 夜雨聆风
夜雨聆风
冠脉斑块的定性,靠一张 H&E 经常不够。脂质坏死核心的边界、内膜里那点微小钙化,常因对比度不足被漏掉。所以病理科的标准做法是把同一段血管病变连续切片,再分别上四种染色:H&E 看整体细胞分布,EvG 评估管壁外基质重构,von Kossa 银染追踪钙盐沉积,Movat 五色染色定位脂质坏死区。
问题在于,把这四张针对同一组织、却呈现完全不同生化信号的千兆像素切片在镜下逐一对齐,再在脑子里完成多维度交叉验证,既费神,又高度依赖医生当时的经验和状态。诊断一致性常常因此打折扣。最近,慕尼黑亥姆霍兹中心、慕尼黑工业大学和德国心脏中心等机构联合做了一项工作,给这个老问题提供了一条计算病理学的新思路,成果发表在 npj Digital Medicine。
它提出了一个叫 UNICORN 的深度学习架构来处理多染色数据;它放弃了过去算法简单拼接特征的做法,转而贴近病理科多学科会诊的思路;它在切片缺失这种临床常态下表现得相当稳,甚至在没被告知五个分期先后顺序的前提下,隐式还原出了斑块的自然演进过程。
01 /推文概览与研究基底
一句话概括:这是一个端到端可训练的双阶段自注意力模型,先提取每种染色各自的特异性表型,再做跨染色的特征融合,最终对冠脉粥样硬化的五个病理阶段做自动分级。
先看数据底座。研究依托慕尼黑心血管研究生物样本库 MISSION 队列。样本库登记了 177 名已故个体的冠脉组织,平均年龄 64 岁,男性占 66%,女性占 34%,平均 BMI 28。取材很细,每人覆盖右冠近端与远端、左主干、左前降支近端与远端、左回旋支近端与远端共 7 个有代表性的节段。经过质控、剔除 5 例染色不合格的样本后,真正进入分析的是 170 名个体、1045 张组织切片。
每个节段都做连续切片,分别上 H&E、EvG、von Kossa、Movat 四种染色,各自承担不可替代的显影任务。两名资深生物医学专家综合看完四种切片后,按改良版 AHA 分类和 Virmani 等人的斑块形态学体系,把切片分成 5 个严重程度递增的阶段,这 5 个阶段就是模型要学的临床基准。适应性内膜增厚 AIT,表现为平滑肌细胞和细胞外基质构成的内膜弥漫增厚,没有明显脂质堆积或炎症浸润。病理性内膜增厚 PIT,内膜里开始出现细胞外脂质池和巨噬细胞等炎症细胞,但还没有真正的坏死核心。再往后是脆弱期,分早晚两期纤维粥样斑块。早期纤维粥样斑块 EFA 以薄纤维帽和正在发育的脂质核心为特征;晚期纤维粥样斑块 LFA 坏死核心更大、炎症更重、胆固醇结晶更多。最后是钙化纤维粥样斑块 CFA,坏死核心内出现镜下或肉眼可见的钙化,细胞密度因钙盐占位而下降。
