 夜雨聆风
夜雨聆风导语:大家都在说 AI 缺芯片、缺电。但有个更隐蔽的瓶颈,最近才被英伟达砸了几十亿美元去补——几万张显卡挤在一个机房里,它们之间"传话"这件事,铜线已经快扛不住了。

一、先看个反差:AI 的瓶颈,正在从"算"变成"传"
前两天刷到一条新闻,英伟达又出手投资了——这回是一家叫 IREN 的数据中心公司,给了它一份最多 21 亿美元的投资权,还要一起铺最多 5 吉瓦的 AI 算力。
5 吉瓦是什么概念?差不多是五座中型核电站满负荷的输出。一家公司,光是给 AI 机房供电,就要吞掉一座大城市的用电量。
这种新闻你大概看麻了。无非又是"英伟达很猛、AI 很烧钱"。
但这次有个细节值得拎出来说:在多家分析里,英伟达看上 IREN 这类公司,除了要它的地、它的电,还有一个常被忽略的环节——把铜线换成光 。
你可能会愣一下:等等,AI 不是拼算力吗?显卡算得越快越好,这跟"光"有什么关系?
关系大了。说白了,今天训练一个大模型,早就不是一张卡的事,而是几千、几万张卡绑在一起,当成一台巨型计算机来用。卡和卡之间要不停地交换数据。算得快只是一半,另一半是:这么多张卡之间,能不能把话传得又快又省。 而这后一半,正在变成新的卡脖子环节。
先立骨架 · AI 光互连速览
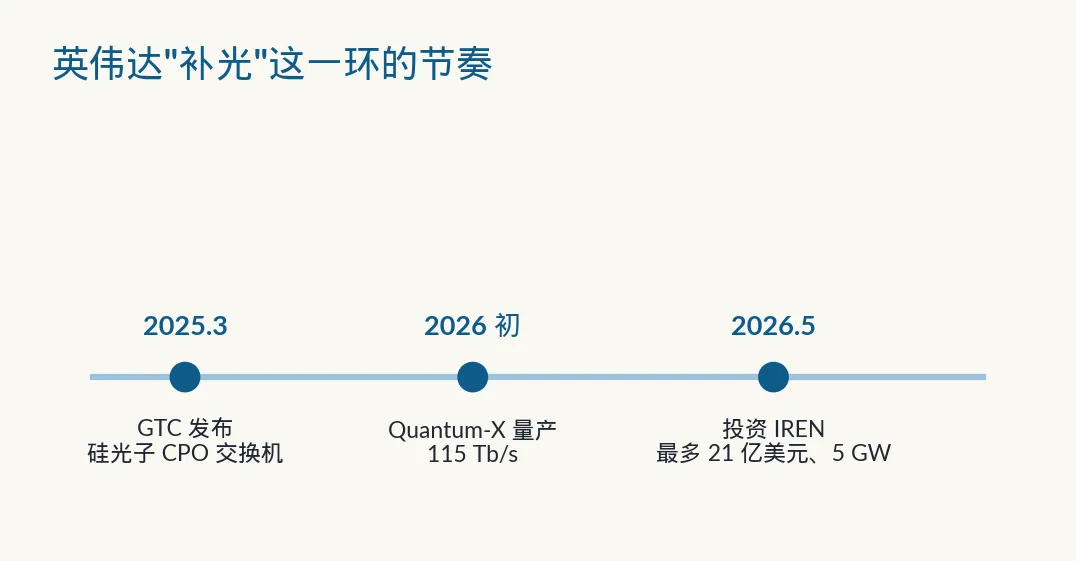
• 互连是什么 :让成千上万张 GPU 像"一台机器"协同的高速连线,分卡内、机柜内、机柜间几个层级。 • 铜的麻烦 :电信号在铜线里跑,距离一长、速率一高,就会衰减、发热、串扰;带宽密度撞上物理天花板。 • 耗电惊人 :业界估算,今天一张 GPU 要配约 6 个可插拔光模块,每个约 30 瓦;规模铺到百万张 GPU,光是这些模块就要烧掉约 180 兆瓦。 • 解法叫 CPO :共封装光学(Co-Packaged Optics),把"电转光"的引擎从机箱边缘搬到芯片旁边。英伟达称这套方案能把互连功耗降约 3.5 倍、可靠性升约 10 倍。 • 时间线 :2025 年 3 月英伟达 GTC 发布硅光子 CPO 交换机;Quantum-X InfiniBand 计划 2026 年初出货,单机 115 Tb/s、144 端口各 800 Gb/s;2026 年 5 月,英伟达宣布与数据中心商 IREN 战略合作。 • 市场 :面向 AI 数据中心的光互连市场,2025 年约 37.5 亿美元,预计 2033 年涨到 180 亿美元上下。 (数据来源:英伟达投资者公告、英伟达技术博客、Yole/行业研报,2025–2026)

二、先搞懂一件事:为什么 AI 要"很多张卡一起算"
要讲清楚光互连,得先回答一个前置问题:为什么非得几万张卡绑一起?
