夜雨聆风
夜雨聆风最近 AI 工具圈有一个很明显的变化。
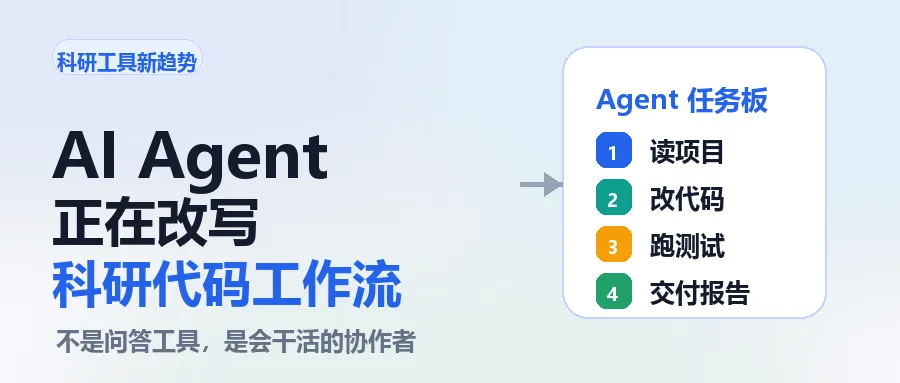
大家不再只讨论“哪个模型回答更聪明”,而是在讨论:能不能把一个任务交给它,让它自己读项目、改文件、跑命令、留下日志,最后给你一个可检查的结果。
这件事对研究生其实很重要。
因为读研最消耗人的,往往不是那个宏大的 idea。
而是这些东西:
一个别人开源但跑不起来的代码仓库。 一堆版本冲突、路径错误、CUDA 报错。 做完实验后散落在不同文件夹里的日志。 想改一个 baseline,却不敢动整个项目。 每次和师兄、导师沟通,都要重新解释“我现在跑到哪一步了”。
以前我们把 AI 当成搜索框、翻译器、润色工具。
但现在更值得关注的是:AI Agent 正在进入科研工作流。

如果只看单个工具,你会觉得每家都在宣传自己。
但把这些信号放在一起,趋势就很清楚。
GitHub 在 2025 年推出 Copilot coding agent,核心变化是:你可以把 issue 分配给 Copilot,它在后台工作,最后提交 pull request。
Anthropic 的 Claude Code 也不只是聊天窗口,它强调的是:在终端和 IDE 里理解代码库、编辑文件、运行命令、处理 git 工作流。
Google 推出的 Gemini CLI,则把 AI Agent 直接放进命令行,面向 coding、problem-solving 和 task management。
OpenAI 最近关于 agents 工作方式的文章里,也强调了一个很关键的方向:真正有价值的 Agent,不是“问一句答一句”,而是更像一个可以被委派任务的工作单元。
这对科研来说,意味着一个判断:
下一轮 AI 工具的信息差,不在于你会不会写提示词,而在于你会不会把科研任务拆成 Agent 能接、你能验收的小任务。
研究生最容易误用 AI 的地方,是直接问:
“帮我复现这个项目。”
这个问题太大。
更好的问法是:
“先不要改代码。请你读这个仓库,告诉我入口文件、数据流、环境依赖、运行命令、可能报错点,并列出最小复现实验方案。”
这两个问题看起来只差一句话。
实际差的是工作方式。
前者是在许愿。
后者是在分配任务。
很多人一听 Agent,就想让它帮自己做整个课题。
