 夜雨聆风
夜雨聆风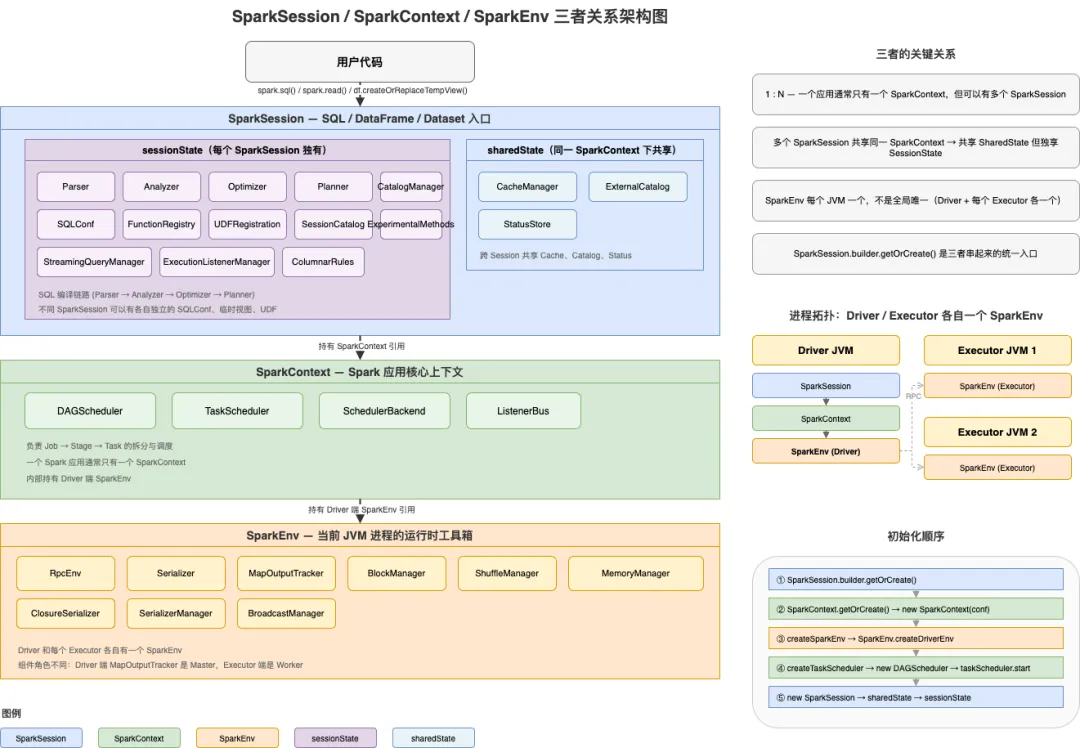
基于 Spark 4.2,分支
branch-4.2阅读时长约 10 分钟 · 入门到中级
背景
刚接触 Spark 时,最容易被这三个名字绕晕:
SparkSession
SparkContext
SparkEnv
它们都像是“上下文”。那到底谁管谁?
一句话总结:
SparkSession 是 SQL 门面,SparkContext 是应用核心,SparkEnv 是 Driver / Executor 的运行时工具箱。
一、流程图:三层关系
用户自己写的代码
│
▼
SparkSession ← SQL / DataFrame / Dataset 入口
│
├─ sessionState ← 每个 SparkSession 独有
│ ├─ analyzer
│ ├─ optimizer
│ ├─ planner
│ └─ catalogManager
│
├─ sharedState ← 同一个 SparkContext 下共享
│ ├─ cacheManager
│ ├─ externalCatalog
│ └─ statusStore
│
▼
SparkContext ← 一个 Spark 应用的核心上下文
│
├─ DAGScheduler ← Job / Stage 调度
├─ TaskScheduler ← TaskSet 调度
├─ SchedulerBackend ← 跟集群管理器通信
└─ SparkEnv ← Driver 端运行时环境
├─ RpcEnv
├─ BlockManager
├─ MapOutputTracker
├─ ShuffleManager
├─ Serializer
└─ MemoryManager
Executor 进程里也有自己的 SparkEnv
关键关系:
一个应用一般只有一个
SparkContext一个
SparkContext下可以有多个SparkSession每个 Driver / Executor 进程各自有一个
SparkEnv
二、SparkSession:SQL 世界的入口
API 抽象类在 SparkSession.scala:63:
abstract classSparkSessionextendsSerializablewithCloseable{它暴露了三个核心对象:
def sparkContext: SparkContext // SparkSession.scala:72def sharedState: SharedState // SparkSession.scala:98def sessionState: SessionState // SparkSession.scala:114
Classic 实现在 classic/SparkSession.scala:92:
class SparkSession private(@transient val sparkContext: SparkContext,@transient private val existingSharedState: Option[SharedState],@transient private val parentSessionState: Option[SessionState],@transient private[sql] val extensions: SparkSessionExtensions,@transient private[sql] val initialSessionOptions: Map[String, String])
这说明 SparkSession 不是凭空存在的,它必须绑定一个 SparkContext。
三、sessionState vs sharedState
SparkSession 里最容易混的是这两个:
lazy val sharedState: SharedState // classic/SparkSession.scala:175lazy val sessionState: SessionState // classic/SparkSession.scala:205
sessionState:每个 Session 自己的 SQL 状态
SessionState.scala:71。下面是简化后的构造参数片段,只保留理解三者关系需要的字段:
private[sql] class SessionState(sharedState: SharedState,val conf: SQLConf,val experimentalMethods: ExperimentalMethods,functionRegistry: FunctionRegistry,tableFunctionRegistry: TableFunctionRegistry,udfRegistration: UDFRegistration,udfExpressionBuilder: SparkUDFExpressionBuilder,catalogBuilder: () => SessionCatalog,sqlParser: ParserInterface,analyzerBuilder: () => Analyzer,optimizerBuilder: () => Optimizer,planner: SparkPlanner,streamingQueryManagerBuilder: () => StreamingQueryManager,listenerManager: ExecutionListenerManager,resourceLoaderBuilder: () => SessionResourceLoader,createQueryExecution: LogicalPlan => QueryExecution,createClone: (SparkSession, SessionState) => SessionState,columnarRules: Seq[ColumnarRule])
这里面放的是 SQL 编译期对象:
SQLConf
Parser
Analyzer
Optimizer
Planner
FunctionRegistry
SessionCatalog
