 夜雨聆风
夜雨聆风大家好,我是小扬。今天分享一篇关于 Skill 和上下文学习 的新论文:Ctx2Skill。
很多真实任务不是考模型“以前背过什么”,而是要求它临场读懂一份新材料:产品手册、实验报告、代码仓库、论文、规则文档,然后按里面的新知识解决问题。论文把这类能力称为 context learning。
直觉上,一个好办法是把长上下文里的规则和流程提炼成自然语言 skills,推理时直接塞给模型。但问题来了:长文档手写 skill 成本太高;如果让模型自动写 skill,又没有外部反馈告诉它写得对不对、有没有用。
Ctx2Skill 的核心想法是:让模型自己给自己出题、自己解题、自己从失败里改技能。
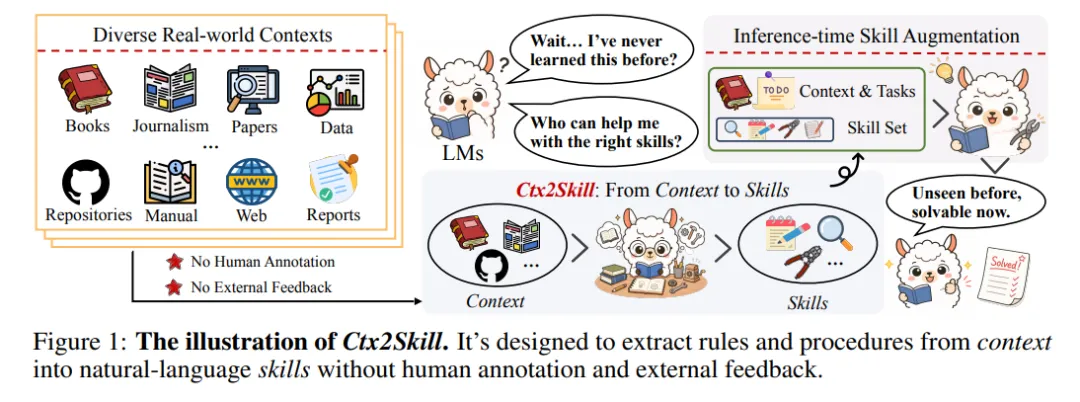
Ctx2Skill到底怎么做
多智能体 self-play
Ctx2Skill 用一个多智能体自博弈循环来构造 skill set。里面有五类角色。
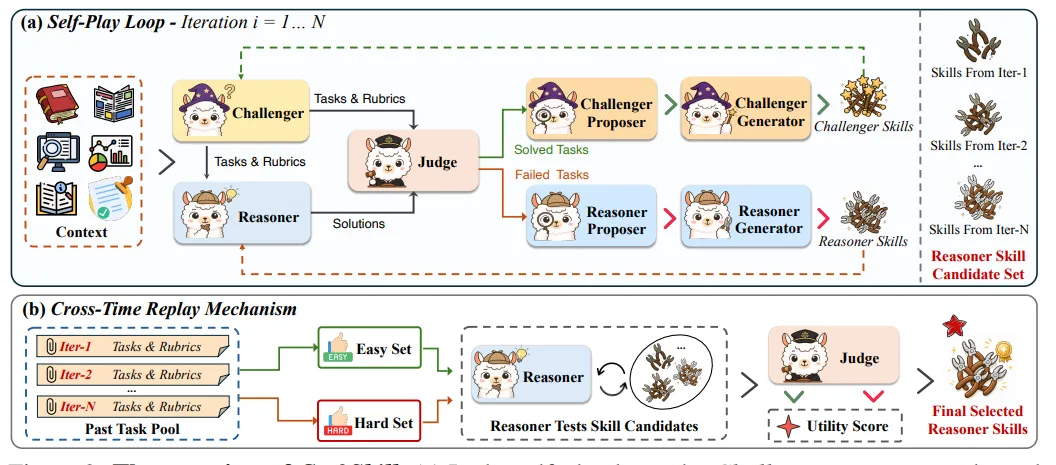
第一是 Challenger。它读上下文,根据当前 Challenger skills 生成一批 probing tasks 和 rubrics。这里的题目不是简单复述原文,而是故意测试模型是否真的归纳出了上下文里的规则。
第二是 Reasoner。它拿着原始上下文、任务,以及当前 Reasoner skills 去解题。Reasoner skills 就像一份从上下文里提炼出的“做题攻略”。
第三是 Judge。它根据 Challenger 给出的 rubrics 对答案做二元判断:每条 rubric 都过了,任务才算 solved;只要有一条不过,就算 failed。
