 夜雨聆风
夜雨聆风
自2023年以来,大模型浪潮席卷各行各业,AI相关的高频词几乎每天都在刷新认知:Transformer、Embedding、Agent、RAG、MCP、RLHF、CoT、Diffusion……
第一次看这些词的时候,没有一个词让我立刻知道"它和其他词是什么关系"——它们是并列的、嵌套的、还是独立的概念?
此次本文就是试着回答这个问题的,把分散在各处的AI词汇,收拢到一张看得清脉络的族谱图里:哪些是底层原理、哪些是训练阶段的产物、哪些是算力层的硬件、哪些是产品层的工程工具、哪些是新兴的业务方向。读到后面你会发现,很多看起来很高大上的词,其实都可以拆解成几个基础概念的组合。
前篇《智能、语言、LLM和Agent》已经把"心智化"、"LLM猜词机制"、"Agent四大组件"这些基础概念拆开讲过了,本文不再重复,而是把笔墨留给更广的词汇生态——你会发现,很多新词其实只是旧词在新场景下的变形。
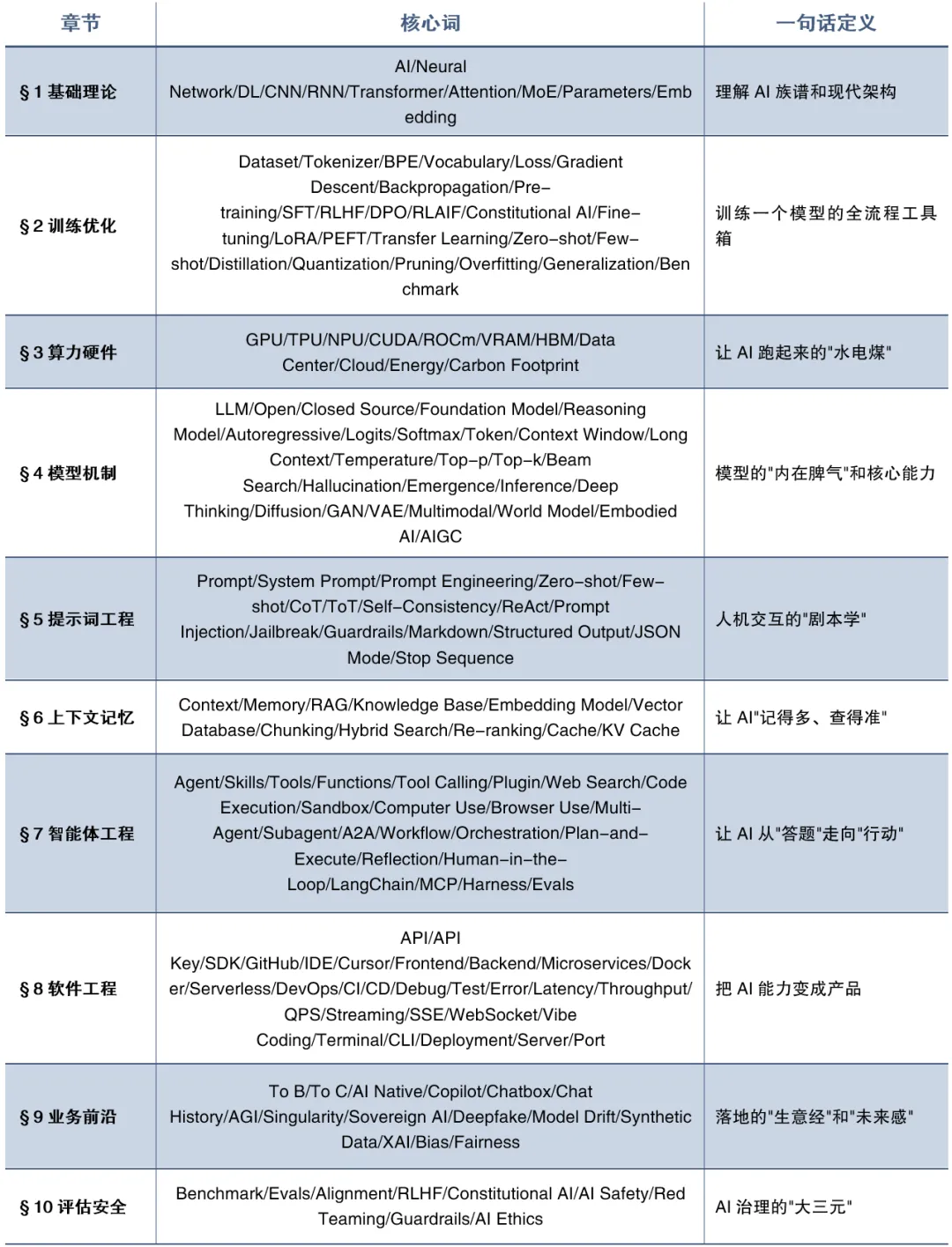
1、基础理论与底层架构
要弄懂AI,第一步是搞清它的族谱。"AI"(Artificial Intelligence,人工智能)是总称——所有会思考、会决策、会学习的智能系统都归它管,会下棋的电脑、能聊天的助手,都是这个大家族里的成员。这个家族的核心骨架叫"Neural Network"(神经网络)——一种模仿生物大脑神经元连接方式的计算结构。2010年以后这一波AI浪潮,几乎所有的明星产品都建立在这个骨架上,包括ChatGPT、Claude、Gemini。神经网络的现代加强版叫"Deep Learning"(DL,深度学习)——堆叠多层神经元让模型能从数据里自动提取特征,不用人手动设计"什么算猫、什么算狗"。这一波AI浪潮的真正起点就是深度学习——没有DL,就没有后面的所有故事。
DL内部也有老前辈和新人的区分:
①"CNN"(Convolutional Neural Network,卷积神经网络)——图像识别的王者,能像人眼一样扫描局部特征,从像素里看出猫狗。2010年代初AlexNet在ImageNet上的那次屠榜,算是CNN高光的起点。
②"RNN"(Recurrent Neural Network,循环神经网络)——处理序列数据的老炮,文本、语音、时间序列都曾是它的主场。它现在基本被Transformer卷下了历史舞台,但2015-2018年那一波机器翻译进步的红利,它吃到了大头。
当下最主流的架构是"Transformer"——依赖"Attention"(注意力机制)来捕捉句子中词与词之间的语义关联。比如"小明借给小华一本书",模型能准确判断动作的方向是从小明到小华,而不是反过来。这背后依赖的就是Attention的加权机制。
很多顶尖大模型还用了"MoE"(Mixture of Experts,混合专家)架构——把一个大模型拆成许多小专家,每次只激活其中一部分来回答问题。我自己的理解是它像医院里的分诊台:先判断你该看哪个科,再挂对应专家的号,省时省力。
"Parameters"(参数)是模型的知识储备,每个参数都像神经元之间的一根线路——线路越密,模型能记住和理解的内容就越多。GPT-3有175B个参数,传闻GPT-4有1.8T(这个数字没有官方确认,仅是第三方推测)。
最后,"Embedding"(嵌入)是连接人类语言和机器数学的关键桥梁——它把文字转换成向量,让"北京-中国+日本≈东京"这种跨语言、跨实体的语义关系可以被算术化。没有Embedding,AI根本读不懂语言——只能处理一串串ID,而不能理解ID之间的语义。
2、模型训练与优化技术
一个模型从白纸一张到能说会道,背后是层层训练。可以把这个过程看作培养一个人才的过程。
首先得有"Dataset"(数据集)/"Training Data"(训练数据)——这是模型的教材。没有数据就没有训练。所谓"吃什么决定长成什么样"——垃圾教材喂进去,模型也只会吐垃圾。
"Tokenizer"(分词器)是文本进入模型的第一把切菜刀——它把句子切成模型能消化的最小单位。后文§4还会详细聊"Token"(词元)这个概念,这里先记住它是模型消化文本的最小颗粒即可。主流的切法叫"BPE"(Byte Pair Encoding,字节对编码),核心思路就是先把高频的字词合并,再把生僻字拆开,兼顾效率和覆盖率。模型能认出的所有Token构成"Vocabulary"(词表)——你可以把它当成模型的全部汉字表。
