 夜雨聆风
夜雨聆风最近在做知识库相关的内容,有很多文件都是PDF的,但是知识库用MD格式即省token,又能做到格式统一
但PDF最大的痛点始终没变:文字无法编辑、表格错乱、公式无法复制、图文混排解析崩坏,普通在线转换工具要么格式乱码,要么直接丢失表格和图片,根本没法用于AI问答、RAG知识库搭建。
最近大火的MinerU,彻底解决了中文文档解析的痛点,也是目前圈内公认的PDF/文档结构化解析天花板。
我们不讲复杂API对接,不带繁琐代码,尝试从一个小白的角色用一篇文章带你从零彻底看懂MinerU:它是什么、强在哪、两款API怎么选、适合什么人、有哪些短板,看完再也不用盲目跟风。
📌 什么是MinerU?官方底层定位
MinerU是上海人工智能实验室OpenDataLab开源的一站式高精度文档解析引擎,GitHub星标25000+,在专业文档解析榜单OmniDocBench上,实测解析分数超越GPT-4o、Gemini 2.5 Pro等主流大模型。
它≠普通OCR文字识别工具
普通OCR只会粗暴提取文字,完全忽略排版、表格、图文逻辑;而MinerU主打结构化深度解析,读懂文档版式逻辑,完整还原全文层级关系,专门适配AI知识库、大模型二次阅读理解场景。
支持解析格式全覆盖:PDF、各类图片、Word、PPT、Excel、HTML,几乎覆盖日常全部办公文档。
🔥 核心硬核能力:碾压同类工具的底气
之所以成为知识库玩家、研究员、学生党刚需,核心靠这5项独家能力:
●
表格无损还原:复杂跨行跨列表格、财报研报复合表格,直接转为可编辑Markdown表格,而非图片,支持AI直接读取计算
●
专业公式精准识别:数理化公式自动转换成标准LaTeX格式,论文、学术资料解析零障碍
●
多语言全覆盖:支持37种主流语言,完美适配中文排版、竖版文档、繁体文档,中文适配度吊打海外同类工具
●
