 夜雨聆风
夜雨聆风
什么是 RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将信息检索与大语言模型(LLM)生成能力相结合的技术范式。它的核心思想是:在大模型生成回答之前,先从外部知识库中检索出与用户问题相关的文档片段,将这些片段作为上下文注入到 LLM 的提示词(Prompt)中,从而让模型基于真实、可靠的知识生成更准确的回答。
RAG 的出现解决了大语言模型面临的几个关键问题。首先是"幻觉"问题——LLM 可能生成看似合理但实际错误的内容,RAG 通过提供真实文档片段来约束模型的输出。其次是知识时效性——LLM 的训练数据存在截止日期,而 RAG 可以接入实时更新的知识库。最后是领域专业性——通用模型对特定行业的专业知识了解有限,RAG 可以挂载企业内部文档、技术手册等专业资料,让模型在回答时有据可依。
RAG 的工作原理
一个完整的 RAG 系统包含两个核心阶段:索引阶段(Indexing) 和 检索生成阶段(Retrieval & Generation)。
索引阶段
索引阶段负责将原始文档转化为可检索的向量索引,其流程如下:
- 文档加载:从各种格式(Markdown、PDF、DOCX、代码文件等)中提取纯文本内容。对于二进制文档(PDF、Word 等),需要先通过格式转换工具将其转为可处理的文本。
- 文本分块(Chunking):将长文档切分为适当大小的文本块。这一步至关重要——块太大会引入噪声,太小会丢失上下文。常见的分块策略包括:递归字符分割(按段落、句子、字符逐级分割)、语义分割(利用嵌入向量的余弦相似度检测话题边界)、结构化分割(尊重 Markdown 标题、代码块、表格等文档结构)。
- 向量嵌入(Embedding):使用嵌入模型(如 Qwen3-Embedding、BGE 等)将每个文本块转换为高维浮点向量。好的嵌入模型能让语义相似的文本在向量空间中距离更近。
- 向量存储:将文本块及其向量、元数据(来源文件路径、块索引等)一起存入向量数据库。向量数据库支持高效的近似最近邻(ANN)搜索,能在海量向量中快速找到与查询向量最相似的结果。
检索生成阶段
检索生成阶段是用户实际使用时的流程:
- 查询编码:将用户的自然语言问题通过同一个嵌入模型转换为查询向量。
- 相似度搜索:在向量数据库中执行 ANN 搜索,返回与查询向量最相似的 Top-K 个文本块及其相似度分数。
- 结果优化(可选):对初步检索结果进行重排序、上下文扩展等操作,进一步提升检索质量。
- 上下文注入与生成:将检索到的文本块拼接成上下文,连同用户的原始问题一起构造 Prompt,发送给 LLM 生成最终回答。
整个流程可以用下面的流程图来概括:

wandering-rag-mcp 实战项目介绍
项目背景
在实际开发中,许多团队和个人都面临一个共同的痛点:本地积累了大量技术文档、代码仓库、产品手册等资料,但当需要快速查找某个具体问题的答案时,往往要在多个文件间反复搜索和翻阅。现有的搜索引擎只支持关键词匹配,无法理解自然语言的语义意图;而直接使用大语言模型又受限于其训练数据,无法回答关于私有文档的问题。
wandering-rag-mcp 正是为解决这一问题而设计的。它是一个基于 MCP(Model Context Protocol)协议的本地 RAG 知识库服务器,能够将本地文档导入向量知识库,并通过语义搜索为 AI 助手提供精准的知识检索能力。