"Pre-training"(预训练)是第一关——通识教育,让模型在海量数据中奠定通用能力。预训练令人印象最深的是:原来真的可以无监督地学完整个互联网——只要数据够大、算力够猛。
训练过程不是魔法,是工程。背后有三件发动机在默默工作:
①"Loss Function"(损失函数)——衡量模型答得有多差
②"Gradient Descent"(梯度下降)——告诉模型该怎么改
③"Backpropagation"(反向传播)——把错误信号层层传回每一根线路
三件套少了任何一件,模型都训不出来。训练时还有四个节奏单位:"Epoch"(整本教材过一遍)、"Batch"(一批样本)、"Batch Size"(每批多少样本)、"Iteration"(每批更新一次参数)。
但光有通识还不够,还得有"Post-training"(后训练)来塑形——其中最常见的两招是"SFT"(Supervised Fine-Tuning,监督微调)和"RLHF"(Reinforcement Learning from Human Feedback,人类反馈强化学习)。前者相当于按正确答案学,后者相当于按老师的反馈改——两者的共同目标都是让模型"Alignment"(对齐)人类意图,并尽量减少"Data Bias"(数据偏差)。
"RLAIF"(用AI反馈代替人类反馈)解决了人类标注太贵的问题,Anthropic主推的"Constitutional AI"(宪法式AI)给AI立一套宪法原则来让它自评自己。
2024年起,"DPO"(Direct Preference Optimization,直接偏好优化)异军突起——它跳过了复杂的强化学习框架,直接让模型学会哪个回答更好。
如果说预训练是通识教育,那"Fine-tuning"(微调)就是专业进修。考虑到完整微调成本太高,"LoRA"(Low-Rank Adaptation,低秩适配)这种轻量化微调技术应运而生——它属于更大的"PEFT"(Parameter-Efficient Fine-Tuning,参数高效微调)门派,只调整一小部分参数就能达到接近全量微调的效果。就像在主干道上开一条小岔路——既省钱又高效。"Transfer Learning"(迁移学习)则是更底层的举一反三能力——在一个任务上学到的知识,可以迁移到相关的新任务上。
模型还能举一反三地处理新问题——"Zero-shot Learning"是完全不学就会,给一个新任务也能上手;"Few-shot Learning"是看一两个例子就懂。
"Knowledge Distillation"(知识蒸馏)走的是大师带徒弟的路线——让大模型(老师)把知识言传身教给小模型(学生)。"Quantization"(量化)和"Pruning"(剪枝)则是两套压缩术——量化降低参数精度,剪枝砍掉不重要的线路,两者经常搭配使用,让模型在手机、嵌入式设备上也能跑起来。手机端LLM这两年进步神速,很大程度就是量化技术成熟的功劳。
训练中还有几个绕不开的坑:
①"Overfitting"(过拟合)——模型把教材背得滚瓜烂熟,但遇到新题就懵
②"Underfitting"(欠拟合)——模型连教材都没学明白
③优秀的"Generalization"(泛化)能力是所有训练追求的圣杯——见多识广,又能灵活应变
训练做得好不好,得靠"Benchmark"(基准测试)来打分——MMLU考综合知识,GSM8K考数学,Human Eval考编程……有一种刷榜式训练——专门针对某个Benchmark调参,在榜上一飞冲天,到真实场景下就拉胯。
3、算力基础设施与硬件
训练和运行大模型,本质上是一场算力军备竞赛。"GPU/AI Chips"(GPU/AI芯片)是算力的心脏,擅长并行计算,能同时处理成千上万的矩阵运算。普通CPU就像一个老练的会计师,一次只能算一道题;而GPU就像几千个小学生同时答题——单个小学生的能力不如会计师,但几千个同时动手,速度提升了好几个数量级。
AI芯片的门派很多:
①NVIDIA的"GPU"(最主流)