这也解释了为什么不同 SparkSession 可以有不同 SQLConf、临时视图、UDF。
sharedState:同一个 SparkContext 下共享
SharedState.scala:51:
private[sql] class SharedState(val sparkContext: SparkContext,initialConfigs: scala.collection.Map[String, String])
它放的是跨 Session 共享的东西:
cacheManager(SharedState.scala:98)statusStore(SharedState.scala:121)externalCatalog(SharedState.scala:149)
所以如果两个 SparkSession 共享同一个 SparkContext,它们通常共享 cache 和外部 catalog。
四、SparkContext:应用核心
SparkContext.scala:86:
classSparkContext(config: SparkConf) extendsLogging{SparkContext 是 Spark 应用的核心上下文。它持有真正负责执行的组件:
private var _conf: SparkConf = _ // SparkContext.scala:216private var _env: SparkEnv = _ // SparkContext.scala:220private var _schedulerBackend: SchedulerBackend = _ // SparkContext.scala:226private var _taskScheduler: TaskScheduler = _ // SparkContext.scala:227private var _dagScheduler: DAGScheduler = _ // SparkContext.scala:229
访问器在:
def conf: SparkConf = _conf // SparkContext.scala:253def env: SparkEnv = _env // SparkContext.scala:297def schedulerBackend: SchedulerBackend = _schedulerBackend // SparkContext.scala:341def taskScheduler: TaskScheduler = _taskScheduler // SparkContext.scala:343def dagScheduler: DAGScheduler = _dagScheduler // SparkContext.scala:348
从前两篇文章可以看出:
spark.sql(...)最终会走到SparkContext.runJobrdd.count()直接走到SparkContext.runJobSparkContext再把 job 交给DAGScheduler
所以 SparkContext 是 SQL 和 RDD 执行链路的共同底座。
五、SparkContext 初始化:先 SparkEnv,再 Scheduler
用户一般不会直接看 SparkContext 构造函数,但这里最能看清对象关系。
SparkContext.scala:501:
_env = createSparkEnv(_conf, isLocal, listenerBus)SparkEnv.set(_env)
createSparkEnv 定义在 SparkContext.scala:290,实际调用:
SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master, conf))也就是说,Driver 端先创建 SparkEnv。
接着初始化调度器。SparkContext.scala:600:
val (sched, ts) = SparkContext.createTaskScheduler(this, master)_schedulerBackend = sched_taskScheduler = ts_dagScheduler = new DAGScheduler(this)_taskScheduler.start()
对应行号:
SparkContext.scala:600:创建 scheduler/backendSparkContext.scala:601:设置_schedulerBackendSparkContext.scala:602:设置_taskSchedulerSparkContext.scala:603:创建_dagSchedulerSparkContext.scala:629:启动_taskScheduler
最后 Driver 端初始化 BlockManager 和 metrics。SparkContext.scala:650:
_env.blockManager.initialize(_applicationId)顺序很重要:
new SparkContext(conf)
→ createSparkEnv
→ SparkEnv.set
→ createTaskScheduler
→ new DAGScheduler
→ taskScheduler.start
→ blockManager.initialize
六、SparkEnv:运行时工具箱
SparkEnv.scala:61。下面是简化后的构造参数片段:
class SparkEnv(val executorId: String,private[spark] val rpcEnv: RpcEnv,val serializer: Serializer,val closureSerializer: Serializer,val serializerManager: SerializerManager,val mapOutputTracker: MapOutputTracker,val shuffleManager: ShuffleManager,val broadcastManager: BroadcastManager,val blockManager: BlockManager,...)
