 夜雨聆风
夜雨聆风BOM递归:工业软件里最被低估的算法,决定了MRP能不能跑准
你有没有遇到过这种情况:
ERP系统里BOM建了几千行,层级看起来清清楚楚,可一跑MRP,结果总是多买、少买、买错。技术团队查了三天,最后发现根因不在MRP参数,而在BOM的递归逻辑——某个半成品被嵌套引用了七层,中间有一层数据错了,所有下级需求全部算偏。
这不是个例。我在多个制造业数字化项目里见过同样的问题:BOM建得”看起来对”,但递归逻辑没理清,后续所有系统都在错误数据上跑。
这篇文章把BOM递归的底层逻辑拆透——从存储结构、遍历算法,到工业落地的注意事项。读完你会明白:为什么理论上BOM可以无限层级,实际中却要人为截断;为什么BOM递归会死循环;以及,如何在你的系统里把这件事做对。
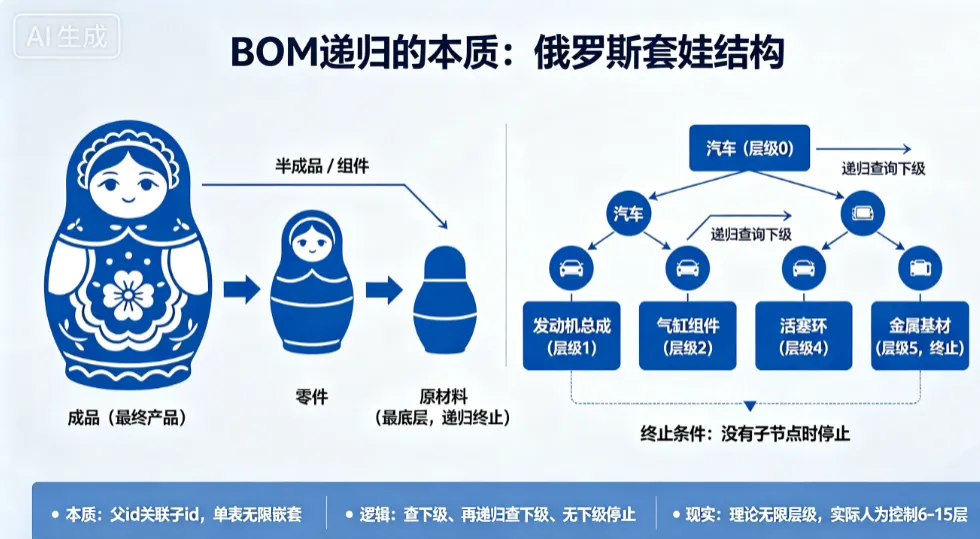
一、BOM递归的本质:俄罗斯套娃
先打个比方。
俄罗斯套娃的特征是:大娃娃里装着中娃娃,中娃娃里装着小娃娃,小娃娃里装着最小的娃娃。可以无限嵌套,没有固定的层数限制。
BOM也是这个逻辑:
最外层大娃娃 = 成品(最终产品,比如一辆汽车) 拆开大娃娃后的中娃娃 = 半成品 / 组件(比如发动机总成) 拆开中娃娃后的小娃娃 = 零件(比如气缸组件) 拆开小娃娃后的最小娃娃 = 原材料(比如金属基材)
递归的定义:不断拆开子节点,直到没有下级(最底层原材料),这个过程就是递归。
真实业务里的BOM层级
以机械行业为例,一个典型的BOM层级是:
汽车(层级0)└─发动机总成(层级1)└─气缸组件(层级2)└─活塞部件(层级3)└─活塞环(层级4)└─金属基材(层级5)
理论上可以无限往下拆分,但实际工业场景中,层级深度是有业务含义的:
关键认知:BOM层级不是越深越好,而是和业务管理粒度匹配。层级太深,MRP运算量大、维护成本高;层级太浅,生产工单拆解不到位,车间执行会乱。
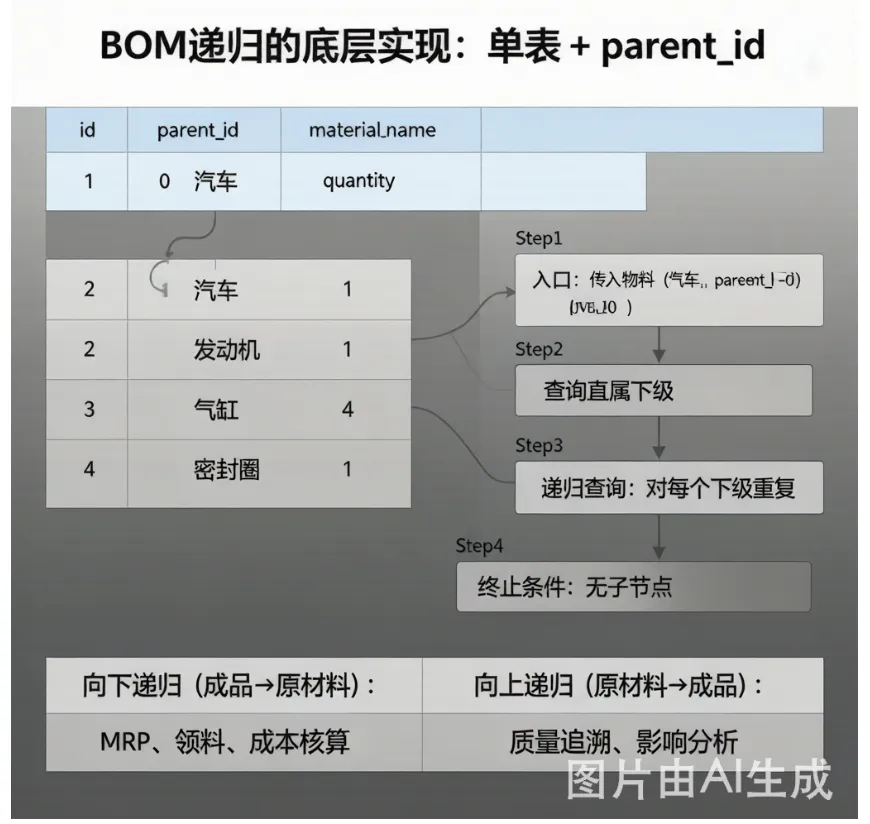
二、底层存储结构:为什么一张表能支持无限层级?
很多人以为,BOM的每一层需要单独建一张表。比如bom_level0、bom_level1、bom_level2……
这是错的。
工业软件(包括SAP、Oracle、用友、金蝶)的底层实现,全行业通用的是:一张表,通过parent_id字段实现无限层级。
单表递归存储结构
id | ||
parent_id | ||
material_name | ||
quantity |
数据示例
逻辑链:汽车 → 发动机 → 气缸 → 密封圈
只要parent_id指向父节点,这张表天然支持无限层级。你想新增第10层、第100层,甚至第10000层,都可以正常存储——数据库不限制行数,也不限制嵌套深度。
这也是BOM可以”理论无限层级”的底层原因
