 夜雨聆风
夜雨聆风当 OpenAI 宕机时,数百万用户失去访问权限。当他们更新拒绝列表时,上个月还能用的主题突然就失效了。
上周,Anthropic发布的Claude Fable 5引爆了前沿AI领域最剧烈的信任危机:研究员发现,一旦模型怀疑用户在开发竞品,它竟会“暗中下毒”悄悄降低回答质量,加之该模型有30天的数据保留要求,导致其在微软内部被禁用。
这引发了一个关于加密领域多年来一直在问的问题:是否应该由任何单一公司掌控如此多的前沿AI?
Venice AI 、Pearl与C0mputer都是去中心化AI。
(1)Venice在去中心化方面依赖 GPU 网络和合作伙伴(如 Phala),而非单一链上推理。
Venice 的隐私哲学是“你不需要保护你没有的东西”(You don’t have to protect what you do not have)。核心做法包括:本地存储 + 无服务器持久化:提示、响应、生成内容和对话历史都仅存储在用户浏览器本地(加密),不会保存在 Venice 的任何服务器上。清除浏览器数据即永久删除。
代理 + 去中心化路由:提示从浏览器通过 Venice 控制的代理(proxy)发送到分布式 GPU 网络。代理会剥离元数据(如 IP、用户标识),每个 GPU 提供商只看到孤立的、匿名的原始提示片段,没有用户历史或身份信息。处理后立即清除(transient memory)。
多层隐私模式(逐步增强):Anonymized:剥离标识元数据访问第三方模型。
Private:自托管开源模型,零数据保留。
TEE(Trusted Execution Environment):硬件安全飞地(enclave),使用 Intel TDX / AMD SEV 等。Venice 或节点运营商无法访问计算过程。
E2EE(End-to-End Encrypted):客户端加密,提示在离开设备前加密,只有 TEE 能解密。
这些结合 SSL/TLS 加密传输,实现比主流 AI 强得多的隐私(除非用户本地完全自跑模型)。
Venice 不是完全 on-chain 的 AI,但大量采用去中心化基础设施来实现抗审查和隐私:
- 去中心化 GPU / 计算网络:从多个全球合作伙伴和提供商处获取 GPU 算力,形成分布式网络(非单一中心服务器)。这避免单点故障/控制,并提升抗审查性。
- Phala Network 等 TEE/机密计算:与 Phala 合作,使用其去中心化机密计算网络(dstack 框架)。TEE 提供硬件隔离 + 远程证明(remote attestation,由 CPU 硬件密钥签名),用户可加密验证代码和环境未被篡改,实现“数据在使用中”(data-in-use)保护。Phala 节点运营商也看不到提示/输出。
- 区块链集成($VVV 在 Base 链):VVV 是 ERC-20 代币(Base L2),用于质押解锁 Pro 访问、铸造 DIEM(AI 信用代币)、收益和平台收入回购燃烧(deflationary)。这将经济激励与平台绑定,但计算本身更多依赖去中心化 GPU 而非纯区块链执行。
- 其他:开源模型 + 代理架构类似 Tor(剥离标识),未来可能探索同态加密等。还与 Morpheus 等 permissionless AI 网络相关。
Venice上最常用的模型并不是什么去中心化训练出来的模型(不是来自Pluralis等),而是像DeepSeek或GLM-5这样的常规公司运行的开源开放权重模型。
(2)Pearl($PRL /@prlnet)主要进行AI推理(inference),也支持训练相关的计算,但核心是“Proof-of-Useful-Work”(PoUW,有用工作量证明)。
它是做什么的?