②Google自家的"TPU"(Tensor Processing Unit,张量处理单元)——在Google内部的搜索、翻译、AlphaFold里都用
③手机和边缘设备上的"NPU"(Neural Processing Unit,神经网络处理单元)——Apple Silicon、华为麒麟、高通骁龙里都有它的身影
④"CUDA"——NVIDIA GPU的独家编程语言,所有AI工程师的必修课
⑤"ROCm"——与之对标的开源阵营,AMD显卡用户在等它成熟
GPU也分三六九等。"VRAM"(显存)或"HBM"(High Bandwidth Memory,高带宽内存)是GPU的桌面大小——桌面越大,能同时放下的模型就越大。跑一个70B参数的模型,至少需要2张80GB显存的GPU,否则连加载都加载不了。普通开发者想本地跑大模型,显存是第一道门槛。
这催生了"Cloud"(云计算)模式——企业不用自己买一堆GPU,按量租用云上的算力,就像电力公司按度数收费。个人玩用Colab、Kaggle;中小企业用AWS、Azure、阿里云;训练大模型用Lambda Labs、Core Weave这类专业厂商。
这些芯片通常集中部署在"Data Center"(数据中心)——你可以把它想象成AI发电厂,里面堆满了成千上万台机器,24小时不间断地训练和运行模型。发电就需要能源——"Energy/Power"(能源/电力)因此成为AI时代的新石油。训练一个前沿大模型所消耗的电力,往往相当于一个小型城市数月的用电量。
这件事已经升级为能源、环境与地缘政治交织的战略问题——"Carbon Footprint"(碳足迹)这个原本属于环保圈的概念,被频繁拉进AI讨论。某些厂商一边宣传绿色AI,一边把训练外包到火电厂密集的地区——这个话题以后会被越揭越深。
4、模型属性与核心机制
"LLM"(Large Language Model,大语言模型)是当下最炙手可热的大模型类型,专攻语言任务。按开放程度,LLM分为"Open Source"(开源)和"Closed Source"(闭源)。闭源模型性能强,开源模型可控性强——闭源代表ChatGPT、Claude、Gemini,开源代表Meta的Llama、阿里Qwen、DeepSeek。
它有不同的版本和类型:
①"Foundation Model/Base Model"(基础模型/基座模型)——未经特殊训练的母版,可以理解为刚出狱的野马
②"Instruction Tuning"(指令微调)——给母版补上听懂人话的能力,相当于把野马训练成能骑着走的马
③"Reasoning Model"(推理模型)——2024-2025年异军突起的新品类,以OpenAI的o1/o3、DeepSeek-R1为代表,主打想清楚再回答,在数学、编程、复杂推理任务上大幅超越传统LLM
LLM的核心工作原理其实很简单——它本质上是一个猜词高手,每次根据上文预测下一个最可能出现的词。这种方式叫"Autoregressive"(自回归)——一个字一个字往外吐。
模型内部会先把每个可能的下文算出一个原始分数,叫"Logits",然后通过"Softmax"函数转换成一个"Probability Distribution"(概率分布)——本质上是把模型的感觉变成百分比。模型在每一步都像是高管会议——100个备选答案举手表决,得票最高的那个被选中。
它处理文本的最小单位是"Token"(词元)——一段中文可能被切成几个字,一段英文可能被切成词或子词。虽然切词是个纯工程细节,但同样的中文,用BPE切和用jieba切,模型效果天差地别。
而这一切的边界是"Context Window"(上下文窗口)——它就像模型的短期记忆容量,窗口越大,模型能"看到"的上下文就越长。2024年起各家厂商开始卷"Long Context"(长上下文),从128K飙到1M、10MTokens——相当于让模型一次性读完一整本《三体》三部曲。Long Context更像是一把双刃剑——长是真的长,但长注意力衰减的问题(前面的内容被记住,后面的内容被忽视)至今没真正解决。
