 夜雨聆风
夜雨聆风我最近不太想继续测试“AI 会不会总结论文”了。
这件事已经不新鲜。把 PDF 丢进去,它多半能吐出摘要、贡献、局限,偶尔还会把公式解释得像回事。读完之后呢?我更关心的是:一篇论文能不能被 AI 处理成可以直接进入工作流的东西。
比如文章、图解、幻灯片。不是让 AI 替我下结论,而是看它能不能把论文里的信息,转成不同场景里能用的表达。
这次我测试的是 paper-craft-skills[1]。它不是一个点开就用的独立 App,更像给 Codex、Claude Code 这类 Agent 准备的技能包。项目里分了几条路线:paper-analyzer 写论文分析,paper-comic 做论文图解,paper-deck 生成汇报用的幻灯片。
测试对象我选了一篇跑步论文,题目是《The training intensity distribution of marathon runners across performance levels》。论文 24 页,研究 119,452 名跑者、151,813 场马拉松,数据来自赛前 16 周的训练记录。
它的核心发现很适合跑圈讨论:跑得快的人,不一定是高强度比例更高,而是能用更多低强度训练撑起更大的总跑量。最快组一周大约 107 公里,较慢组大约 35 公里。真正拉开差距的,是 Z1 低强度训练堆出来的容量。
这是一个挺好的样本。数字足够大,结论有传播性,也容易检查 AI 有没有乱讲。
先看文字:一篇论文的三种读法
我先跑 paper-analyzer。
它做的事比普通摘要多一点:先解析 PDF 全文,再查论文有没有公开代码仓库,最后按指定风格生成 HTML。这次它提取了大约 5.2 万字符、7,947 个英文词。代码部分没有找到公开仓库,论文里也写明数据来自 Strava 的有限研究许可,代码需要向作者合理请求。
这一点我反而喜欢。没有公开代码,就写没有;不能做源码对照,就别编一个“复现分析”。
