 夜雨聆风
夜雨聆风
最近常看到一种说法,说 AI 制药的泡沫快破了。
过去几年,这个行业几乎共用一套说辞:更快、更便宜、更高成功率、更强 novelty。大量公司靠“AI 发现新药”的故事拿融资、谈合作、撑估值。
等到全球创新药融资转冷,大家才开始追问一个问题,这四件事,到底有几家能同时证明。
资本盯上的核心指标也变了,你的项目中从 idea 到 development candidate 到底缩短了多少时间?
我的看法是,泡沫没破,是在出清。这两个词差别很大。破,意味着方向错了;出清,意味着方向没错,只是只会讲故事的人正在被挤出去。
01 /速度叙事开始失效
一个被反复引用的例子。Exscientia 用 AI 设计的强迫症药物 DSP-1181,大约 12 个月就设计出来,而传统流程通常要四到六年。2020 年它进入临床,速度快得让整个行业兴奋。然后呢,Phase I 之后就停了,没能走到 Phase II。
BenevolentAI 的故事要更一言难尽。核心管线在临床中段折戟,紧接着是一轮又一轮裁员、关掉美国办公室、计划从泛欧交易所退市,重组计划一路排到 2027 年,只能靠对外授权资产续命。2025 年 3 月,它被 Osaka Holdings 收购。
这两个案例放在一起,能看清一件事:AI 能加速的是“发现”这一段,可它降不了临床的失败率。一个靶点选错了,AI 把研发速度提高三倍,也只是让你更快地失败,而失败数据甚至都不算数据。
说到底,药物研发最贵的从来是决策成本,实验速度排在后面。一个真正有价值的 AI 系统,应该帮团队更早识别无效机制、更早砍掉错误项目、更准地预测毒性和转化风险,而不只是生成更多候选分子。
02 /行业不是破裂,是分层
但要因此说“泡沫破了”,数据并不支持。截至 2026 年初,全球有超过 173 个 AI 发现的药物项目在临床开发中,预计 2026 年有 15 到 20 个进入关键试验,AI 来源分子的 IND 申报在 2025 年还创了单年最大增幅。真东西还在往前长。
真正发生的,是这个行业在分层。

一边是并购出清。Recursion 在 2024 年底以约 6.88 亿美元的全股票交易吃下 Exscientia,合并后管线砍到只剩五条左右;BenevolentAI 被收购。
另一边是真正跑出来的反例。英矽智能的 ISM001-055 治疗特发性肺纤维化,用 AI 找到新靶点、设计分子,从临床前到 Phase I 不到 18 个月,成本大约是传统的十分之一,到 2024 年底拿到了积极的 Phase IIa 结果。
市场正在把“AI 基础设施公司”和“真正的 AI biotech”分开。前者卖模型、平台和算法服务,后者得持续产出真能进临床、有差异化的药。决定格局的,是谁真正改变了 R&D 的生产函数,至于模型大小,排在很后面。
03 /真正的护城河
真正的护城河是数据闭环。
模型这东西,今天谁都能调大。真正稀缺的,是高质量的“负数据”。公开数据库几乎都在记录成功结果,但真正能提升模型判断力的,是失败的实验、无效的化合物、不可重复的结果,以及从没发表过的毒性数据。
这些东西通常散落在不同部门,甚至根本没被系统保存。于是很多公司会走到一个尴尬的阶段,模型越堆越大,预测能力却不再同步提升,因为训练数据已经撞到了信息天花板。
领先的公司赢在哪?通常赢在它手里攥着一个别人看不到的数据闭环。会讲 AI 故事的人太多,能攒下数据闭环的太少。
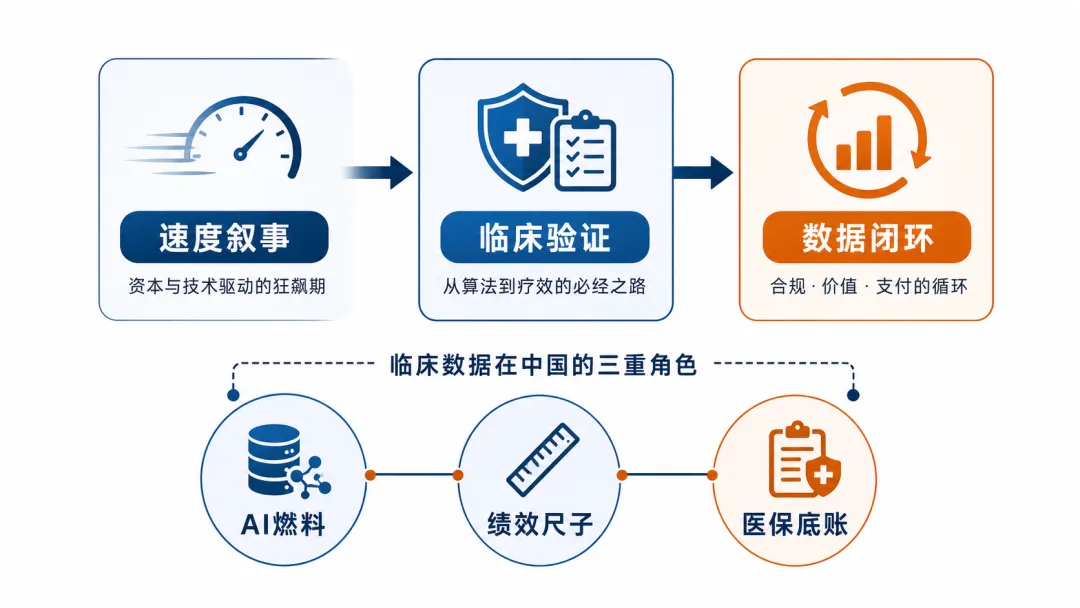
04 /在中国,数据闭环更重要
在中国,医疗数据不是一份你能随便抓来喂模型的“资产”,它是被制度性地攥住的。
拿上海举例。有一家叫上海申康医院发展中心的机构,很多人以为它是公司,其实它是上海市政府直属的事业单位,2005 年因为公立医院“管办分离”改革成立,负责市级医院的出资和院长绩效考核。
它从 2006 年起建“医联工程”,把上海几十家三级医院的临床数据接到一张网上。公开报道里,这个平台覆盖的诊疗档案、医嘱、检查报告都是以亿计的量级,被称作全国最大的医疗档案信息库之一。
这批数据怎么用?