为了控制输出的多样性,"Temperature"参数登场——可以把它想象成创作的温度计:温度越高,输出越发散、有创意;温度越低,输出越确定、保守。和它配套的还有"Top-p"(核采样)和"Top-k"(取概率最高的前k个候选)——它们都是在放开创意和避免胡说之间找平衡,比如:写代码用temperature=0,写文案用temperature=0.7,写创意用temperature=1.0+。
"Beam Search"(束搜索)是推理时多路并行搜索最优答案的策略——一次想N种走法,挑最好的那条。这个在传统NLP里很常用,但LLM时代已经被Top-p/Top-k取代了——因为Beam Search计算成本太高。
但LLM有时会一本正经地胡说八道——这就是"Hallucination"(幻觉)。比如问某公司的CEO是谁,模型会自信地编出一个名字,你不去查证就可能上新闻。
当模型规模、训练数据、能力积累到某个临界点时,常常会突然开窍,出现"Emergence"(涌现)能力——这是量变引起质变的典型例子。但涌现到底是模型真的变聪明了,还是评估方法恰好能检测出来了——这个问题至今没有共识。
"Inference"(推理)是模型实际应用的过程,而"Deep Thinking"(深度思考)则是推理的进阶版——让模型在回答前先想清楚。"Reasoning Model"的本质就是"Deep Thinking"的工业化。
除了LLM,AI世界还有几条图像/视频生成路线:
①"Diffusion Model"(扩散模型)——当前图像生成的主力军,Stable Diffusion、Midjourney、Sora背后都是它。原理是先学怎么把一张图慢慢变成噪点,再学会怎么把噪点一步步还原成新图
②"GAN"(生成对抗网络)——上一代图像生成的王者,"一个造假,一个打假"互相博弈,2017-2020是GAN的高光期
③"VAE"(变分自编码器)——更老一辈的生成模型,现在主要配合Diffusion使用
最后,"Multimodel"(多模态)让模型不再局限于文字——能同时处理图像、音频、视频等多种信息。这一类的最新形态叫"World Model"(世界模型)——Yann LeCun力推的方向,让AI学会理解物理世界的运行规律。在我个人看来,LLM的天花板可能就是语言,而World Model的天花板才是智能。
"Embodied AI"(具身智能)/"Robotics"(机器人)则让AI走进物理世界——"Autonomous Driving"(自动驾驶)是其最典型的落地场景。自动驾驶可能是World Model最早大规模落地的场景——Waymo、Tesla FSD都在抢。
这一切的最终成果就是"AIGC"(AI Generated Content,AI生成内容)——写文章、画插图、编曲、剪视频,AI都能一显身手。对于大多数人来说,AIGC最多的场景是写文章配图、生成PPT插画、做短视频片段——但说实话,一次不能用的比例依然偏高。
5、提示词工程与人机交互
如果说模型是舞台上的演员,那"Prompt"(提示词)就是递给它的剧本——问什么、怎么问、要求什么格式,直接决定了模型给出什么样的答案。同一个问题,用词不同、格式不同、上下文不同,模型能给出天差地别的答案。
"System Prompt"(系统提示词)是幕后导演的指令,它设定模型的角色、行为边界和全局规则——这一块是产品级Prompt的核心。写好一个System Prompt通常要迭代20-50次,直接拍脑袋的多半不好用。
"Prompt Engineering"(提示词工程)研究的是如何写好剧本的技术。这门技术2023年被过度神化,现在回归理性了——好的prompt确实能提升效果,但没有2023年那波自媒体吹的那么邪乎。
常用技术大致分这些:
①"Zero-shot Prompting"(零样本提示)——不给任何例子直接提问
②"Few-shot Prompting"(少样本提示)——给一两个示例让模型依葫芦画瓢。Few-shot在GPT-4之后效果似乎已经减弱了,模型本身已经懂了
③"Chain-of-Thought"(CoT,思维链)——让模型把思考过程写出来,对复杂推理任务效果显著,数学题、逻辑题用CoT是真香
④CoT还有两个加强版——"Tree of Thoughts"(ToT,思维树)让模型同时探索多条推理路径,"Self-Consistency"(自一致性)让模型多次作答后投票选出最稳的答案
