 夜雨聆风
夜雨聆风

整理编辑|TesterHome社区
来源|Snap Engineering Blog
以下为作者观点:
AI编程工具从本质上改写了软件开发流程。
在Snap,工程师日常使用Cursor、Claude Code等工具,开发效率的提升实实在在:今年迄今,合并后的拉取请求(PR)数量涨幅达60%。但新的瓶颈随之而来:全员编码提速后,瓶颈并未消失,只是发生了转移——瓶颈集中到了代码评审环节。团队面临PR数量激增、单份PR体量变大的问题,评审人力被持续摊薄,最终导致评审队列积压、合并周期拉长。编码速度提升却跟不上评审效率,只会不断累积技术债务。为此,Snap自研了内部AI代码评审助手CodePal。我们的目标是打造一套高度智能、贴合Snap工作流程的AI评审系统,为PR提交者提供真实、有价值且快速的反馈,减轻团队成员的评审负担。我们的愿景是:让CodePal成为工程师在软件开发生命周期中常态化协作的评审伙伴。如今,Snap 90%的PR都会先经过CodePal评审,再进入人工评审环节。
为何选择自研在决定自研前,我们评估了多款商用第三方工具。当前AI代码评审赛道日趋拥挤,各类产品均具备亮眼能力,但在Snap的核心需求上,仍存在两处关键短板:1. 集成深度不足
Snap工程基建庞大且高度互联,构建系统、部署流水线与内部工具链均有专属规范,商用工具难以适配。CodePal需要识别Snap专属的协议定义、内部配置体系,适配数百项服务间协作的细节;同时团队层面还需大量定制化配置,多数工具仅能提供部分能力,无法覆盖全部需求。仅靠少量配置项的通用工具,无法满足我们的场景。2. 响应速度受限
