 夜雨聆风
夜雨聆风一个在重构旧模块,一个在补测试,一个在改文档。三个都在飞速地写、改、提交。我坐在中间,盯着三块屏幕,脑子里只有一个念头:我到底该看哪一个?
那一刻我意识到一件有点反常识的事。我以为让 AI 替我干活,是把活从我手里拿走了。结果不是。它把我从"写代码的人"变成了"盯着三个写代码的人的人"——而盯,恰恰是我最不擅长、也最不能并行的那件事。
自动化"做",没有解放我,反而多了三个要监督的 loop
先把话说透。Claude Code 能同时盯十件事,我一次只能盯一件。这不是我菜,这是带宽——人的注意力本来就是串行的。
更要命的是,有些东西无论 AI 跑得多快都不会从我身上转移走。这个项目到底想干嘛、哪些约束不能碰,只有我知道;先修哪个、哪个可以拖,得我排。但真正焊死在我身上的是两样:一个改动该不该合,是我拍板,不是它;最后这玩意儿到底对不对,签字的人还是我。判断权和验收权,AI 再快也接不走。
所以当我把"执行"自动化掉之后,我的负担没减,它只是换了个形态——从"我亲手做一件事",变成了"我得监督 N 个自己跑的 loop"。说白了,我把搬砖外包了,结果给自己招了一个需要时刻盯梢的包工队。
行业里现在很热闹。Vibe Kanban 给你一块看板,Claude Squad 帮你把一堆 agent 并行派出去——工具越来越花,可它们解决的全是同一个问题:怎么让你跑更多的 agent。没有一个在管那个真正稀缺的东西——盯着这些 agent 的那一个人。说白了,大家都在拼命加宽马路,没人问开车的还剩几只眼睛。
这就是我做 evolve 的起点。但 evolve 真正的设计重心,其实不在它能自动干多少活,而在它怎么决定要不要来烦我。
evolve 一轮在做什么
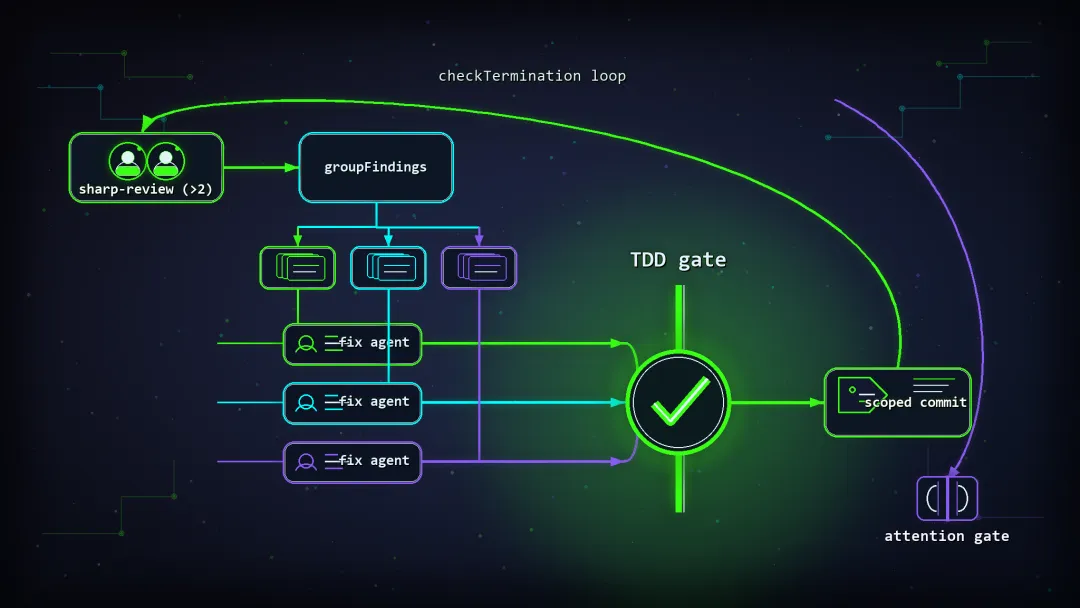
/evolve 是一个 Claude 驱动的迭代 review→fix loop。每跑一轮,代码就往"干净"挪一步。我把一轮拆成这么几步:
第一步,锐评。 我让它去跑 sharp-review——这是我之前已经做好的另一个插件,专门干"锐评"这件事,至少两个独立 reviewer 并行审同一份代码加 diff。为什么至少两个?因为一个模型审自己刚写的代码,等于让贼来抓贼——它逮不住第一次就没逮住的东西。两个不同的脑子打架的地方,往往就是真 bug 藏身的地方。审完出一份按严重度排序、去过重的 OPEN findings 列表。
