 夜雨聆风
夜雨聆风
背景
在医疗AI这个赛道,有一个近乎公认的逻辑:通用大模型太宽泛,医学需要专业性,所以要用专门针对医疗场景训练或优化的AI工具。
这个逻辑听起来顺理成章。医生问的问题,涉及药物交互、诊断思路、临床指南,不是普通人会问的问题,也不是普通AI该乱答的领域。于是,围绕这个逻辑,一批"临床AI工具"应运而生。
OpenEvidence是其中之一,专门面向美国临床医生,免费使用,靠广告盈利。2025年,它完成了2.1亿美元融资,估值35亿美元,被称为"史上增长最快的医生应用"。UpToDate则更老牌,是医学界几十年来的"参考圣经",其AI版本UpToDate Expert AI以每年约699美元的个人订阅价向医生销售。
这两款工具都宣称,自己在通用大模型的基础上,通过医学知识检索增强(RAG)或专业训练,让AI在临床场景中表现更好、更安全。
2026年5月,纽约大学朗格尼健康中心的研究团队在《自然·医学》上发表了一篇论文,把这个前提直接拿去检验了一遍。[1]

三轮比赛,全部告负
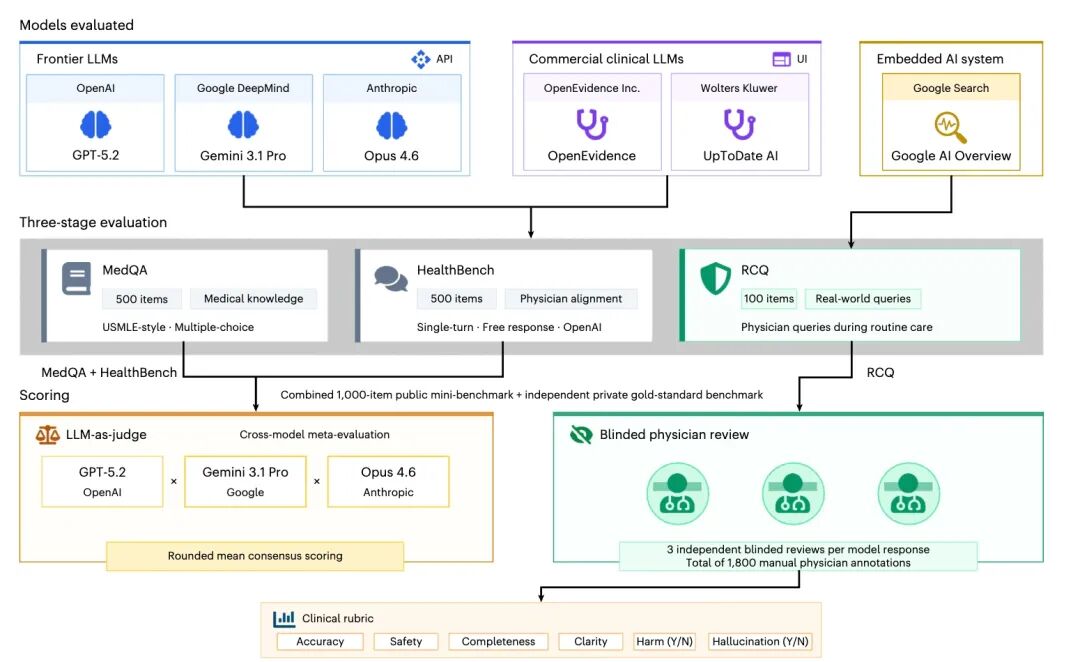
研究设计了三个阶段的评测,从标准化题库到真实临床查询,难度依次递进。
第一关是500道美国执照考试(USMLE)风格的医学选择题。Gemini 3.1 Pro准确率97.4%,GPT-5.2是94.2%,Claude Opus 4.6是90.2%。OpenEvidence是89.6%,UpToDate是88.4%。
差距不算悬殊,但方向很清晰:三个通用模型占据前三位,两个专用工具排在后面。
第二关是500条HealthBench题目,这是OpenAI设计的一套标准,考查模型的回答与专业临床医生的判断有多一致。GPT得了88分(满分100),Gemini 79.3,Claude 77。两个专用工具:OpenEvidence 62.6,UpToDate 61.3。
这一关的差距就大了。
第三关最接近真实世界:100条来自纽约大学朗格尼医院的真实匿名临床查询,就是医生在工作中实际向院内HIPAA合规GPT系统提出的问题。12名临床医生在不知道答案来自哪个模型的情况下,从四个维度(临床正确性、完整性、安全性、表达清晰度)给每条回答打1-4分,共产生1800条独立评分。