我生成了三版:academic 最像文献解读,会保留论文元信息、研究问题、方法、公式、图表引用和局限;concise 像一张压缩过的论文卡片,适合快速判断值不值得继续读;storytelling 更接近公众号文章风格,会从“快跑者是不是练得更狠”这样的直觉问题切入,再把结果讲给普通跑者听。
同一篇论文,被拆成三种读法。这是我觉得 paper-analyzer 比“总结器”更有意思的地方。总结器回答的是“这篇讲了什么”,而它开始处理另一个问题:这篇论文要讲给谁听。
再看图:论文开始有了第二张脸
接着是 paper-comic。
名字里有 comic,但它不是把论文画成剧情漫画。更准确地说,它是在做论文图解:方法流程、变量关系、关键结果,尽量用图讲清楚。我让它给这篇马拉松论文生成 4 张中文 sketchnote,最喜欢的是封面这张。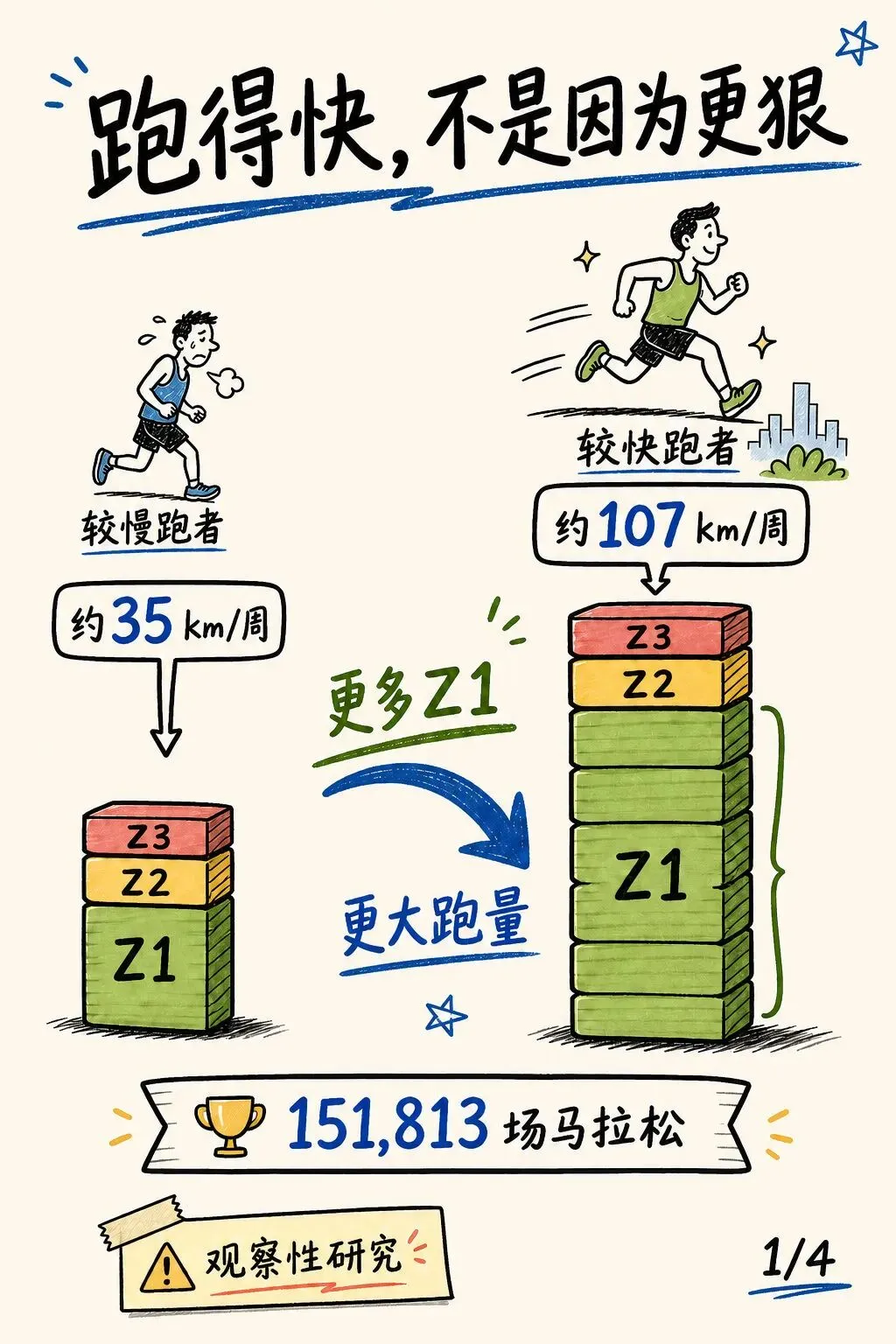
这张图的好处很直接:左边是较慢跑者,一周约 35 公里;右边是较快跑者,一周约 107 公里。两个柱子都按 Z1、Z2、Z3 分层,用的是跑圈熟悉的绿色、黄色、红色。
不用解释太多,一眼就能看到:较快跑者的柱子更高,多出来的大部分是 Z1。这不是“给文章配图”,而是把论文的核心关系重新说了一遍。
后面几张图继续拆方法流程、三区间划分和主要结果。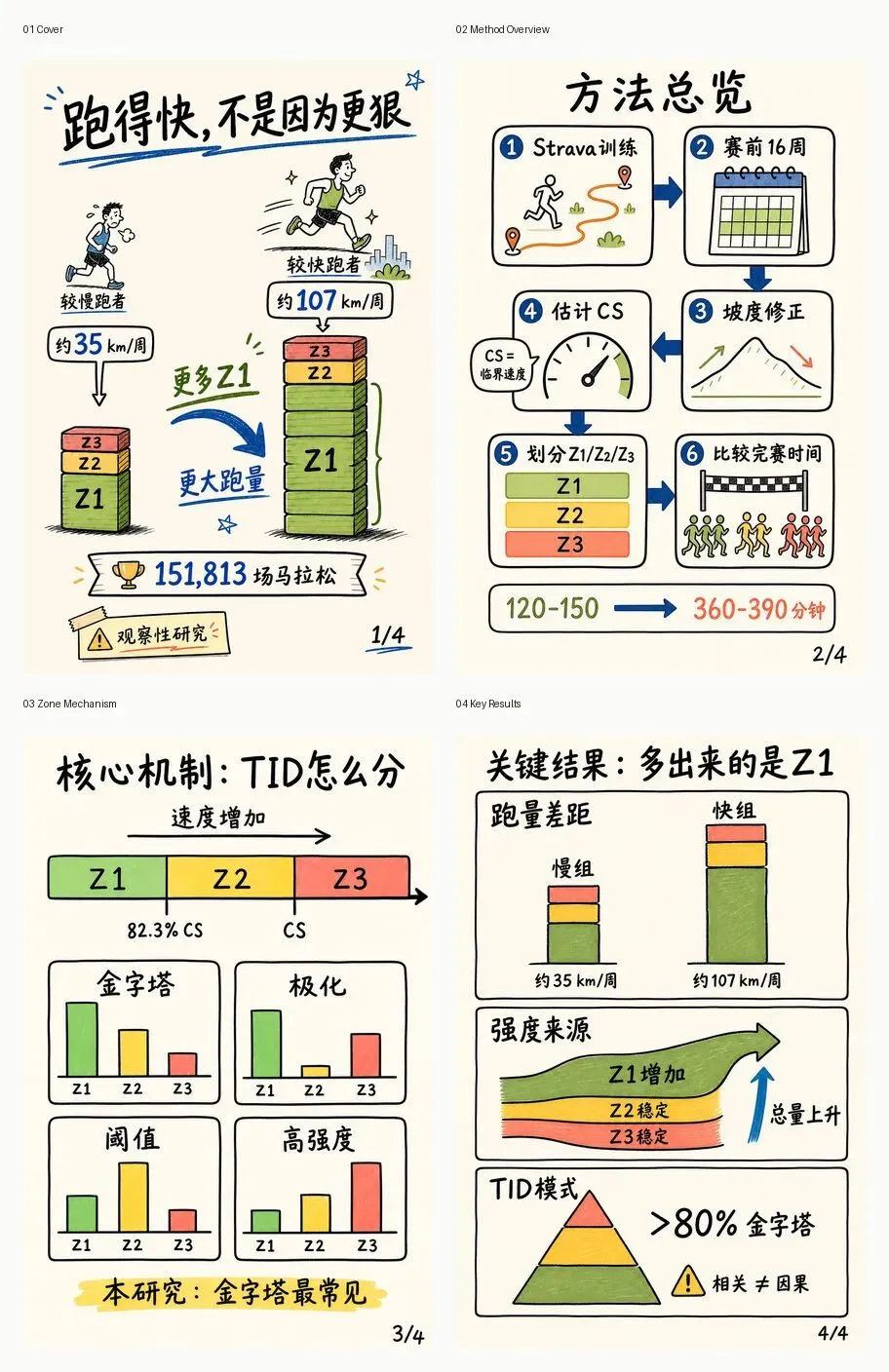
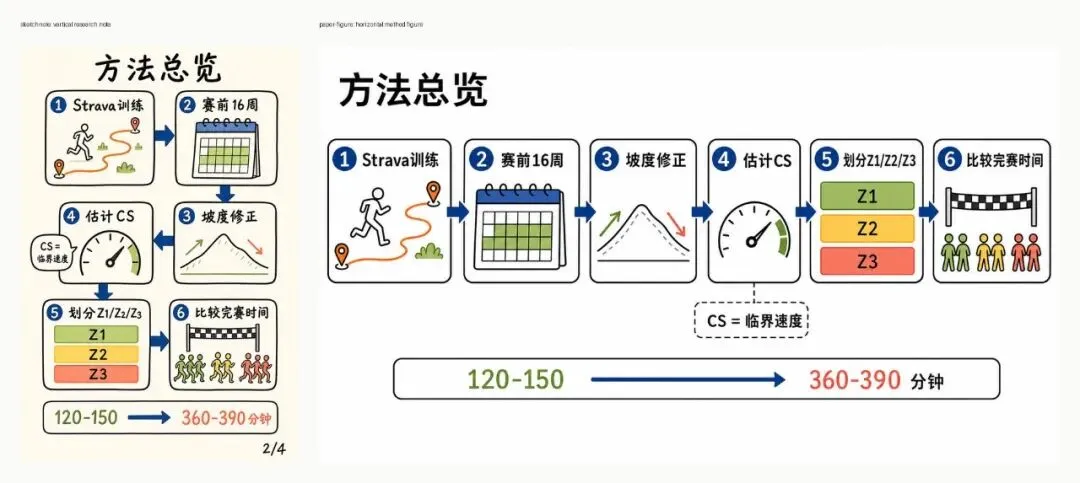
我还把同一张方法总览图用 paper-figure 风格跑了一版。对比很明显:sketchnote 更像公众号解释图,paper-figure 更像论文里的机制示意,适合放进汇报。
 这里也有一次小翻车。第一版封面里,模型自己在柱子旁边加了百分比。那些数字看着很像论文结果,但并不是论文直接给出的快慢两组百分比。我后来保留了柱形对比和 Z1/Z2/Z3 结构,把百分比去掉。