第四和第五是两组 Proposer / Generator。Judge 只告诉系统成败,不解释原因,所以 Proposer 负责诊断:失败任务到底暴露了 Reasoner 缺什么知识?成功任务说明 Challenger 哪些地方还不够刁钻?然后 Generator 把这些诊断改写成新的自然语言 skills。
关键设计是:失败任务流向 Reasoner 侧,用来补齐解题技能;成功任务流向 Challenger 侧,用来让出题者下轮更会考。这样一来,Reasoner 越学越会解,Challenger 越练越会出题,双方一起进化。
为什么还需要 Cross-Time Replay
自博弈有一个风险:Challenger 可能越出越偏、越出越极端;Reasoner 也可能为了通过这些怪题,积累一堆过拟合 skill。最后看起来训练很热闹,泛化反而变差。
所以论文提出 Cross-Time Replay。做法是把不同迭代产生的 Reasoner skill sets 都保留下来,再放到历史任务池上重测。任务池会被分成 easy set 和 hard set,用来衡量某个 skill set 是否既能解决简单代表性问题,也能扛住难题。
最终系统不是盲目选择最后一轮 skill,而是选择跨时间表现最均衡、泛化最好的那一版。这一点很重要,因为论文里的统计也显示,早期迭代的技能经常反而更稳。
实验结果
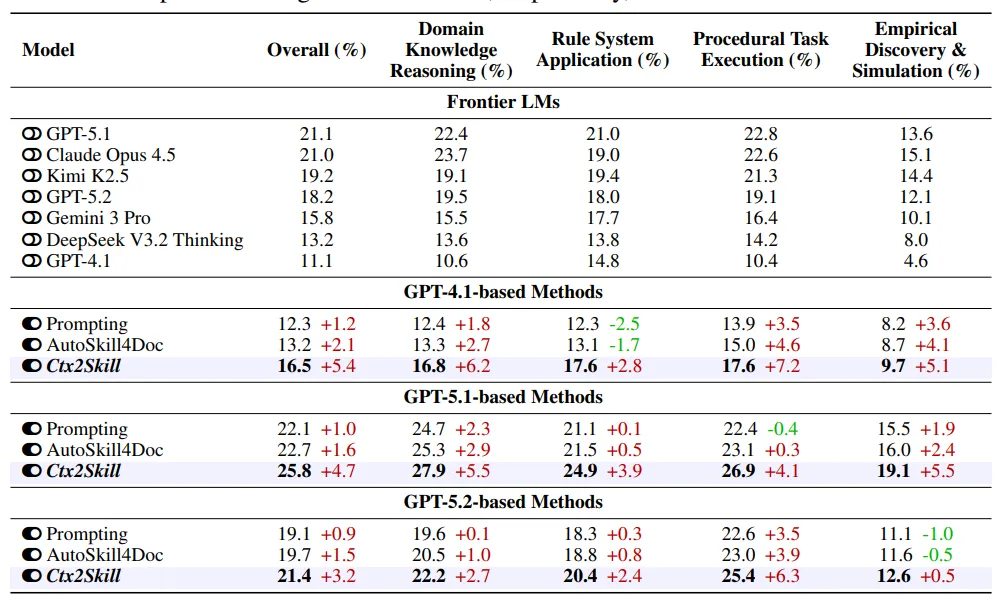
论文在 CL-bench 的四类上下文学习任务上测试:Domain Knowledge Reasoning、Rule System Application、Procedural Task Execution、Empirical Discovery & Simulation。
结果很直接:Ctx2Skill 在多个 backbone 上都提升明显。GPT-4.1 从 11.1% 提到 16.5% ,GPT-5.1 从 21.1% 提到 25.8% ,GPT-5.2 从 18.2% 提到 21.4% 。相比单次 Prompting 和 AutoSkill4Doc,Ctx2Skill 的提升更稳定。
