 夜雨聆风
夜雨聆风

导读当大模型能力竞赛进入“下半场”,高质量数据的获取与治理已成为比算力更现实的技术瓶颈。北京大学大数据科学研究中心梁昊在 DAcon 大会上分享了开源项目 DataFlow——一套面向非结构化数据、以大模型语义理解为核心的工业级数据流水线。本文从数据准备痛点出发,系统拆解 DataFlow 的算子抽象、语法约束、分布式底座 RayOrch,及其在多模态、表格、知识图谱等场景下的扩展。
1. 大模型数据准备
2. DataFlow 数据准备系统
3. 多模态与多数据源支持
分享嘉宾|梁昊博士 DataFlow开源项目作者
内容校对|韩珊珊
出品社区|DataFun
01
大模型数据准备
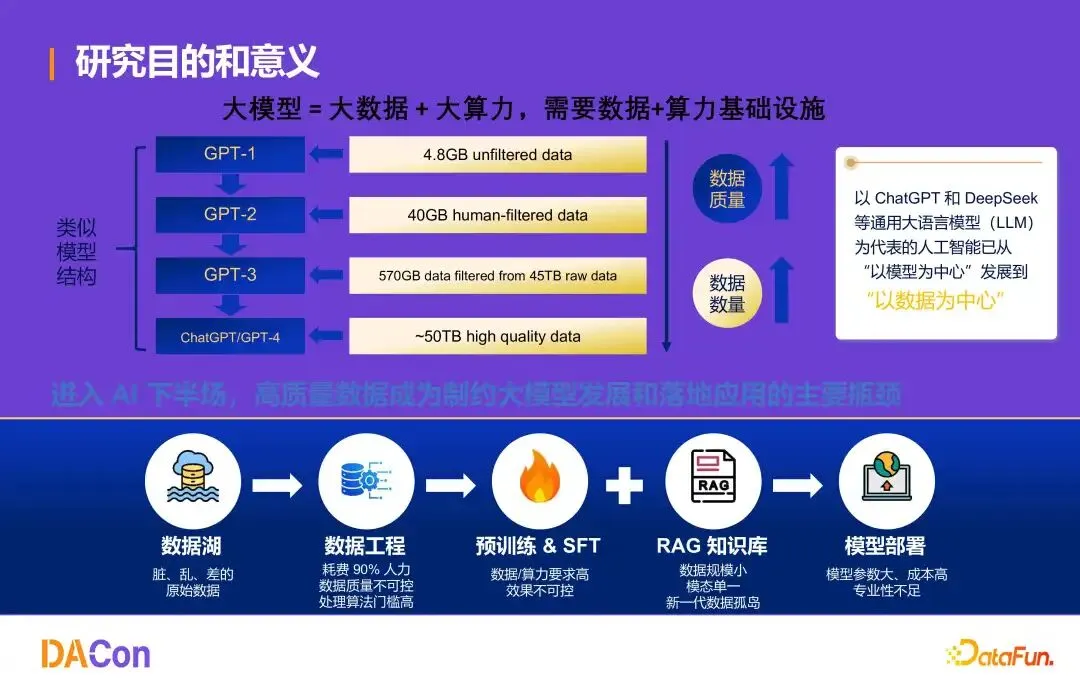
大模型时代的基础公式依旧成立:大模型 = 大数据 + 大算力。从 GPT-1 到 GPT-4,每一次能力跃升都离不开数据规模与质量的同步升级。业内共识是:构建大模型 80%–90% 的精力投入在数据工程。进入 AI 下半场,高质量数据成为核心瓶颈——爬取的网络语料充斥噪声、重复与广告,人工标注成本难以随模型规模线性扩展。
DataFlow 项目的定位并非替代 Spark、Flink 等传统大数据平台,而是面向非结构化文本与多模态数据,构建以 GPU 算力和大模型 API 为核心的语义级数据治理系统。
02
DataFlow 数据准备系统
数据全流程
DataFlow 将数据准备链路划分为:数据采集 → 格式清洗 → 数据选择 → 配比优化 → 权重调整。上游对接 WebAgent 自动爬取的网页与 Hugging Face 等数据集,原始数据统一转化为 ShareGPT 可训练格式。随后基于质量评分精准筛选,动态调整各数据领域相对权重,甚至细化到每个数据点的个体权重,以提升模型泛化能力。
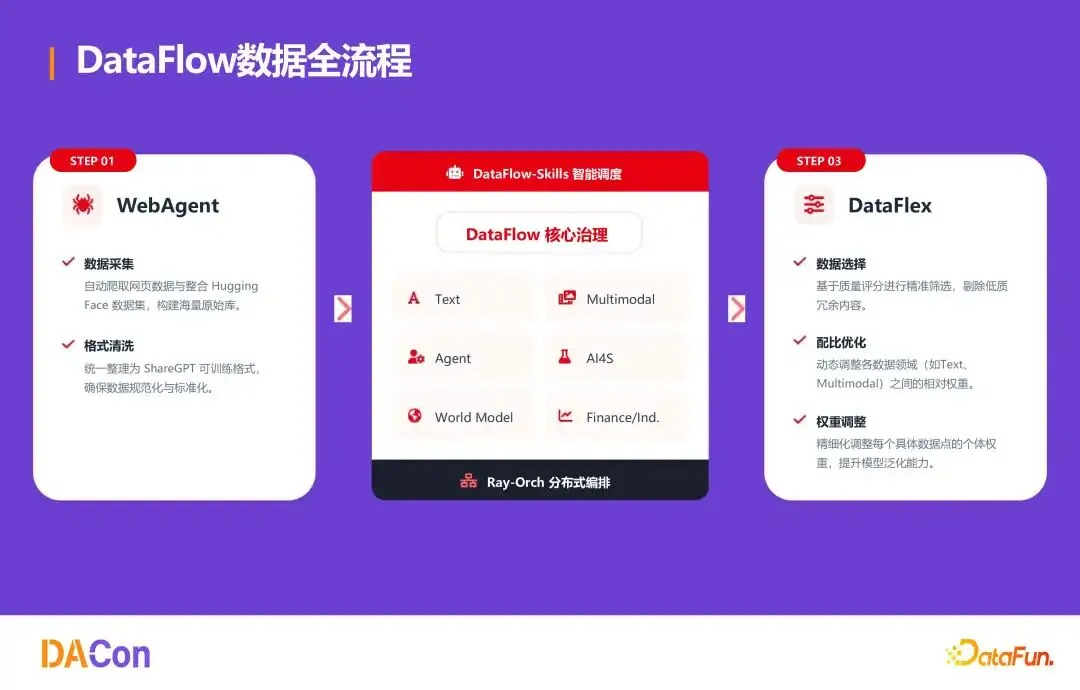
系统设计
DataFlow 编程模型借鉴 TensorFlow——像搭积木一样编排数据流水线。代码仓库位于https://github.com/OpenDCAI/DataFlow,允许开发者结合通用与行业算子,构建任务组合流水线。
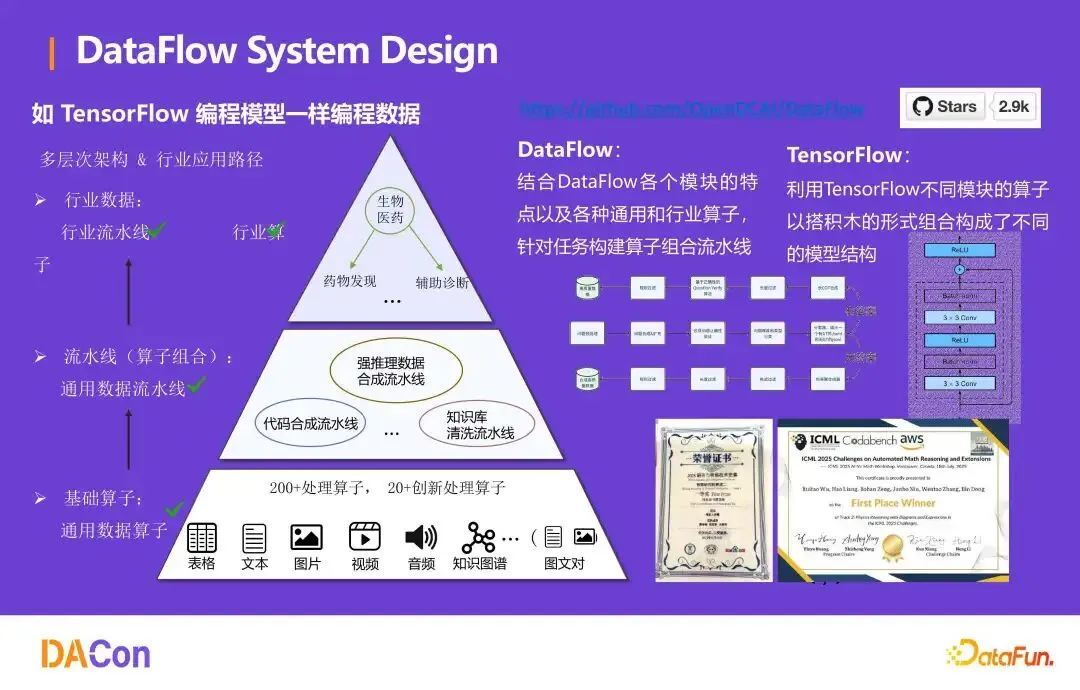