原因很简单——一个大模型,一张卡根本装不下。
今天的前沿大模型,参数动辄上万亿。这些参数、再加上训练时产生的中间数据,要占的显存远远超过单张卡的容量。于是只能把模型"切开",摊到很多张卡上:有的卡负责这一层,有的卡负责那一层,有的卡各算一部分。
问题来了:模型被切开了,可它本身是一个整体。这张卡算出来的结果,下一步就是另一张卡的输入。每往前走一步,卡和卡之间就要交换一大批数据。训练时还有一个环节叫"梯度同步"——每张卡各自算完,要把结果汇总、对齐,再一起更新。这一步,所有卡几乎要同时开口说话。
打个比方。这就好比一篇巨型工程图纸,一个人画不完,拆给一千个工程师分工画。画得快当然重要,可每画几笔,大家就得凑到一起对一次图、把接口对齐。如果"凑到一起对图"这一步很慢,那再多再快的工程师,也只能干等着。
这就是互连(interconnect)的活儿 :让这一千个工程师之间传图、对图,传得越快、越省力越好。在 AI 机房里,它分好几层——一张芯片内部不同单元之间、一个机柜里几十张卡之间、一排排机柜之间,层层都要连。卡越多、模型越大,"对图"的数据量就越恐怖。
这里还有个常被混淆的区别,顺手讲清楚。机柜内部、让几十张卡"紧密绑成一台超级 GPU"的高速连接(英伟达的 NVLink 就是干这个的),业内叫"纵向扩展"(scale-up),追求的是极致带宽;而把一个个机柜、一排排机柜连成更大集群的网络(InfiniBand、以太网那一层),叫"横向扩展"(scale-out),追求的是规模。今天的麻烦在于 :无论纵向还是横向,规模一上来,铜的老路子都开始顶不住,于是"把光往里推"这件事,在每一个层级上同时发生。理解了这点,你就明白英伟达为什么连交换机、连网络都要亲自下场——它要把每一层的"传话"都攥在手里。
到了这一步你就明白了:当卡的数量从几百张涨到几万张、几十万张,"传话"的压力是指数级往上窜的。算力可以靠堆卡解决,可"传话"这件事,堆是堆不出来的——你得让每一条线都更快、更省。
三、往下挖一层:铜线,为什么快不行了
过去几十年,芯片之间传数据,靠的都是铜。主板上的走线、机柜里的铜缆,本质都是让电信号在金属里跑。铜便宜、成熟、好用,一直够使。
但到了 AI 这个量级,铜开始撞墙,撞的是物理墙。
第一,距离和速率是天敌。 电信号在铜线里跑,频率越高、跑得越远,衰减就越厉害,还会发热、互相串扰(旁边那根线的信号会窜过来捣乱)。短距离低速率,铜很从容;可一旦要在几米开外、用极高的速率传海量数据,铜就力不从心了。这不是工艺问题,是材料的天花板。
第二,带宽密度见顶。 一张顶级 GPU 要吞吐的数据量大得吓人,需要的连线越来越多、越来越密。可铜线塞到一定密度,发热和串扰就压不住了。空间就那么大,你没法无限往里塞铜。
