 夜雨聆风
夜雨聆风AI 简报 0625
AI 平台竞争开始向芯片、协作入口与知识接口三层同时下沉
今天的主线落在三层底座一起收紧:上层协作入口、中层知识编排和底层推理基础设施正在同步变强,AI 系统的工程栈也随之更完整。
今天最值得关注的是 AI 平台的三层底座在同一天继续补齐。上层是 Claude Tag 这类直接进 Slack 的团队协作入口,中层是 Gemini Enterprise 和 Open Knowledge Format 这类把 agent 编排、治理和知识交换做成平台能力的系统层,底层则是推理芯片、推理网关和本地推理引擎继续往生产形态靠拢。对架构师来说,接下来更关键的工作是把入口、知识和推理层接成一条稳定链路。
今日重点速览
团队协作入口开始直接把 agent 拉进 Slack 和业务频道。
知识编排与推理网关正在从零散能力收敛成平台级接口。
Agent 训练和故障诊断研究都在强调长流程、长轨迹和上下文外问题。
01 / MODEL
今日重点 AI 动态
OpenAI 与 Broadcom 把竞争继续压到推理芯片层
发生了什么:OpenAI 在 2026-06-24 公布与 Broadcom 联合推出面向 LLM 推理优化的 inference chip,官方已把芯片层能力直接放进新闻主条目。
为什么重要:这说明前沿模型公司的竞争继续从模型层往算力供给层下沉。谁能更早掌握推理成本、吞吐和供应链节奏,谁就更容易把大模型服务做成稳定生意。
你该关注:后续应重点看这类自研或联合芯片会优先服务哪些推理场景,以及它会不会进一步改变 API 成本和延迟曲线。
Claude Tag 让团队可以在 Slack 里直接委派 Claude
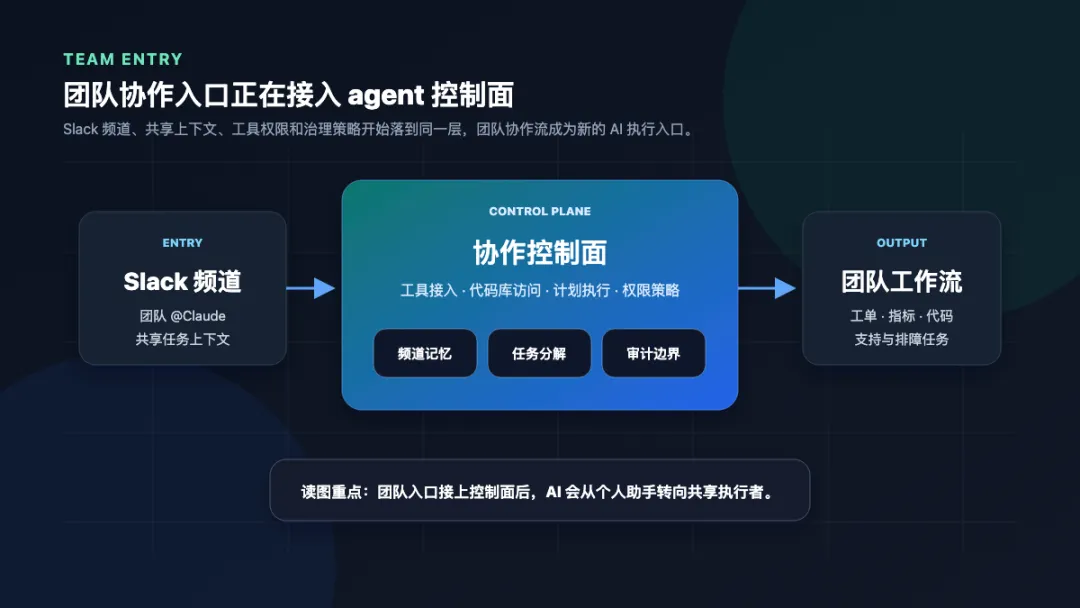
这张图想说明:团队协作入口接上控制面后,AI 会从个人助手转向共享执行者。
发生了什么:Anthropic 在 2026-06-23 发布 Claude Tag,先从 Slack 开始,让 Claude 以团队成员身份加入指定频道,接入选定工具、数据和代码库,并支持在频道内直接 @Claude 委派任务。
为什么重要:这把 agent 入口从个人对话框推进到团队协作频道。上下文、任务和执行开始围绕真实团队协作流转。
你该关注:企业后续更该关注 Claude 被授予哪些频道、工具和代码库权限,以及跨频道记忆和任务委派的审计边界。
Gemini Enterprise 开始把 agent 开发、编排和治理打成一套平台
发生了什么:Google Cloud 近期把 Gemini Enterprise 定义为面向 agentic era 的端到端系统,官方描述里直接强调 agent development、orchestration 和 governance 的统一平台定位。
为什么重要:平台厂商开始把模型、SDK 和企业 agent 控制面打成一套整体方案。模型、界面、权限和部署框架会越来越像同一个采购决策。