数据自动获取:WebAgent
WebAgent 采用“决策‑执行‑治理”三层解耦架构:策略中枢由 LLM 驱动,将模糊需求自动解析为异构策略;动态路由智能调度搜索引擎、数据集平台及垂直论坛;全自动执行引擎基于 DOM 深度遍历进行语义探索,MinerU 负责 HTML 精准萃取与 LLM 降噪清洗,最终产出符合 DataFlow 标准的预训练或 SFT 格式数据。
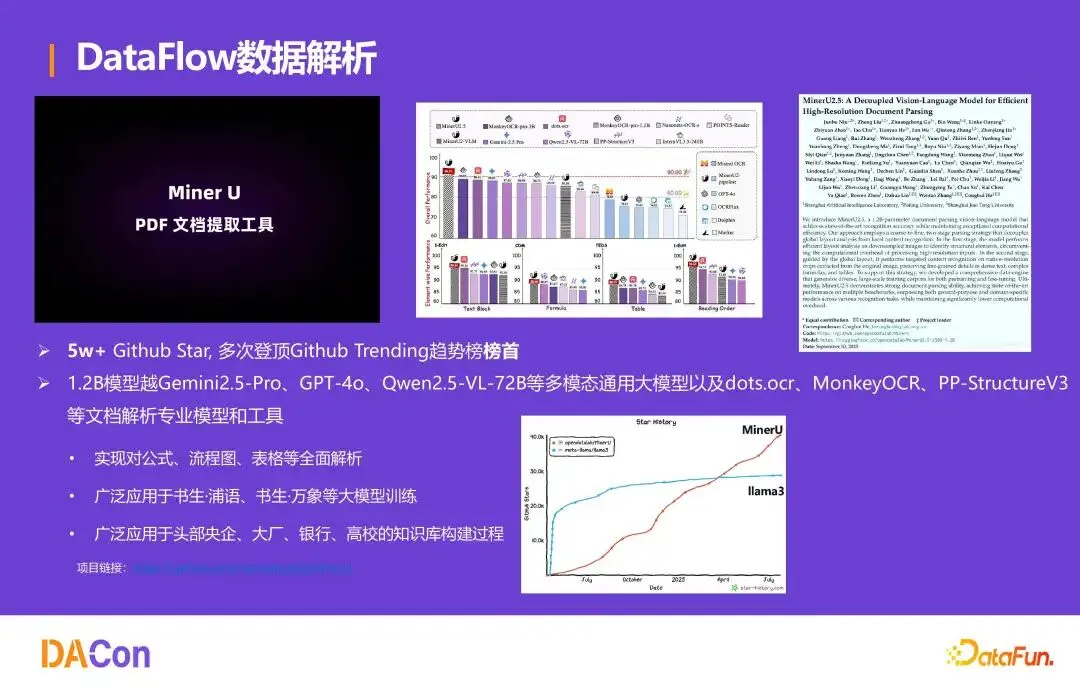
数据解析:MinerU
MinerU 是团队开源的文档解析工具,能从 PDF 中精准提取公式、流程图、表格并转为 Markdown 格式。GitHub 5 万+ Star,多次登顶 Trending 榜首。其 1.2B 模型在文档解析上超越 GPT-4o、Qwen2.5-VL-72B 等通用模型及专业 OCR 工具,被广泛应用于书生·浦语、书生·万象等大模型训练,以及头部央企、银行的知识库构建。
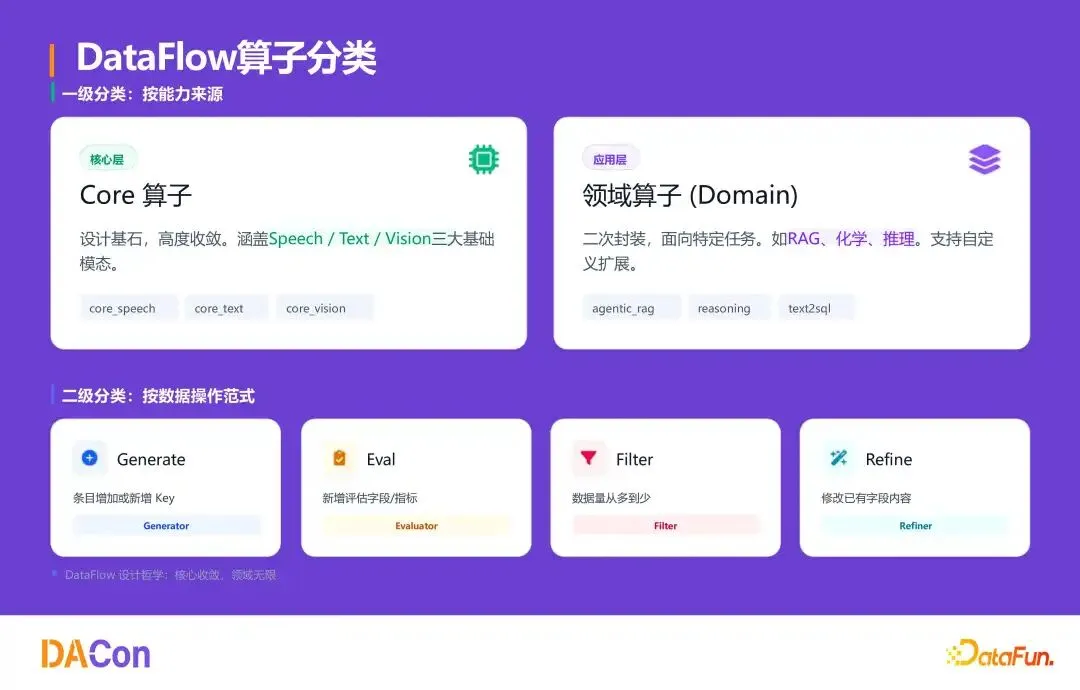
算子分类体系
采用两级分类管理算子:
一级(能力来源):Core 算子与应用层算子。Core 算子高度收敛至 20–30 个,覆盖语音、文本、视觉三大基础模态;领域算子在 Core 基础上二次封装,面向 RAG、化学、推理等任务,支持自定义扩展。
二级(操作范式):归纳为四类——Generate(新增 key)、Quality Evaluation(打分)、Filter(从多到少过滤)、Refine(低质优化为高质)。该分类囊括几乎所有非结构化数据处理需求。
这种设计使不同部门可按同一范式独立开发算子,上层 Agent 也能自动理解算子能力并编排流水线。
合成与改写算子
集成五种基础文本合成器:PretrainGenerator(预训练文档合成 QA 对)、SFTGenerator(种子文档合成 SFT QA 对)、CondorGenerator(知识树两阶段生成)、PromptedGenerator(自定义 prompt)、ConsistentChatGenerator(多轮对话合成)。覆盖预训练、SFT、多轮对话等阶段。