和已有方法最大的差别,在于它怎么融合这些异构的多模态特征。处理千兆像素级的 WSI 时,受内存限制,常规做法是多实例学习 MIL:用预训练的视觉提取器把切片切成小块、压成特征向量,再汇总给分类网络。碰到多染色,过去多数团队走的是早期融合,直接把四种染色的底层特征向量拼在一起,凑成一个超高维向量喂给分类器。这条路在病理逻辑和算法逻辑上都有缺陷。四种染色的显色机制和空间分布差异极大,硬拼在一起,特征会在高维空间里互相干扰、彼此淹没。模型很难分清哪一维对应 H&E 揭示的细胞核密度,哪一维对应 Movat 暴露的脂质沉积边界。UNICORN 的破题点就在这里:给每种染色配一个独立的处理模块,先在模块内部把单一染色的信息提纯,再把浓缩后的结论送进全局聚合网络做高层研判,从源头上避开了不同染色特征在早期高维空间里互相干扰的问题。
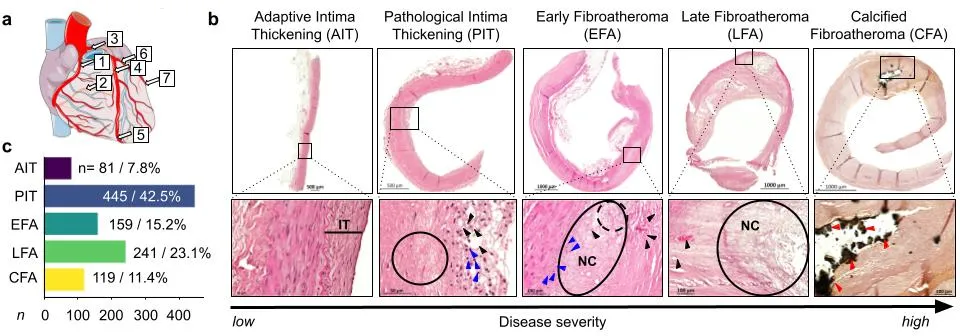
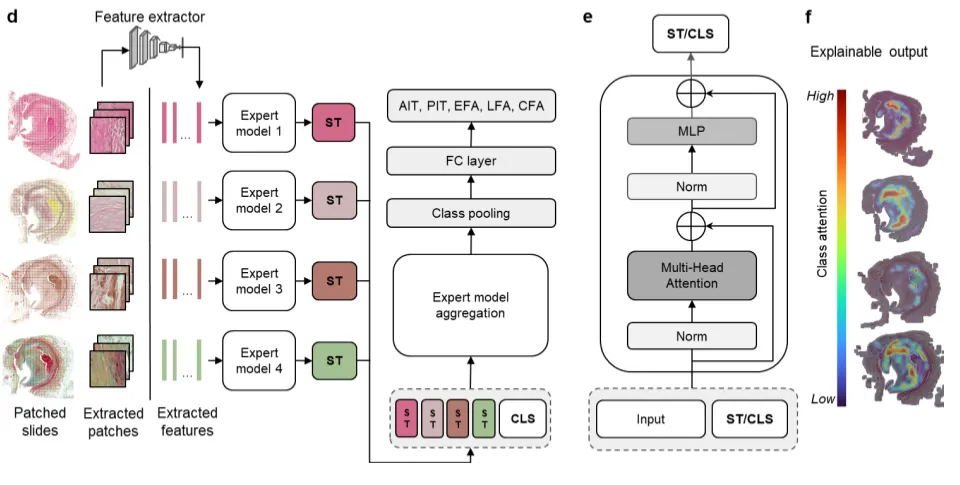
图注:UNICORN 的整体架构与 MISSION 样本库。a 展示研究取材的冠脉节段分布;b、c 给出五个病理分期的组织学示例和在队列中的占比;d 到 f 是模型主体,四种染色的特征分别送进对应的专家网络,各自输出一个 stain token,再由聚合网络汇总进 CLS token,经全连接层得到分期得分,并能输出跨染色的可解释热图。
02 /核心创新点
一:基于双阶段自注意力的专家聚合架构
在大医院病理科或心血管疑难病例讨论里,给一个复杂的易损斑块定性,很少靠一个人拍板。常规流程是几位不同亚专科的主治分别独立阅片,再由科室主任汇总各家意见、权衡证据轻重,出最终报告。UNICORN 的结构,可以类比成这套会诊机制。
道理不难想。如果硬让一张神经网络同时学会读 H&E 的细胞核排列、EvG 的胶原网状结构、von Kossa 的黑色钙化点、Movat 的黄绿色脂质池边界,参数更新很容易陷入目标互相打架的状态。就像逼一个医生在同一瞬间用四种专业视角去解析同一块组织,结果往往是哪种都看不透。面对高度异构的医学图像,指望一张网络当全能选手,通常事与愿违。
双阶段架构把这件难事拆开了。第一阶段设了 4 个结构相同的专家子网络,每个由 2 层、4 个注意力头的模块构成,相当于 4 位只盯一种染色的资深主治。以 H&E 专家为例,它只接收切成 256×256 像素的 H&E 图像块特征,靠模块内部的自注意力,在成百上千个小图像块之间找结构关联,比如某处密集的炎性浸润。
每个专家处理完自己那张切片,会对外输出一个高度浓缩的信息载体,也就是 stain token。打个比方,它像一位主治认真阅片后提炼出的一页核心意见,把这种染色里的关键病理线索都收了进去。