第二步,并行 fan-out 修复。 这里有个我特意写的细节。我用 groupFindings 把所有 findings 按"碰到的文件"切成不相交的连通分量——保证没有两个 agent 会去动同一个文件,然后每组开一个 agent 并行修(默认上限 8 个)。要是某个改动横跨一大片文件,我宁可让它退化成一个串行 agent,也不让两个 agent 在同一个文件上打架。
第三步到第六步,收尾。 剩下没修的,逐个归类:是误报、是故意为之、还是超出范围、还是得我做架构决策。然后是 TDD gate——我先探测出项目的测试命令,全绿才允许提交。这里我还卡了一道:全局测试绿,只是必要条件,不是充分条件。一条声称"修好了"的 finding,我会单独再验它一次,没真闭合就打回 OPEN。
第七步,提交。 我坚持用按文件的 git add,从不用 git add -A。你手头那些跟这轮无关的改动,evolve 一个字都不碰。提交信息走 conventional 格式,碰到 main/master 这种保护分支,自动跳过提交。就这么死板——我宁可它什么都不提交,也不愿它替我把一堆没看过的改动一锅端进去。
还有一个让 loop 能收敛、而不是空转的关键:收敛是按严重度算的。只有新冒出来的 HIGH/MEDIUM findings 才会重置"空轮计数器"。因为 LLM reviewer 永远能挑出鸡毛蒜皮的 nits,要是按"还有没有 findings"来判断,这 loop 能在小毛病上 churn 到天荒地老。一条卡了 unfixedRounds=3 还没修的,直接升级给我。
这套"跑一轮、看结果、再跑一轮、到条件就停"的结构,本质上是把我从"亲手 prompt 每个 agent"里拔出来,去设计那个替我 prompt 它们的系统。这正是最近被反复讨论的那件事——一个像样的自动 loop 要有明确目标、工具、上下文管理、终止逻辑、错误处理。前面这些 evolve 都有:checkTermination 是终止逻辑,rem 给的是跨轮持久化,TDD gate 是错误处理。但还有最关键、也最容易被一笔带过的一条——知道什么时候把控制权交回给你。这一条恰恰是 evolve 的整个设计重心,也是我下面要重点讲的。换句话说,evolve 不只是又一个自动 loop,它把那个最被忽略的"交还"动作,做成了主角。
讲到这你可能发现了:上面这一整套,确实把"做"这件事自动化了。可它没解决我开头那个问题——它只是把我的负担从"做"挪到了"监督这一整轮"。每一步都可能蹦出一个需要我拍板的岔路口。如果每个岔路口它都来问我一句,那我跟同时盯三块屏幕,有什么区别?