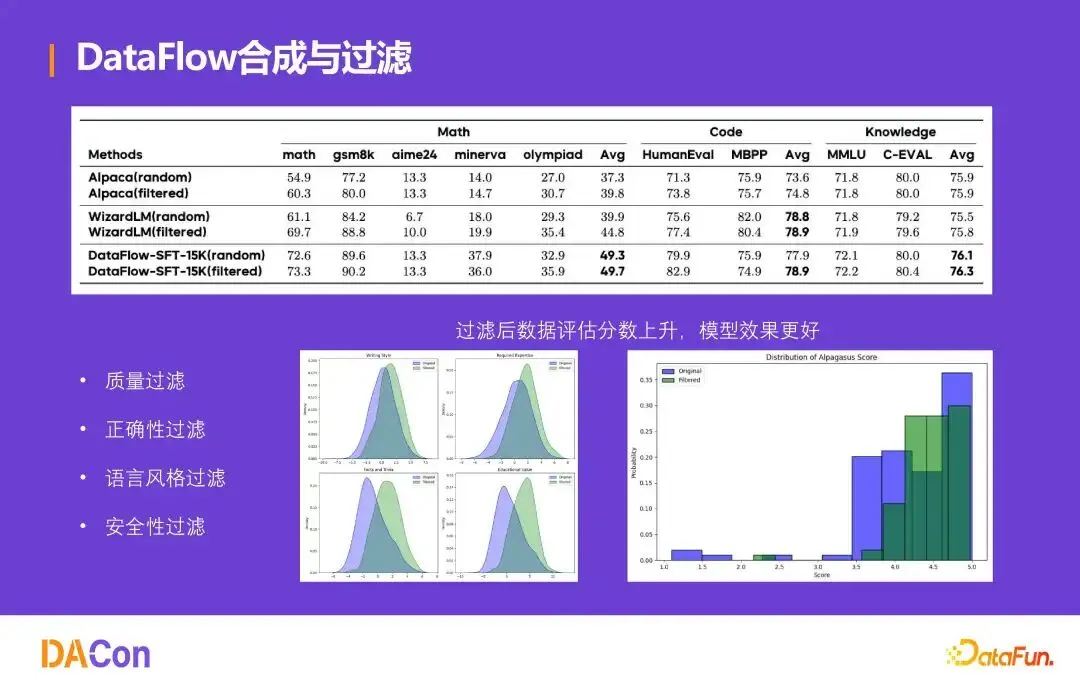
合成与过滤实验
在 Math、Code、Knowledge 领域对比随机采样与过滤后效果。Alpaca 经 GSM8K 从 54.9 升至 60.3,WizardLM 从 61.1 升至 69.7。DataFlow-SFT-15K 过滤后 Math 平均分从 49.3 升至 49.8,Code 平均分从 77.9 升至 78.9。过滤后数据评估分数上升,模型表现更好。
数据评估与打分
内置多维度评估算子:APICaller(API 打分)、Diversity(数据集多样性)、Models(12 种模型打分)、Statistics(统计学指标)。选择高分数数据显著提升训练效果。
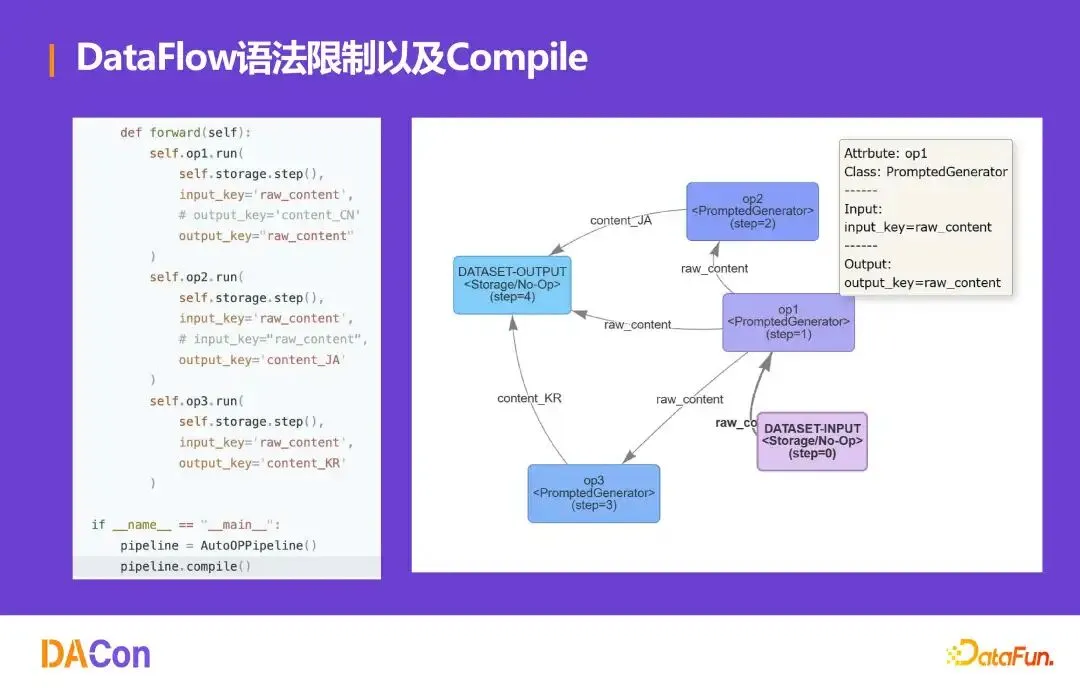
语法约束与 Compile
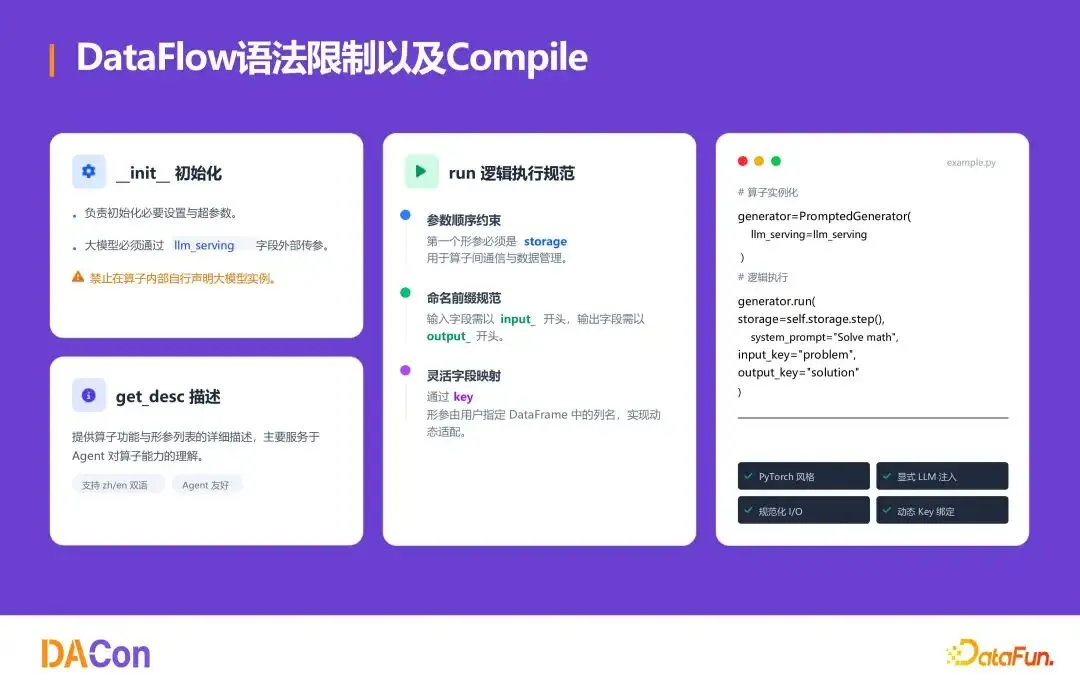
为保障大规模流水线可靠性,对算子施加约束:init 必须确定所有超参数,大模型只能通过 llm_serving 外部传参;run 第一形参为 storage,输入字段以 input_开头,输出以 output_开头。支持 compile()——运行前静态验证字段通路是否完整,减少 Agent 调试轮数,并支持 forward(resume_step)断点恢复。
DataFlow Skills
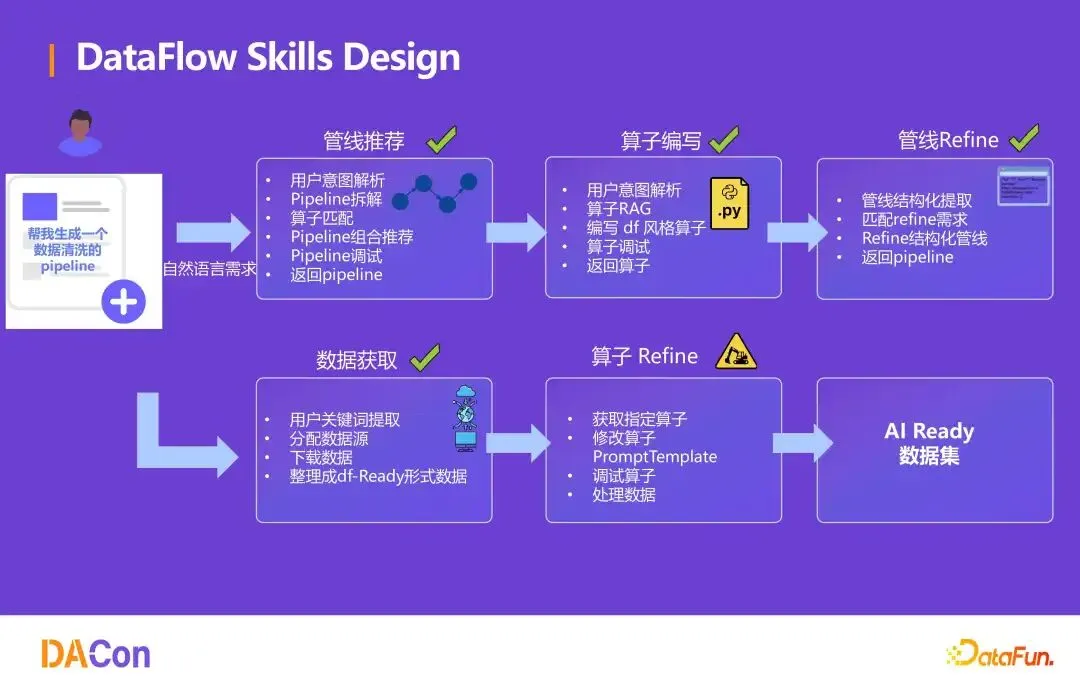
DataFlow Skills 将整个系统升级为自然语言驱动的数据工程师。结合 Claude Code 或 Cursor,系统可自动编写数据处理管线、算子甚至 prompt。业务专家通过对话即可完成复杂清洗任务,所有流程可复现、可验证,显著提升数据操作的标准化水平。

