 夜雨聆风
夜雨聆风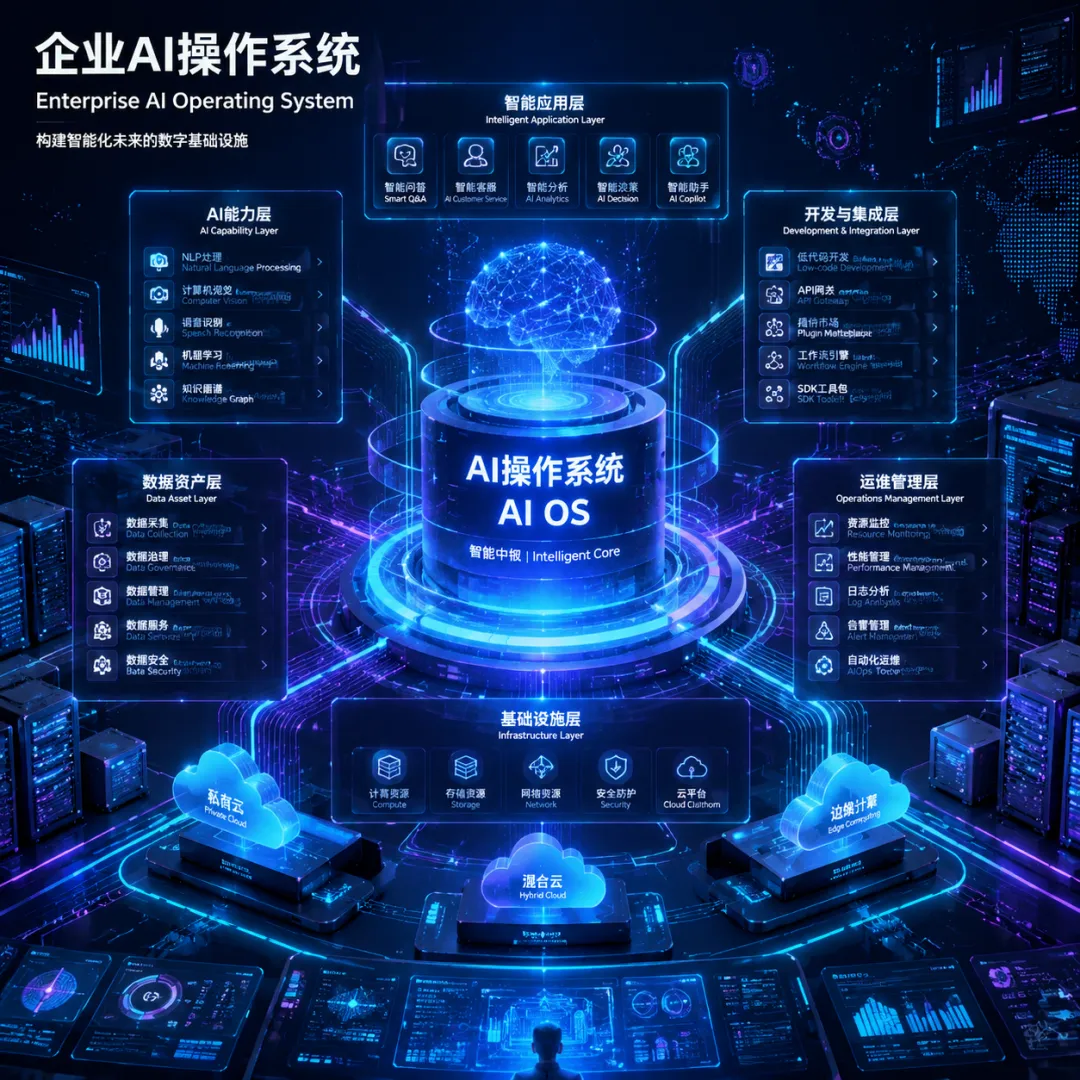
当所有人都在讨论"用哪个AI工具"时,真正的问题其实是:你的企业需要的不是一个工具,而是一套AI基础设施。
Dify不是工具,是企业AI操作系统
2026年,企业AI落地已经走过了"随便接个API试试"的草莽阶段。当沃尔沃用Dify管理自动驾驶数据管线,当理光用它驱动公民开发者构建智能体,当全球超过100万个应用跑在Dify上——一个事实越来越清晰:
Dify不是又一个AI工具,它是企业级AI的操作系统。
这不是一个营销比喻。如果你理解Linux之于服务器、Kubernetes之于容器编排的含义,你就会明白Dify在企业AI栈中扮演的正是同样角色——它定义了应用如何被构建、调度、运行和监控的标准范式。
今天我们不讲"Dify怎么用",而是从操作系统设计的底层逻辑,拆解Dify为什么是AI时代的"基础设施级"存在。
一、认知跃迁:从"工具"到"操作系统"
先问一个问题:你的手机上装了200个App,但真正让这些App能跑起来的,是iOS或Android——那个你看不到的操作系统。
AI应用也一样。一个企业级AI应用需要:
• 调用大模型(哪个模型?怎么切换?怎么控成本?)