SparkEnv 不是“应用上下文”,而是当前 JVM 进程里的运行时工具箱。
Driver 有一个 SparkEnv,Executor 也有一个 SparkEnv。它里面装的是运行时必备组件:
| 组件 | 作用 |
|---|---|
RpcEnv | Driver / Executor RPC 通信 |
Serializer | 数据序列化 |
closureSerializer | 闭包序列化 |
MapOutputTracker | Shuffle map 输出位置跟踪 |
BlockManager | 管理内存/磁盘/远程 block |
ShuffleManager | 管理 shuffle 读写 |
MemoryManager | 管理 execution/storage 内存 |
注意:Spark 4.2 里这里叫 RpcEnv,不是早期文章里常见的 actorSystem。老版本 Spark 曾经用 Akka,后面换成了 RPC 抽象。
七、Driver SparkEnv 和 Executor SparkEnv
SparkEnv 有两个明确入口:
createDriverEnv(...) // SparkEnv.scala:285createExecutorEnv(...) // SparkEnv.scala:320
Driver 端:
def createDriverEnv(...): SparkEnv = {create(..., isDriver = true, ...)}
Executor 端:
def createExecutorEnv(...): SparkEnv = {val env = create(..., isDriver = false, ...)env.initializeMemoryManager(...)SparkEnv.set(env)env}
统一创建逻辑在 SparkEnv.scala:347 的 create(...)。
几个关键分支:
SparkEnv.scala:378:根据 Driver / Executor 选择 RPC system nameSparkEnv.scala:379:调用RpcEnv.create(...)创建 RPC 环境SparkEnv.scala:407:创建mapOutputTracker,Driver 用 Master,Executor 用 WorkerSparkEnv.scala:471:创建blockManagerSparkEnv.scala:506:最终new SparkEnv(...)
这也解释了为什么 Driver 和 Executor 都能访问:
SparkEnv.get因为每个 JVM 进程里都会 SparkEnv.set(env)。
八、SparkSession.builder.getOrCreate:三者如何串起来
最常见的入口:
val spark = SparkSession.builder().appName("demo").master("local[2]").getOrCreate()
classic/SparkSession.scala:938 是 Builder 类。
核心构建逻辑在 classic/SparkSession.scala:1009 的 build(forceCreate: Boolean)。下面是简化后的代码:
private def build(forceCreate: Boolean): SparkSession = synchronized {// 1. 先查 active sessionval active = getActiveSession// 2. 再查 global default sessionval default = getDefaultSession// 3. 没有现成 session,就创建 / 复用 SparkContextval sparkContext = SparkContext.getOrCreate(sparkConf)// 4. new SparkSession(...)val session = new SparkSession(sparkContext, existingSharedState = None, ...)// 5. 设置 default 和 activesetDefaultSession(session)setActiveSession(session)session}
对应行号:
classic/SparkSession.scala:1018:查找 active sessionclassic/SparkSession.scala:1028:查找 default sessionclassic/SparkSession.scala:1045:SparkContext.getOrCreate(sparkConf)classic/SparkSession.scala:1052:new SparkSession(...)classic/SparkSession.scala:1058:设置 default 和 active sessionclassic/SparkSession.scala:1065:getOrCreate()调用build(false)
所以创建顺序是:
SparkSession.builder.getOrCreate
→ 查 active/default session
→ SparkContext.getOrCreate
→ new SparkContext(conf)
→ create SparkEnv
→ create Scheduler
→ new SparkSession(sparkContext, ...)