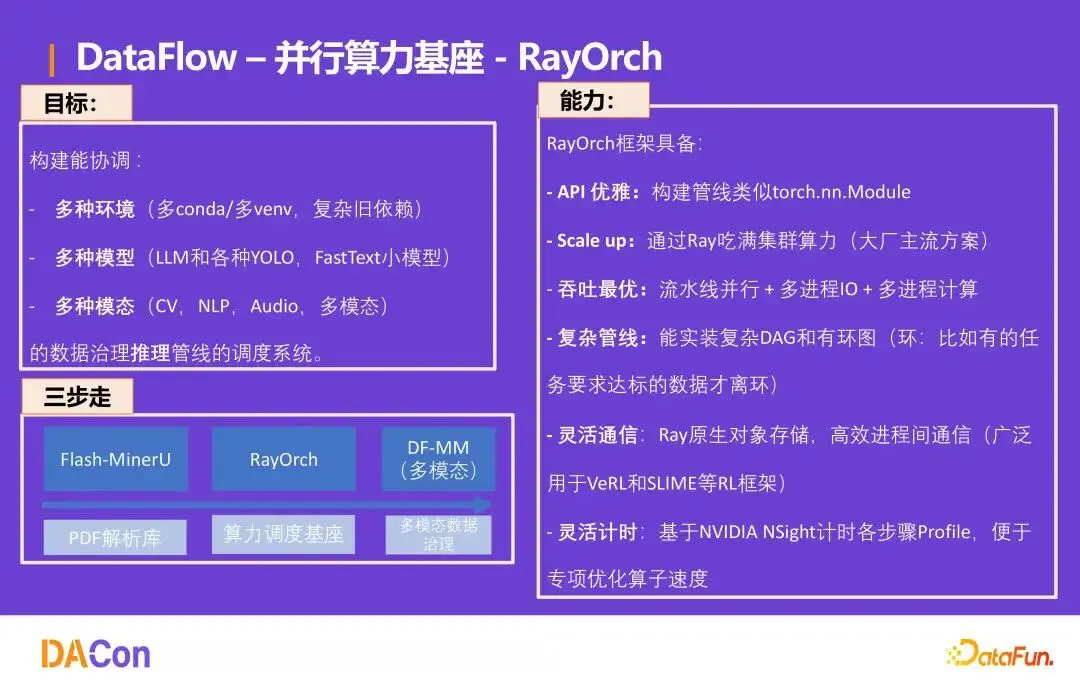
并行算力基座:RayOrch
RayOrch 协调多 conda 环境、多种模型(LLM、YOLO、FastText)与多模态(CV、NLP、Audio)的数据管线。能力包括:API 类 nn.Module、通过 Ray 吃满集群算力、流水线并行+多进程I/O+多进程计算、支持有环 DAG、Ray 原生对象存储高效通信、NVIDIA NSight 计时优化。
分布式算子封装与加速