• 检索企业知识(文档怎么切?向量库怎么选?怎么重排?)
• 编排工作流(先检索还是先推理?并行还是串行?出错怎么办?)
• 管理权限和审计(谁能用?用了什么?合规吗?)
• 监控和调优(响应慢了找谁?Token花在哪了?)
这些事情,每一件单独拿出来都能做一个"工具"。但如果你的企业要跑10个、50个、100个AI应用,你能忍受每个应用都自己解决一遍这些问题吗?
这就是操作系统的核心价值——提供统一的抽象层,让上层应用只关注业务逻辑,底层复杂性由系统托管。
表1:操作系统 vs Dify 能力对照
这张表不是牵强附会。当你把每一行对照起来看,就会发现Dify的架构设计跟操作系统的设计哲学惊人地一致:分层解耦、统一抽象、插件化扩展。
二、四大核心层:AI操作系统的架构拆解
Dify的系统架构分为六层,但映射到"操作系统"视角,可以归纳为四大核心层:
① 应用层:AI应用的"运行时"
在传统OS中,你写一个程序,编译成二进制,操作系统负责加载和执行。在Dify中,你编排一个工作流(Workflow),系统负责调度和运行。
Dify支持四种应用类型:
• Chatbot:对话式应用,支持上下文管理
• Agent:自主决策型智能体,可调用工具
• Workflow:可视化编排的DAG工作流
• Text Generator:一次性文本生成任务
每种应用都有标准化的运行时:接收输入 → 执行逻辑 → 流式返回结果。这跟操作系统管理进程的方式如出一辙——进程有生命周期,有资源配额,有错误处理机制。Dify的2026版本甚至增加了节点级错误捕获和重试逻辑,这不就是进程的信号处理和异常恢复吗?
② 编排层:工作流引擎 = 进程调度器
这是Dify最核心的能力,也是最像"操作系统内核"的部分。
2026版本的工作流引擎做了三件关键升级:
1. 并行节点执行
以前工作流是串行的——A完成才做B。现在独立节点可以真正并行运行。这意味着一个需要同时检索3个知识库 + 调用2个外部API的Agent,执行时间从5个步骤的串行总和变成最长那个步骤的时间。这是从"单核"到"多核"的跨越。
2. 循环节点
工作流支持对列表中的每个元素迭代执行——相当于操作系统的循环调度。处理一个包含100条工单的列表?一个循环节点搞定,不需要写外部脚本。
3. 全局变量池
跨节点的数据共享机制,类似于操作系统的共享内存。节点A的输出可以自动流转到节点B、C、D,无需手动传递参数。
如果你把这些能力翻译成操作系统术语:并行执行=多线程调度,循环节点=循环队列,变量池=IPC共享内存,条件分支=中断处理。Dify的工作流引擎,本质上就是一个AI任务的内核调度器。
③ 知识层:RAG管道 = 文件系统
操作系统的文件系统负责"存储和检索数据"。Dify的RAG管道负责"存储和检索知识"。这不是简单的类比——它们的架构设计模式几乎相同。
文件系统:数据 → 格式化 → 写入磁盘 → 索引 → 按需检索
RAG管道:文档 → 分块 → 向量化 → 写入向量库 → 混合检索 → 重排序
2026版本RAG管道的五个关键升级,每一个都对应着文件系统的核心能力:
表2:RAG能力 vs 文件系统类比
特别值得一提的是父子分块模式。传统分块按固定大小切割,经常把一句话从中间截断,导致语义断裂。父子分块让小块用于精确匹配、大块用于上下文补充——就像文件系统中inode记录元数据、数据块存储实际内容,各司其职。
④ 驱动层:模型管理 + MCP协议 = 设备驱动
操作系统通过设备驱动对接各种硬件——显卡、网卡、磁盘。Dify通过模型Provider和MCP协议对接各种AI能力和外部系统。
模型管理层支持OpenAI、Anthropic、通义千问、文心一言、DeepSeek等数十种模型,统一接口调用,一键切换。你不需要为每个模型写不同的调用代码——就像你不需要为每个品牌的显卡写不同的驱动程序,Linux内核已经帮你抽象好了。
而2026年最重要的更新——原生MCP(Model Context Protocol)支持——则是Dify从"AI工具"进化为"AI操作系统"的决定性一步。
MCP是Anthropic提出的开放协议,正在成为AI工具集成的"USB-C标准"。Dify原生支持MCP意味着:
• 连接GitHub、Slack、Notion等第三方服务,无需写API包装代码
• 实时访问外部数据库和文件系统
• 自定义工具的标准化接口
• 跨工作流的上下文持久化
这就是操作系统的"即插即用"(Plug and Play)。你接上一个MCP服务器,Dify自动发现、自动适配、自动可用——跟你在Linux上插一个USB设备,内核自动加载驱动是同一个道理。
三、企业级内核:安全、多租户与可观测性
如果上面说的还停留在"工具"层面,那接下来这些能力才真正让Dify配得上"企业级操作系统"这个定位。
多租户架构:每个部门都是独立的"用户空间"
Dify的数据模型以Tenant(租户)为核心组织:
Tenant(工作空间/组织)├── App(AI应用)│ └── Workflow(工作流图定义)├── Dataset(知识库)│ └── Document(文档)└── Member(成员与角色)Account(用户账户)└── 关联多个 Tenant(跨组织协作)
Dify 官方镜像 langgenius/dify-api 通过环境变量 MODE 切换启动角色:
langgenius/dify-api 镜像├── MODE=api → 启动 Gunicorn(HTTP API服务)├── MODE=worker → 启动 Celery Worker(异步任务处理)└── MODE=beat → 启动 Celery Beat(定时任务调度)
每个Tenant有自己的应用、知识库、成员和权限设置,彼此完全隔离。这跟Linux的用户空间隔离是同一个设计哲学:root用户管理整个系统,普通用户只能看到自己的文件和进程。
安全与合规:企业部署的"内核加固"
Dify企业版提供了完整的操作系统级安全能力:
• SSO单点登录:SAML 2.0 / OIDC,对接企业现有身份系统
• RBAC细粒度权限:角色级控制,谁能建应用、谁能看数据、谁能调模型
• 审计日志:所有用户操作全记录,满足合规审查
• API配额管理:防止某个应用"吃掉"所有Token预算
• 私有化部署:数据不出企业网络,许可证管理
• 端到端加密:传输层加密 + 数据访问控制
可观测性:OpenTelemetry全链路追踪
这是很多AI平台缺失但企业必需的能力。Dify深度集成了OpenTelemetry,提供:
• 生成流程追踪:每个Token的来龙去脉
• 工作流执行追踪:哪个节点慢、哪个节点出错
• 模型调用监控:延迟、成功率、成本
• API使用统计:按应用、按用户、按时间段
这就像操作系统的dmesg、strace、perf——当系统出问题时,你需要能看到每一个调用链路,而不是对着一个"Error"干瞪眼。
四、部署架构:单镜像多模式的工程美学
好的操作系统设计,在于用最简洁的架构覆盖最复杂的场景。Dify的容器部署体现了一种工程美学——单镜像多模式运行:
langgenius/dify-api 镜像├── MODE=api → 启动 Gunicorn(HTTP API服务)├── MODE=worker → 启动 Celery Worker(异步任务处理)└── MODE=beat → 启动 Celery Beat(定时任务调度)
一个Docker镜像,三种运行模式,通过环境变量切换。这意味着:
• 构建一次,到处部署——API、Worker、Beat共用同一镜像
• 版本一致性有保障——不会出现API是v1.2但Worker还是v1.1的问题
• 维护成本低——升级只需要重新构建一个镜像
配合Docker Compose的profiles机制,还可以按需选择数据库(PostgreSQL或MySQL)、向量库(Weaviate/Milvus/Qdrant/pgvector等23+种),用YAML锚点共享配置。这种"积木式"的部署设计,让Dify能从单机Docker Compose平滑扩展到Kubernetes集群。
2026版本还做了显著的性能优化:内存占用降低15%,冷启动从3-5分钟缩短到60-90秒,数据库连接池在高并发场景下更高效。这些改进看似不起眼,但对运维团队来说,每一点都是在降低TCO(总拥有成本)。
五、真实案例:当企业把AI跑在"操作系统"上
