定义 Skill 自动化处理(spec-compliance-check + openspec-superpowers-bridge)。
十二、AI 在 UFS 固件开发中的挑战与机遇

12.1 六大挑战
| 挑战 | 严重度 | 应对策略 |
|---|---|---|
| 领域知识匮乏 | 高 | 知识库建设 + 专家将经验写入 Spec |
| 正确性验证困难 | 高 | TDD + 6 项门禁 + 目标板实机验证 |
| 硬件时序敏感性 | 高 | Spec 中写入时序约束 + /guard 锁定高风险模块 |
| AI "幻觉"代码 | 中 | Spec 合规审查 + API 文档作为事实源 |
| 工具链碎片化 | 中 | 统一 CLAUDE.md + Skills + Git 管理 |
| 团队信任建立 | 中 | 从低风险模块开始,用数据证明;/retro 展示质量趋势 |
12.2 五大机遇
| 机遇 | 预期收益 | 落地方式 |
|---|---|---|
| 新人上手加速 | 6-12 月 → 1-2 月 | MELD quick-spec 理解代码 + AI 辅助写单元测试 |
| 知识永续 | 不再依赖个人记忆 | OpenSpec Archive + Lessons Learned 知识库 |
| 代码质量一致性 | 返工率降低 60-80% | TDD + 双重审查 + 质量门禁 |
| 专家杠杆最大化 | 1 个专家带 5 个 AI 辅助新人 | 专家写 Spec + 审查,新人做实现 |
| 持续交付能力 | 迭代周期缩短 40-60% | gstack /ship 自动化发布 + /qa 自动化测试 |
12.3 UFS 固件的底线思维
NAND 操作相关代码:AI 可以写,但必须 /guard+ 必须实机验证Power Loss Protection:AI 只能辅助分析,最终方案必须专家确认 RPMB / 安全相关:建议不用 AI 直接写,用 AI 做方案审查 生产环境固件:AI 辅助的代码至少要经过几轮回归压力测试
十三、落地路线图:四周从 0 到 1
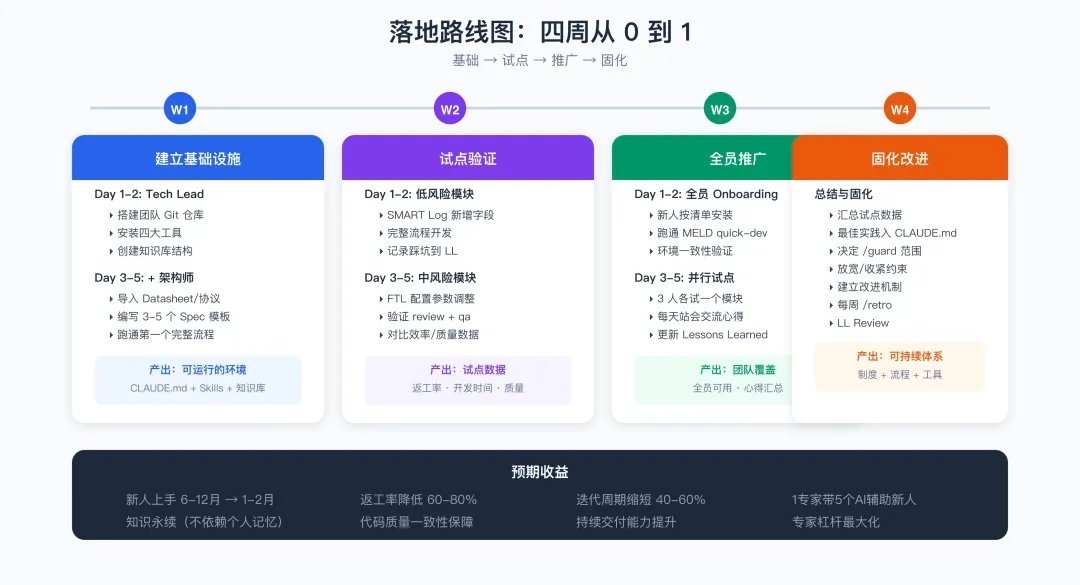
第一周:建立基础设施
Tech Lead 搭建团队 Git 仓库(含 CLAUDE.md),安装四大工具到 .claude/skills/,创建 IMA 知识库结构。架构师导入关键文档,编写 3-5 个核心 Spec 模板,跑通第一个完整流程。
第二周:试点验证
选一个低风险模块(如 SMART Log 新增字段)用完整流程完成开发,记录所有踩坑到 Lessons Learned。再选一个中等风险模块(如 FTL 配置参数调整),验证 /plan-eng-review + /review + /qa,对比 AI 辅助与纯人工的效率和质量数据。
第三周:全员推广
新人按 Checklist 安装环境,跑通 MELD /quick-dev 小需求。3 个工程师各试用一个模块,每天站会交流 AI 使用心得,更新 Lessons Learned。
第四周:固化改进
总结试点数据(返工率、开发时间、质量指标),将最佳实践固化到 CLAUDE.md 和 Skills,决定哪些模块需要更强约束(/guard)、哪些可以放宽,建立持续改进机制(每周 /retro + Lessons Learned Review)。
十四、选型指南:什么场景用哪个?