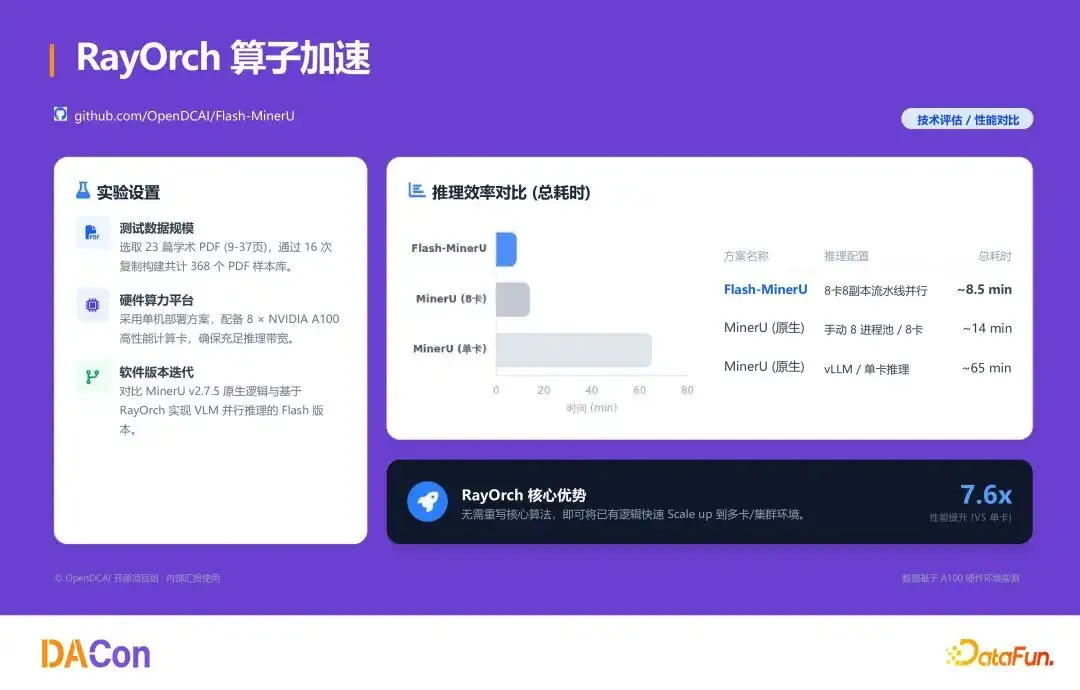
开发者定义 SumOp 类后,通过 RayModule(SumOp, replicas=3, num_gpus=1)即可分布式部署。以 MinerU 为例,8×A100 上获得 7.6 倍加速(对比单卡)。

小模型打分(GPT-2 124M,Alpaca 4096 行):2 卡加速 1.8 倍,4 卡 3.6 倍,8 卡 6.1 倍。同时支持 vLLM/SGLang 实现大模型并行推理。
多模态 DAG 构建