这里也有一次小翻车。第一版封面里,模型自己在柱子旁边加了百分比。那些数字看着很像论文结果,但并不是论文直接给出的快慢两组百分比。我后来保留了柱形对比和 Z1/Z2/Z3 结构,把百分比去掉。
这个细节很能说明问题。AI 生图很适合把概念快速视觉化,但只要图里出现数字,就必须人工看一遍。尤其是中文、论文数据、图表标注,不能因为画面完整就默认它正确。
最后是 PPT:像一个已经搭好的汇报骨架
paper-deck 是第三步。
它不是把文章塞进模板,而是先生成 deck brief,再写 outline,再逐页生成 16:9 的 slide image,最后合成 PPTX 和 PDF。我这次选了 8 页 journal-minimal 风格。
这套 deck 的顺序比较清楚:封面抛出主结论,后面依次讲问题、数据集、方法流程、Z1/Z2/Z3 的划分,再用最快组和较慢组的周跑量差距收束到结论。它也保留了一个必要提醒:这仍然是观察性研究,不能直接说因果。
它已经不像“生成几张漂亮幻灯片”了,更像一个汇报雏形。你可以拿它去内部分享,也可以继续改成正式课件。
限制也很清楚:这套 PPT 是 raster-first,每一页本质上是一张整页图片。视觉上成稿很快,但不能像正常 PPT 那样逐个编辑标题、图表、文本框。如果要精修到发布级,后面还是要人工重做一部分。
所以我更愿意把 paper-deck 看成汇报草稿生成器。它帮你把顺序、节奏和视觉方向先搭出来,不负责替你做最终审稿。
我觉得它真正有用的地方
这一轮跑完以后,我对“AI 读论文”的期待有点变化。
以前我会把重点放在理解上:摘要准不准,贡献有没有说全,局限有没有漏掉。这些当然重要,但在真实工作里,理解往往只是第一步。你还要写公众号、做组会分享、给团队讲研究发现,或者把论文改写成不同读者能听懂的版本。
这时候,单纯的总结就不够了。你需要的是一条从 PDF 到内容材料的流水线。