我们两周内就完成了可用的端到端原型,而第三方采购流程往往尚未走完。从上线首周起,CodePal即可评审自身提交的PR,发现问题的速度远超人工评审。
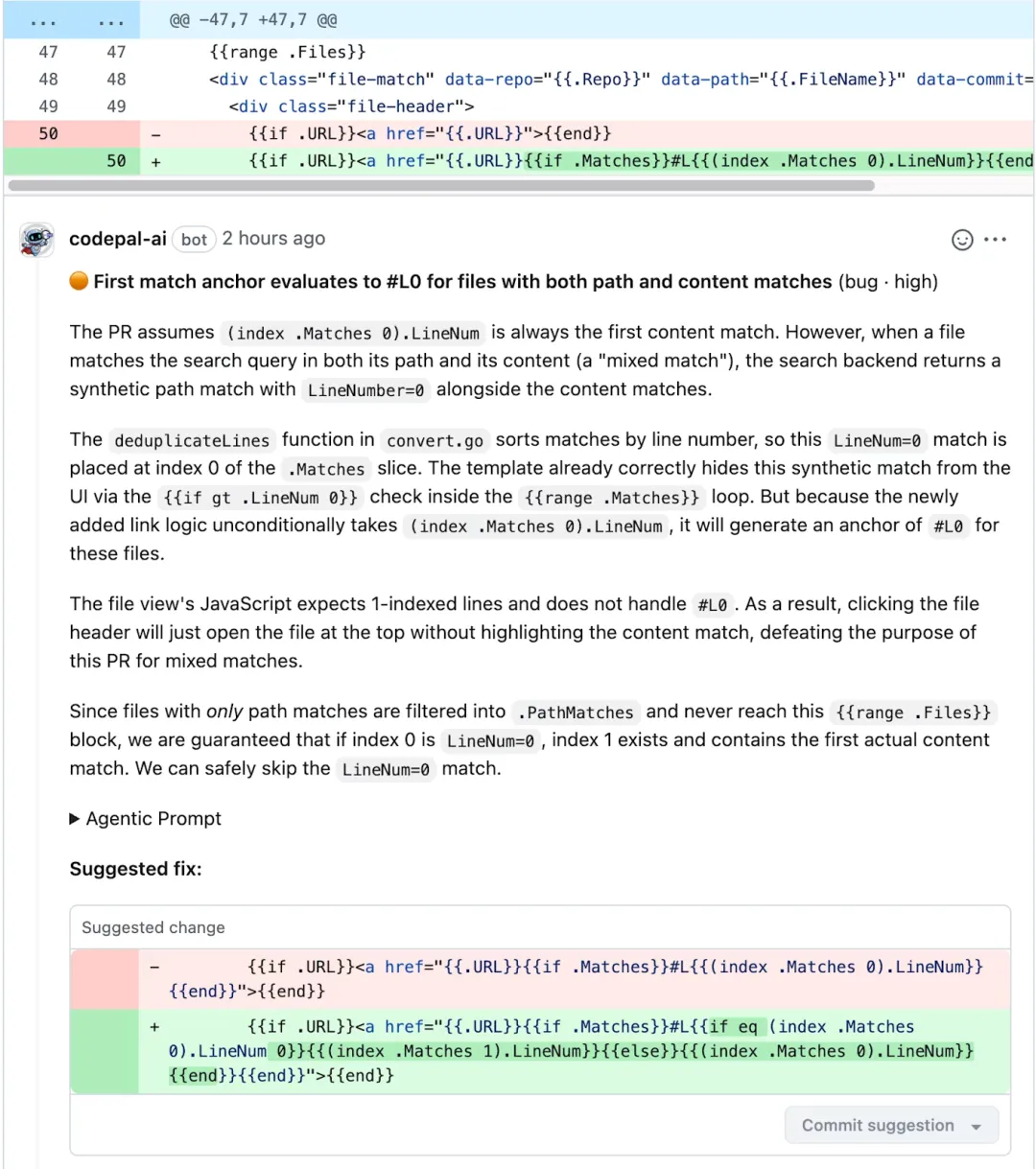
CodePal核心能力核心逻辑上,CodePal与常规评审工具一致,以代码差异为分析基础,但它具备仓库级深度符号上下文,且越来越多评审场景可跨仓库获取信息,分析维度远不止表面检查。跨仓库能力将在第二篇详细展开。
跨仓库依赖追踪在多数评审场景中,CodePal可依托内部语义化代码检索系统,突破仓库边界,覆盖Snap全量代码库。在函数签名变更合并前,它能识别出会受影响的下游调用方——即便这些调用位于其他仓库。该能力已提前拦截多起跨仓库合并故障,这类问题仅靠人工查看代码差异,往往难以被发现。代码检索能力及其与CodePal的集成,将在第二篇深入说明。缺陷检测CodePal可识别编译与常规测试套件难以覆盖的问题:逻辑错误、空指针风险、竞态条件、资源泄漏、异常处理缺失、类型不匹配、边界场景疏漏与状态管理异常等。针对特定仓库,还可启用专属定制检查,实现场景化评审。工程师普遍认可CodePal的检出结果,其中多数被采纳的缺陷(PR评审中获点赞确认)被标注为严重或高优先级——若没有CodePal,这类问题只能依赖人工评审拦截,极易流入生产环境。同时,它还能在开发阶段、上线前提前发现潜在性能隐患。语义化摘要、描述与差异解读除逐行分析外,CodePal可生成语义化差异摘要,说明PR的改动目的与核心逻辑,帮助评审者快速建立全局认知,再深入代码细节;还能自动生成PR标题、描述,以及发布说明、迁移步骤等结构化内容,全部从代码变更中推导生成。这些能力大幅节省提交者与评审者的时间:评审者无需花费十分钟理解改动意图,可直接评估方案合理性。摘要、描述、评审结论等输出,均基于同一套上下文构建,下文将展开说明。