⑤"ReAct"(Reasoning+Acting,推理+行动)——把推理和行动结合起来,让模型边想边做。这个后文§7还会详聊,是Agent的核心套路
但提示词技术也带来了新的安全风险。"Prompt Injection"(提示词注入)是AI时代的"SQL注入"——攻击者把恶意指令藏在用户输入里,诱导模型执行危险操作。
"Jailbreak"(越狱)则是想方设法让模型说脏话、越红线。最经典的一招是"DAN"(Do Anything Now)——用角色扮演的方式绕过安全限制。完全防住Jailbreak是不可能的,但可以把命中率从80%降到5%以下。
对应的防御手段是"Guardrails"(护栏)和"Safety Filter"(安全过滤)——给AI装上安全门。Guardrails一般不放在模型内部(容易被绕),要放在模型外部的中间件——这是2024年之后行业的共识。
为了让输出更易读、更可控,"Markdown"常被用来规范输出格式。"Structured Output"(结构化输出)/"JSON Mode"则更进一步——强制模型吐出JSON之类的机器可读结果,方便下游程序直接消费。JSON Mode是LLM接入业务系统的必备——没有它,解析模型输出就是一场灾难。
"Stop Sequence"(停止符)告诉模型什么时候闭嘴——避免它说个不停或跳出角色。
整个过程本质上就是围绕用户的"Input/Output"(输入/输出)展开的对话循环:用户输入Prompt,模型输出回答,再根据回答调整下一轮输入。好的Prompt不是一次性的,而是迭出来的——第一版永远不满意,多改几版才能用。
6、上下文、记忆与知识检索
"Context"(上下文)是模型当前的临时记忆体——它包含了对话历史、系统提示以及任何用户提供的参考资料。我自己的比喻:这就像一个人脑的工作记忆,装不下太多东西,一旦超过就会忘掉最早的内容。这个忘掉不是技术缺陷,是设计选择——模型不可能无限记住所有东西。
为了维持长对话的连续性,模型引入了"Memory"(记忆)机制——它把过去的对话精华压缩存档,在需要时再调出来喂给模型。Memory机制的难点不是存,是压——压缩太狠会丢信息,保留太多又占token,这个平衡得靠反复试。
这种记忆思想和后文§7智能体里的长期记忆模块一脉相承,区别只是规模、存储位置和调用方式的差异。但即便如此,模型依然可能知识陈旧或瞎编乱造。
这时候"RAG"(Retrieval-Augmented Generation,检索增强生成)就登场了。RAG的思路很朴素,和开卷考试是同一个意思——先查资料,再回答。模型在生成答案前,会先从外部"Knowledge Base"(知识库)中检索与问题相关的事实,再结合这些真实信息来作答。这一招直接解决了LLM知识陈旧和瞎编乱造两个最大的痛点。
RAG的背后是"Embedding Model"(嵌入模型)和"Vector Database"(向量数据库)的组合拳——前者就是§1提到的Embedding技术的专门化版本,负责把文本变成向量;后者是一个专门存向量、查向量的数据库,能在亿级向量中毫秒级找出最相关的若干条。
RAG还有几个关键步骤:
①"Chunking"(文本分块)——把长文档切成语义完整的小段。切得太细,检索精度高但召回低;切得太粗,召回高但噪音多
②"Hybrid Search"(混合检索)——把关键词检索和语义检索组合使用,比单一方式准很多
③"Re-ranking"(重排序)——对检索结果做二次精选,把最相关的顶到最前面
但RAG也有自己的竞品——前面§4提到的"Long Context"(长上下文)模式。两种路线各有各的命门——RAG适合超大规模知识库和成本敏感的场景;Long Context适合一次丢进去几本书直接问的模式。现实里两种技术经常被组合使用——Long Context处理主问题,RAG处理细枝末节。
在性能优化上,"Cache"(缓存)是节省成本和加速的神器——"Prompt Cache"缓存常用前缀,"KV Cache"缓存推理时的中间结果。KV Cache的存在,让推理速度提升了至少3倍——没有它,ChatGPT那种"一个字一个字往外吐"的体验会非常糟糕。
7、智能体、工具与工程化