智能过滤冗余内容:自动剔除文档水印、页眉页脚、无关装饰元素,只保留有效正文内容
●
双模型可选:提供Pipeline轻量化模型、VLM视觉增强模型,低配电脑和高精度需求都能兼顾
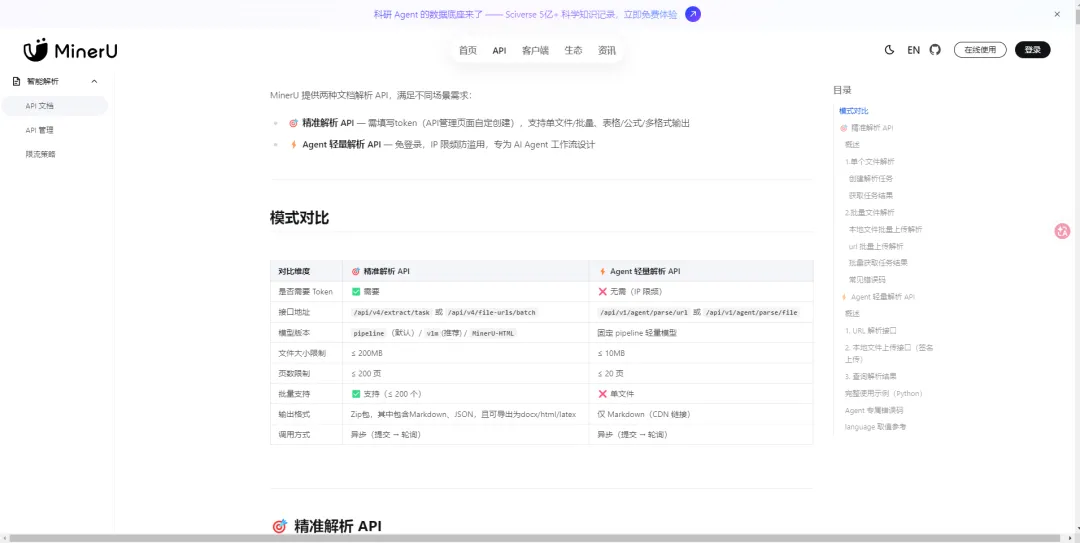
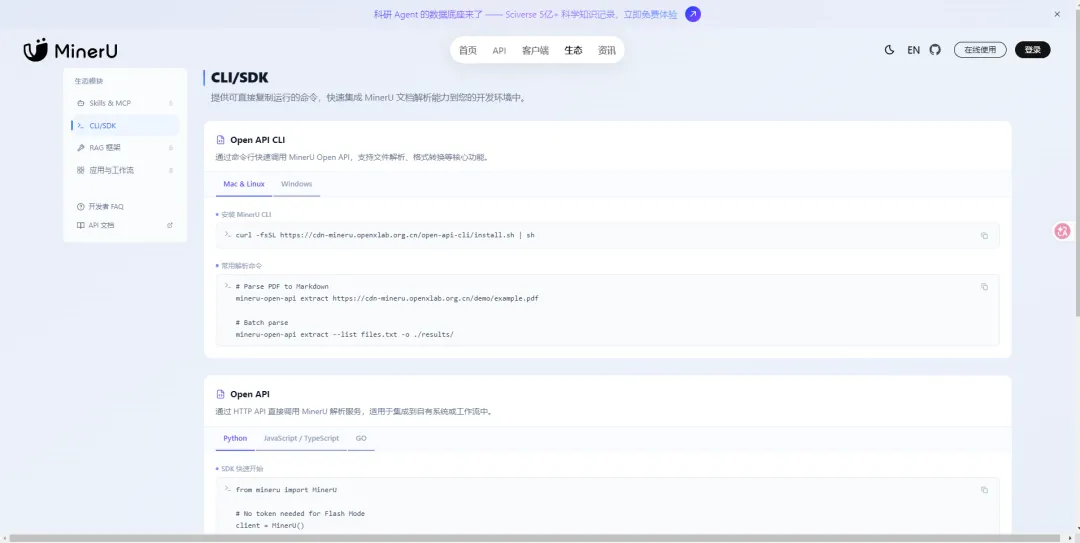
⚖️ 两大官方API怎么选?新手直接抄选型指南
很多人踩坑,都是因为选错了MinerU官方API。平台一共上线两款解析接口,定位完全不同,我整理了直白对比,新手一看就懂:
🎯 精准解析API(日常主力推荐)
●
准入要求:需要注册账号,获取专属Token
●
文件限制:单文件最大200MB,最多支持200页文档,支持批量一次性上传200个文件
●
适配场景:大容量研报、长篇论文、多文件批量转换、追求极致解析精度
●
输出格式:Markdown+JSON原生输出,额外支持导出HTML/DOCX/LaTeX
●
适合人群:知识博主、行业研究员、需要批量搭建知识库的用户
 ⚡ Agent轻量解析API(临时快速使用)
⚡ Agent轻量解析API(临时快速使用)
●
准入要求:无需注册、无需Token,零门槛直接调用
●
文件限制:单文件≤10MB,最多20页,仅支持单文件单次解析
●
适配场景:临时解析短篇文档、AI Agent快速调用、小文件应急转换
●
输出格式:仅输出Markdown,开箱即用
●
限制说明:基于IP限流,高频调用会被限制访问
一句话选型结论:长期批量用精准API,临时小文件用轻量API;长篇研报、论文无脑选精准API。
✅ 两种解析模型区别:Pipeline vs VLM
调用API时还有模型选择困惑,这里直白讲清,不用看懂专业参数:
1.
Pipeline基础模型(默认):占用资源低、解析速度快,普通纯文字、简单表格文档够用,低配电脑也能流畅运行
2.