RayOrch 支持类 nn.Module 的 DAG 构建,算子接受多个输入时分支持自动处理,确保多模态流水线灵活性。
生态系统
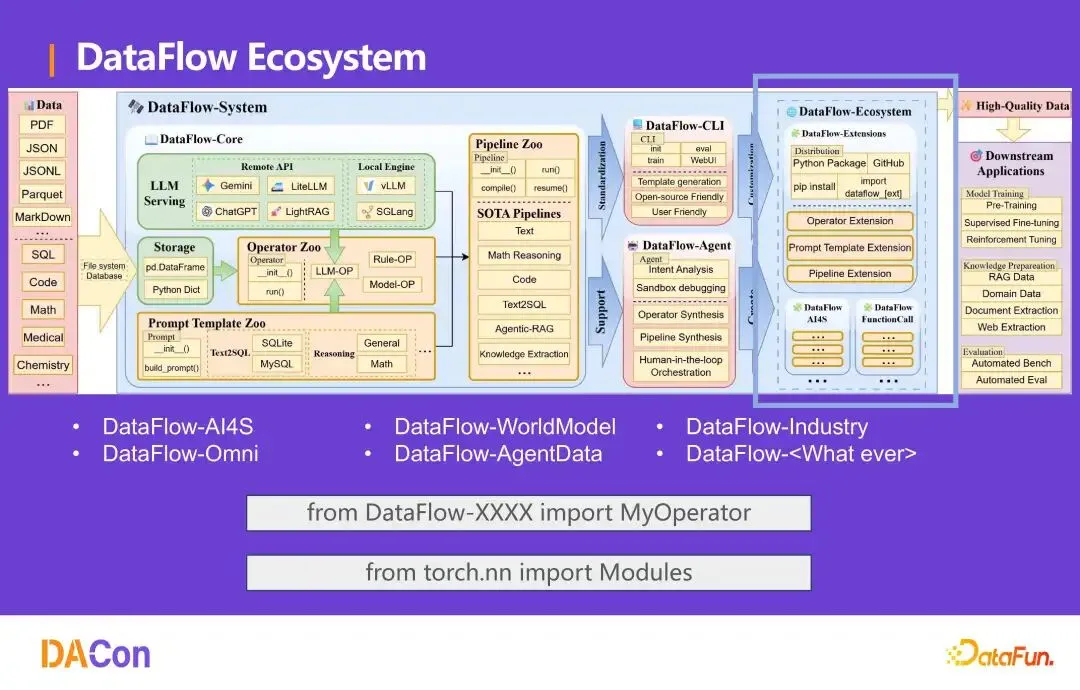
DataFlow 提供一种 data engineering harness 设计模式。维护多个仓库:主仓库(文本)、DataFlow-Omni(多模态)、WorldModel、AgentData、AI4S、Industry 等。任何团队可按同样范式加入——如同 from torch.nn import Module,使用 from DataFlow-XXXX import MyOperator。不同部门独立开发,互不干扰。
编程案例

PyTorch 化 API,“搭积木”构建 Workflow。通过更换 Prompt 实现算子复用,Agent 自动编写 Pipeline。compile()自动纠错,forward(resume_step)断点恢复。
特色 Pipeline 1:教材试题自动化提取
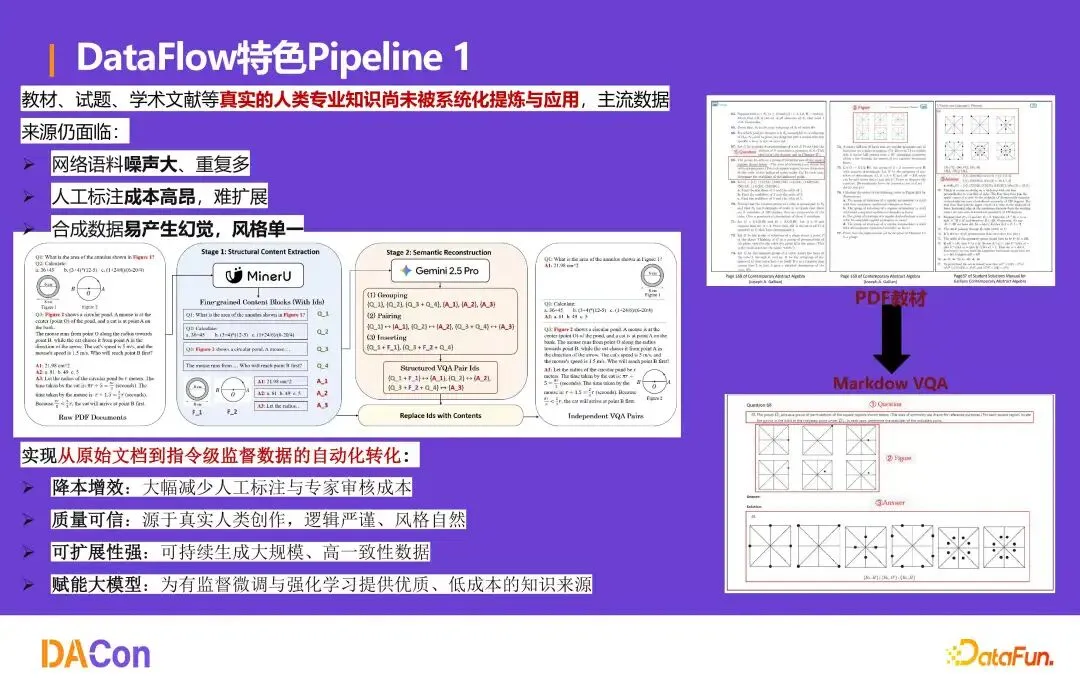
将题目(可能在书本前部)与答案(可能在书本后部)自动串联,生成可训练的 VQA 格式数据。源于真实人类创作,逻辑严谨,降本增效且可扩展。
特色 Pipeline 2:复杂推理数据合成
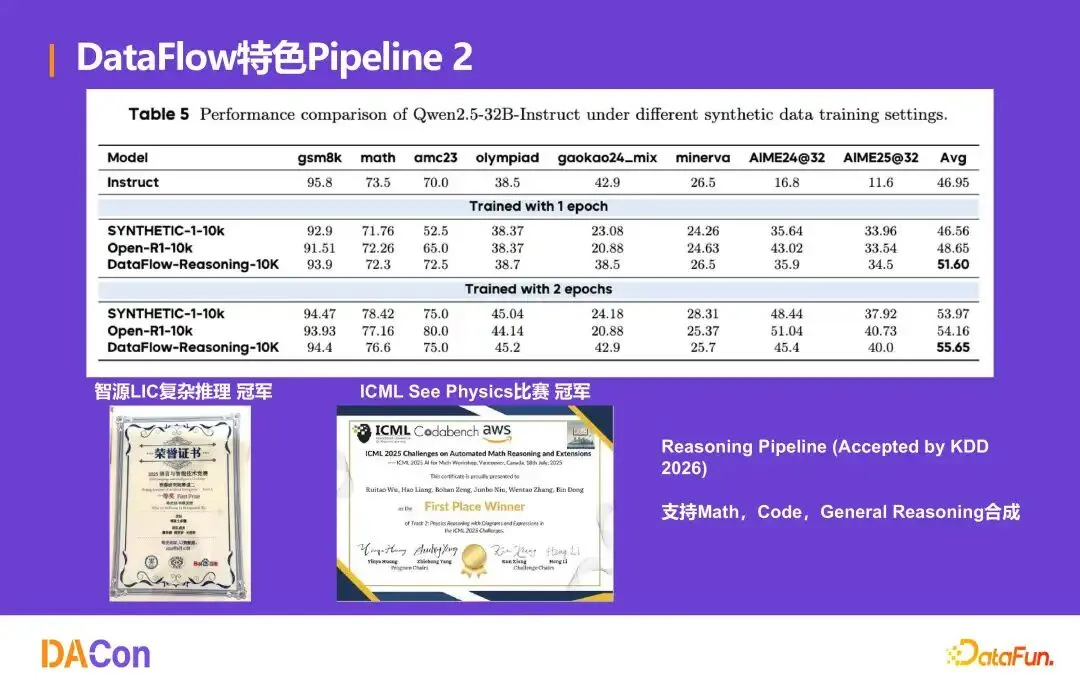
推理 Pipeline(被 KDD 2026 接收)支持 Math、Code、General Reasoning 合成。在智源 LIC 复杂推理比赛和 ICML See Physics 比赛中获得冠军。Qwen2.5-32B-Instruct 上使用 10K 合成数据训练 1 epoch,DataFlow-Reasoning-10K 平均分 51.60,优于 SYNTHETIC-1-10K(46.56)和 Open-R1-10K(48.65);2 epoch 后达 55.65,持续领先。
DataFlow-Instruct-10K 实验结果