该项目最大的特点是 无需额外配置 LLM。传统的 RAG 系统通常需要同时部署向量数据库、嵌入模型和大语言模型,配置复杂且资源消耗巨大。而 wandering-rag-mcp 采用了"MCP Server 负责检索、AI 客户端负责生成"的职责分离设计——MCP 服务器只处理文档索引和语义检索,生成回答的能力由接入的 AI 助手(如CodeBuddy、Qoder等)自带的模型提供。同时,提供离线安装包制作脚本,一键下载embedding模型和rerank模型,可以完全离线环境下部署安装。这样一来,用户只需关注知识库的构建和检索,无需关心 LLM 的部署和调用,极大地降低了使用门槛。
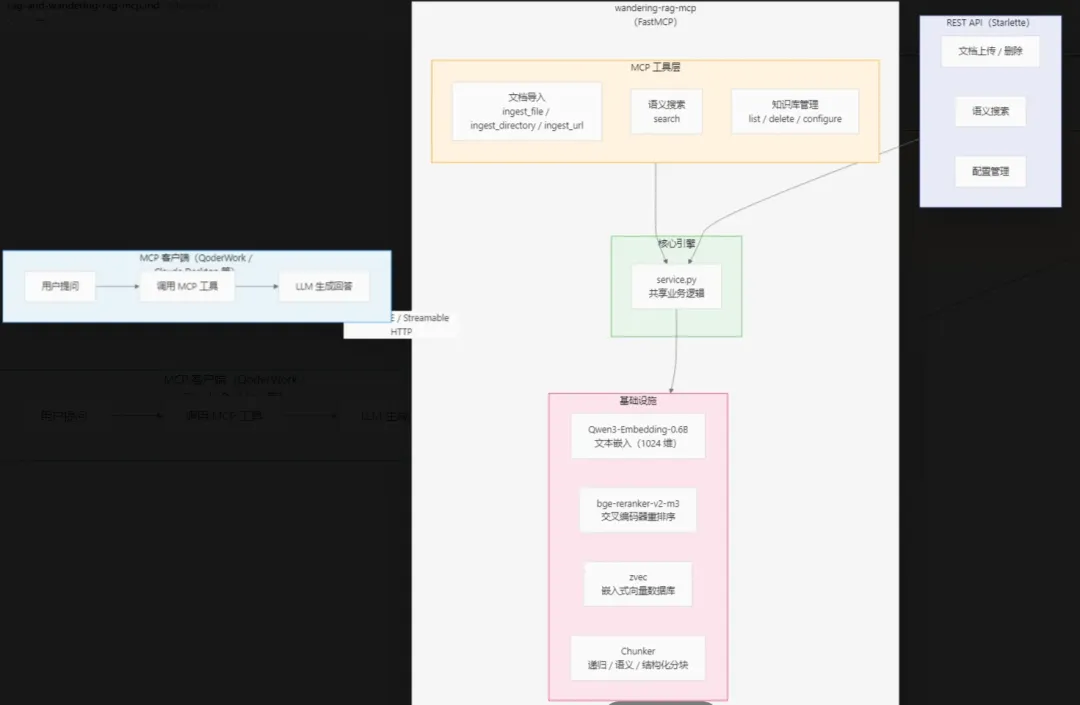
技术架构
wandering-rag-mcp 的技术架构围绕以下几个核心组件构建:
- FastMCP 服务器:基于 MCP 协议 SDK 构建的工具服务器,对外暴露 11 个 MCP 工具(涵盖文档导入、语义搜索、知识库管理等),同时支持 stdio、SSE、Streamable HTTP 三种传输模式。
- Markitdown: 一个轻量级 Python 工具,用于将各类文件转换为 Markdown,它在保留文档结构(标题、列表、表格、链接等)的同时,输出对 AI 友好的 Markdown 文本。
- zvec 向量数据库:阿里巴巴开源的嵌入式向量数据库,零配置、无需 Docker、支持 WAL 持久化和 HNSW 索引,非常适合本地部署场景。
- Qwen3-Embedding-0.6B:通义千问系列的轻量级嵌入模型,仅 0.6B 参数,生成 1024 维向量,支持 32K 上下文长度和中英双语,在保持高精度的同时对 CPU 推理友好。
- bge-reranker-v2-m3:可选的交叉编码器重排序模型,用于在初步检索结果之上进行二次精排,提升最终返回结果的相关性。
- REST API 层:基于 Starlette 构建的 HTTP API,与 MCP 共享同一个向量存储,方便 Web 前端集成文档管理和搜索功能。
整体架构如下图所示:
从项目目录结构来看,代码组织清晰且紧凑:
wandering-rag-mcp/ ├── pyproject.toml # 依赖和入口配置 ├── server.py # MCP 服务器入口 + 11 个工具定义 + 组合 ASGI 应用 ├── api/ │ └── app.py # REST API 路由(Starlette) ├── core/ │ ├── chunker.py # 文本分块(递归 + 语义 + 结构化三种策略) │ ├── embeddings.py # sentence-transformers 封装(懒加载) │ ├── reranker.py # 交叉编码器重排序(懒加载) │ ├── service.py # 共享业务逻辑层(MCP + REST 共用) │ └── vector_store.py # zvec 封装(CRUD + 搜索 + 配置管理) ├── data/ # zvec 存储目录(运行时自动创建) │ └── default/ └── deploy/ # 部署脚本(在线 + 离线)
core/service.py 是整个系统的业务逻辑中枢。它持有 VectorStore 单例,对外暴露结构化的操作接口(返回 dict),MCP 工具和 REST API 都通过调用 service 层来完成任务。这种设计避免了 MCP 层和 HTTP 层的逻辑重复,也便于后续扩展新的接入方式。
使用方法
安装
项目基于 Python,要求 Python >= 3.10。安装非常简单:
git clone https://github.com/mambo-wang/wandering-rag-mcp.git cd wandering-rag-mcp pip install -e .