你该关注:团队接下来应优先看这类平台是否真的把身份、策略、工具接入和运维观测打通,避免只得到多个入口的简单捆绑。
02 / INFRA
开源与工程生态
GKE Inference Gateway 开始把 prefix caching 做成可量化的推理入口能力
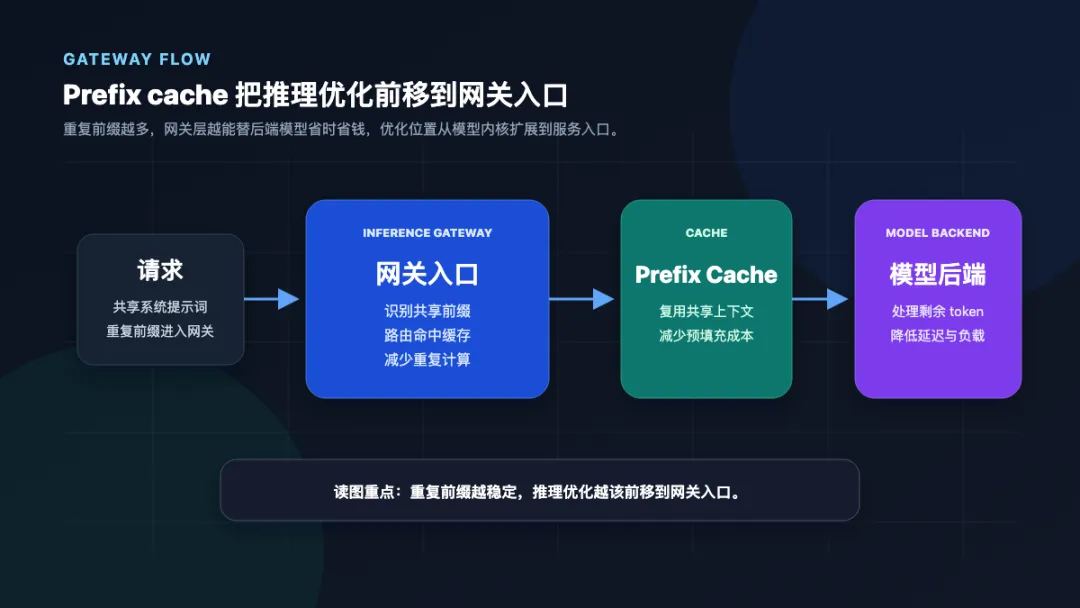
这张图强调的重点是:推理优化正在前移到网关入口,模型内核之外也有降延迟空间。
发生了什么:Google Cloud 官方在 2026-06 中给出一份最新报告,称 GKE Inference Gateway 结合 prefix caching 可带来最高 92% 的 AI 响应提速。
为什么重要:推理优化正在从模型内核技巧转成网关层能力。对于多租户服务和重复前缀明显的业务,入口网关本身就会成为降延迟和控成本的重要位置。
你该关注:更值得跟的是这类网关优化在多模型、多租户和混合缓存场景下是否仍然稳定,以及平台是否暴露足够可观测指标。
Open Knowledge Format 试图把知识交换变成统一接口
发生了什么:Google Cloud 在 2026-06-12 发布 Open Knowledge Format,方向是改进数据与知识共享,让结构化知识交换不再依赖各家私有拼装方式。
为什么重要:当 agent 系统越来越依赖知识对象流转时,统一格式比单点模型能力更容易决定系统能否跨团队、跨工具和跨平台协作。
你该关注:后续应重点看 OKF 是否能进入更多知识库、分析平台和 agent 框架,否则它只会停留在概念层。
Ollama 最新 release 继续把本地推理往可分发引擎推进
发生了什么:Ollama 在 2026-06-17 发布 v0.30.10,新增让 Command A 与 North 系列模型在 Apple Silicon 上通过 MLX engine 运行,并同步更新底层 llama.cpp 构建。
为什么重要:本地推理的关键已经从“能跑”推进到工程分发层:不同模型族、不同芯片和不同引擎需要稳定落到同一入口。Ollama 正在继续补这层工程完整度。
你该关注:如果团队考虑端侧或开发机本地推理,应优先验证 MLX 路径的兼容性、模型覆盖面和后续服务接口是否稳定。
03 / RESEARCH
论文与研究动态
OpenThoughts-Agent 开始系统回答 agent 数据该怎么做
发生了什么:6 月 23 日提交的 OpenThoughts-Agent 提出一套全开放的数据构造流程,做了 100 多组消融实验,并用 10 万条样本把 Qwen3-32B 在 7 个 agent benchmark 上做到平均 44.8%,比 Nemotron-Terminal-32B 高 3.9 个百分点。
为什么重要:开源 agent 模型的瓶颈正在逐步从底模能力转向数据配方。谁更懂任务来源、多样性和数据管线,谁就更可能把 agent 能力稳定复现出来。
