当前时间: 1970-01-01 08:00:00
分类:办公文件
评论(0)
别再让 AI 每次重新读 PDF 了几秒钟速读版
这篇讲什么
这次看的项目是 GitHub 上的 virgiliojr94/book-to-skill。仓库地址:https://github.com/virgiliojr94/book-to-skill它做的事很直接:把技术书、PDF、EPUB、DOCX、Markdown、HTML、RTF、MOBI/AZW 等文档,转换成 Claude Code 能按需加载的 Skill。为什么要看
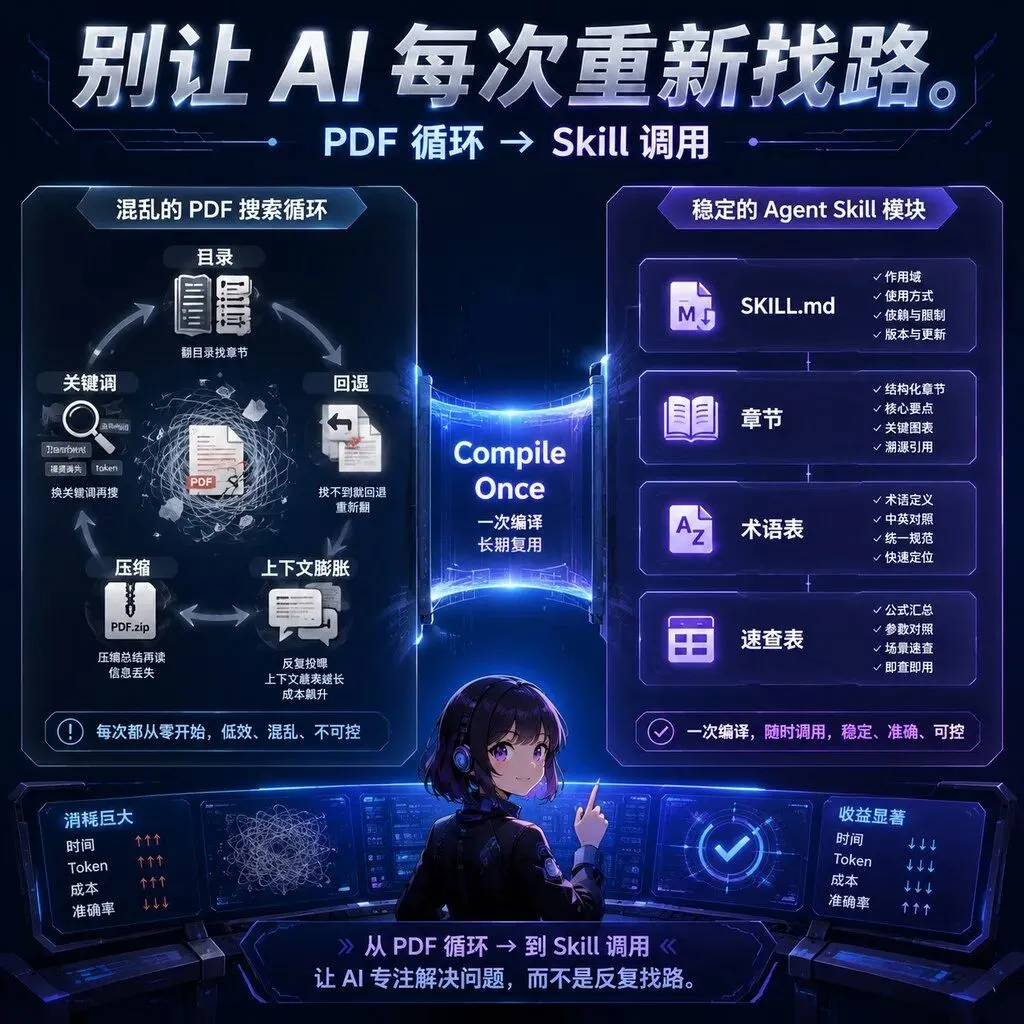
因为很多人对 AI 学习资料的理解还停在“把 PDF 丢进上下文”。这能用,但不适合长期使用。上下文一大,token 成本上去;内容一多,Agent 每次都要重新找、重新压缩、重新解释。book-to-skill 给了另一个思路:先把知识编译成结构化技能,之后每次只加载相关章节、术语、模式和速查表。你能记住什么
- 它不是普通读书笔记工具,而是“书籍到 Agent Skill”的转换器。
- 它生成 SKILL.md、chapters、glossary、patterns、cheatsheet,知识被拆成可调用结构。
- 它支持多种输入格式,不只 PDF,也能处理文件夹、glob 和多文件集合。
- 它适合反复使用的技术书、规范、内部文档、研究资料,不适合只看一次的材料。
适合谁
适合经常读技术书、维护知识库、写代码时要查规范、做 Agent Skills、把团队文档沉淀成可复用能力的人。不适合谁
如果你只是临时问一本书的一个问题,直接丢给 PDF 阅读工具就够了。book-to-skill 的价值在“反复调用”。完整正文版
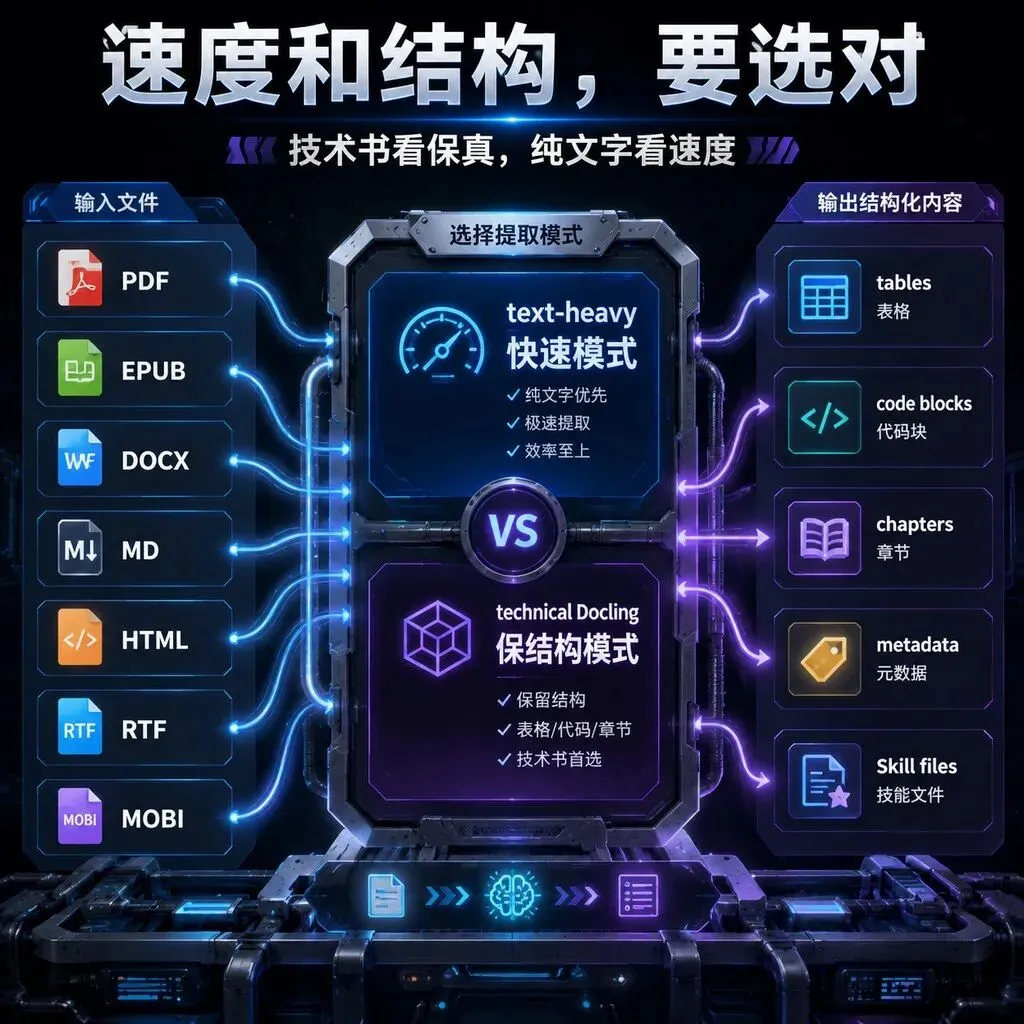
很多技术书,最后都死在一个地方:你读过,但用不上。不是你不努力。是书这种载体,本来就不适合被 AI Agent 在工作中反复调用。你买了一本好书,认真读完,划了重点,甚至还写了笔记。三个月后,你只记得“这本书很重要”,但忘了第 7 章到底讲了什么。真正要写代码、做架构、查一个概念时,你又回到老路:打开 PDF,搜关键词,翻目录,复制一段给 AI,再让它解释。book-to-skill 这个项目有意思的地方,就在这里。它没有把自己包装成“更聪明的读书助手”。它做的是更工程化的一步:把一本书、一个文档目录,或者一组资料,编译成一个 Claude Code Skill。项目目前在 GitHub 上约 5.2k Star,主语言是 Python,MIT 许可证,默认分支 master。仓库里有 README、SKILL.md、docs、scripts、tools、tests 等目录,核心提取逻辑在 scripts/extractor 下面,按 PDF、EPUB、DOCX、HTML、RTF、Calibre、text 等格式拆了不同 parser。它有真实的提取脚本,有依赖检查,有测试,有 discovery tax 计算工具,还有生成 Skill 的完整规范。运行 `/book-to-skill your-book.pdf`,或者传一个文件夹、glob、一组文件,它会创建一个完整 skill。