案例一:沃尔沃汽车——自动驾驶数据管线
沃尔沃AI与数据亚太区负责人Ewen Wang的评价一针见血:"在持续Beta的时代,能快速验证的工具不只是有帮助的,而是生存必需的。"
自动驾驶涉及海量数据处理——传感器日志、路测视频、标注数据。沃尔沃用Dify构建了从数据接入、自动标注、质量检查到模型评估的完整工作流。关键不在于单个功能,而在于所有环节跑在同一个平台上,数据流转无缝衔接。
如果用传统方式,每个环节用不同工具,数据需要反复导入导出,光是维护数据管道就会消耗大量工程资源。Dify作为"操作系统",让这些工具变成了同一系统内的不同"进程",通过工作流编排自动协作。
案例二:理光——公民开发者的AI赋能
理光事业部总经理Yoshiaki Umezu的关键词是"democratize"(民主化):
"Dify让AI Agent开发民主化。通过将强大的AI/ML能力与无代码平台结合,它的快速部署和直观界面让初学者也能轻松上手,显著加速了公民开发。"
这恰恰是操作系统的另一个核心价值——降低使用门槛。Linux让普通程序员也能操作服务器(而不是只有系统管理员才行),Dify让业务人员也能构建AI应用(而不是只有AI工程师才行)。
案例三:跨部门AI应用矩阵
Dify企业版页面展示了一个完整的跨部门AI应用矩阵:
表3:跨部门AI应用矩阵
注意:这些应用共享同一套Dify基础设施——同一套模型管理、同一套知识库、同一套权限体系、同一套监控面板。每个部门只关注自己的业务逻辑,底层复杂性由"操作系统"托管。这就是"一套Dify,全公司AI"的真正含义。
六、Dify vs 其他方案:操作系统 vs 应用程序
理解了Dify是"操作系统"的定位,你就能看清楚它跟其他方案的本质区别:
表4:Dify vs 其他方案
| Dify | |||
LangChain是"标准库"——你用它写代码,但运行环境、监控、权限管理都得自己搞。Coze是"建站工具"——好用但天花板明显,数据不在你手里。直接调API是"裸机编程"——灵活但没有基础设施。
Dify的定位在这三者之上:它既提供可视化编排(比LangChain门槛低),又支持私有化部署和数据自主(比Coze安全),还有完整的企业级基础设施(比裸调API省心)。
这不是功能多少的区别,是架构层次的代差。
七、给企业AI负责人的三条建议
1. 别再为每个AI需求找单独的工具
如果你的企业有3个以上AI应用需求,就应该考虑统一的AI平台。每多一个独立工具,就多一份运维成本、多一个数据孤岛、多一个安全风险点。Dify作为"操作系统",让所有AI应用共享基础设施,是规模效应的必然选择。
2. 从一个高价值场景切入,但要规划全局
不要一上来就想"AI转型"。选一个痛点明确的场景(比如客服知识库、合同审查),用Dify快速落地。但在选型时就要想清楚:这个平台能否支撑未来10个、50个应用?能否对接现有身份系统?能否私有化部署?Dify的优势在于,你从一个场景切入后,扩展到其他场景不需要换平台。
3. 重视可观测性,否则AI就是黑箱
企业AI最大的风险不是模型不够强,而是你不知道它在做什么。Dify的OpenTelemetry集成和审计日志能力,让每个AI调用都可追踪、可审计、可优化。在合规要求越来越高的今天,这不是可选项,是必选项。
结语
回到标题——Dify不是工具,是企业AI操作系统。
这不是说Dify没有工具属性,而是说把它当工具来理解,严重低估了它的价值。就像你不会把Linux称为"一个跑程序的软件"——它是整个服务器生态的基石。
2026年的Dify,已经具备了操作系统的所有核心要素:统一的运行时环境(工作流引擎)、标准化的文件系统(RAG管道)、丰富的驱动生态(模型管理+MCP协议)、完善的安全机制(多租户+RBAC+审计)、以及内置的可观测性(OTel全链路追踪)。
当全球已有超过100万个应用跑在Dify上,当沃尔沃、理光这样的行业巨头把它作为AI战略基础设施——是时候停止用"工具"的眼光看Dify了。
你的企业需要的不是一个AI工具,而是一套AI操作系统。
— Dify,可能是目前最好的答案。
如果这篇文章对你有启发,欢迎转发给团队中负责AI落地的同事。关注我们,获取更多企业AI实战干货。
