 夜雨聆风
夜雨聆风最近我维护的开源 PDF 翻译工具 pdfTrans 做了两个重大更新,更新日志都写了将近 200 行。今天跟你聊聊这次更新里值得关注的东西:藏语翻译全链路支持,还有百度千帆平台 API 接入。
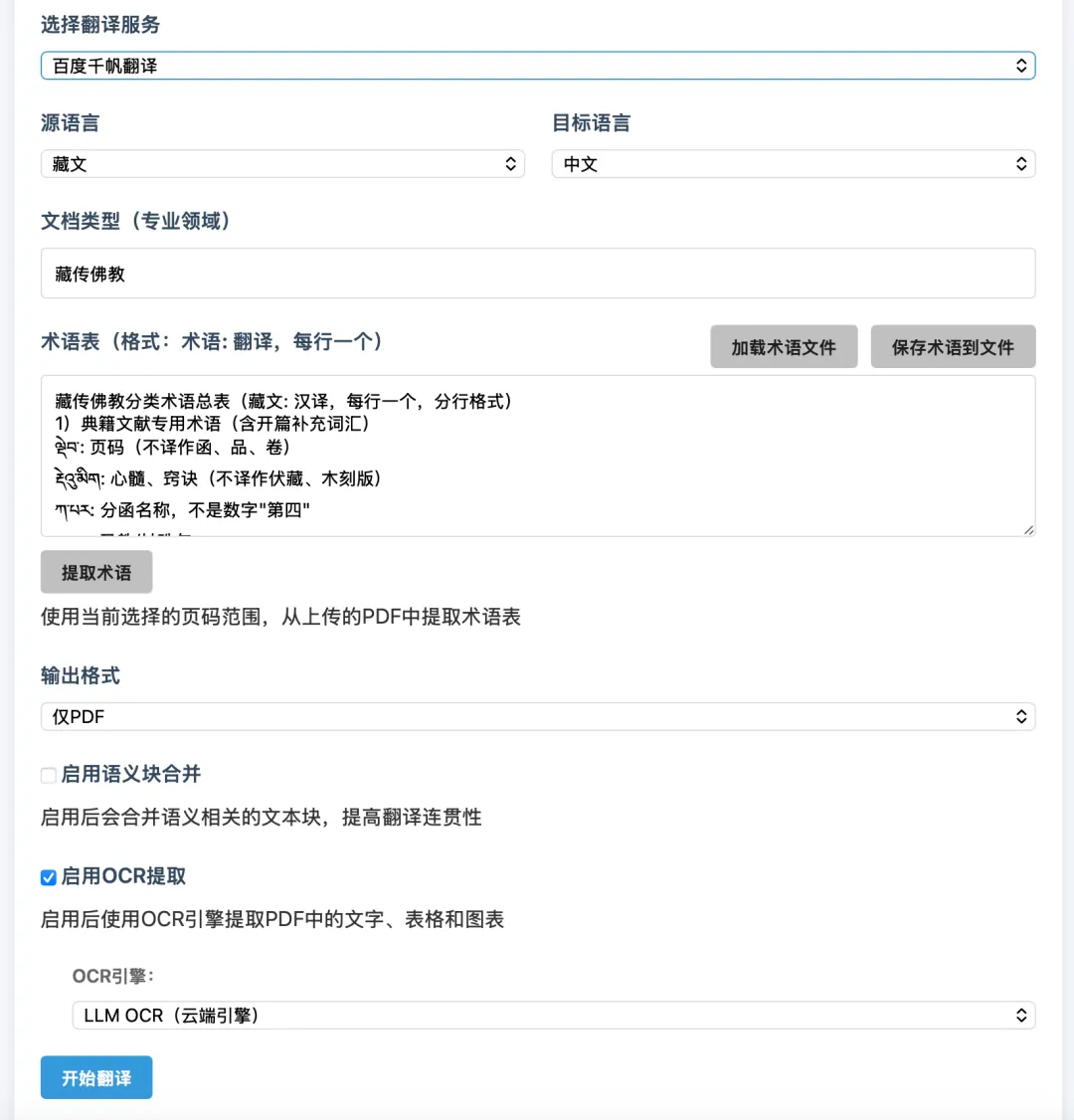
百度千帆来了
pdfTrans 最早只接了硅基流动平台上提供的 API,后来加上了 Aiping 的API。这次更新,直接把百度千帆也接了进去。一般来说三选一即可。
每家平台能用的模型不同,而不同的模型对不同语种、不同领域的文档,出来的效果也会有差别。比如文心模型对中文理解和表达有天然优势,翻出来的东西更自然。
除了使用Web界面下拉框里选择平台,也可以在 命令 CLI 里用 -T qianfan 切换百度千帆。环境变量配置文件里新增了 QIANFAN_API_KEY、QIANFAN_MODEL_TRANSLATION 等选项,跟另外两家配置方式完全一致。
另外,这次更新里还修复了一个跟 GLM-5.1 模型相关的坑。之前 GLM 系列的关闭思考的参数没有起作用,思考模式默认是开启的,翻译藏语时模型会先生成上万 token 的推理过程,把 token 配额全耗光了,最后翻译结果直接是空的。修正之后,GLM 和 Qwen 两个系列都能正常工作了。
藏语支持:小众语言的大工程
这次更新里,我个人觉得最有价值的一个功能是藏语支持。
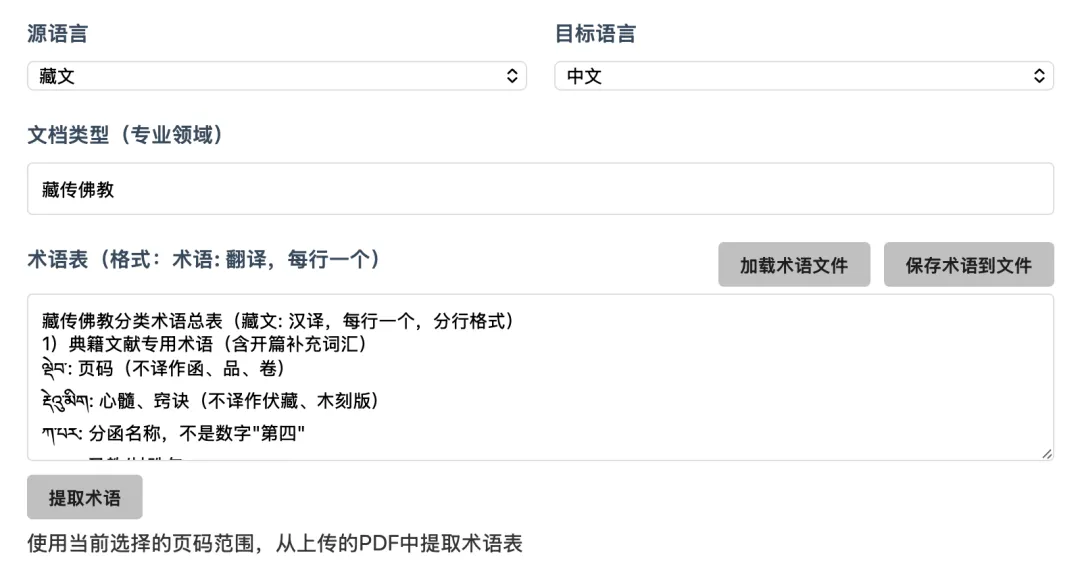
藏语翻译的需求其实不小。学术研究、历史文献、政府公文,大量藏语 PDF 需要翻译成中文。
这次新增了藏语(语言代码 bo)的支持。从翻译器到语义分析器到术语提取器,全链路都接入了藏语。翻译提示词里还专门写了藏语到中文的翻译专项规则,覆盖了藏语语法、敬语体系、格助词、省略规则等细节。建议塔配藏语术语表使用,翻译结果更准确。需要注意,文档类型必须根据实际情况选择,比如"藏传佛教"、"藏语历史"等。
另外,建议使用GLM-5.1模型翻译藏语,测试下来感觉效果比较好,缺点就是贵,但是至少不会象有些模型一样直接胡言乱语,甚至拒绝翻译。
需要注意的是,很多藏语PDF里都是扫描图片,建议选择 LLM-OCR 模式并配置模型 Deepseek-OCR 来识别图片并翻译。

LLM-OCR 模式除了能配置 Deepseek-OCR 模型,也支持配置其它的视觉模型来识别图片中的藏语,比如 QWen VL 系列。
这是一页藏传佛教文档的翻译对比,使用 Deepseek OCR 识别, GLM 5.1 翻译:


对于命令行模式,翻译藏语需要指定源语言主代码bo, 并指定术语表文件glossary.txt:
pdftrans translate document.pdf -s bo -t zh -g glossary.txt -o output.pdf这次更新,还为CLI命令行模式新增了指定模型名称的参数,可以在命令行中直接指定,覆盖默认环境文件配置的翻译模型,方便批量翻译。