结果出现了两个明显的层次。通用三人组:Gemini 3.62,GPT 3.54,Claude 3.52,相互之间没有显著差异。专用工具一组:OpenEvidence 3.24,UpToDate 3.17。顺带也测了谷歌搜索的AI Overview——3.27,和两个专用工具基本持平。
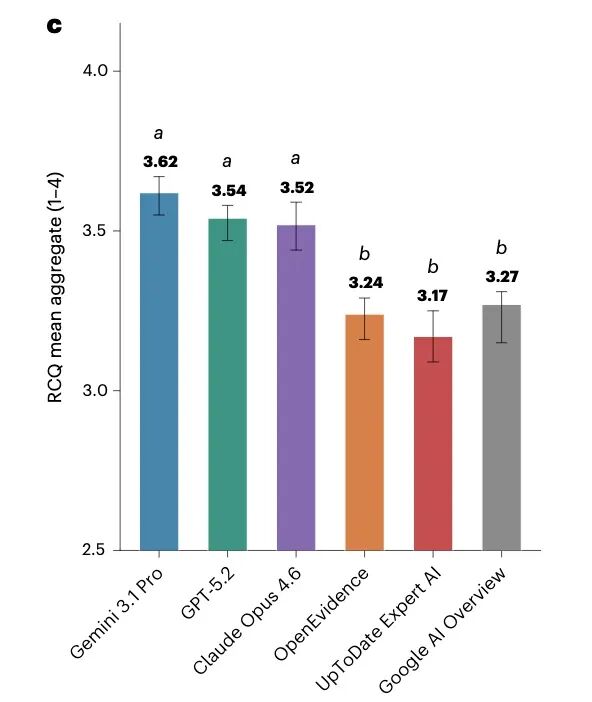
换句话说,医生花699美元一年订阅的医疗AI,在真实临床问题上,和直接开着谷歌搜索差不多。而它的竞争对手——GPT、Gemini、Claude——是通用模型,不需要任何医疗专项订阅费。
拒绝回答,也是一种失误
有人或许会说,专业工具更谨慎,宁可拒绝回答也不乱说,这是负责任的表现。
数据倒是确实支持这个说法的前半段。UpToDate Expert AI在100条查询中拒绝了19条,拒绝率19%,远高于通用模型(Gemini 2%,GPT 3%,Claude 1%)。
问题在于,"拒绝回答"在临床场景中并不是一个中性选项。医生查询AI,是因为他们在工作现场需要答案。如果工具选择沉默,医生并不会就此停下来,而是换一个工具,或者自己判断。五个问题里有一个被直接拒绝,对一个工作流来说,不是谨慎,是不可靠。
研究者还做了一个错误分类统计,把临床医生给低分回答时留下的文字备注整理成了七类错误。OpenEvidence在这张表里的总错误数是52,是所有模型中最多的——包括15条临床内容不完整、12条遗漏安全关键信息、13条组织混乱难以阅读。Gemini只有8条,GPT 21条,Claude 19条。
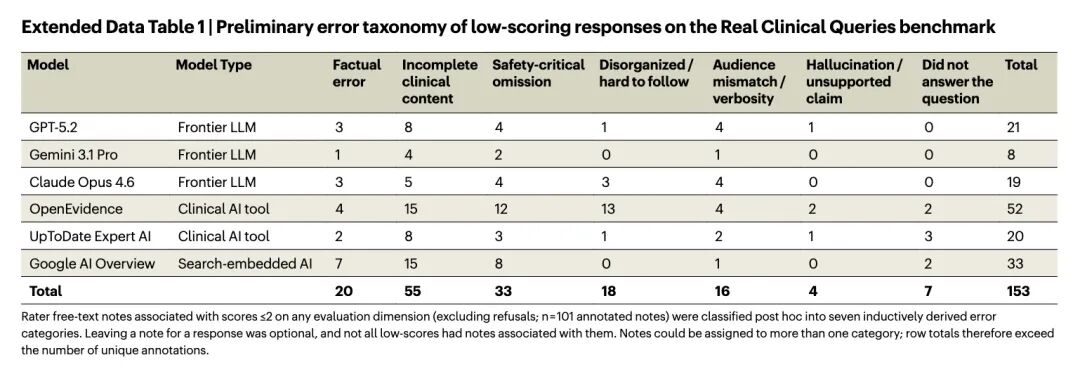
这里有个细节值得注意:OpenEvidence得分最低的维度不是"临床正确性",而是"清晰度"——这说明它的弱项可能更多在于沟通,而不是纯粹的知识。这也许是工具设计取向的问题,但对使用者来说,一个回答正确但表达混乱的工具,在繁忙的临床场景中并不好用。
专业化的技术路线,可能适得其反
这个结果让人困惑:专用临床AI工具的设计初衷,就是要在通用模型基础上通过检索增强(RAG)来调取最新的医学文献和临床指南,理论上应该更准才对,为什么反而更差?