如果说普通模型是案头的研究员——你递一份资料,它交一份报告,那"Agent"(智能体)就是外勤的项目经理——接到目标后自己出门调研、协调资源、调用人手、最终把事情办成。这是AI从对话走向行动的关键一步。
Agent在调用工具时有几个关键概念需要厘清:"Skills"(技能)是Agent自己会的本领;"Tools"(工具)是Agent能调用的外部能力;"Functions"(函数)则是更底层的代码函数——三者层层递进。在技术上,调用通过"Tool Calling/Function Calling"实现——模型在需要时举手说"我需要查个天气",系统就去调用相应的工具。工具的JSON Schema写得不好,模型就乱调——这比想象的常见。
工具的形式多种多样:可以是"Plugin"(插件)——给AI装上手和脚;可以是"Web Search"(联网搜索)——让AI实时获取最新信息;还可以是"Code Execution"(代码执行)/"Sandbox"(沙箱)——让Agent安全地写代码并运行。这是Agent工程的生命线——我自己的铁律:生产环境的Agent必须在沙箱里跑。有一次Agent把测试数据库里的数据真的删掉了——还好是在沙箱里跑的。
Agent的能力版图正在快速扩张:"Computer Use"(电脑使用)让Agent能像人一样操作电脑界面(点鼠标、开软件);"Browser Use"/"Web Agent"让Agent能上网冲浪——刷网页、填表单、抓数据;"GUI Agent"则把两者合二为一。OpenAI的Operator、Anthropic的Computer Use都在这个方向。
当任务太复杂时,"Multi-Agent"和"Subagent"上场——多个智能体分工协作,一个负责规划、一个负责执行、一个负责检查。"A2A"(Agent-to-Agent,智能体间通信)则是多智能体之间的社交语言——让不同Agent能互相交流、协同工作。"Workflow"(工作流)是更高一层的流水线编排——把多个步骤、多个工具、多个Agent串成一个自动化流程,专业术语叫"Orchestration"(编排)。
Multi-Agent听起来美好,做起来炸裂——Agent之间的通信调试能让人崩溃。
Agent内部的工作范式有几种典型:
①"Plan-and-Execute"(规划-执行)——先做整体计划再分步执行。往往在目标清晰、路径多变的任务里特别管用
②"Reflection"(反思)/"Self-Critique"(自我批评)——让Agent检查自己的输出并迭代改进
③"Human-in-the-Loop"(人在回路)——在关键决策点保留人类把关。凡是有花钱、发出去、不能撤销的动作,必须有HITL
Agent的开发也有自己的协议栈。"LangChain"是常用的AI开发框架。"MCP"(Model Context Protocol,模型上下文协议)提供了一套标准化的协议,让不同的工具和数据源能说同一种语言——它像AI世界的"USB接口标准"——插上就能用。"Harness engineering"则为Agent提供安全运行的外壳与接管机制——就像给自动驾驶汽车装了安全围栏和人工接管按钮。
Agent不是越智能越好,而是越可控越好。一个会做100件事的Agent,不如一个能稳定做10件事的Agent。
Agent做得好不好,需要"Evals"(评估)/"Agent Evaluation"来衡量——既要看任务完成率,也要看工具调用是否合理、是否符合安全规范。Evals是Agent产品里最被低估、但最关键的一环——没有它,Agent的迭代就是盲人摸象。前面§6提到的"RAG"在Agent场景下也会被反复调用,构成Agent知识获取的基础设施之一。
8、软件工程与开发部署
把AI能力真正变成产品,得走完完整的软件工程链路。
"API"(Application Programming Interface,应用编程接口)及"API Key"是调用AI服务的钥匙——开发者通过API把模型能力嵌入到自己的应用中。"SDK"(Software Development Kit,软件开发工具包)则是更完整的开发套件——它把API+文档+示例代码+工具打包好。