第二阶段是一个聚合网络,角色相当于有全局视野的科室主任。它不再去碰庞杂的原始图像块,只专门审阅那几份 stain token 形式的意见。这里用的是跨 token 的自注意力,让聚合网络动态评估不同染色的意见在当前任务里的相对权重。比如怀疑目标是钙化为主的晚期斑块时,它会自动调高 von Kossa 意见的采信权重,相应压低主要反映一般结构的 H&E 的权重。最后,聚合网络把综合判断收进一个全局的 CLS token,送进全连接层,给出 5 个分期的分类得分。每种染色都在不受干扰的环境里贡献自己的诊断价值,这是这套模块化隔离加高层融合设计的好处。
二:应对临床真实数据缺失的随机域丢弃机制
理想实验室里,每份样本都能凑齐四种染色。真实临床不是这样。脱片、染液污染导致切片报废、出于控费只开了部分基础染色,集齐四张完美切片反倒是少数。一个模型如果遇到某种输入缺失就报错罢工,或者性能直接跳水,那它实验室跑分再高,临床价值也接近于零。
研究团队的应对,是在训练阶段加了一道 70% 概率的域丢弃。训练里成千上万次迭代,算法会像个苛刻的教官,用随机数高频、无规律地抽走四张切片里的一张、两张甚至三张特征,逼模型在信息严重残缺时照样给出预测。为了不让训练彻底崩,底层留了个兜底:每一轮无论怎么抽,至少保留一种染色作为依据。
这么练下来,UNICORN 不会对某一种染色产生路径依赖,也就不会养成只靠某张信息量大的染色一把梭的惰性。真正部署时,哪怕数字病理系统只丢进来一张 H&E,模型也能靠既往学到的知识稳定运行,给出有参考价值的结果。更关键的是,聚合网络底层是处理序列的 transformer,天生能适应输入数量的变化。来四份意见也好,只来两份也好,它都能动态调整权重分配,从残缺信息里尽量多挖诊断价值。这种鲁棒性,给模型未来在资源条件不一的各级医院落地,扫清了一道工程障碍。
三:特征提取与决策归因的双重可视化热图
医疗 AI 推广时,深度学习常被质疑是不透明的黑箱。一个系统只丢给你一个分类结果,却说不清它凭什么得出这个结论,那在关乎治疗方案的决策里,医生没法信它。
要破这层信任壁垒,得让算法能解释自己,在镜下视野里标出它据以下判断的具体病灶。研究团队为此做了两件事。一是用注意力回滚追踪模型在两层特征提取里的注意力流动,二是设计了一种针对特定类别的注意力热图生成机制。
具体算法是把模型对每个小图像块的注意力权重,乘上模型仅凭这一块预测出某个疾病类别的概率得分。靠这套流程,UNICORN 能给医生出三张视觉导航图。第一张回答模型看向了哪里,标出它认为整张切片里信息最密集的区域。第二张回答某个病变表型出现在哪里,比如用特定颜色圈出疑似坏死核心或纤维帽增厚处。第三张是最有用的类别注意力图,回答模型究竟是因为看到了哪片组织,才下了当前这个分级判断。