parent_id关联 | ||
三、BOM递归遍历逻辑:工业软件底层是怎么”拆”BOM的?
理解了存储结构,接下来是核心问题:给定一个成品,系统怎么把它的所有下级物料全部找出来?
这就是BOM递归遍历算法。
递归核心规则
传入一个父物料 → 遍历它所有子物料 → 对每一个子物料再次执行相同查询 → 直到没有子物料时停止。
通用四步流程
以【汽车】为例:
第一步:入口
给定顶层物料,parent_id = 0(或指定的根节点ID)。这里传入【汽车】,ID=1。
第二步:查询直属下级
在表中查出所有parent_id = 1的物料,得到:发动机(ID=2)、车架(ID=5)、轮胎(ID=6)……
第三步:递归查询
对每一个下级重复第二步:
拿【发动机,ID=2】查下级,得到:气缸(ID=3)、油管(ID=7)…… 再拿【气缸,ID=3】查下级,得到:活塞(ID=8)、密封圈(ID=4)…… 再拿【密封圈,ID=4】查下级——结果为空,停止。
第四步:终止条件
当一个物料在表中没有任何数据的parent_id等于它的id时,该物料就是最底层原材料,递归终止。
工业软件中的两种递归类型
| 向下递归 | ||
| 向上递归 |
向下递归是MRP运算的核心:系统从销售订单出发,向下递归展开BOM,算出每个原材料的需求量。
向上递归是质量追溯的核心:发现某批原材料有质量问题,向上递归查出所有受影响的成品批次。
四、为什么BOM递归会出事?三大常见问题与解决方案
BOM递归的逻辑并不复杂,但在工业落地中,有三个问题最高发,而且后果严重。
问题一:死循环(最致命)
错误场景:数据错误导致A包含B,B又包含A。递归会无限运行,直接导致数据库CPU飙升、系统卡死。
真实案例:某汽车零部件厂,BOM维护人员误将”轴承盖(ID=203)”的parent_id填成了”轴承总成(ID=198)”的子零件,同时”轴承总成”又是”轴承盖”的子组件——形成了循环引用。MRP一跑,整个系统宕机。
解决方案:
- 软件必须做防循环校验
:在BOM保存时,检查是否存在循环引用(常用方法:给每个节点打访问标记,递归过程中遇到已访问节点即报错) - 数据库层防护
:使用 CONNECT BY语法的数据库(如Oracle)会自动检测循环,但应用层仍需做校验 - 定期审计
:每月跑一次BOM完整性检查,提前发现异常数据
问题二:层级太深,性能卡顿
问题场景:上百层的BOM,每次MRP运算都要反复查询数据库,响应时间从秒级变成分钟级。
解决方案:
- 平铺BOM
:在BOM变更时,预先计算并存储”成品 → 所有原材料”的展平关系表,MRP运算时直接查平铺表,避免实时递归 - 使用数据库原生递归语法
:Oracle的 CONNECT BY、PostgreSQL的WITH RECURSIVE,比应用层递归效率高5-10倍 - 做缓存