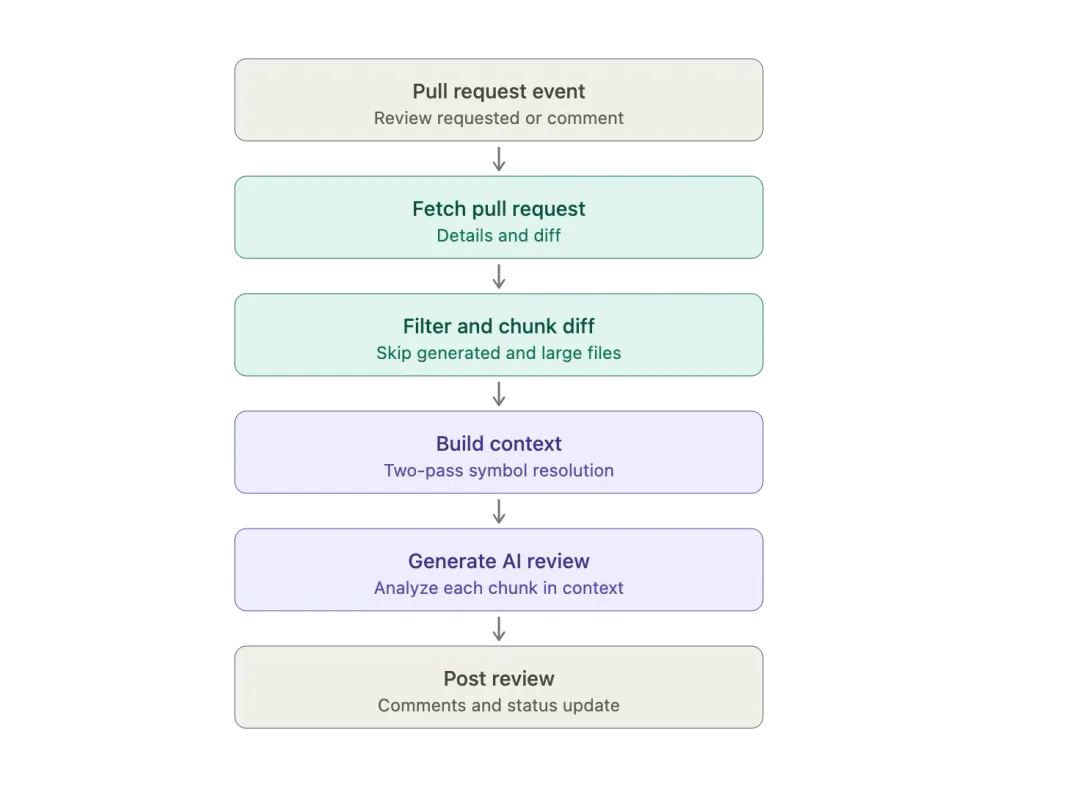
代码上下文构建孤立的代码差异,往往不足以支撑完整逻辑判断。例如新增一行return user.Profile.Email,单看并无异常,但若知晓该代码路径中Profile可能为空,就需额外校验——而这类信息分布在差异未涉及的多个文件中。多数AI评审工具要么忽略上下文导致漏检,要么全仓灌入提示词,造成不必要的算力损耗。CodePal则采用折中优化方案。符号上下文与双阶段文件筛选CodePal通过双阶段流程构建上下文:1. 第一阶段借助tree-sitter解析仓库,建立符号与文件的索引映射;2. 第二阶段分析代码差异,提取关联符号并匹配索引,按符号关联度对文件打分排序,在token预算内选取最相关的N份文件。CodePal不只看改动内容,更先完成代码逻辑理解。
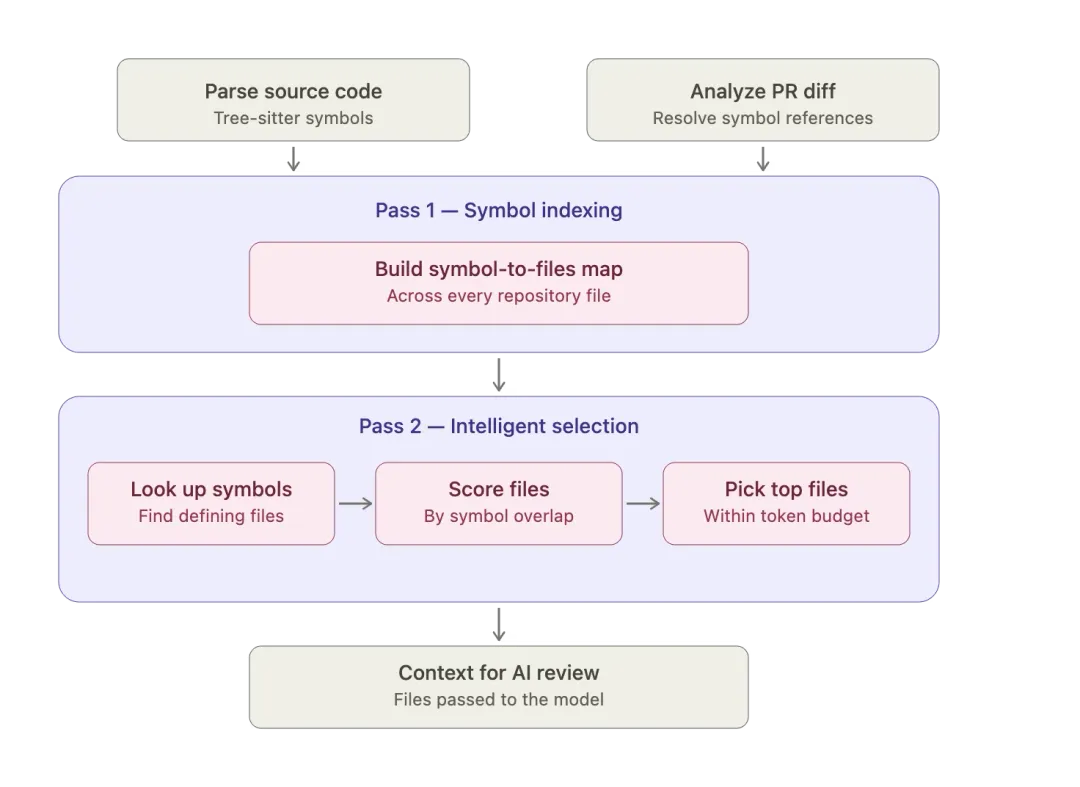
无需克隆仓库、不生成本地工作副本在说明分析逻辑前,先明确CodePal的运行特性:不克隆仓库,所有评审完全在内存中通过GitHub Enterprise(GHE)接口完成,不检出本地副本、不落地源码,也不长期维护仓库镜像。这是主动设计的约束,而非能力局限。
Snap大型仓库克隆耗时久、存储成本高,若按单评审克隆架构,会压垮基建与GHE服务。我们依托Git树级差异识别改动范围,仅拉取所需文件片段,配合双阶段筛选压缩处理集:无论仓库规模多大,单次评审通常仅需少量接口调用、读取数百KB源码,保障规模化落地。该架构带来显著收益:主流程一次性完成高开销的符号索引与文件筛选,将上下文存入共享存储;代码评审、摘要生成、描述生成三个子流程复用同一份上下文,摘要与描述的生成几乎无额外上下文成本,仅产生存储开销。这一共享设计,也为第二篇中代码检索的接入奠定基础。