从底层特征到高层决策的这套透明映射,既能和病理医生的肉眼经验相互印证,在容易疲劳的阅片环节,高灵敏的热图还能把人眼容易漏掉的微小改变挑出来。把决策过程摊开给人看,能实实在在提高临床对算法输出的信任。
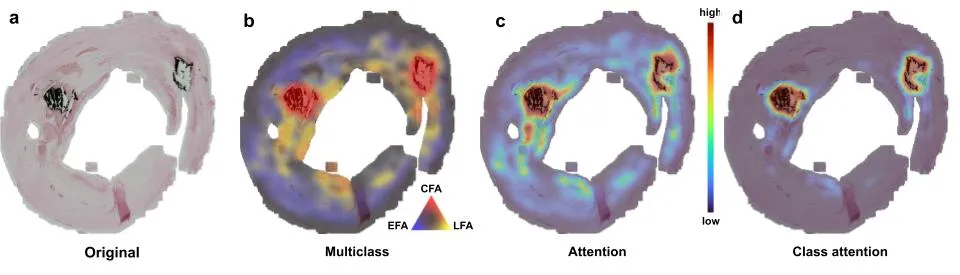
图注:高分辨率热图标出影响分类决策的关键区域。原始 von Kossa 切片显示黑色钙化区;多类别图用颜色标记最严重几类病变对应的结构;注意力图给出模型的高关注区域;类别注意力图把注意力权重和预测类别概率相乘,直接指向模型据以下判断的组织位置。
03 /关键数据与结果解析
要客观评估 UNICORN 的真实效能,研究团队在患者层面做了严格的数据切分,用 5 折交叉验证,按 60% 训练、20% 验证、20% 测试划分。这里有个关键的防泄漏处理:同一名患者的 7 个节段必须全部进同一个集合,不允许某人的左前降支切片在训练集、右冠切片却跑到测试集。这样就堵住了因患者自身生物学特征相似而刷出来的虚高分。
在多染色冠脉病变分级这个核心任务上,UNICORN 接收全部四种染色时,测试集总体准确率 0.68,宏平均 F1 0.66。这两个数字单看不算亮眼,得放进对比里才看得出意思。先说任务本身有多难:5 分类,随机猜的基线只有 0.20,相邻分期连资深专家都常常分不清。再看三条对比基线,它们都是把四种染色特征直接拼接当输入。经典的 AttentionMIL 只有 F1 0.41、准确率 0.51;Perceiver 稍好,F1 0.53、准确率 0.57;排第二的标准单阶段 transformer 做到 F1 0.62、准确率 0.64。UNICORN 对这三者的优势都有统计学显著性。
需要实话实说的是,UNICORN 对那个单阶段 transformer 的领先幅度并不大,作者在讨论里也直接用了 marginal 这个词。它的价值更多落在另外两件事上。其一,跨四次重复交叉验证,UNICORN 的标准差是 0.04 和 0.05,在几条基线里属于偏小的一档。其二,也是更要紧的,它额外给出了染色重要性的可解释信息,这是单纯拼接特征的基线给不了的。