:对不频繁变更的BOM,缓存递归结果,减少数据库查询次数
问题三:层级混淆(管理问题,不是技术问题)
问题场景:很多工厂BOM混乱的根源,不是递归算法有问题,而是人为层级定义混乱。比如:
有的零件放在第2层,有的同类零件放在第4层 半成品和原材料的边界不清晰 工艺合件(纯管理用途)混入了参与MRP计算的BOM里
核心结论:BOM层级划分属于管理问题,递归算法属于技术问题。算法再对,管理层级乱,MRP照样跑不准。
解决路径:
制定BOM层级划分标准(比如:0层=成品,1-2层=主要总成,3-4层=部件/零件,5层及以上=原材料) 区分”实物BOM”和”管理型结构”(参考前一篇文章的边界管理原则) BOM变更走审批流程,避免随意调整层级
五、工业落地:BOM递归在三大系统里的不同实现
同一个BOM递归逻辑,在PLM、ERP、MES里,实现的侧重点不同。
| PLM | ||
| ERP | ||
| MES |
关键洞察:BOM递归不是只写一次的代码,而是贯穿PLM-ERP-MES整个数据链的核心逻辑。任何一个环节的递归规则没对齐,数据传递就会出错。
比如:PLM里某个半成品的用量是2,但ERP里BOM的用量写成1,MRP算出来的采购量就会少一半——而这个问题,表面上看和”递归算法”无关,本质是主数据不准。
六、操作建议:三步把BOM递归这件事做对
基于上面的分析,给制造业数字化负责人三个具体建议:
第一步:做一次BOM递归完整性审计
用下面这张检查表,对核心产品的BOM做一次全面体检:
第二步:在系统里落实防循环校验
不管是自研系统还是商用ERP,都必须确保:
BOM保存时有循环引用检查 MRP运行前有一次完整性预检 异常BOM有清晰的报错提示(而不是 silently 算出错误结果)
第三步:制定BOM层级管理规范
把BOM层级划分写进管理制度里,至少明确:
成品、半成品、零件、原材料的层级范围 什么情况下可以新增层级,什么情况下要拒绝 BOM变更的审批流程和责任归属
七、写在后面的话
BOM递归是工业软件里最基础、也最容易被低估的算法。
它不性感,不像AI、大模型那样有话题度;它不显眼,藏在MRP运算、成本卷积、质量追溯的底层,平时没人关注。
但正是这个”不显眼”的算法,决定了你的MRP能不能跑准、成本能不能算对、质量追溯能不能追到根。
下次遇到MRP跑不准的问题,别急着调参数——先看看你的BOM递归逻辑,是不是哪里没理清。
附录:BOM递归完整性自检清单
□核心产品BOM已做循环引用检查,0个循环□ BOM层级深度在6-15层合理范围内□虚拟件(不参与MRP)已正确标识,系统会跳过□关键物料的MRP计算结果已与人工计算核对,误差<2%□ BOM变更走审批流程,有变更日志可追溯□每季度做一次BOM完整性审计,有书面记录