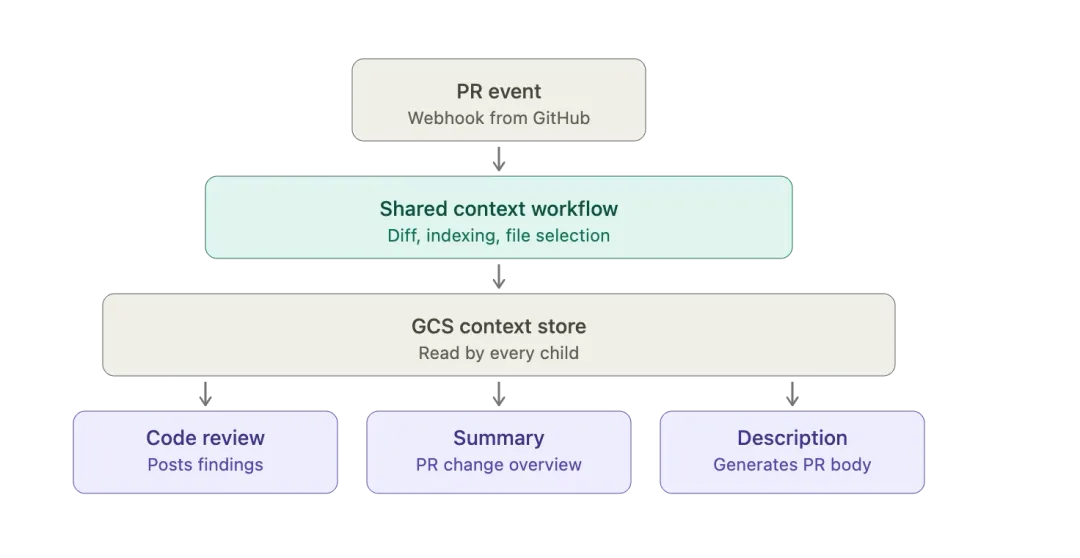
评审循环常规AI评审逻辑,是将差异与上下文传入模型并生成结论。我们也曾尝试该方案:虽能检出真实缺陷,但易产生幻觉、多次输出结果自相矛盾,结论随机性极强。为此,我们设计了多阶段迭代评审循环,成为CodePal的核心创新点。
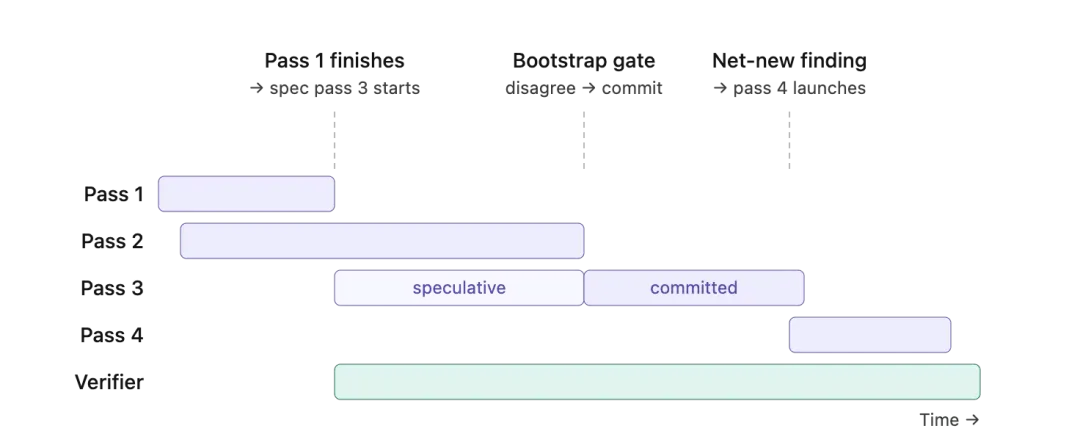
并行基准轮次首轮启动两组并行评审,采用同一模型、不同采样参数,核心目标为缺陷挖掘。两次结果交叉比对,可判断结论的可信度。前瞻第三轮与共识判定任意一轮基准评审完成后,立即启动可中断的第三轮前瞻分析,结果可随时丢弃;待两轮基准评审结束,调度器比对结论:若结果一致,立即终止第三轮;若存在分歧,则保留其已输出内容,纳入最终结论。预研流水线递进第三轮起,一旦发现未收录的新问题,无需等待当前轮次结束,即可启动下一轮分析;若一轮无新增结论,则不再触发后续流程。该机制实现高效收敛:待发现问题较多时增加轮次,差异无隐患时及时终止。评审循环配套独立的校验器:以长会话模型持续处理评审结论,完成最终过滤,解决早期单轮评审的幻觉与矛盾问题。例如校验结论中提及的符号是否真实存在于上下文,大幅降低幻觉结论被提交的概率。整体而言,该循环的分析深度优于单轮评审,结果稳定性远高于单次模型调用;虽算力消耗有所上升,但共识机制剔除无效前瞻计算,收敛规则避免冗余分析,实现成本可控。
单季度内覆盖率从0到90%
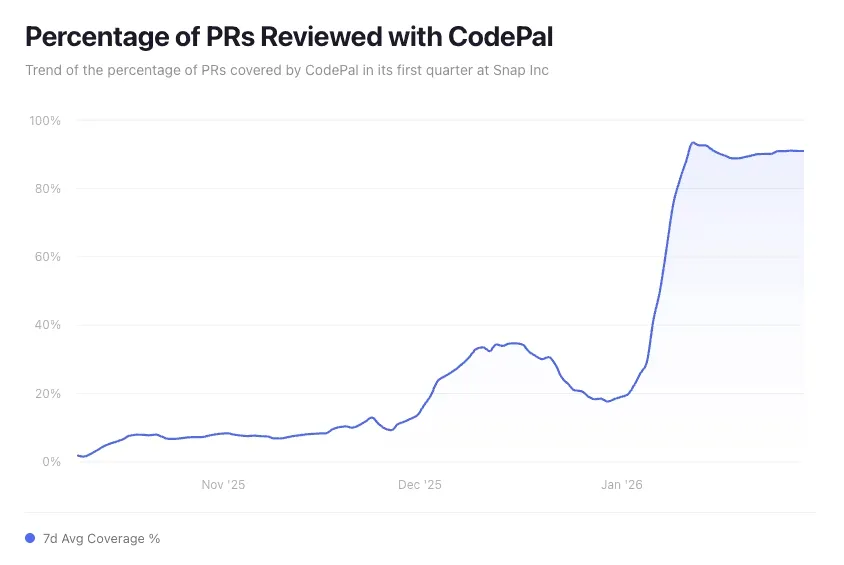