拆到 5 个分期看,数据更贴合临床演进规律。在最早期的 AIT 上,标准 transformer 以 F1 0.45 略微领先 UNICORN 的 0.43。这在工程上说得通:AIT 的判定主要靠 H&E 下细胞密度的细微变化,还没牵扯多组分的复杂交互,单阶段网络直接处理单一核心特征,效率反而可能略高。但疾病往后走,进到脂质池、巨噬细胞、坏死核心、钙化多重成分叠加的阶段,多染色融合的优势就出来了。在 PIT、LFA、CFA 这三个临床风险和诊断难度都更高的阶段,UNICORN 稳定领先基线。最重的 CFA 上,它的 F1 做到 0.87、精准度 0.89、召回 0.84。还值得一提的是,模型大多数误分类都落在时间线上紧挨着的相邻分期之间,比如早晚期纤维斑块的临界点难划清,这和资深病理专家在镜下的诊断痛点一致,侧面说明模型抓住的是真实的病理形态特征。
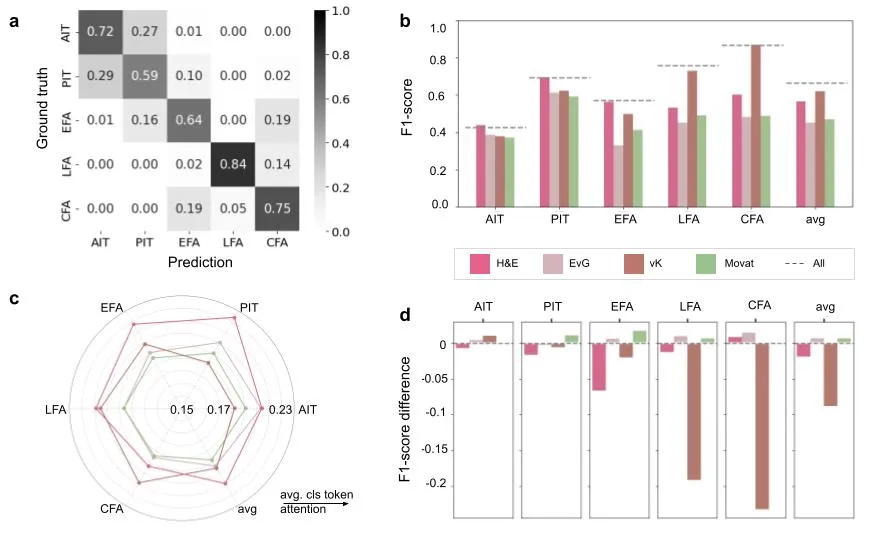
图注:UNICORN 对四种染色信息的整合效果。混淆矩阵显示模型对五个分期的区分情况;柱状图对比单染色与全染色输入下的 F1,全染色表现最好;雷达图和消融柱状图相互印证,反映出 von Kossa 对晚期钙化识别的决定性作用,以及 H&E 在早期内膜病变评估中的核心地位。
为了更细地看模型对各染色的依赖,团队做了逐一剔除的消融实验,这个设计对临床很有操作指导意义。结论是:单染色输入也能维持基本分级,但聚齐四种时性能最好。推理阶段人为剔除染色,性能按梯度下滑。平均来说,少任意一种,整体 F1 掉 2.3%;少任意两种的组合,掉 6.3%;只留一种、也就是少三种的极端情况,掉 13.5%。
再看聚合网络的注意力权重,模型对组织病理的理解和人类教材里的常识高度吻合。判断一个病变是不是钙化为主的 CFA,或是胆固醇结晶多的 LFA 时,聚合网络给 von Kossa 意见的权重明显抬高,这正对应银染专门高亮钙盐的化学特性。区分相对早期的 AIT 和 PIT 时,模型把注意力主要压在 H&E 上,因为这一阶段的鉴别关键就是细胞排列密度和基础组织结构的细微差别。
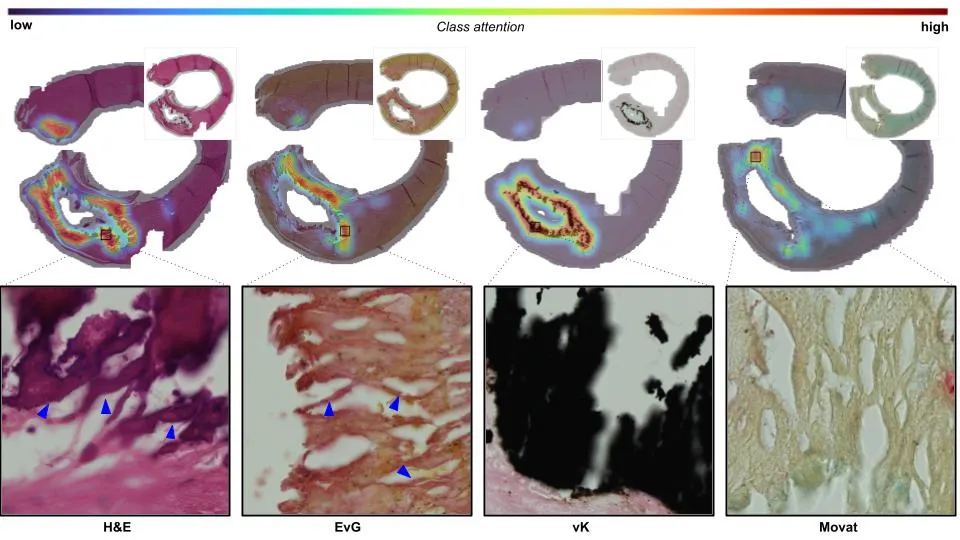
图注:UNICORN 在四种染色上标出与分类相关的特异区域。这是一个 CFA 案例,红色为最高类别注意力区。H&E 和 EvG 上用蓝色箭头标出最相关结构;von Kossa 的放大块显示内膜内的钙化沉积;其余染色呈现以细胞外脂质和细胞碎屑为主的脂质坏死核心,核心外覆盖由平滑肌细胞、胶原和其他细胞外基质构成的纤维帽。
团队还安排了一场和人类专家的正面对比,看模型够不够临床及格线。他们从测试集里随机抽了 15 个有代表性、符合真实病患分布的完整多染色样本,交给一位没参与过任何标注和清洗的第三方资深专家做独立盲测。在这个规模小、难度大的子集上,UNICORN 拿到 0.80 的准确率和 0.80 的宏平均 F1;人类专家是 0.53 的准确率、0.48 的 F1。作者在文中态度很克制,专门提醒:盲测样本量小,专家之间本就存在认知差异,这组悬殊的数字不能拿来说 AI 可以取代病理医生。但它确实说明,模型在统一诊断标尺、压低疲劳和经验差异带来的主观波动上,已经具备做高阶辅助工具的潜力。
