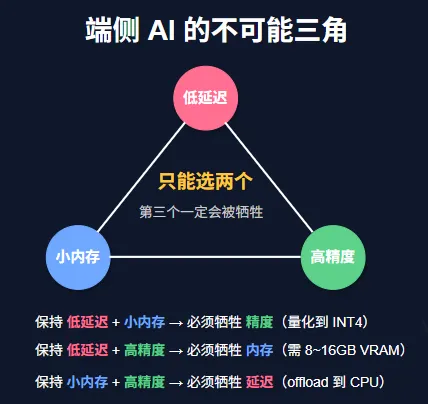
这不是某个模型或某个芯片的局限,是物理规律——端侧设备的内存带宽、算力和功耗上限决定了这一点。云端服务器可以靠堆 A100 和 NVLink 回避问题,但端侧不行。• 低延迟:推理速度快,用户感觉流畅(首 token < 100ms,生成 > 20 tok/s)• 小内存:模型能装进有限的 RAM/VRAM(比如手机上 2~4GB)保住任意两个,第三个就必然受损。所有的边缘 AI 优化技术:量化、剪枝、推测解码、KV Cache 压缩——本质上都是在三角的三个顶点之间移动你的位置。很多人一上来就想"我的 GPU 算力够不够"。其实LLM 推理的瓶颈几乎从来不 FLOPS(浮点运算),而是内存带宽。为什么?因为自回归生成每一步都要把整个模型权重从内存搬到计算单元。7B 模型,BF16 精度,14GB 权重。每生成一个 token,这 14GB 就要读一遍。你的 GPU 算力再强,如果内存带宽只有 100GB/s,那理论上限就是 100/14 ≈ 7 tok/s。这个叫 Memory-Bound 问题。公式很简单:最大吞吐 = 内存带宽 / 模型权重大小量化是最直接的优化——把权重的数值精度降低。BF16(16-bit)→ INT8(8-bit)→ INT4(4-bit),模型大小直接按比例缩小。
• 7B 模型 INT4:3.5GB(减到 1/4)内存省了,带宽需求也降了,生成速度自然上去。但代价是什么?精度损失。• INT8:通常损失 1~3 个百分点(MMLU 等基准),很多场景可接受• INT4:损失 3~8 个百分点,部分复杂推理任务明显退化• INT3/INT2:损失开始非线性增长,模型"变笨"的速度超过预期这里有个容易被忽略的事实:不同模型对量化的敏感度天差地别。MoE 架构(比如 Mixtral、Qwen MoE)通常比 Dense 模型更抗量化,因为每个 token 只激活部分专家,单条路径的精度损失被稀释了。所以量化不是"无脑 INT4 就行"——你得知道你的任务对精度的容忍度。对话场景可以接受 INT4,代码生成可能 INT8 是底线。量化是"把模型缩小",推测解码(Speculative Decoding)是完全不同的思路:保留原模型精度不变,用小模型"预猜"来加速。
核心思想:让一个小模型(draft model)先快速生成 N 个 token,然后用大模型(target model)一次性验证这些 token。猜对的直接接受,猜错的回退重算。这就像你让实习生先写草稿,你最后审一遍。实习生写得快但可能出错,你审得慢但保证质量。两者配合,总体比你自己从头写要快。你需要同时加载两个模型。7B 大模型 + 1B 小模型,BF16 下需要 14 + 2 = 16GB。量化可以缓解这个问题(比如小模型 INT4,大模型 INT8),但总体内存占用还是比单模型高。加速效果取决于大小模型之间的"相似度"——如果小模型经常猜对,加速比可以到 2~3x;如果猜不对,反而更慢。很多人量化完模型,发现内存还是不够——因为忘了算 KV Cache。
KV Cache 是自回归推理的"工作记忆"。每生成一个 token,之前所有 token 的 K 和 V 矩阵都要缓存起来。上下文越长,KV Cache 越大。7B 模型,BF16,8K 上下文,KV Cache 大约 2~3GB。32K 上下文,直接涨到 8~10GB。在端侧设备上,这完全可以吃掉你剩下的所有内存。• KV Cache 量化:把 K 和 V 也量化到 INT8/INT4,省 50~75% 内存,精度影响通常很小• 分页注意力(PagedAttention):像 OS 分页一样管理 KV Cache,避免碎片浪费• 滑动窗口注意力(Sliding Window):只保留最近 N 个 token 的 KV,长文本有损但省大量内存• KV Cache Offload:把部分 KV 搬到 CPU 内存,GPU 显存不够时自动降级最后一种在端侧特别实用——GPU 显存只有 4GB,但系统内存有 16GB。把 KV Cache 部分 offload 到 CPU 上,虽然访问慢一些,但至少能跑完。延迟会比较慢,但在 IoT 场景下通常可以接受——没人要求智能音箱 100ms 内响应。• 尽量用 BF16 或 FP16,不量化或只量化 KV Cache• 内存不够就 offload 到 CPU,慢就慢点,不能出错• 可以接受 1~2 tok/s 的速度,但输出质量不能打折实际工作中,你不会只选一种技术。通常是组合使用。一个典型的端侧部署方案:
# 典型边缘部署配置model = "Qwen2.5-7B-Instruct"quantization = "INT4" # 精度换内存kv_cache_quant = "INT8" # KV Cache 额外压缩max_context = 4096 # 限制上下文长度speculative = True # 开启推测解码draft_model = "Qwen2.5-1.5B"offload_to_cpu = True # 溢出时 offload# 结果:# 模型权重: ~3.5GB (INT4)# KV Cache: ~1GB (INT8, 4K ctx)# Draft model: ~1GB (INT4)# 总内存: ~5.5GB# 速度: ~15 tok/s (推测解码命中时)
这个配置在 8GB 内存的设备上可以跑 7B 模型,速度 15 tok/s 左右——虽然不是极快,但对大多数对话场景足够了。端侧 AI 没有银弹。不可能三角是物理规律,不是工程缺陷。每一个优化方案都是在三个顶点之间做 tradeoff。但实际应用中,大多数场景不需要三个顶点都保住。搞清楚使用场景里哪个最重要,然后有选择地牺牲另外两个,部署方案就清晰了。
[1] https://fireworks.ai/blog/frontier-rl-is-cheaper-than-you-think[2] https://huggingface.co/papers/2603.24477[3] https://github.com/huggingface/trl/pull/5417[4] Kwon et al. vLLM: PagedAttention. https://arxiv.org/abs/2309.06180 夜雨聆风
夜雨聆风