启动服务
wandering-rag-mcp 支持三种传输模式,可根据使用场景灵活选择:
# stdio 模式(默认,适用于 QoderWork / Claude Desktop 等桌面客户端) python server.py # SSE 模式(适用于远程服务器 + Web 前端) python server.py --mode sse --port 8000 # Streamable HTTP 模式(新一代 MCP 传输协议) python server.py --mode streamable-http --host 0.0.0.0 --port 8000
客户端配置
以CodeBuddy为例,在 stdio 模式下只需添加如下 MCP 服务器配置:
{
"mcpServers": {
"wandering-rag-mcp": {
"command": "python",
"args": ["D:\\repos\\rag-mcp\\server.py"]
}
}
}如果是远程 streambleHttp 模式,则配置为:
{
"mcpServers": {
"wandering-rag-mcp": {
"type": "streambleHttp",
"url": "http://your-server:8000/mcp"
}
}
}MCP 工具一览
服务器启动后,AI 客户端可以使用以下 11 个 MCP 工具:
| 工具 | 功能 |
|---|---|
| `search` | 语义搜索,支持自然语言查询、Top-K、重排序、文件过滤、上下文扩展 |
| `ingest_file` | 导入单个文件,适用于本地部署 |
| `ingest_directory` | 批量导入目录下所有文件,适用于本地部署 |
| `ingest_url` | 从 URL 下载文件并导入知识库 |
| `upload_info` | 获取 REST API 上传接口,适用于远端部署 |
| `list_collections` | 列出所有知识库集合 |
| `list_documents` | 列出集合中的所有文档 |
| `delete_document` | 删除指定文档及其所有向量块 |
| `delete_collection` | 删除整个知识库集合 |
| `configure_collection` | 配置集合的默认参数(分块策略、重排序等) |
| `get_collection_config` | 查看集合的当前配置 |
使用示例
下面通过一个完整的场景来演示如何使用 wandering-rag-mcp 构建一个本地知识库并进行问答。
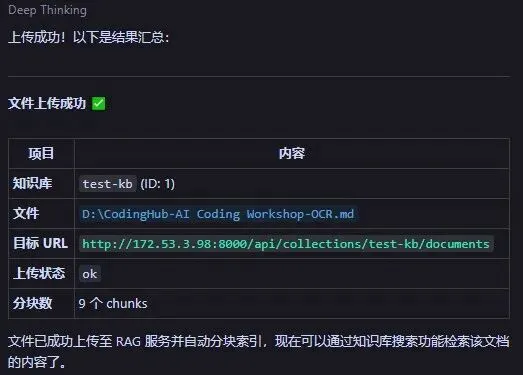
1. 上传单个文件
如果要上传一个单独的技术规格书:
"把 D:\specs\api-design.pdf 上传 project-docs 知识库"
AI 助手调用 upload_info:获取上传REST API信息,然后调用接口做文件传输
curl -F "file=@design-doc.pdf" \ http://localhost:8000/api/collections/project-docs/documents
PDF 文件会被 markitdown 自动转换为文本,再进行分块和索引。返回:
Successfully imported 'D:\specs\api-design.pdf' into collection 'project-docs': 34 chunks indexed.