"GitHub"是代码托管的中央仓库——存放代码、协作开发、管理版本。开发者的主战场是"IDE"(Integrated Development Environment,集成开发环境),如VSCode,以及它的AI升级版"Cursor"——就我个人的使用体验来看,Cursor写代码比VSCode+Copilot顺手很多,"Tab补全"的准确度明显高一档。
开发过程通常分为"Frontend"(前端,用户能看到的界面)和"Backend"(后端,背后的逻辑和数据)——前端是门面,后端是内功。"Microservices"(微服务)则是后端架构的乐高积木——把复杂系统拆成独立的小服务。"Monolith"(单体应用)则相反,所有功能塞在一个项目里。AI产品早期推荐Monolith——业务没跑通前,微服务的拆分成本会拖垮团队。
"Docker"/"Container"(容器)是应用打包的行李箱——让代码在哪都能跑,避免在我电脑上能跑的经典悲剧。"Serverless"(无服务器)则是按需请人干活的云开发模式——不用自己管服务器,只管写代码。"DevOps"/"CI/CD"(持续集成/持续部署)则是自动化运维的流水线——让代码一提交就自动测试、自动部署。
开发过程中少不了"Debug"(调试)、"Test"(测试)和处理"Error"(报错)。AI应用尤其关注性能三件套:
①"Latency"(延迟)——首字响应要快。一般来说,首字响应超过1.5秒,用户就开始觉得卡
②"Throughput"(吞吐量)——单位时间能处理多少请求
③"QPS"(Queries Per Second,每秒查询数)
ChatGPT那种打字机效果叫"Streaming"(流式输出),背后依赖"SSE"(Server-Sent Events,服务器推送事件)或"WebSocket"技术——让模型边生成边推送,用户体验立马丝滑。
"Vibe Coding"是近年来兴起的一种编程理念——借助AI进行氛围感或直觉式辅助编程。开发者不再死磕每一行代码,而是把更多精力放在我想做什么上,让AI帮忙把想法变成代码。这不是躺平式编程,而是一种新的分工——人负责想做什么,AI负责怎么做出来。
本地开发离不开"Terminal"(终端)、"Command"(命令)、"Path"(路径)和"Environment Variables"(环境变量),"CLI"(Command Line Interface,命令行界面)则是它们的主要呈现形式。最后,应用开发完成后,还需要"Deployment"(部署)到"Server"(服务器)上,并配置好"Port"(端口)。80端口被占用、443端口要证书、3000端口是前端默认——这些坑每个新人都要踩一遍。
9、业务场景、应用与前沿概念
"AI Application"(AI应用)按受众可分为"To B"(企业级)和"To C"(消费级)。2023-2024是To C爆发(ChatGPT、Midjourney、Cursor都在抢用户),2025开始To B才是真正的钱袋子——企业级客单价高、付费意愿强、护城河深。
"AI Native"(智能原生)指从底层架构上原生为AI设计的应用——从产品定义的第一天起,就把AI当成一等公民。传统软件"AI Native"化的标志是——没有AI,整个产品就跑不起来(不是有了AI体验更好,而是没有AI就根本不存在)。微软的"Copilot"(副驾)命名学把这一理念推到了极致——AI隐身于办公软件、IDE、操作系统之后,像个副驾驶一样随时待命。
"Chatbox"(聊天框)是当下最常见的对话交互界面,它的核心依赖"Chat History"(对话历史)来维持连贯性。Chat History的存储和检索是大部分Chatbot产品的隐形瓶颈——历史太长token爆,历史太短体验割裂。
"RPA"(Robotic Process Automation,机器人流程自动化)是AI之前的自动化前辈——让软件机器人模拟人操作电脑。2024年以后,"AI Agent+RPA"正在融合——Agent负责思考,RPA负责动手,这一块UiPath、Automation Anywhere都在转型。