README 里给出的默认结构大概是这样:SKILL.md 放核心模型和章节索引,控制在约 4000 tokens;chapters/ch01-*.md 这类文件按章节拆开,每章约 1000 tokens,只有问到相关主题时才加载;glossary.md 放术语表;patterns.md 放技巧、算法、设计模式;cheatsheet.md 放决策表和速查规则。普通 PDF 问答,是“临时搜索”。你问一个问题,Agent 先找目录,再找章节,再找相关段落,再压缩,再回答。下一个回合,很多内容还会留在上下文里继续消耗 token。先把书里的框架、概念、反模式、术语、决策表整理好。运行时只加载核心 SKILL.md,加上你这次问题相关的一两个章节。大部分书内容留在磁盘上,不进入上下文。RAG 更像“帮我找接近这个问题的片段”。book-to-skill 更像“提前把作者的知识结构拆成一套工具箱”。它关心的不是某段话在哪里,而是这本书到底教了哪些框架、原则、技巧、反模式,什么时候该用。book-to-skill 把自己的优势叫 Discovery Loop Tax,发现循环税。一个 PDF-reading Agent 回答一个问题,通常不只是读。它要导航目录、确认术语、回头找上下文、抽取相关页,再压缩给主 Agent。这个过程本身就会吃上下文,而且后续对话还会继续带着这些内容走。项目用三个真实书籍做了测算。book-to-skill 的运行时大概加载 resident core 约 4000 tokens,加一个编译后的章节约 1000 tokens,总计约 5000 tokens。对比上下文全量塞书,Think Python 2 是 119K tokens,Working Backwards 是 175K tokens,AI Engineering 是 256K tokens。book-to-skill 相比直接 dump 上下文,大约是 24×、35×、51× 的差距。对比一次性的发现循环,也有 2.4× 到 15.6× 的差距,差异取决于章节大小。它不是说每次都能神奇省 50 倍,也不是说 RAG 没用了。它说的是:如果一本书你会反复用,把导航和结构化成本前置,比每次重新找书更划算。book-to-skill 支持 PDF、EPUB、DOCX、TXT、Markdown、reStructuredText、AsciiDoc、HTML、RTF、MOBI/AZW/AZW3。普通文本、Markdown、reStructuredText 和 AsciiDoc 不需要额外依赖。PDF 这块,它区分 text-heavy 和 technical 两类。如果是纯文字类书,可以用 pdftotext、PyPDF2、pdfminer.six 这类工具,速度很快。README 里写,pdftotext 在一个 103 页技术 PDF 上只要 0.1 秒,但表格和代码块保留不了。如果是技术书,有代码、表格、公式,它建议用 Docling。代价是慢一些,大概 1.5 秒一页;好处是能把表格和代码块保成 Markdown。项目给出的同一份 103 页技术 PDF 测试里,Docling 用了 164 秒,保留了 48 个表格和 36 个代码块。它没说所有材料都用同一种方式处理,而是让你在“速度”和“结构保真”之间选。对技术书来说,这个选择非常重要。代码块、参数表、决策表一旦被打平,后面生成的 Skill 就会像读书摘要。保住结构,Skill 才更像工具。