还有一个挺巧的注意力对齐实验。研究者给专家看测试集的全景切片,随机标出 5 个小图像块,其中 2 个是算法给了高注意力权重的,3 个是低权重的干扰项,请专家凭经验挑出 2 个最具诊断意义的区域。结果是:69.5% 的切片里,专家选的两个关键区域和 UNICORN 算出的高注意力区域完全重合;另有 22% 的切片,专家至少选中一个和算法一致;两者彻底分歧的只占 8.5%。补充材料还显示,Movat 和 EvG 的一致性最高,von Kossa 最低。这么高的吻合度说明,算法学到的是真正有病理价值的组织形态,看的地方和资深医生看的地方基本是同一处。
04 /延伸讨论与临床落地前瞻
模型隐式建模带来的疾病认知新方向
整篇研究里,最让临床科研人员上心的信息增量,与其说在准确率涨了几个点,不如说在模型把动脉粥样硬化的自然演进过程隐式理解了出来,而且全程没有依赖任何人为设定的时序规则。在延伸分析里,团队用 UMAP 这种非线性降维,配上单细胞测序常用来描绘分化轨迹的拟时间分析,对模型出最终分类前那一层的高维特征做了可视化。验证用的是一个额外的内部扩展数据集,覆盖 114 名个体、768 个血管节段。映射出来的二维图谱里出现了一个值得注意的现象:散落的组织样本自发排成了一条连贯、有方向的发展轨迹。轨迹从最起始的 AIT 出发,平稳过渡到 PIT,再依次穿过早、晚期纤维斑块,最后落到代表晚期终局的 CFA。
要知道,在此之前研究者只给了模型 5 个离散的分类标签,从没告诉它这 5 类在真实血管的时间维度上有先后递进关系。模型完全是靠自己学海量斑块在不同阶段的形态变化和基质演变,在潜变量空间里独立重新发现了斑块生长的自然病程。更有临床指导意义的是,哪怕限制它只用一种染色作输入,它照样能拼出一条符合逻辑的疾病演化序列。这说明模型提取的特征扎根在疾病背后的生物学本质里。往前看,这给医疗 AI 提示了一个方向:未来的多模态模型也许能跳出离散分类标签,通过测量一个新发斑块在这条连续轨迹上的坐标点,给临床更靠前的个体化进展预测,帮医生在斑块破裂前就介入。
UNICORN 的跨病种泛化潜力也值得一提。在没改任何底层代码、没重调图像分辨率、连网络参数都没动的情况下,团队把它直接迁移到一个独立的乳腺癌数据集,去预测 HER2 阳性乳腺癌患者新辅助化疗后的病理应答。初步结果是 F1 0.69、AUC 0.70。这说明这套基于各染色独立专家加高层聚合的框架,没有过度拟合到心血管数据上,有望成为计算病理处理多模态异构图像的通用骨架。不过作者也标注了,这只是 preliminary 结果,而且乳腺癌迁移里同样暴露了特征提取器的局限,这一点放到下面一起说。