研究者在论文中也没有确定答案,因为这两个工具的架构不公开,无法从外部做机制分析。但他们引用了自己团队之前的研究——当检索到的内容与问题不够相关,或者基础模型整合能力不足时,RAG实际上会干扰模型的判断,让回答质量下降而不是上升。
换句话说,检索增强如果用得不好,不是加分项,是减分项。
通用大模型则有另一套优势:更大的训练语料、更密集的对齐优化、以及更快的迭代节奏。医学知识本质上也是语言知识的一部分,在足够大的通用语料和足够强的推理能力面前,专项微调带来的增益可能远不如想象中显著。
研究者的观点是:至少在知识检索和多步骤推理这类任务上,规模和对齐的优势,可能比领域专项调优的优势更大。当然,他们也承认,在高度细分的专科任务(比如特定亚专科的诊断推理)上,结论未必相同。
这对医疗AI市场意味着什么
这篇论文的作者来自纽约大学朗格尼医院,他们本身就在运营一套院内HIPAA合规的GPT部署。他们做这项研究,不是学院里的纯理论讨论,而是有实际部署经验的人,在问一个务实的问题:我们采购什么,才能给临床医生用?
他们的结论是,专用临床AI工具目前在性能上并不优于通用前沿模型。这对医院采购、保险报销、监管审批都有直接含义。
不过他们也指出了几个重要的局限性。这次评测没有测试响应速度和引用质量——这两点对临床工作流很重要,而专用工具可能在这方面有优势。此外,真实临床查询数据集只有100条,是从一家医院的查询记录里采样的,不一定能代表所有场景。HealthBench是OpenAI自己开发的测试集,GPT能得最高分多少有点说不清道不明。
研究者也没有回避这一点,他们在论文里直接写道:这类由行业开发的基准测试,可能系统性地偏向开发者自己的产品。这是需要独立评估机构来填补的空白。
对于这个行业未来走向,他们的判断是:前沿通用模型在大多数知识和沟通类任务上,暂时领先于专用工具;但医院自建的、能调用本地数据的专属模型,可能是更有前景的方向。
点评
这篇论文当然有值得争议的地方。OpenEvidence 在 LinkedIn 上公开反击,指出 MedQA 题目是公开题库、大模型训练集可能早就见过答案;HealthBench 是 OpenAI 自己做的标准,GPT 在上面考最高分有点像老师自己出卷;研究团队在 NYU 医院里运营着一套自己的 GPT 系统,和 OpenEvidence 存在直接竞争关系。这些质疑不是无理取闹,论文作者自己也在文中承认了其中几条。
但有一点 OpenEvidence 没有正面回应:100道真实临床查询、12名盲审医生、1800条独立评分。那一关的数据是原创的、不在公开训练集里、也是临床医生直接打分的。这一关,专用工具输了。
更值得琢磨的是背后的结构性原因。两个专用工具都不公开自己用的是哪个底座模型。但同期另一项覆盖95个模型的大型基准测试(Nature Biomedical Engineering,2026年6月)直接说了:基于旧底座微调的医学专用模型,经常落后于更新版的通用大模型。 这不是孤证,而是一个可复现的规律。
问题的本质是速度差。OpenEvidence 创始人说他们两年前 USMLE 只考了90%,现在已经100%——这是真实进步。但与此同时,Gemini 已经是97.4%,GPT-5 更高。追赶者在跑,但跑道在缩短。通用模型的迭代节奏,专用工具系统性地跟不上,因为前者有几百亿美元的算力投入在背后,后者没有。
专用医疗AI不会因此消亡。高度细分的亚专科任务、医院自建能调取本地 EHR 数据的专属系统、合规与引用可溯源——这些是通用模型暂时填不上的空缺。但"用 RAG 把通用模型包一层、就能打出溢价"的那套逻辑,正在失效。
35亿估值的医疗AI,在临床医生眼里的表现,和直接开着谷歌搜索差不多。独立评估,比任何时候都重要。

参考资料
[1] Vishwanath, K. et al. General-purpose large language models outperform specialized clinical AI tools on medical benchmarks. Nature Medicine (2026). https://doi.org/10.1038/s41591-026-04431-5