真正的设计中心:attention gate
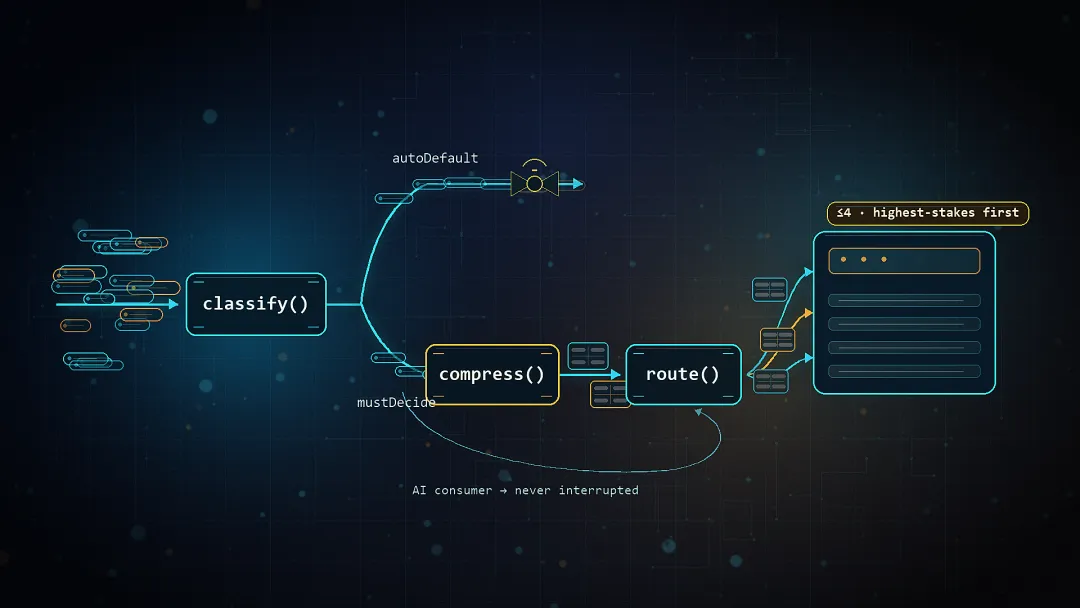
所以我做了一道前置层,shared/attention.mjs。先说它为什么非存在不可。
上一节那套 loop 跑得越顺,越会暴露一个新麻烦:它每一步都可能撞上一个需要我拍板的岔路口,而它本能地会把每个岔路口都丢给我。一个能自动干一百件事的系统,要是顺手也把一百个问题甩到我脸上,那它省下的执行力,全被它制造的打扰给吃回去了。所以光有"会做"的闸还不够,我得在它和我之间再加一道闸:任何技能想花我的注意力,都不能直接花,必须先过这道闸。
这道闸的活儿很纯粹——保护接收端那个稀缺资源。如果接收端是人,就把我的注意力花到最省;如果接收端是另一个 AI(headless 跑、被上层编排器调用),那边压根没有稀缺的注意力要保护,那就别装模作样地弹窗——给 AI 弹确认框,纯属对空气鞠躬。
而要把"花到最省"落地,闸门内部干三件事:先把不值得打扰的拦下来,再把剩下的压瘦,最后把它们攒成一次问。
先说拦。classify() 把每一条要升级的事项分成两堆:
/*** Split items into those a human must decide vs those safe to auto-default.* autoDefault = reversible AND has a default AND not HIGH stakes.*/export function classify(items = []) {const mustDecide = [], autoDefault = [];for (const it of items) {const hasDefault = it.default !== null && it.default !== undefined;const safe = it.reversible && hasDefault && (it.stakes || 'MEDIUM') !== 'HIGH';(safe ? autoDefault : mustDecide).push(it);}return { mustDecide, autoDefault };}
判据就一行:可逆,而且有默认值,而且不是 HIGH stakes——这三条全中,就自动走默认,永不打扰我。我当初这么设的判据,对应的就是一笔很具体的注意力账:一件能撤销、有安全兜底、又没什么利害的事,凭什么要消耗我一次抬头?市场上现在管这个叫"风险分级"——可逆性、影响范围、合规暴露、模型置信度,四个维度,听着挺唬人。文献把它讲得很抽象,我这边就是大概 30 行可测试的纯函数,跑得过就是跑得过。
再说压。剩下那些真得我决定的,compress() 把它压成一张标准卡片,字段就这四个:
export function compress(item) {const hasDefault = item.default !== null && item.default !== undefined;return {id: item.id,headline: item.title,mustKnow: item.detail || item.title,decision: item.kind ? `${item.kind}: ${item.title}` : item.title,options: item.options || [],consequenceIfIgnored: item.reversible? 'Reversible — can be undone later.': 'Irreversible — cannot be cheaply undone.',defaultIfIgnored: hasDefault ? item.default : null,reversible: !!item.reversible,stakes: item.stakes || 'MEDIUM',};}