- 不是单纯的AI训练或推理平台,而是一个Layer-1区块链(基于Bitcoin fork,UTXO模型),用AI计算(主要是矩阵乘法 MatMul / GEMM)来挖矿和保障网络安全。
- 矿工在GPU上运行矩阵乘法(AI训练和推理的核心操作),这个计算同时产生PRL代币奖励(作为PoW)和有用的AI输出(2-for-1设计,几乎无额外开销)。
- 目前重点是推理(inference),如与Together AI合作,提供折扣的Gemma模型推理端点,矿工运行这些负载时可同时挖矿。未来计划扩展到训练(training),包括低精度浮点(如BF16、FP8)支持。
- 矿工可以把现有AI工作负载“插件”化(kernel集成),让GPU周期同时服务真实AI任务并挖矿,改善AI的经济性(补贴算力成本)。
如何去中心化?Pearl是去中心化的PoUW区块链,类似Bitcoin的机制,但工作量更有用:
pearlresearch.ai
- 共识与安全:使用“cuPOW”协议(基于矩阵乘法的NoisyGEMM)。矿工提交矩阵、添加结构化噪声、计算乘法、生成哈希证明,通过难度目标验证。网络用最长链规则(累积工作量最高)达成共识。攻击需要 majority 的计算力(GPU算力),经济上极难。
- P2P网络:全节点通过gossip协议传播交易和区块,去中心化传播。
- 挖矿去中心化:任何有NVIDIA GPU的人/实体都可以挖(云租用、个人矿机、数据中心)。有社区矿池,支持solo/共享挖矿。矿工选择自己的输入矩阵(经济上有用性由市场驱动,而非协议强制)。
- 验证:证明可高效验证(ZK或Merkle证明),全节点可轻松检查,而无需重算整个MatMul。
- 经济去中心化:代币发行与真实GPU周期(AI算力)挂钩,形成“AI原生货币”。未来计划构建算力市场,匹配供给需求,进一步去中心化AI计算访问。
- 它是开源的(GitHub有node、miner等),主网已上线(2026年4月左右)。
总结:Pearl不是“运行AI模型”的去中心化平台,而是把AI计算本身变成区块链安全和货币发行机制的创新项目。它让GPU挖矿从“浪费能源哈希”变成“服务AI同时挖矿”,增强去中心化(分布式GPU网络而非中心化云)。当前以推理为主,矿工主要是GPU持有者/租户。
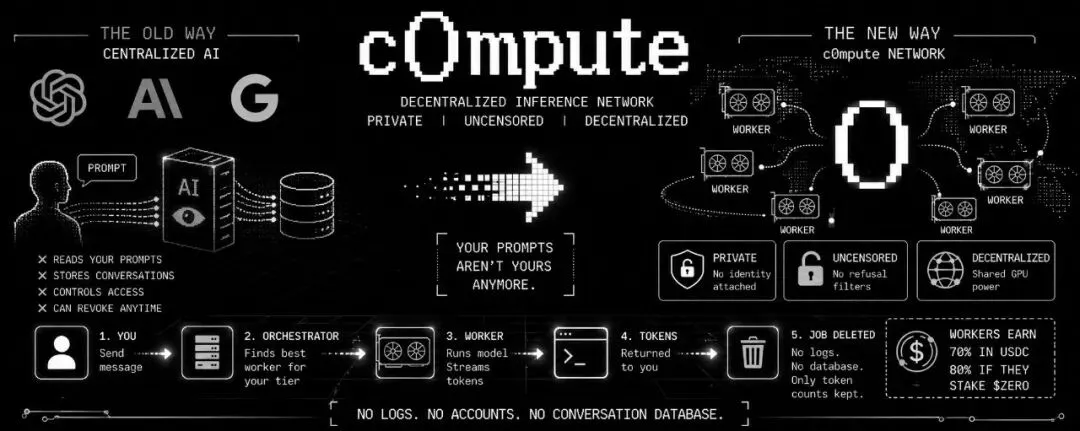
(3)c0mpute 是一个去中心化的推理网络。
c0mputeAI($ZERO)的 Shard 分片引擎是如何实现的?
它被称为“去中心化网络”是因为技术上实现分布式公网推理 + 经济上开放参与并激励贡献,目标是构建替代中心化云的 AI 计算层。
普通人分享 GPU 算力。你获得私密的、无审查的 AI。
消费流程:
1. 你发送一条消息
2. 协调器根据你的等级找到一个可用的工作者
3. 工作者运行模型并流式返回令牌
4. 任务完成。协调器丢弃它。没有对话数据库。只保留令牌计数用于计费。
消费者:C0mputer提供两个订阅等级:
➜ Pro:Qwen3 8B 无审查版,通过 WebGPU 在你的浏览器中运行,每条消息 10 积分 .
➜ Max:Qwen3.5 27B 或 SuperGemma4 26B,原生 GPU 工作者,支持网络搜索 + 视觉,每条消息 15 积分 .
工作者:只收到你的提示词文本,其他什么都没有,没有名字,没有钱包,没有账户。他们无法知道你是谁。
工作者从每项任务中赚取 70% 的 USDC,如果他们质押 $ZERO 则为 80%。协调器根据 tokens/sec 加权选择,因此更快的工作者赚得更多,但整个池子都能获得任务。
去中心化和中心化AI的创业者经常在解决落后两代的问题。
一位研究员前几天告诉我,“预训练还没有完全解决,但已经非常无聊了。” 很多关于推理的创新来自于后训练,现在我们在谈论递归、持续学习等。中心化AI在人才和资金的降维打击下,差距其实越拉越大了。至于小模型和端侧计算,很多时候直接拿大模型做个蒸馏(比如谷歌的Gemma)就非常好用。
去中心化训练集群为创业者提供极强的抗压韧性。在巨型数据中心里,一个GPU坏了你可能需要重新启动训练;而在Swarm中,不同大小和形状的GPU可以在训练进行时随时进出网络而不会产生负面影响。最大的证据是,谷歌最近在博客上表示,他们开始在自己的数据中心内使用DiLoCo风格的算法了。
OpenAI之前提到“模型本身已不再是产品”。在去中心化AI领域,人们似乎痴迷于构建模型,而实际上落后了现有技术两三代。我们应该在模型周围的基础设施上寻找价值:用于代码执行和计算的沙盒、评估机制(Evals)、合成数据管道等环境能力。很多现代金融应用可以在DeFi和AI的交叉点上构建,但我们还没充分利用。
去中心化AI可以说是加密货币领域最后的堡垒,它是真正起作用的前沿技术。