--translation-model:指定翻译模型模型名--layout-model:指定Markdown排版模型--glossary-model:指定术语提取模型--ocr-llm-model:指定LLM OCR模型
一次命令,三种格式
之前的 pdfTrans 命令行翻译一次只能输出一种格式:要么 PDF,要么 Word,要么 Markdown。想要三种全要,得跑三次。
现在 CLI 新增了组合输出格式。-f pdf_docx 一次输出 PDF 加 Word,-f all 直接 PDF、Word、Markdown 三件套全给你。
这个功能特别适合需要灵活分发翻译结果的场景。比如翻译完一份技术文档,PDF 给客户看,Word 给同事编辑,Markdown 扔到知识库,一个命令全搞定。
翻译可靠性:从能用到好用
28日更新了一个新模块叫 llm_error_handler,这是个统一错误处理模块。以前翻译失败,日志里就一个干巴巴的 str(e),你根本不知道是 API 密钥过期了,还是被限流了,还是模型直接挂了。现在每种错误都被分类、并有友好提示。
翻译器也全部切成了流式调用。流式的好处是实时返回,不会因为一个长文档卡半天。而且所有翻译器统一禁用了 SDK 内置的重试,改由应用层自己控制,避免底层重试叠加导致连锁失败。
语义分析器也加了三级 JSON 提取容错。正常情况下模型返回的就是标准 JSON,但有时候模型会自作主张在 JSON 外面包一层 markdown 代码块,或者在 JSON 前后加一堆文字。以前这种场景就直接挂了,现在能自动把 JSON 从包围中抠出来。
安装步骤
1. 克隆仓库
Gitee仓库地址:https://gitee.com/chunju/pdfTrans
GitHub仓库地址:https://github.com/chunju-zhong/pdfTrans
git clone https://gitee.com/chunju/pdfTrans.git# 或git clone https://github.com/chunju-zhong/pdfTrans.gitcd pdfTrans2. 创建并激活conda环境
conda env create -f environment.ymlconda activate pdfTrans3. 配置环境变量
复制 .env.example文件为.env注册平台的账号(三选一) Aiping账号:https://aiping.cn/#?invitation_code=UVSZ6QWRRK 硅基流动账号:https://cloud.siliconflow.cn/i/OFUfQfNj 百度千帆账号:https://cloud.baidu.com/product-s/qianfan_home 获得平台成API密钥 在 .env文件中配置平台模型名称及API的密钥
cp .env.example .env4. 安装依赖
pip install -r requirements.txt5. 安装 PaddlePaddle(不用可以不装)
PaddlePaddle 的 CPU 和 GPU 版本互斥,不能同时安装。使用自动检测脚本:
bash install_paddle.sh或手动安装:
# CPU版本(默认,适用于所有平台)pip install paddlepaddle>=3.0.0# GPU版本(需要 NVIDIA GPU + CUDA 11.8+)pip install paddlepaddle-gpu>=3.0.0注意:OCR功能需要安装 PaddlePaddle(PaddleOCR引擎)或配置 LLM OCR 模型(LLM OCR引擎)。如两者均未配置,OCR提取功能将不可用。
6. 安装 LaTeX(可选,公式高质量渲染)
LaTeX 用于公式的高质量渲染(usetex 模式)。如不安装,系统将自动降级使用 matplotlib mathtext 渲染公式,功能可用,但复杂公式效果可能较差。
# macOSbrew install --cask mactex# 或仅安装基础版(体积更小)brew install --cask basictex# Linux (Ubuntu/Debian)sudo apt-get install texlive-full# 或仅安装基础版(体积更小)sudo apt-get install texlive-latex-base texlive-fonts-recommended注意:安装完成后请确保
latex命令可在终端中直接调用。
怎么用
pdfTrans 提供三种使用方式,你可以根据场景选。
Web 界面:适合偶尔用一下,打开浏览器上传文件就行。
python app.py# 然后访问 http://localhost:5000CLI 命令行:适合批量处理,或者放到自动化脚本里。
# 安装pip install -e .# 翻译英文 PDF 为中文pdftrans translate document.pdf -o output.pdf# 用千帆翻译,输出 PDF+Word+Markdownpdftrans translate document.pdf -T qianfan -f all -o output.pdfAI IDE 技能模式:如果你用的是 Trae 这类支持 Skill 的 AI IDE,直接把 pdfTrans 放到技能目录下,在对话窗口里说一句帮我翻译这个 PDF,AI 会自动帮你组装命令。
一个开源工具,为什么要花这么多时间打磨
写到这里,想聊点题外话。
pdfTrans 这个项目从开始到现在,代码拆了又拆,重构了又重构。有人说一个翻译工具,能跑就行,搞那么复杂干嘛。
但我的想法不一样。翻译工具是一个典型的看起来很简单的功能,做起来全是坑的产品。表格对齐、公式保留、换行处理、OCR 定位、大模型幻觉,每个环节都可能翻车。
这次两个大版本的更新,表面上是加了新功能,但仔细看更新日志,大量的工作是在做底层重构:TranslationService 从 1400 行拆成 5 个子模块,PdfGenerator 从 1641 行精简到 300 行,Config 从类级别属性改成实例级别。这些改动用户看不到,但直接影响工具能不能稳定跑完一份上百页的 PDF。
如果你有翻译 PDF 的需求,或者对这个小工具感兴趣,欢迎去 Gitee 上看看。也欢迎在公众号或小红书留言,聊聊你遇到过的坑。