这反而危险。
AI Agent 最适合接的,不是“这个方向有没有创新”这种判断题,而是那些规则明确、结果可检查、人工做很烦的任务。
比如:
读一个陌生代码库,先画出结构和入口。 把 README 里的环境配置整理成可执行步骤。 找出某个报错可能来自依赖、路径、数据格式还是显存。 把一个长脚本拆成几个函数。 给已有代码补最小测试。 把实验日志整理成表格。 根据输出结果生成图标题、表注、实验记录草稿。
这些事情不高级。
但它们非常耗时间。
而且它们有共同点:你能检查它做得对不对。
这就是 Agent 适合科研的第一原则:
能验收的任务,可以交给 Agent;不能验收的判断,必须自己负责。
读研期间,很多人的第一道坎不是创新,而是复现。
你下载一个代码仓库,README 看着很完整,但一跑就报错。
Python 版本不对。
PyTorch 版本不对。
数据路径不对。
模型权重下载不了。
配置文件里还有几个没有说明的参数。
这时候不要一上来让 Agent “帮我修好”。
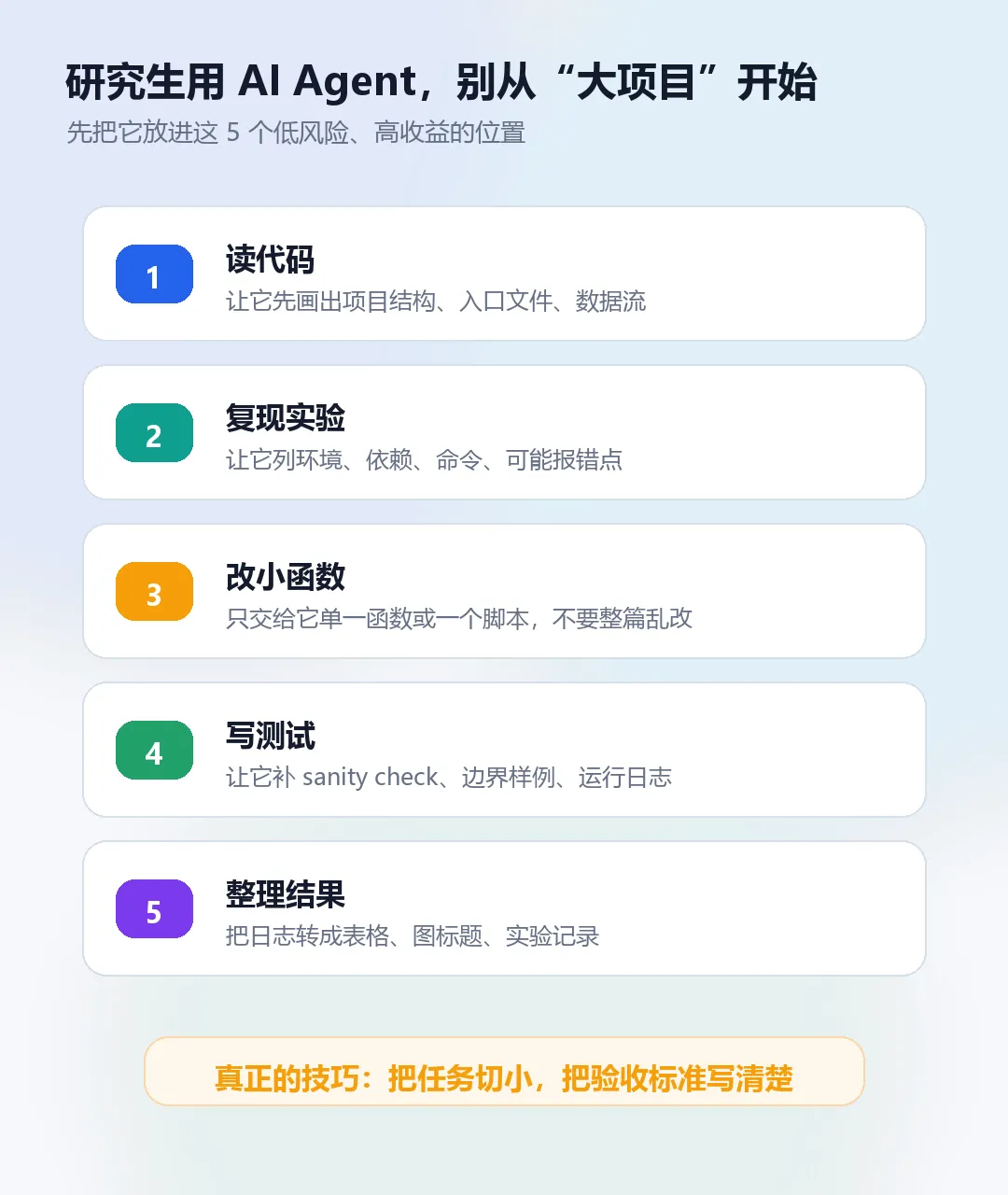
先让它做四步。
第一步,读项目结构:
它要告诉你哪些文件是入口,哪些文件是模型,哪些文件是数据处理,哪些文件是训练脚本,哪些文件只是工具函数。
第二步,列运行链路:
从数据准备,到训练,到评估,到保存结果,整个流程按顺序列出来。
第三步,找最小可运行实验:
不要一开始就全量训练。先用一小部分数据,跑通一个 batch,保存一次输出,确认流程通。
第四步,列风险点:
哪些地方可能卡在环境,哪些地方可能卡在数据,哪些地方可能卡在显存,哪些地方可能需要人工下载。
这样做的好处是,你不会被 Agent 牵着乱改。
它先给你地图。
你再决定从哪里下手。
Agent 能干活,不等于它能替你负责。
尤其是科研场景,下面这些事情不要外包:
判断一个方向是否有创新。 决定实验结果是否支持论文主张。 编造没有跑过的结果。 替你下结论说“显著优于 baseline”。 把没验证过的代码当作最终实验代码。 把不确定的引用、数据来源写成确定事实。
AI 很容易给出一种“看起来很完整”的答案。
但科研里最贵的不是完整。
是可靠。
所以你要把 Agent 当成研究助理,而不是共同作者。