CodePal初期为可选试用功能,分析PR中的缺陷与安全隐患,初始覆盖率仅9%;随后在部分核心仓库强制启用,凭借稳定全面的评审快速推广。随着仓库负责人主动接入,300余个仓库自愿启用,工程师正面反馈率超70%。当人工评审遗漏本可被CodePal拦截的缺陷后,团队普遍要求将其设为默认评审工具;批量为团队开启自动接入后,无团队申请关闭,需求以常态化启用为主。短短一个季度内,Snap实现AI评审PR覆盖率从近乎0到90%的跨越,且质量同步提升:同期缺陷检出召回率从30%升至80%,工程师对缺陷结论的正面认可度达80%。
质量量化与优化90%覆盖率是首个里程碑,但高覆盖不等于可信:工具曝光度提升后,各类短板也随之显现——评审结果不稳定、模型误判业务意图、新功能上线前缺乏验证流程,且仅依赖用户反馈迭代,效率低下。为此,我们搭建完整评估体系,明确优劣表现,并建立全量变更的A/B测试流程;基于真实工程师反馈构建基准数据集,以提升真实缺陷召回率、降低误报率为核心目标,兼顾速度与成本,优先保障可信度。四项核心优化推动召回率显著提升:1. 深化代码理解:跨文件符号解析+扩展语法解析,从猜测意图升级为逻辑理解;2. 落地前文所述的多阶段评审循环;3. 扩大检测范围:缺陷覆盖类别从8类拓展至12类;4. 增量评审:新提交触发定向重审,已修复文件自动归档相关结论。优化成效显著:真实缺陷召回率从30%升至80%;基准数据集误报率降至0%(基于隔离测试集统计,非线上流量);高认可度缺陷检出量提升75%,工程师正面反馈维持80%。
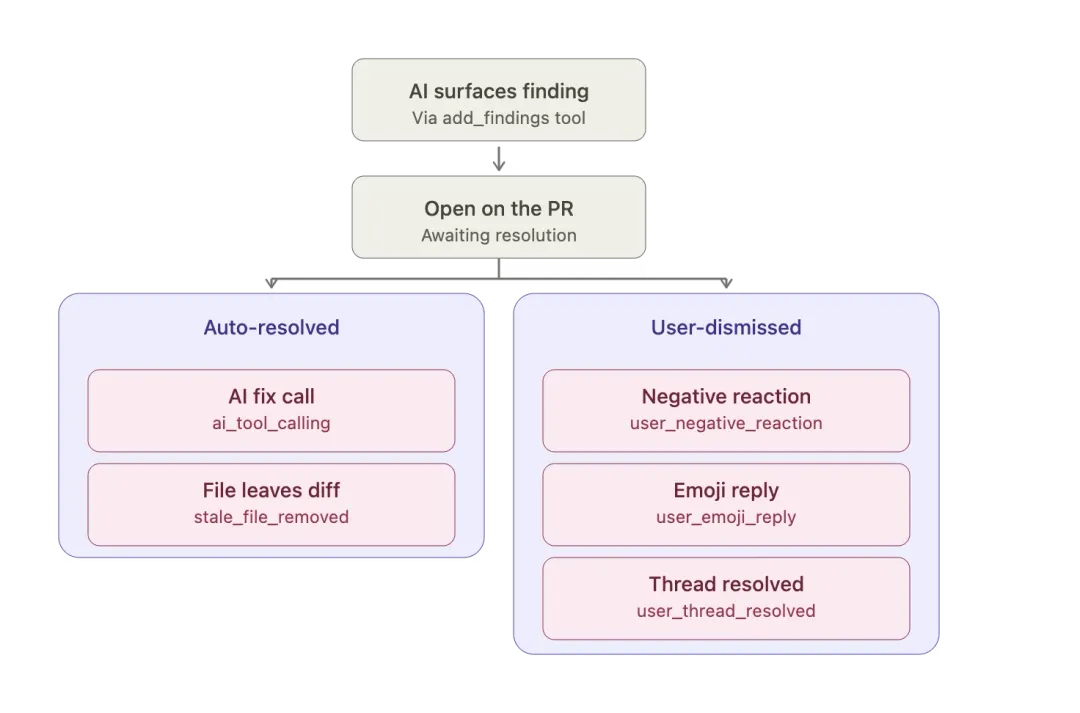