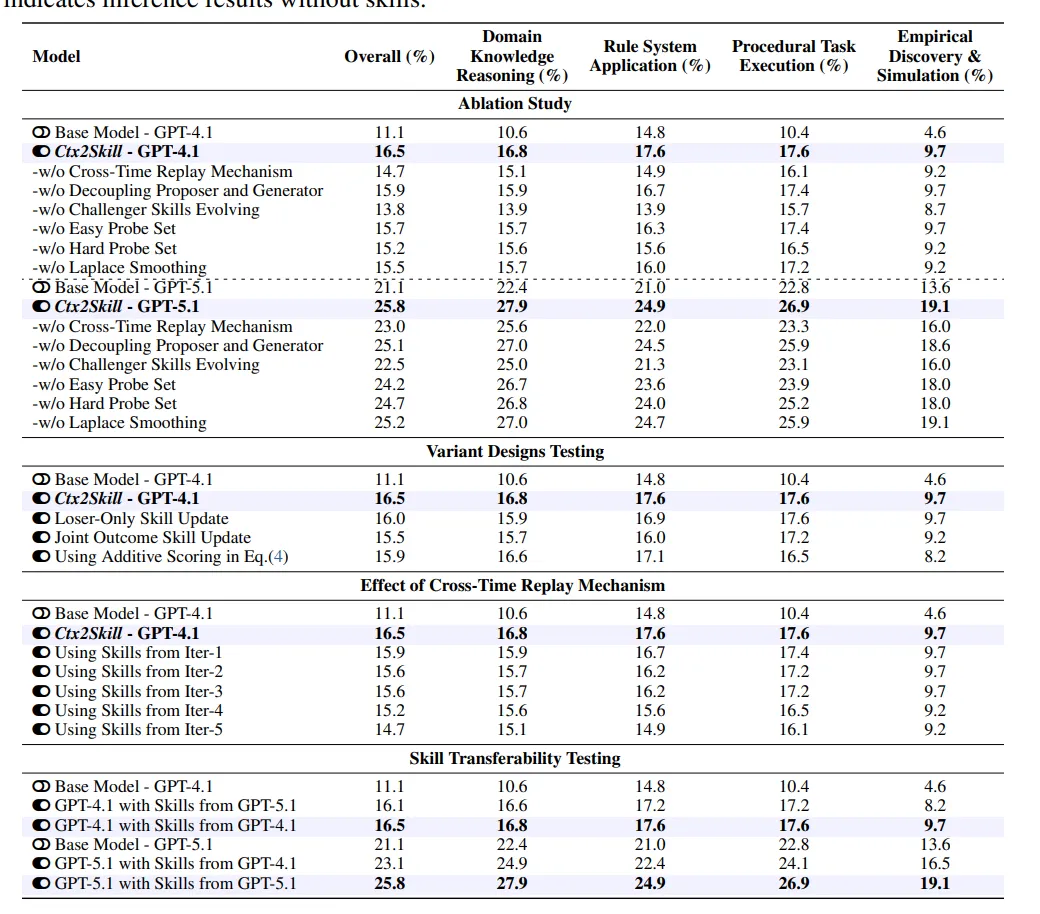
消融实验也说明几个组件确实有用。去掉 Cross-Time Replay 后,GPT-4.1 版本从 16.5% 掉到 14.7% ,GPT-5.1 版本从 25.8% 掉到 23.0% 。去掉 Challenger skills evolving,性能下降更明显,说明“会出题的一方”不是装饰,而是推动 Reasoner 学到更好 skill 的关键。
小扬总结
这篇论文最值得看,不是因为它又发明了一个 prompt 模板,而是因为它把 skill 构造 从“人工总结”推进到了“自博弈进化”。
以前我们给模型加 skill,往往像老师给学生写复习提纲;Ctx2Skill 更像让一个出题老师和一个学生互相陪练:学生做错了就补课,老师发现学生会了就升级题目,最后再从历次笔记里挑一份最稳的攻略。
这对实际工作流很有价值。面对企业手册、复杂规则、代码仓库、实验说明这类长上下文,模型不只是“读一遍再回答”,而是可以先把里面的规则提炼成可复用 skill,再用这些 skill 去处理一批任务。
当然,自博弈需要多轮调用多个 agent,成本比单次 prompt 高;而且 Judge 和 rubrics 的质量会影响整个循环。但方向很清楚:未来的上下文学习,可能不只是塞更多 token,而是先把上下文炼成技能。
论文标题: From Context to Skills: Can Language Models Learn from Context Skillfully?论文链接: https://arxiv.org/pdf/2604.27660GitHub: https://github.com/S1s-Z/Ctx2Skill