三种模式的实测对比
以同一个功能开发为例,三种模式的实测数据:
| 维度 | 单用 OpenSpec | 单用 Superpowers | 四工具联用 |
|---|---|---|---|
| 需求边界管控 | 依靠提案排除范围 | 口头约束 | 排除范围 + 合规双重管控 |
| 单元测试 | 无强制 | 全量 TDD | 全量 TDD |
| 规范合规校验 | 仅 Verify | 无此能力 | 合规审查 + Verify 双重 |
| 返工次数 | 1-2 次 | 2-3 次 | 0-1 次 |
| 历史规范沉淀 | 持续沉淀 | 无留存 | 规范 + 编码纪律 + 知识库 |
| 团队角色覆盖 | 无 | 无 | CEO→Eng→QA→Ship 全链 |
场景推荐
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 多人协作固件项目 | 四工具联用 | 标准化 review 抓手,减少知识孤岛 |
| 长期维护的 UFS 产品线 | 四工具联用 | 迭代周期以年计,规范沉淀价值巨大 |
| Write Booster/HPB/RPMB | 四工具联用 | 协议级复杂功能,需双向约束 |
| 存量固件重构 | 四工具联用 | 老代码重写需清晰范围约束 |
| 一次性原型验证 | 仅 Superpowers + MELD | 流程 overhead 可接受 |
| 纯 Bug 修复 | 仅 OpenSpec + MELD quick-dev | 改动小,TDD 显得重 |
| 生命周期 < 3 个月 | 都不用 | 投入产出比不高 |
简单判断公式
代码生命周期 ≥ 3 个月 + 需要他人接手维护 → 四工具联用 需要测试保障但需求简单 → 仅 Superpowers + MELD 需要沉淀规范但开发量小 → 仅 OpenSpec + MELD
十五、生态图谱
在 AI 编程工程化领域,还有几个相关工具值得关注:
| 工具 | 定位 | 与四工具的关系 |
|---|---|---|
| Spec-Kit (GitHub) | GitHub 官方 SDD 工具 | 重流程管控,8 阶段线性流程;与 OpenSpec 互补 |
| GSD | 增量执行机制 | 适合复杂任务分步执行 |
| CodeGraph | 代码知识图谱 | 静态分析代码结构,辅助 AI 理解项目上下文 |
| Comet | 工作流编排器 | 将 OpenSpec + Superpowers + CodeGraph 拧成整体 |
社区实践共识:OpenSpec 管需求边界 → Superpowers 管落地质量 → gstack 管团队角色 → MELD 管方法路由 → CodeGraph 管代码理解,五层叠加实现从需求到交付的全链路 AI 管控。
十六、未来展望:工具会过时,原则不会
这套方案解决的核心问题是:当下的 AI 不会自动叠加 TDD + 双向反查的严密性。所以我们需要写桥接命令强制它走。
但 6-12 个月后,情况会变:AI 能从需求直接生成 TDD spec + 跑红绿;AI 主动推断该 invoke 哪些 skill;AI 自动维护双向反查。
工具会过时,三条原则不会:
Spec 是单一真相源:业务契约必须有唯一定义点,无论 AI 多强 1 Scenario = 1 Test 是契约的机器表达:可机器断言的协作契约是工程领域的硬通货 Fresh evidence over claims:没跑过的验证等于没验证,这是工程伦理
十七、总结
UFS 固件团队引入 AI 工作流,本质上不是"用 AI 替代工程师",而是建立一套让 AI 在正确轨道上帮助工程师的体系。
四大工具的定位分工:
OpenSpec → "我们到底要做什么" —— 需求规格的宪法 Superpowers → "怎么保证做对" —— 工程纪律的执法者 gstack → "谁来做什么" —— 团队角色的编排器 MELD → "怎么做更快" —— 轻量方法的加速器
三个关键原则:
知识共享是地基:没有共享知识库,AI 工作流就是空中楼阁 环境统一是前提:CLAUDE.md + Skills + Spec 必须在 Git 中,所有人一致 质量门禁是底线:测试 → 覆盖率 → 静态分析 → 规范校验 → 双向反查,不全部通过禁止归档
工程师的新价值:定义边界、验证输出、沉淀知识。AI 能写代码,但只有工程师知道什么是一个好的 UFS 固件。
建立工程纪律的那一刻,比工具用什么更重要。
参考资料:
OpenSpec(Fission-AI)开源项目 Superpowers(Jesse Vincent / obra),GitHub 14万+ Star gstack(Garry Tan / Y Combinator),GitHub 16,000+ Star MELD(Solomon James),MIT 开源 社区实践文章:程序员技术实录、码途进化论、创见AI实验室、星仔AI、Swanky Studio、SitePoint 等 本文固件案例为教学示例,实际项目中请根据硬件平台调整