为每一条结论建立信任宏观指标反映系统整体进步,但单条评审结论同样需具备说服力——工程师无法容忍强制评审带来的无效噪音。我们通过前置校验与反馈闭环保障结论可信,工具随使用持续迭代优化。前文提及的校验器,会在结论提交前完成完整性核验:伴随评审流程并行运行,逐条核对结论与上下文匹配度,例如确认引用符号真实存在。幻觉、矛盾结论会提前拦截,不进入评审流程。系统可靠性依托结论生命周期反馈闭环构建:工程师可对CodePal评论点赞/点踩,反馈实时记录;正面反馈标记真实缺陷,负面反馈标记误报;未处理、已修复的结论也同步纳入基准数据集,联动A/B测试框架。所有提交、驳回、修复、忽略的结论,均成为迭代依据,驱动系统持续优化。
实践经验总结在Snap规模化落地CodePal后,我们沉淀出几项核心认知:1. 上下文优先级高于顶尖模型
我们持续测试各类模型,平衡评审质量、成本与速度;多数漏检案例中,根源并非模型能力,而是上下文信息不足。前沿模型具备极强推理能力,只要信息完整即可识别缺陷;同时需避免上下文过载,这也是评审分模块拆解的核心原因。2. 开箱即用通用性强
多数仓库无需额外配置,即可获得高质量评审;基础模型、代码差异与符号上下文结合,足以覆盖多语言、多框架场景,检出真实问题、输出有效反馈。3. 复杂仓库需深度定制
超大型仓库贡献者众多、内部库体系复杂、长期积累专属规范,通用评审易产生噪音;通过.codepal.yaml配置与路径化规则定制,可显著优化评审效果。4. 反馈闭环是核心动力
工程师的点赞点踩直接影响后续评审,形成正向飞轮——参与度越高,工具越贴合团队实际需求。5. AI评审并非替代人工,而是重塑评审流程
工程师普遍反馈,CodePal将人力从常规问题中解放,聚焦架构设计、长期可维护性、业务影响等需人工判断的核心事项;常规问题提前拦截,评审重心向高阶决策转移。