放眼未来,"AGI"(Artificial General Intelligence,通用人工智能)是AI发展的终极形态——它具备像人类一样的通用学习、推理和适应能力。我自己的判断:AGI不会以某天突然AGI了的形式到来,而是以我们事后看才发现已经是AGI了的形式到来——这和Sam Altman早期的判断一致。再往后,"Singularity"(技术奇点)是科幻概念——AGI自我迭代、智慧爆炸的那个临界点,个人持保留态度。
各国政府也在积极布局"Sovereign AI"(主权AI)/"National AI Strategy"(国家AI战略)——AI已经成为大国博弈的核心战场。我自己的观察:美国、中国、欧盟三条路线完全不同——美国靠企业主导、中国靠政策驱动、欧盟靠法规约束。全球主要玩家包括OpenAI、Anthropic、Google DeepMind、Meta AI、Mistral、DeepSeek(深度求索)、Qwen(通义千问)、Kimi(月之暗面)等。
但通往未来的路上也布满荆棘。"AI Safety"(AI安全)/"AI Alignment"(AI对齐)/"AI Ethics"(AI伦理)构成AI治理的大三元——这三个词在媒体上经常混用,但学术界有清晰区分。"Bias"(偏见)/"Fairness"(公平性)是数据偏差问题的延伸;"XAI"(Explainable AI,可解释AI)致力于让AI的决策说人话——为什么拒贷?为什么推荐这个?都要给出可追溯的理由。金融、医疗、HR这三个领域对XAI的要求最高——监管要求拒绝必须能解释。
"Deepfake"(深度伪造)让眼见不再为实——AI能生成高度逼真的虚假视频和音频。2024年发生过几起知名案例:某公司CFO被deepfake视频骗走了2亿港元——这个案例之后,全球大企业的财务流程都加了一道面对面核实。
"Model Drift"(模型漂移)则提醒我们:模型部署上线后不是一劳永逸的——随着时间推移,外部数据分布会变,模型表现也会逐渐衰退。风控模型可能上线6个月,效果就开始衰减——必须配套"持续训练+监控告警"。
"Synthetic Data"(合成数据)是另一面镜子——用AI造数据再喂AI。短期内缓解数据枯竭是真有用,长期看放大偏见、形成数据回音壁是更大的风险——涉及人脸、医疗、金融的合成数据,一般不推荐。
10、评估、对齐与安全
"Benchmark"(基准测试)是衡量模型能力的标准考试卷——MMLU考综合知识、GSM8K考数学、Human Eval考编程、Super GLUE考语言理解……这些排行榜决定了哪家公司能在下一轮PR中露脸。"Evals"(评估)则是更广泛的概念——既包括学术Benchmark,也包括企业内业务指标。某些厂商专门针对Benchmark调参,在榜上一飞冲天,到真实场景下就拉胯。
"AI Alignment"(AI对齐)研究的核心问题是:如何让AI的目标和人类的目标保持一致?前面§2提到的"RLHF"、"RLAIF"、"Constitutional AI"(宪法式AI)都是这一领域的核心武器——后者让模型按宪法原则自评。除此之外,"Scalable Oversight"(可扩展监督)研究当AI越来越强、人怎么管得住它。
"AI Safety"(AI安全)关注AI失控的极端风险——模型会不会撒谎、会不会觉醒、会不会被滥用?觉醒这种表述太科幻,撒谎和被滥用才是真实的风险。
"Red Teaming"(红队演练)是常见的安全测试方法——专门派人找茬,故意用恶意输入测试模型的防御能力。红队测试要100%自动化才靠谱——人工点能点的样本太有限,Prompt Injection 80+种、Jailbreak 50+种、敏感词200+个,跑完一遍大概4小时。
"Guardrails"(护栏)把安全规则嵌入到产品层面。Guardrails不要放在模型内部(容易被绕),要放在模型外部的中间件——这是2024年之后行业的共识。
"AI Ethics"(AI伦理)则讨论更广的社会议题——算法歧视、就业冲击、信息茧房、AI创作的版权归属……这些问题没有标准答案,需要技术、法律、社会多方共同协商——作为从业者,至少要知道这些话题存在,而不是只看技术不看社会。
附录:AI高频词速查表(按章节分类)
作者:赵搏 投资咨询证号:Z0021236
重要申明:本报告内容及观点仅供学习和参考,不构成任何投资建议。市场有风险,投资需谨慎。