mustKnow 是我此刻必须知道的,decision 是我必须定的,consequenceIfIgnored 是我要是不理它会怎样,defaultIfIgnored 是我啥都不说时它会默默采用的安全兜底。我想要的是:你别给我倒一整页上下文,把我必须知道、必须决定、不决定的后果,压成我扫一眼就能拍板的三四行。让我读完一张卡片的工夫,比读完一条微信还短。
最后说问。route() 把真正需要我的那些,按利害从高到低排序,合并成一个AskUserQuestion——最多 4 题(这是 Claude Code 的硬上限),剩下的溢出到下一轮再问。
// human: surface highest-stakes decisions first, overflow the rest.const ordered = [...mustDecide].sort(byStakesDesc);const shown = ordered.slice(0, MAX_QUESTIONS);const overflow = ordered.slice(MAX_QUESTIONS).map((it) => ({ id: it.id, title: it.title }));
注意这个"合并成一个"。我最怕的不是它问我问题,而是它一会儿弹一个、一会儿弹一个。确认疲劳现在已经被正经点名成一种安全漏洞了——当审批请求来得太勤,人会停止阅读,养成不看就点"同意"的反射,跟你家那个永远直接点"全部允许"的自己一模一样。到那时候,你那道精心设计的闸门就成了纯摆设。所以我宁可把这一轮里所有需要我的决定攒成一次打扰,让我一口气拍完,也不让它把我的注意力切成碎片。
至于那个 4 题硬上限——它不是我抠门,是 Claude Code 的物理天花板。但说实话,这个限制反倒帮了我:它逼着 route() 必须排序、必须取舍,逼着这道闸把"什么最值得我看"想清楚,而不是一股脑全推给我自己挑。
不打扰我,不等于偷偷扔掉
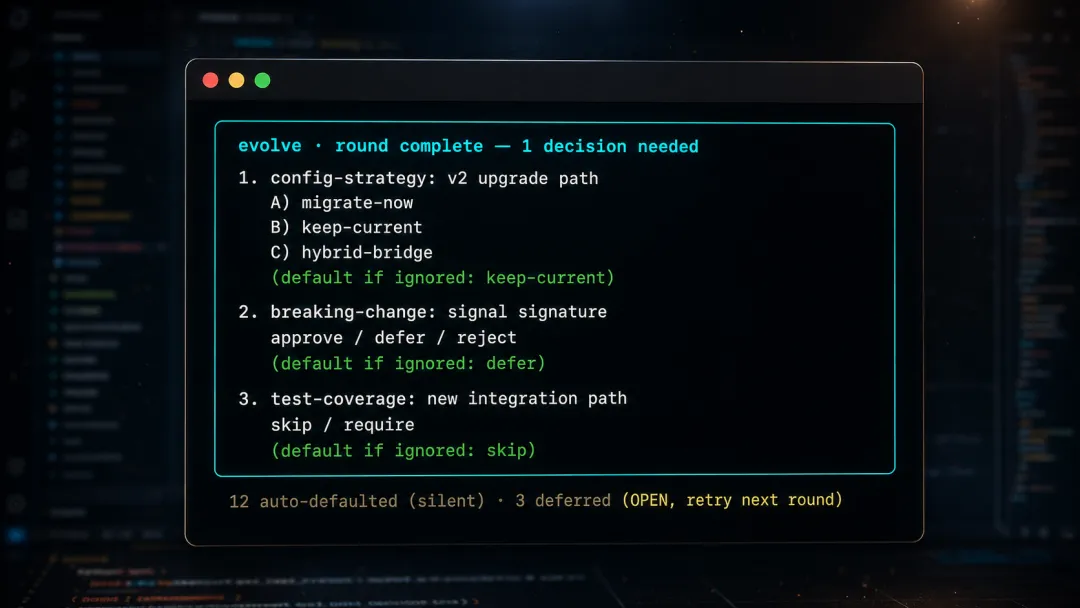
到这儿有个隐患。一道一门心思"少烦你"的闸门,最危险的失败方式是:为了不烦你,把该办的事悄悄咽下去了。低优先级的那些被默默丢掉,你还以为天下太平——直到三个月后线上爆了,你才发现它一直被"体贴"地藏着。
所以我给它配了一条硬保证:defer ≠ drop。
被 defer 的 finding(LOW 也算)不会消失,它继续躺在 backlog、todo 和 sharp-review.md 里挂着 OPEN 状态。下一轮 fan-out 照样会去重试它,不管它 stakes 多低。卡到 unfixedRounds=3 还没修,那道"卡死 finding"的上限就把它顶到我面前。这道闸管的,永远只是要不要打扰你,从来不是要不要修它——少烦你和少干活,是两码事。
在 ai consumer 那一路,逻辑也一样克制:
if(consumer === 'ai') {const deferred = [];for(const it of mustDecide) {const hasDefault = it.default !== null && it.default !== undefined;if(hasDefault) applied.push({ id: it.id, value: it.default, via: 'policy' });else deferred.push({ id: it.id, reason: 'irreversible/ambiguous, no safe default — deferred (left OPEN, logged)' });}return { consumer: 'ai', applied, deferred, prompt: null };}