比如你长期用《Designing Data-Intensive Applications》《Clean Architecture》《Pro Git》这类书。不是为了读完打卡,而是写系统、做架构、查概念时经常要回去看。把它转成 Skill 后,你可以问某个主题,Agent 去读对应章节,不需要把整本书丢进对话。架构决策记录、Runbook、Onboarding 文档、接口规范、合规说明,很多公司都有。但这些文档平时没人读,出事时才翻。把它们折成 Skill,团队 Agent 就能在写代码、排查问题、做变更时调用它们。论文、报告、笔记、标准文档可以合并进一个统一 skill。对于做 AI、量化、工程研究的人,这个方向很有价值。很多知识不是不知道,而是散在十几个 PDF 和 Markdown 里,工作时想不起来。如果一个团队有自己的 tone of voice、设计原则、内容风格、客服话术,把它们做成 Skill,Agent 输出时就不只是“参考一下文档”,而是真正按规范工作。过去我们喜欢把资料塞进上下文,觉得窗口越大越好。大窗口当然有用,尤其适合一次性通读。但如果知识会被反复调用,单靠大窗口不是最优解。更好的方式,是把知识做成可加载、可索引、可验证、可更新的能力。它把“知识管理”往 Agent Skills 推了一步。第一,它生成的是 skill,不是原书替代品。版权上,项目 README 也写得很清楚:仓库不包含任何书籍内容,只是转换器;你处理什么材料,要遵守对应书籍或文档的许可证和使用条款。第二,章节识别依赖书的结构。README 提到,它需要类似 Chapter N / Capítulo N 这样的显式标题来自动分章。像 Pro Git 这种使用章节标题而不是 Chapter N 的书,就不能自动分章得那么顺。第三,技术书提取质量取决于工具。你用 pdftotext 很快,但表格和代码块可能丢;用 Docling 保真更好,但慢。别把它当成一键魔法。第四,它主要面向 Claude Code Skill。虽然 README 和 SKILL.md 里也提到 Amp、Copilot 等技能目录适配思路,但最顺的使用场景,还是 Claude Code 这一类支持 Skill 的编码 Agent。如果你有一批反复要用的技术书、团队文档、研究资料,它很可能是 Agent 时代知识库的一个新形态。Agent 时代,核心动作会变成编译、索引、按需加载。这就是 book-to-skill 最值得看的地方。它解决的是:当我真的要工作时,这本书能不能来帮我。收藏版清单
- 先读 README,理解 book-to-skill 不是普通读书笔记,而是 Skill 生成器。
- 看 docs/PERFORMANCE.md,重点看 Discovery Loop Tax 和不同提取方式的对比。
- 看 docs/ARCHITECTURE.md,理解它的两段式架构:Python extractor 加 agent generator。
- 跑了 `python3 scripts/extract.py --check`,确认本机支持哪些格式。
- 先拿一本你确定会反复查的技术书试,不要一开始就扔 80 本进去。
- 技术书优先考虑 Docling,纯文字书优先考虑快速文本提取。
- 生成后重点检查 SKILL.md、chapters、glossary、patterns、cheatsheet,不要只看有没有文件。
- 内部文档或付费书籍要注意版权和使用范围,别把不该公开的内容做成公开 skill。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-07-01 04:51:53 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/819745.html
- 运行时间 : 0.088311s [ 吞吐率:11.32req/s ] 内存消耗:4,642.91kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=6f6237811b81533940ca4b8e7679323f
- CONNECT:[ UseTime:0.000649s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000959s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000332s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000277s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.000564s ]
- SELECT * FROM `set` [ RunTime:0.000221s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.000554s ]
- SELECT * FROM `article` WHERE `id` = 819745 LIMIT 1 [ RunTime:0.000426s ]
- UPDATE `article` SET `lasttime` = 1782852713 WHERE `id` = 819745 [ RunTime:0.002020s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000268s ]
- SELECT * FROM `article` WHERE `id` < 819745 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000369s ]
- SELECT * FROM `article` WHERE `id` > 819745 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.000350s ]
- SELECT * FROM `article` WHERE `id` < 819745 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.000751s ]
- SELECT * FROM `article` WHERE `id` < 819745 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.000835s ]
- SELECT * FROM `article` WHERE `id` < 819745 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.001828s ]

0.090148s

 夜雨聆风
夜雨聆风