VLM视觉增强模型(强烈推荐):依靠视觉识别复杂版式,多栏排版、图文交错、复杂图表解析能力大幅提升,研报、学术文档首选,精度最高
📊 真实实测:解析效果客观复盘(优点+硬伤)
不吹不黑,结合多份研报、论文实测,客观盘点MinerU真实表现,帮大家理性种草:
✅ 无可替代的优势
●
中文文档适配拉满,相比海外工具,不会出现语序错乱、排版颠倒问题
●
大文件稳定性强,30MB以上完整版研报也能完整解析,不会中途崩溃
●
输出格式极致适配AI,结构化Markdown完美兼容Obsidian、Notion、各类RAG知识库
●
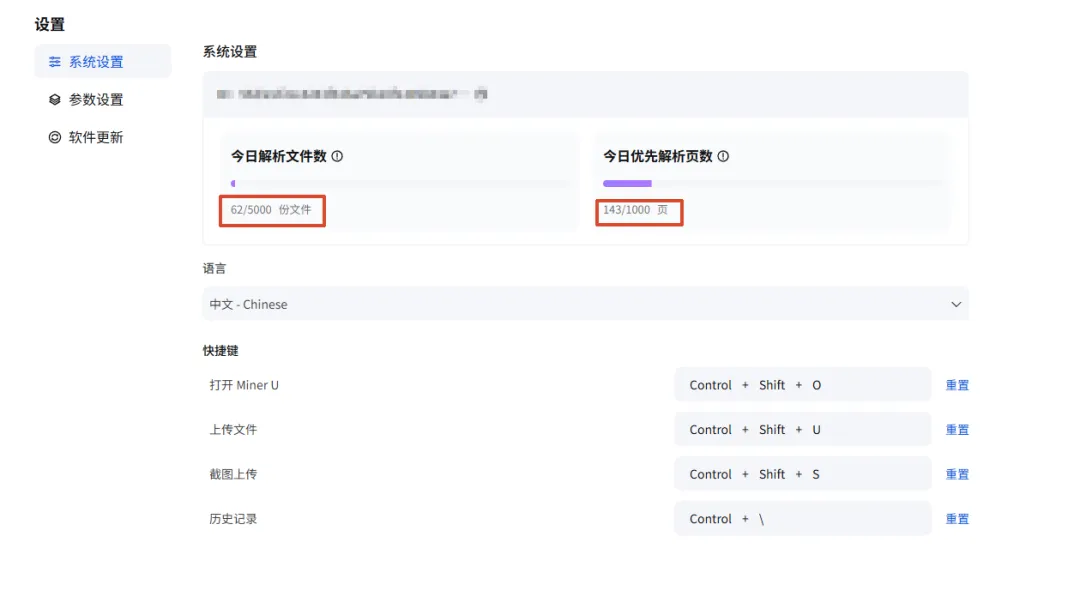
官方免费额度充足:单日最多处理5000个文件,个人日常使用完全免费
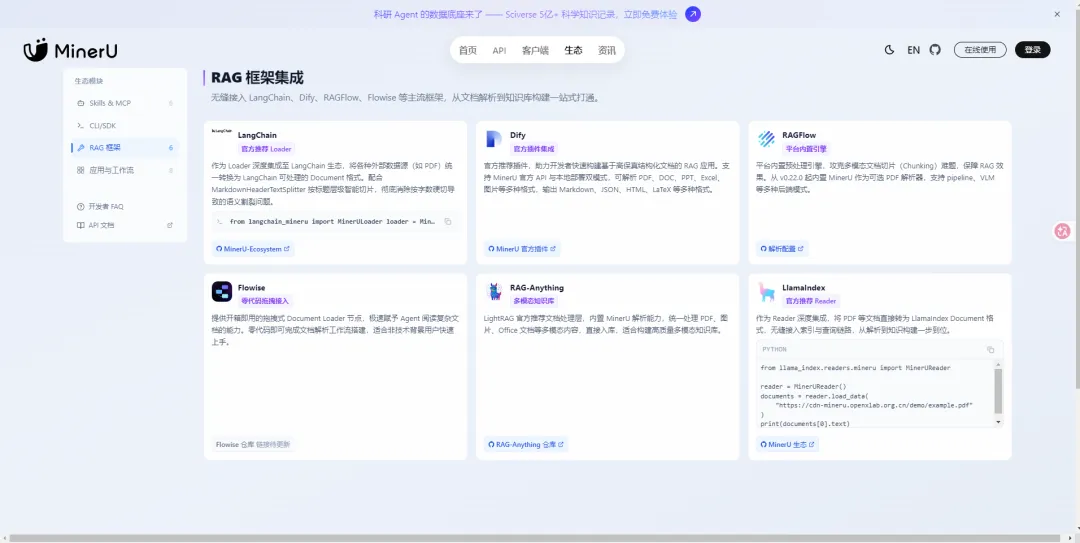
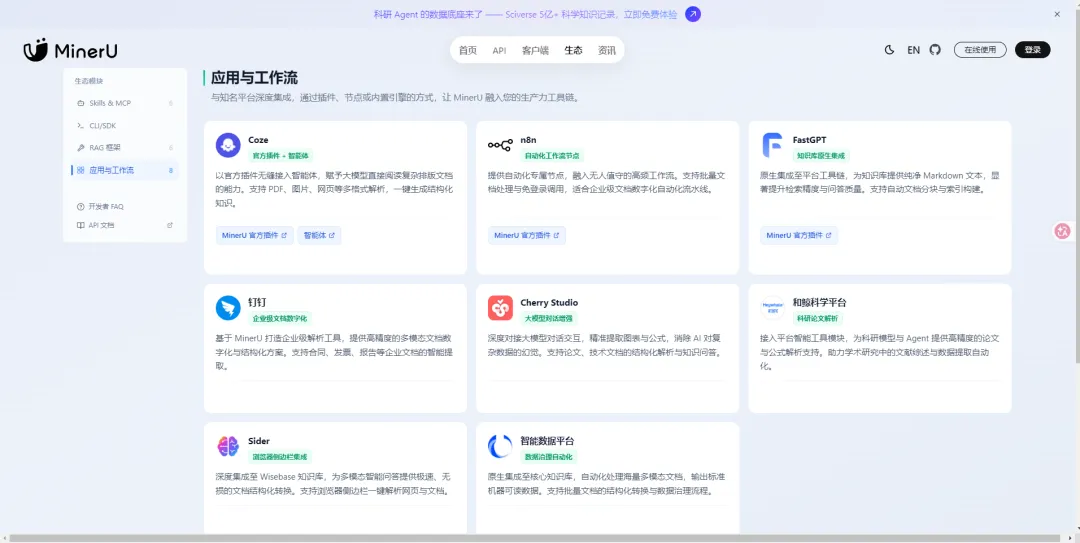
⚠️ 目前现存短板(提前避坑)
1.
排版装饰元素识别偏差:PDF纯分隔线、装饰横线会被误识别为图片
2.
截图表格过度解析:截图形式的表格,会强制转为Markdown表格,不如原图直观
3.
原生本地文件上传有BUG:官方自带本地上传通道偶尔报错文件损坏,推荐使用URL链接提交更稳定