你该关注:短期更值得关注它公开的数据管线和训练集是否能被其他开源模型复用,单次榜单分数只适合作为辅助信号。
SAFARI 用主动调查替代整段轨迹硬塞上下文
发生了什么:同样在 6 月 23 日提交的 SAFARI 针对长轨迹 agent 故障归因,采用工具增强的主动调查循环和短期记忆,减少对一次性塞入全部执行轨迹的依赖;论文报告在 Who&When 数据集上提升 20%,在 TRAIL 的 GAIA 子集上提升 19%。
为什么重要:这类研究说明长流程 agent 的调试与评测不能继续依赖更长上下文硬扛,系统化的检索、分段读取和诊断循环会越来越重要。
你该关注:如果团队已经在做多步 agent,后续应把轨迹索引、故障定位工具和跨轮短期记忆一起纳入调试链路。
04 / 判断
AI 系统的竞争面正在明显变宽,入口、知识接口和推理底座开始同时决定交付质量。
对 AI 架构师和技术团队,今天更值得落地的动作有三个:
先补协作入口:不要只盯住聊天框接模型,应先判断 AI 是否已经进入团队真实协作入口,例如 Slack、IDE、终端和工单系统。
再补知识接口:如果系统后续要做多 agent 与跨团队协作,应尽早统一知识对象、共享格式和工具接入边界。
最后看推理栈:成本、缓存、网关和芯片层能力正在越来越早影响产品形态,推理栈不再只是基础设施团队的事。
今日一句
下一阶段更稳的 AI 系统,不只要有强模型,还要把团队入口、知识接口和推理底座接成一条闭环。
参考链接
https://openai.com/index/openai-and-broadcom-unveil-llm-optimized-inference-chip/
https://www.anthropic.com/news/introducing-claude-tag
https://cloud.google.com/blog/products/ai-machine-learning/the-new-gemini-enterprise-one-platform-for-agent-development
https://cloud.google.com/blog/products/containers-kubernetes/gke-inference-gateway-prefix-caching-accelerates-ai-inference
https://cloud.google.com/blog/products/data-analytics/how-the-open-knowledge-format-can-improve-data-sharing
https://github.com/ollama/ollama/releases/tag/v0.30.10
https://arxiv.org/abs/2606.24855
https://arxiv.org/abs/2606.24626