有默认就按 policy 解决,没安全默认的那些不可逆、有歧义的,就 defer——留 OPEN、记日志,但绝不阻塞整条流水线。"不打扰"配上"但仍会修、且仍 OPEN 着",这俩凑一块儿,我才敢真把它放到每个技能前面。
它不是一个孤岛:evolve、sharp-review、rem、todo 是一套框架
讲到这我得把镜头拉远一点,因为只看 evolve 一个插件,会错过我真正在搭的东西。
evolve 自己并不"全能"。它硬依赖我另外三个插件,缺一个都跑不起来,而且我故意没给 fallback:
- sharp-review
负责"找"——每一轮的锐评就是它跑的,至少两个独立 reviewer 并行审,出一份去过重、按严重度排序、带稳定 SR-编号的问题清单。evolve 自己不审代码,它把"找问题"整个外包给了 sharp-review。 - rem
负责"记"——evolve 的 loop 状态( evolveState:跑到第几轮、哪些 finding 还 OPEN)就存在 rem 的.rem-state.json里;每轮的 round-log 也写成 rem 的记忆条目。跨轮、跨会话的连续性,是 rem 给的。 - todo
负责"追"——finding 的状态(open / fixed / wont-fix)以 todo和sharp-review.md为事实源,evolve 只是把状态镜像一份到自己的 state 里。
所以 evolve 更像一个编排器:sharp-review 找、它驱动修、rem 记、todo 追,四个插件咬合成一条完整的 review→fix→记忆 流水线。
但真正让我觉得"这是一套框架、而不是几个各干各的脚本"的,是 attention gate 摆放的位置。它不在 evolve 目录里——它在 shared/,被打包进每一个插件。换句话说,这道闸门从设计第一天起就不是 evolve 的私有功能,而是整套框架的公共保护层:今天是 evolve 末尾的待决项过这道闸,明天 sharp-review、rem、任何一个会消耗我注意力的插件,走的都是同一道闸、同一套 classify / compress / route、同一条 defer ≠ drop。
这才是我想要的结构:sharp-review 负责找、evolve 负责修、rem 负责记、todo 负责追,而 attention gate 是横切在它们所有人之上、统一保护那个唯一的人的那一层。执行的技能可以一个个加,但保护我注意力的方式,全框架只有一套。
我真正想进化的,是人机协作的方式
回过头看,evolve 那句 slogan 是个梗——「加入光荣的进化吧!」。它有两层意思。
表面那层,是插件让代码每一轮自己往干净里"进化"。但我真正想进化的,是另一样东西:人和 AI 协作的方式。
并行 AI 时代,大家的本能反应是逼自己追上 AI 的速度——开更多窗口、上更多看板、盯更多进度条。我觉得这条路是错的,因为它默认了那个稀缺资源是算力。不是。稀缺的从来是那一个人,是他串行的、不可并行的注意力。
所以正确的事不是让人变快,而是让 AI 学会替人省注意力——把"打扰你"当成一笔要精打细算的预算来花。可逆的小事自动放行,真要你拍板的攒成一次,该修的一件不落。判断权、验收权还在你手上,但你不用再被每一个岔路口拽住。
这就是那道闸门想做的全部:别让任何技能直接花你的注意力,让它先过这道闸。
代码在 GitHub,shared/attention.mjs 拢共一百多行,零依赖,纯函数,每个字段、每条判据你都能自己翻、自己测。
GitHub: https://github.com/DawnEver/cc-market(plugin: evolve/)