4.
中文文件名兼容差:直接上传中文名PDF大概率解析失败,需要提前改名
👥 哪些人一定要用MinerU?
●
行业研究员:需要批量解析财报、行业研报,提取表格与核心数据
●
学生党:解析毕业论文、文献资料,提取公式与图表
●
知识库爱好者:Obsidian/Notion用户,批量把PDF沉淀为结构化笔记
●
AI办公玩家:给本地大模型投喂文档,搭建私人RAG知识库
如果你只是偶尔转一下PDF看文字,普通免费转换工具就够用;只要涉及AI阅读、数据提取、知识库搭建,MinerU是目前最优解。
📝 新手使用避坑小贴士
1.
上传前统一修改文件名为英文,规避中文文件名解析报错
2.
复杂图文文档、研报直接选择VLM模型,不要用默认基础模型
3.
大批量文件拆分时段处理,避免触发接口限流
4.
追求人工阅读美观度:解析完成后,用AI二次微调排版即可
💡 写在最后
现在大部分文档工具,都在迎合人阅读的美观度;而MinerU精准抓住了AI时代的核心需求:让机器读懂文档。
在AI知识库、本地大模型越来越普及的当下,PDF不再只是用来翻看的文件,而是AI可以读取、复盘、问答的原始素材。
如果你长期囤积PDF资料,想要打通文档和AI之间的壁垒,MinerU绝对是刚需工具。
— 光哥的自留地 —