局限性
特征提取器的认知边界。研究用的预训练视觉提取器 CTransPath,主要是在海量 H&E 公共数据集上预训练出来的。换句话说,这个初级视觉引擎的知识库里,从没真正见过 Movat 的黄绿色或 von Kossa 的黑色沉淀。靠深度网络的泛化能力,它能勉强提出其他染色里的边缘和纹理,但对这些特殊染色底层生化逻辑的理解,远不如它对 H&E 那么透。这种先天认知缺陷,压住了模型处理非常规补充染色时的性能上限,乳腺癌迁移测试里也观察到了同样的趋势。要突破这道精度瓶颈,下一步多半得换上覆盖多种染色、用更大规模无监督预训练出来的病理基础大模型。
判定基准里潜在的人口学偏倚。当前 MISSION 样本库的切片,绝大多数来自平均年龄偏高的已故患者,男性数量大约是女性的两倍。现实里,斑块形态、脂质沉积速率、血管重构规律在不同性别、种族、年龄段之间存在明显的生物学异质性。模型在这批数据上学到的演进规律和诊断阈值,遇到年轻的早发女性患者或代表性不足的族裔样本时,灵敏度可能出现未知方向的漂移,进而牵出医疗公平性的隐忧。
模型对特定染色组合之间复杂交互的理解还有小盲区。消融实验里有个反常现象:在少数几类预测任务上,人为屏蔽掉 Movat 或 EvG,模型综合性能反而有极微弱的提升。这个反直觉的结果提示,在某些结构特别复杂的病变区域,辅助染色带来的微弱信号或者染色背景噪声,可能被现有特征提取器当成了系统性干扰,误导聚合网络的权重分配。怎么从算法底层优化注意力,让它更聪明地自动过滤掉低质量、相互矛盾的补充染色信息,是下一步要啃的硬骨头。
UNICORN 在理论上证明了多种异构染色的病理数据能在计算空间里做深度语义融合;它那套贴合临床会诊思维的双阶段聚合架构,也给业界指了一条解决多模态数据缺失和特征干扰的工程路子。随着数字病理硬件逐步普及、多中心规范化数据慢慢积累,这类能兼顾全景视野和跨染色交叉验证的架构,比较有机会先以高级分诊过滤或辅助阅片插件的形式进到各级医院的工作站,承担批量切片的前期质量筛查、多染色对齐聚合和可疑病灶的热图标注,给病理医生递上一份带溯源证据链的初筛报告,把诊断效率和质量下限往上托一托。
原文出处:Koch, V., Bauer, S., Mahajan, S. et al. UNICORN: a deep learning model for integrating multi-stain data in histopathology. npj Digit. Med.
— END —