第三,也是最要命的——太费电。 今天的主流做法,是用"可插拔光模块"来救场:在机箱边缘,把电信号转成光、用光纤往外传,到对面再转回电。这套已经在用了,但它有个硬伤——每一次"电转光、光转电"都要耗电。
业界给过一个直观的账:今天一张 GPU 大概要配 6 个这样的可插拔光模块,每个约 30 瓦。一张卡光这些模块就近 200 瓦。要是把规模铺到一百万张 GPU,单单这些光模块加起来,就要烧掉约 180 兆瓦——这点电,够一座中型电厂全力供应,而它什么都没"算",纯粹用来"传话"和来回转换信号。
你看,"AI 缺电"这件事,电不只烧在算力上,相当一部分烧在了"互连"上。铜+可插拔模块这套老办法,越往大里铺,浪费越触目惊心。
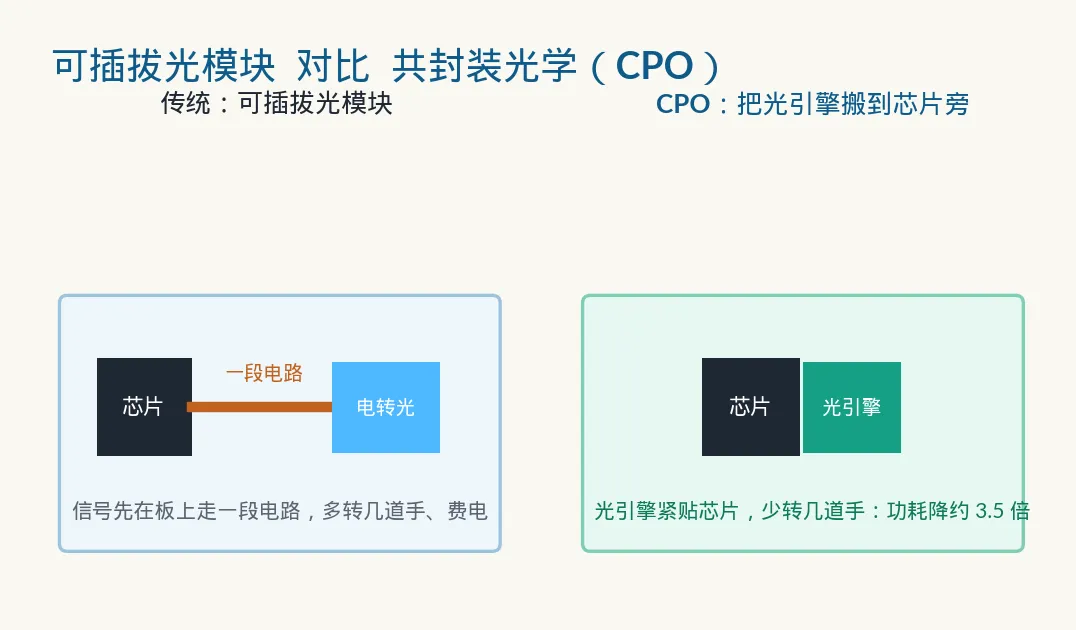
四、再往下,本质是这个:请光出场
既然电子在铜里跑不动、又费电,那换个介质——让信息改坐"光"。
光的好处,恰好是铜的短板。光在光纤里跑,损耗极低、几乎不发热、不互相串扰,能在更长的距离上扛住更高的速率。今天机房之间、城市之间的网络早就是光纤的天下。现在要做的,是把光一路往里推,推到离芯片越来越近的地方。

这里有两个关键词,拆开就懂:
一个叫硅光子(silicon photonics)。 说白了,就是用做芯片的那套硅工艺,在硅片上"刻"出走光的微型光路,把激光器、调制器这些原本笨重分立的光学器件,集成到一小块芯片上。这样"电转光"的部件就能做得又小又省,还能跟电芯片一起量产。
另一个叫共封装光学(CPO,Co-Packaged Optics)。 这是关键一步。过去"电转光"放在机箱边缘,信号得先在电路板上走一段电路才能变成光;CPO 干脆把光引擎直接搬到交换芯片、GPU 的旁边,封装在一起。信号少绕了一大圈,少转了几道手,自然就更快、更省电。
这正是英伟达在做的事。2025 年 3 月的 GTC 大会上,它发布了基于硅光子的 CPO 网络交换机——Quantum-X(InfiniBand)和 Spectrum-X(以太网),把光的转换搬进了处理器封装,用的是台积电的相关光电工艺。官方给的数字是:这套方案能把互连功耗降约 3.5 倍、可靠性升约 10 倍。其中 Quantum-X InfiniBand 交换机计划 2026 年初出货,单机吞吐 115 Tb/s,144 个端口、每个跑 800 Gb/s。
3.5 倍的功耗差,放在百万卡的规模上,就是几十兆瓦的电费差、是真金白银。可靠性升 10 倍同样关键——可插拔模块多、接口多,坏一个就可能拖垮一片;把环节减下来,整个系统才稳得住。在动辄要连几十万张卡的"AI 工厂"里,这两条直接决定了能不能铺得起、跑得稳。
五、为什么是现在:从"可选"变"必须"
光互连不是新东西,光纤通信几十年前就有了。那为什么直到这两年,它才被推到聚光灯下、被巨头排队砸钱?