paper-craft-skills 现在做的就是这个方向:同一篇论文,先变成文章,再变成图解,最后变成幻灯片。每一步都不是终稿,但都比空白页好很多。
我喜欢这个定位。它没有把人挤出去,反而把人的工作往后挪了一段:从搭结构、找表达,变成判断、校对和取舍。
也别把它想得太自动
这套流程有用,但还不能闭眼交付。
它依赖 Agent 环境。paper-craft-skills 是技能包,不是完整 SaaS。你用的是 Codex、Claude Code,还是别的执行环境,PDF 解析、生图、文件处理能力都会影响结果。
生图也要逐张检查。我这次遇到的百分比问题不算严重,因为很容易发现;如果是更细的实验流程、统计图或中文标签,错误可能更隐蔽。PPT 也一样,整页图片适合快速预览和汇报雏形,但如果希望团队继续改,就需要重新拆成可编辑对象。
论文有没有公开代码也不能强求。这次这篇论文没有公开 GitHub 仓库,paper-analyzer 能做的是说明状态,而不是假装完成了源码分析。
这些边界会让它没那么“神”,但也让它更像一个能放进真实工作流的工具。它不替你判断论文,也不替你承担发布责任。它做的是把原本很耗时的第一版内容,先推到你面前。
结尾
如果只看摘要能力,AI 读论文已经不稀奇了。更值得观察的,是它能不能把论文转成可以被别人阅读、理解和转述的东西。
这次用一篇马拉松训练论文测试下来,我对 paper-craft-skills 的印象大概是:它不是论文阅读器,更像论文内容工作台。你把 PDF 放进去,它给你文章、图解和 PPT 的初稿。剩下的工作仍然要人来做:查数字、改表达、决定哪些内容能发,哪些只能当草稿。
但至少你不是从空白页开始了。对经常读论文、写科普、做研究分享的人来说,这已经是一个很实在的变化。
引用链接
[1] `paper-craft-skills`: https://github.com/zsyggg/paper-craft-skills