九、几个常容易混淆的问题
1. 一个应用能有多个 SparkContext 吗?
通常不能。SparkContext 是应用级别的核心上下文,同一个 JVM 里一般只允许一个 active SparkContext。
这也是为什么 SparkContext.getOrCreate 会先找已有实例,找不到才 new SparkContext(config)。入口在 SparkContext.scala:3070,真正创建在 SparkContext.scala:3075:
setActiveContext(new SparkContext(config))2. 一个应用能有多个 SparkSession 吗?
可以。
多个 SparkSession 可以共享同一个 SparkContext,但拥有不同的 SessionState。例如你可以用 spark.newSession() 创建隔离的 SQLConf / 临时视图空间。
3. SparkEnv 是全局唯一的吗?
不是全局集群唯一,而是每个 JVM 一个。
Driver JVM 有 Driver 的 SparkEnv
每个 Executor JVM 有自己的 SparkEnv
所以 SparkEnv.get 返回的是当前进程的环境,不是整个集群的环境。
4. 为什么 SparkSession 要有 sharedState 和 sessionState 两套状态?
因为有些东西应该共享,有些东西应该隔离。
cache、external catalog、statusStore:更适合跨 Session 共享
SQLConf、临时视图、UDF、Analyzer/Optimizer:更适合每个 Session 隔离
十、实战:在 spark-shell 里看三者
val spark1 = SparkSession.builder().getOrCreate()val sc1 = spark1.sparkContextval env1 = SparkEnv.getval spark2 = spark1.newSession()val sc2 = spark2.sparkContextprintln(s"same SparkContext: ${sc1 eq sc2}")println(s"same SharedState: ${spark1.sharedState eq spark2.sharedState}")println(s"same SessionState: ${spark1.sessionState eq spark2.sessionState}")println(s"env executorId: ${env1.executorId}")println(s"blockManager: ${env1.blockManager}")
输出:
same SparkContext: true
same SharedState: true
same SessionState: false
env executorId: driver
blockManager: org.apache.spark.storage.BlockManager@5cfa2ac5
如果你想看 Executor 端的 SparkEnv,可以写一个简单 map:
sc.parallelize(1 to 2, 2).mapPartitions { it =>Iterator(SparkEnv.get.executorId)}.collect().foreach(println)
local 模式下可能仍然看到 driver 或本地 executor 标识,集群模式下会看到 executor id。
十一、总结
三者关系再压缩一次:
| 对象 | 一句话定位 | 生命周期 | 典型入口 |
|---|---|---|---|
SparkSession | SQL / DataFrame 门面 | 可以多个 | SparkSession.builder.getOrCreate() |
SparkContext | Spark 应用核心 | 通常一个 | SparkContext.getOrCreate / new SparkContext |
SparkEnv | 当前 JVM 的运行时工具箱 | Driver / 每个 Executor 各一个 | SparkEnv.createDriverEnv / createExecutorEnv |
完整创建链路:
SparkSession.builder.getOrCreate
→ SparkContext.getOrCreate
→ new SparkContext
→ SparkContext.createSparkEnv
→ SparkEnv.createDriverEnv
→ SparkContext.createTaskScheduler
→ new DAGScheduler
→ new SparkSession
→ sharedState
→ sessionState
三个最重要的总结:
SparkSession 是 SQL 层入口,不是执行引擎本身。 SQL 编译用到的 Parser / Analyzer / Optimizer 都藏在 SessionState 里。
SparkContext 是应用级核心。 它持有 DAGScheduler、TaskScheduler、SchedulerBackend 和 Driver 端 SparkEnv,所有 RDD / SQL 最终都会落到它这里。
SparkEnv 是进程级运行时环境。 Driver 和 Executor 都有 SparkEnv,但里面组件角色不同:Driver 端 mapOutputTracker 是 Master,Executor 端是 Worker。
每天花费10分钟学习spark,让你技术之路走得更稳、更快。
喜欢的点个关注。