核心数据• 过去4个月,CodePal完成超20万次评审,覆盖90%PR,拦截数千起已确认问题,在人工评审前、上线前完成修复;• 单次评审耗时10分钟内,而人工首评中位等待时长约5小时,为提交者提供快速迭代反馈;• 单季度内PR评审覆盖率从0升至90%;• 工程师对缺陷结论正面认可度80%;• 单次评审平均成本约0.4美元。
长远布局CodePal是Snap长期技术布局的一环:未来数年内,Snap绝大多数PR将由可信AI系统自动编写、评审并完成核准,人力聚焦于需专业判断、审美取舍与责任兜底的决策环节。当前CodePal可评审人工与AI编写的代码,但最终仍需工程师核准;从「可信评审者」到「可信核准者」,正是我们不断发力的核心方向。
原文章链接:https://eng.snap.com/codepal

大会火热报名中
目前购票8折优惠
5人及以上购票享团体优惠,每张再减100元
时间越晚折扣越少噢~
扫描上方图片二维码,即可参会

人工智能驱动的自主测试,LinkedIn的质量保障智能体(QA‑Agent)搭建方式、架构设计思路
600亿美元收购Cursor:全球AI编程工具格局全景复盘与软件工程智能体时代的到来
AI测试|33个需要重点关注的大语言模型评测指标(附学习建议)
容器镜像改造案例:AI驱动测试体系搭建与Distroless批量切换
Visa开源AI漏洞管理平台背后:软件安全正在进入“Agentic AI时代”
字节跳动AI编程实践:TRAE走通的那条“把AI塞进真实研发机器”的路
研发效能|AI时代的文档策略演变:为什么集中式知识库成为企业必备
大厂AI Coding走到哪了?从得物×腾讯的两份“万字级”实践说起