在 Qwen2.5-7B-Base 上,10K 数据微调后:MATH 从 62.8 升至 73.8,GSM8K 从 67.1 升至 88.2,AIME24 从 10.0 升至 16.7,逼近 Qwen2.5-7B-Instruct 效果,远超 Inf-10K/1M。代码任务上 HumanEval 从 78.7 升至 80.5,MBPP 从 74.3 升至 76.7;知识任务 MMLU/C-EVAL 保持基线水平。表明合成数据在数学和代码推理上增益显著,同时保持通用能力。

03
多模态与多数据源支持
多模态流水线
DataFlow‑MM 扩展了对图像、视频、音频的支持。主要功能包括:图像多模态详细 caption 合成、图像高质量 VQA 合成、图文交错数据集合成、强推理图像数据集合成、语音转录打标签、视频 COT 数据集构建。其设计模式与接口与主仓库完全一致,同样支持 DataFlow-Agent。

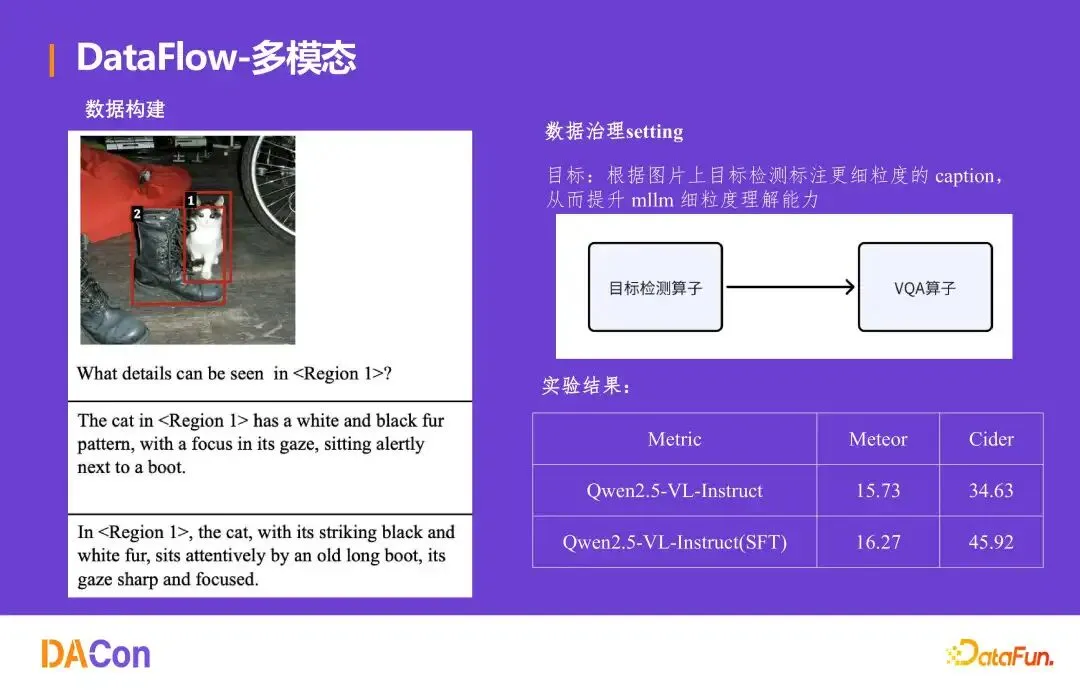
图像细粒度数据构建
针对图像场景中的痛点:需要根据目标检测标注生成更细粒度的 caption,以提升多模态大模型的细粒度理解能力。团队构建了相应 Pipeline。例如,对图片中猫和靴子的区域,生成“带有黑白花纹的猫,目光专注地坐在靴子旁”等详细描述。实验结果显示,Qwen2.5-VL-Instruct 经过 SFT 后,Meteor 指标从 15.73 提升至 16.27,Cider 从 34.63 提升至 45.92。
视频 COT 数据构建
视频问答任务中,模型不仅需要给出答案,还需要具备中间推理能力。DataFlow‑MM 支持根据视频 QA 生成 Chain-of-Thought(CoT),并对生成的 Answer 进行打分和过滤。示例中,模型通过多步推理回答“视频结束时有多少个移动的橡胶物体”,最终输出正确答案。实验表明,经过 SFT 后,Qwen2.5-VL-Instruct 在 VSI-Bench 上从 27.7 提升至 31.8,在 MMVU 上从 59.2 提升至 61.3。

全模态数据源适配
DataFlow 支持结构化数据(SQL、CSV、EXCEL)、半结构化数据(JSON/BSON、XML)和非结构化数据(通过文档解析引擎支持 PDF 表格、TXT 文本)。核心功能包括:智能元数据解析——Agent 自动识别字段类型、解析特殊属性(主键、外键、量纲),无需手动编写复杂ETL脚本;Text2Data 能力——用户只需输入一句自然语言,即可实现跨库、跨格式的数据检索与聚合。

智能处理:表格清洗
针对表格数据的自动化预处理,挑战在于:结构化数据感知理解难,多表多需求任务编排复杂,表格字段庞大。DataFlow 的 TableAgent 基于表格预处理算子库的多智能体协作框架,任务示例包括表格清洗(如识别并删除重复的行走记录)、转换、增强、匹配等。在表格预处理评测基准上,TableAgent 的任务完成率(97.37%)和成功率(78.51%)均大幅领先 DeepAnalyze(92.11% / 57.85%)和 ChatDev(38.89% / 27.09%)。