既是大家都想要的 AI 训练燃料,又是衡量医院的那把尺子。每年医院要参加公立医院绩效考核,业内叫“国考”,里面有四个维度、几十项指标,其中四级手术占比、出院患者手术占比、并发症发生率这些,都是直接从病案首页里提取的。
同一批数据,又是医保审查医院的底账。DRG/DIP 支付改革之下,医保要看你科室做了多少高难度手术、有没有超支、药耗占比是否超标,而且在不少省份,医保绩效评价的结果还会抄送卫健部门,和国考挂钩。
所以你看,在中国,同一份临床数据同时扮演三个角色:它是大家都想要的 AI 燃料,是给医院打分的尺子,也是医保结算和审查的底账。
它被申康这样的机构、被医院、被医保,牢牢锁在一个治理闭环里。这意味着一个只有大模型、却进不去这个闭环的算法团队,手里那点优势其实很虚。模型决定你能不能入场,数据治理才决定你能不能留下。
05 /中小团队该从哪里切进去?
个人观点。
这几年技术这一层卷得太满,能讲的故事差不多都讲过了。
如果把怎么把失败的、负的、没人愿意存的数据攒下来,去探索怎么合规地进到医院和医保的数据闭环里,搞懂怎么在别人看不见的地方,悄悄打出自己的那口井。
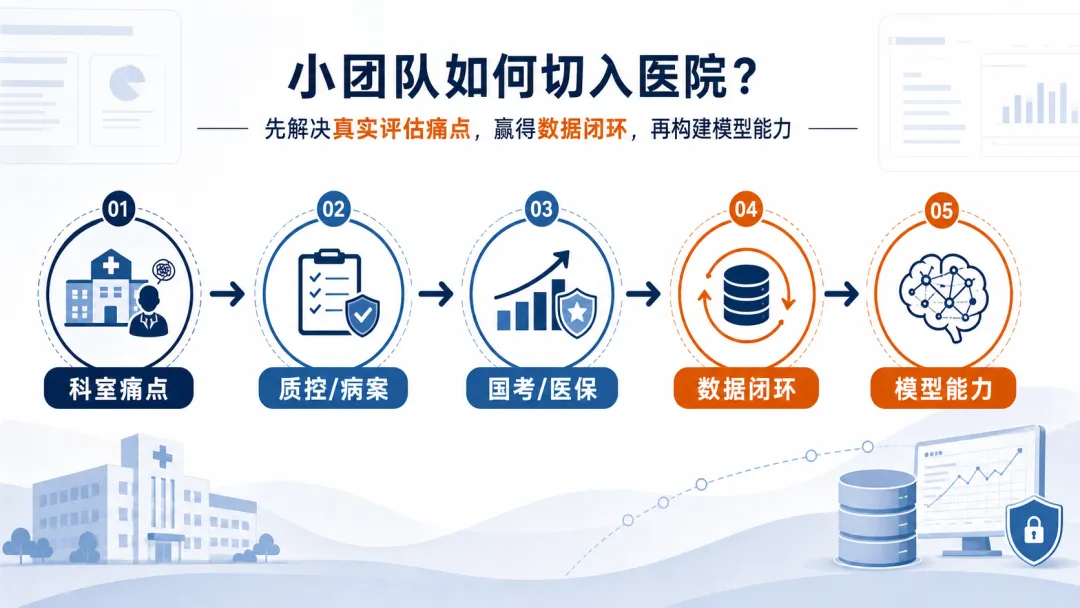
图注:小团队更现实的路径,是先解决评估痛点,再沉淀数据闭环。
做诊断大模型去硬闯医院是很艰难的路子,不如先找一个具体的科室、一个具体的病种,从他们每天为了国考和医保头疼的那些指标切进去,帮他们把数据理顺、把质控做扎实。
你帮医院解决了“被考核”的真问题,数据闭环才会向你打开一条缝。等你在那条缝里站稳了,再去谈模型,谈 novelty,谈下一步也不迟。
AI 制药这轮退潮,退掉的是只会讲故事的人,留下来的,都是手里有井的人。
医疗 AI,也是一样。
— END —
我们手上有个AI+医疗的行业小群,里面是创业者、临床医生、医药企器械这些真正在一线做AI临床落地的人。群里更实在的是线下,我们差不多每两周就会攒一次小局,十来个人围一桌,喝咖啡吃点心,聊各自在做什么、卡在哪。线上没赶上的,线下能补回来。
另外还有个偏科研向的群,想去的可以一起跟我说。
备注你的方向,我看到回你。