它可以帮你整理材料、跑通流程、定位问题、生成初稿。
但它不能替你承担真实性。

适合场景:刚拿到一个 GitHub 项目,不知道怎么跑。
你可以让 Agent 输出:
项目目录说明。 入口脚本。 数据流。 配置文件含义。 最小运行命令。 可能缺失的依赖。
重点不是让它立刻改。
重点是让它先“读懂”。
适合场景:你已经跑了命令,但卡在报错。
不要只丢一行 error。
最好给它这些信息:
完整命令。 完整报错。 当前环境。 相关配置文件。 你已经试过的方案。 希望它先分析,不要直接改代码。
这样它的输出会更像排查记录,而不是随便猜一个方案。
适合场景:你跑了很多组实验,但日志很乱。
让 Agent 做:
提取每组实验的参数。 提取指标。 按数据集、方法、指标整理表格。 标出缺失值。 给出“哪些结果还需要补跑”的清单。
这个任务特别适合研究生。
因为它不替你造结果,只帮你把已经发生的实验整理清楚。
你最后要做的,是检查表格是否和原始日志一致。
下面这段可以直接放到 Codex、Claude Code、Gemini CLI 或其他能读项目的 Agent 工具里。
不要一上来让它“帮我做完”。
先让它计划。

你可以这样写:
你是我的科研代码助理。先不要直接改代码,先完成 4 件事:1. 读项目结构,说明入口文件和数据流;2. 找出运行所需环境、命令和潜在报错;3. 给出最小可运行实验方案;4. 列出你准备修改的文件和原因。修改时遵守:- 一次只改一个目标;- 保留原始结果和日志;- 每次改完都给出验证命令;- 不确定的地方标注“需要人工确认”。如果你只记住一句话,就记住这句:
先计划,再执行;先验证,再相信。
以前会写代码,是优势。
后来会调包、会复现、会读论文,是优势。
接下来,会不会管理 AI Agent,也会变成一种实际能力。
不是因为它神。
而是因为科研里有太多重复、琐碎、但必须做对的环节。
你不需要把所有事情都交给它。
你要学会把任务切小,把标准写清,把过程留下,把结果验收。
这才是研究生真正该学的 AI 用法。
不是让 AI 替你读研。
而是让它替你处理那些本来就不该消耗你整晚的脏活。
如果你最近也卡在导师选择、读研规划、论文选题、代码复现、实验 debug 或科研工具选择上,可以来找我聊。能帮你一起拆问题、看方向、搭工作流,也可以直接做技术支持。