智能分析:不止于“看”数据
DataFlow 的智能分析模块能够根据自然语言指令自动完成统计分析与指标计算,理解业务语义并生成解释性强的分析结论,以及可视化报表生成。在确保数据质量的基础上,AI 自动生成统计报表和可视化图表,深入洞察“元数据规模”、“字段分布”等关键指标。所有分析结果均附带自然语言解释,帮助用户清晰理解数据问题与业务结论。

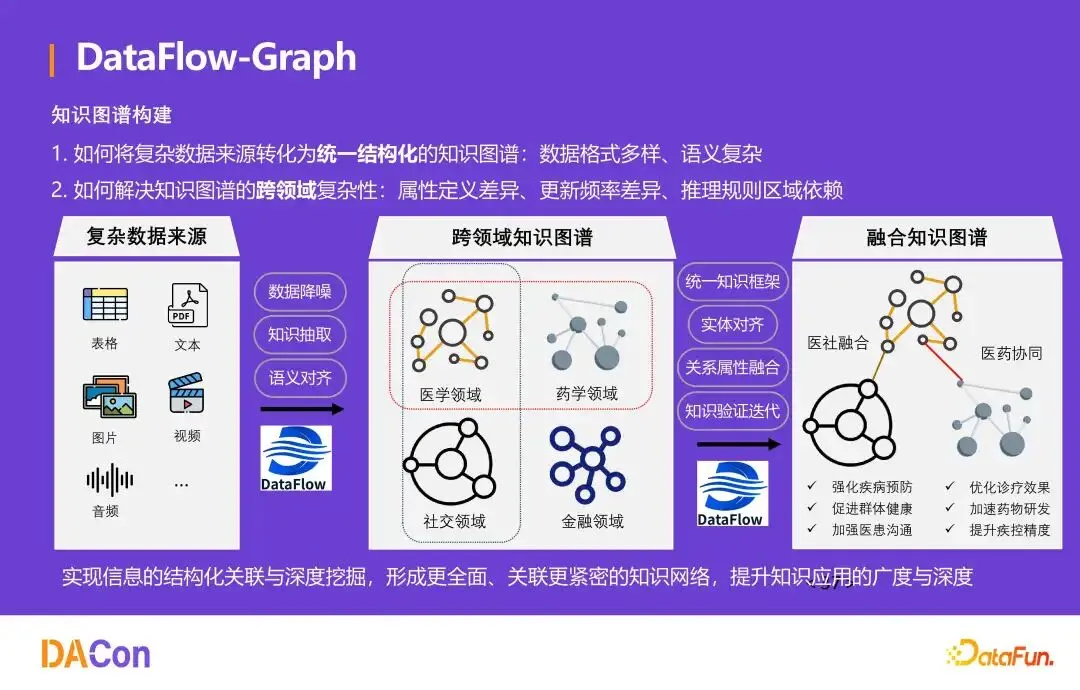
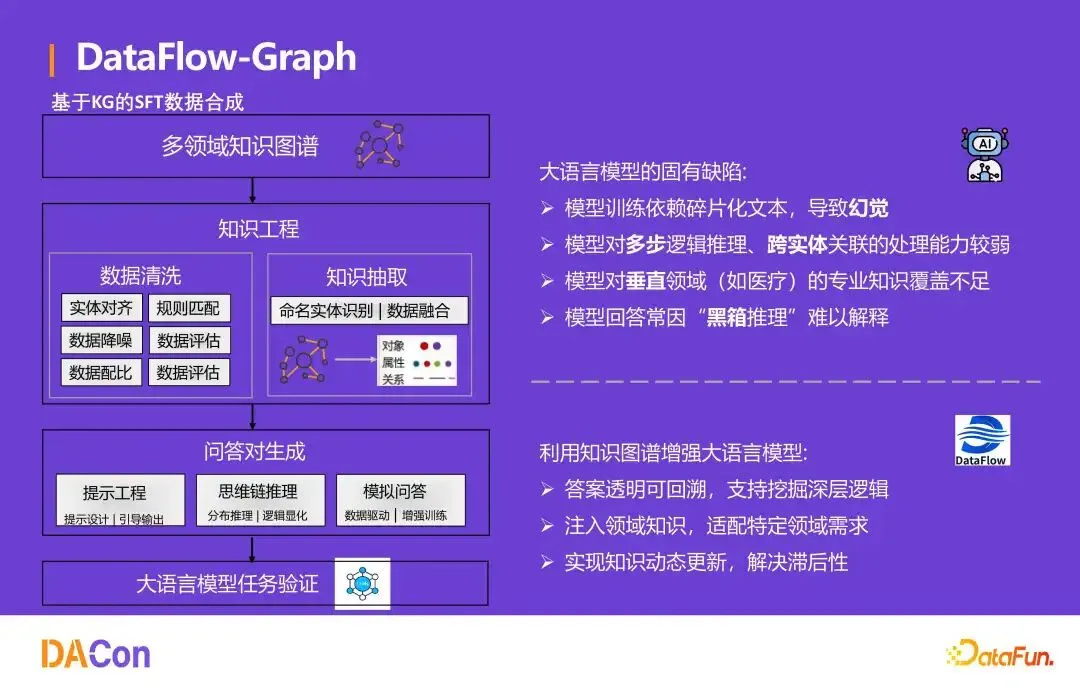
知识图谱构建
DataFlow‑Graph 解决两个核心问题:一是如何将复杂数据来源(格式多样、语义复杂)转化为统一结构化的知识图谱;二是如何解决知识图谱的跨领域复杂性(属性定义差异、更新频率差异、推理规则区域依赖)。通过流水线编排,系统实现信息的结构化关联与深度挖掘,形成更全面、关联更紧密的知识网络。
基于知识图谱的 SFT 数据合成
大语言模型存在固有缺陷:训练依赖碎片化文本导致幻觉;对多步骤逻辑推理、跨实体关联的处理能力较弱;垂直领域专业知识覆盖不足;回答因“黑箱推理”难以解释。利用知识图谱增强 LLM 可以实现:答案透明可回溯、支持深层逻辑挖掘;注入领域知识、适配特定需求;知识动态更新、解决滞后性。
DataFlow‑Graph 的合成 Pipeline 包括:多领域知识图谱构建 → 知识工程(数据清洗、实体对齐、规则匹配)→ 知识抽取(命名实体识别、数据融合)→ 问答对生成 → 模型训练验证。在教育类 K12 书籍的实验中,仅用 2000 余条合成数据,训练效果便超越了所有开源数据集。
代码仓库与开源矩阵
DataFlow 主仓库位于 GitHub OpenDCAI/DataFlow。团队来自北京大学赵文涛老师课题组,整体开源矩阵 OpenDCAI 覆盖智能体、数据治理等多个方向。


往期推荐

点个在看你最好看
SPRING HAS ARRIVED