一句话:以前算力没这么密,铜够用;现在不够了。
过去机房里卡没那么多、距离没那么远、功耗没那么离谱,铜+可插拔模块这套完全应付得来,光进到机箱边缘就够。可 AI 把一切都顶到了极限——单个集群动辄几万、几十万张卡,整片园区几吉瓦地耗电。在这个量级上,互连的功耗和故障率被放大成了主要矛盾。于是,把光往芯片旁边搬这件"早晚要做"的事,从"可选项"变成了"必答题"。Tom's Hardware 在报道里直接说:对下一代 AI 数据中心,硅光子和共封装光学"可能会变成强制标配"。
产业链也在跟着转向。老牌玻璃巨头康宁,正为英伟达新建多座专做光学的工厂——英伟达在铺机柜级系统时,会越来越多地用光纤替代铜缆。而开头那笔对 IREN 的投资,本质也是同一盘棋:英伟达不只想卖显卡,它要把电、地、网络、光这一整套"AI 工厂"的环节都攥在手里,缺哪环补哪环。光,就是它正在补的那一环。
市场已经用钱投票了。据 Yole 等机构估算,面向 AI 数据中心的光互连市场,2025 年规模约 37.5 亿美元,预计到 2033 年会涨到 180 亿美元上下;更宽口径的数据通信光学市场,2025 年增速超过 60%、规模破 160 亿美元。这些数字背后,是整个行业的共识:电子负责"算",光负责"传",这条分工线正在被重新划定。
六、这事跟咱普通人有啥关系
聊了半天硅光子、CPO,你可能会问:这跟我有什么关系?我又不买交换机。
有三点,值得记住。
第一,重新理解"AI 很贵"。 以后再看到"某公司又投几百亿建 AI 机房""AI 太费电",你心里要清楚:这笔账里,除了显卡和电费,还有一大块花在"让芯片之间把话传好"上。互连,是 AI 基建里一个看不见但极烧钱的环节。能把它做省的公司,等于在成本上抢到了先手。
第二,看懂英伟达到底在卖什么。 很多人以为英伟达就是个"卖显卡的"。但它这两年发的、买的、投的,越来越多是网络、是光、是整套数据中心方案。它真正在卖的,是一座能开箱即用的"AI 工厂"——显卡只是其中最显眼的一块招牌。
第三,一条朴素的技术规律。 每当一种介质跑到极限,人类就会换下一种。算盘换成电路,铜线换成光纤。今天 AI 把电子推到了墙角,于是又一次轮到光上场。理解这条线,比记住任何一个具体型号都有用。
七、小结
说到底,这一轮 AI 竞赛,表面拼的是谁的模型更强、谁的卡更多,底下拼的却是一件特别朴素的事——怎么把信息搬得又快又省。
算力决定了一群芯片"能算多快",互连决定了它们"能不能真的拧成一股劲"。当几万张卡挤在一起、电子在铜线里再也跑不动的时候,工程师们做的,不过是请出那个一直都在、只是这次被逼到台前的老朋友:光。
电子跑不动了,就让光来跑。这世界推进的逻辑,往往就是这么朴素。
参考来源
• NVIDIA Investor Relations:《NVIDIA and IREN Announce Strategic Partnership to Accelerate Deployment of up to 5 Gigawatts of AI Infrastructure》(2026-05) • aibusiness.com:《Nvidia in $2.1B Deal With Data Center Provider IREN》(2026) • NVIDIA Technical Blog:《Scaling AI Factories with Co-Packaged Optics for Better Power Efficiency》(2025) • Tom's Hardware:《Nvidia outlines plans for using light for communication between AI GPUs by 2026》(2025) • Yole Group:《Silicon photonics and co-packaged optics at the heart of next-generation AI-driven data infrastructure》(2025) • 英伟达 GTC 2025 关于 Quantum-X / Spectrum-X 硅光子交换机的发布材料
配图来源
• 光互连-01/02/03、封面:本文自制示意图与数据图,数据来自上述英伟达技术博客、投资公告与 Yole 行业研报(2025–2026)。 • 光互连-网络1:光纤缆线照片,Wikimedia Commons 文件 Fiber Optical Cable.jpg,授权以 Commons 文件页为准。