文档上传成功codebuddy截图
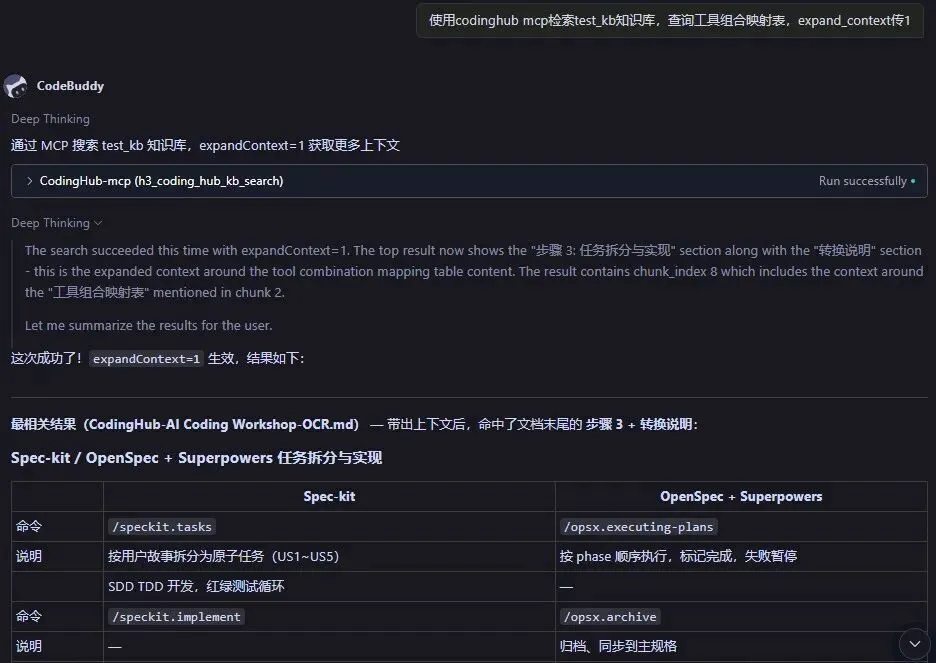
2. 语义搜索
当知识库建好后,就可以通过自然语言进行搜索了。例如:
"在 project-docs 知识库中搜索:用户认证的 API 接口是怎么设计的?"
AI 助手调用 search 工具:
{
"query": "用户认证的 API 接口设计",
"collection": "project-docs",
"top_k": 5,
"rerank": true
}服务器将查询文本编码为向量,在 zvec 中执行 ANN 搜索,可选地经过交叉编码器重排序后返回最相关的文档片段:
Found 5 relevant chunks: --- Result 1 (rerank score: 92.3%, source: api-design.pdf) --- ## 3.2 用户认证接口 系统采用 JWT Token 机制进行用户认证。登录接口 POST /api/v1/auth/login 接受用户名和密码,验证通过后返回 access_token 和 refresh_token... --- Result 2 (rerank score: 87.1%, source: auth-module.md) --- 认证模块位于 src/auth/ 目录下,包含 AuthController、AuthService 和 JwtTokenProvider 三个核心组件... --- Result 3 (rerank score: 81.5%, source: api-design.pdf) --- ## 3.3 Token 刷新 access_token 有效期为 2 小时,过期后客户端需使用 refresh_token 调用 POST /api/v1/auth/refresh 获取新的 token 对...
AI 客户端拿到这些检索结果后,会将其作为上下文与用户的问题一起发送给 LLM,由 LLM 生成最终的自然语言回答。整个过程中,RAG 服务器不需要知道 LLM 的存在——它只负责"找到相关内容",而"理解内容并生成回答"则由 AI 客户端完成。
小技巧:设置expand_context为1会返回前后的chunk,上下文更丰富,结果更准确
3. 配置知识库参数
可以针对不同的知识库设置不同的默认参数。例如,对于代码文件为主的知识库,使用语义分块策略可能更合适:
"把 code-base 知识库的默认分块策略改为 semantic,chunk\_size 设为 600,开启重排序"
{
"collection": "code-base",
"chunk_mode": "semantic",
"chunk_size": 600,
"rerank": true
}此后所有对该知识库的导入和搜索操作都会使用这些默认值,无需每次重复指定。
4. 通过 REST API 上传文件
对于 Web 前端集成场景(如 CodingHub 平台),也可以通过 REST API 直接上传文件:
curl -F "file=@design-doc.pdf" \ http://localhost:8000/api/collections/project-docs/documents
返回:
{"status": "ok", "filename": "design-doc.pdf", "chunks": 24}5 带图片的文件
先使用上一篇介绍的markitdown-mcp做OCR识别把图片转文字,再上传到rag知识库。
总结
wandering-rag-mcp 通过 MCP 协议将 RAG 能力标准化为一系列可组合的工具接口,实现了"检索"与"生成"的解耦。这种设计让任何支持 MCP 协议的 AI 客户端都能即插即用地获得知识库检索能力,而无需关心底层的向量数据库和嵌入模型配置。对于想要为 AI 助手构建私有知识库的开发者来说,这是一个轻量、实用且易于扩展的选择。
本文介绍了AI助手驱动的RAG,至于RAG存什么东西、什么时机检索,可以根据自己业务的实际情况来处理。比如存放已有技术方案、产品手册、问题处理记录等,既可以给AI丰富上下文,也可以给人看。我也处于探索阶段,后续我也会把使用经验分享给大家。
项目地址:
https://github.com/mambo-wang/wandering-rag-mcp
