 夜雨聆风
夜雨聆风每天打开 Cursor 或 Claude Code,第一件事是什么?
重新解释一遍项目。
package.json 在哪、这个函数上礼拜刚从同步改成异步、那个支付回调的逻辑别动它有坑、用户偏好返回结构用 JSON 不要用 YAML——这些你上周说过、上上周也说过的话,新会话一开,全部清零。AI 看你的眼神,像个第一次见你的实习生。
所以"给 AI 编程助手装个记忆"这件事,2026 年彻底炸了。GitHub 上几个主流的 MCP 合集仓库 (像 punkpeye/awesome-mcp-servers,9 万多颗星) 里,记忆与知识类 server 已经单独成了一大分类;MCP 协议发布一年多,生态里的 server 数量从最初的几十个涨到了近万个,被叫作"AI 领域的 USB-C"。
重点是另一句:
你以为在横评三款记忆工具,其实它们根本不是一类东西。
Supermemory、PMB、zen-mcp-server,名字都被塞进"AI 记忆工具"这个榜单里,但一个管"AI 跨会话记住你",一个管"AI 理解项目脉络",一个干脆不记东西、只做多模型协作。把它们放一起比基准分,就像拿冰箱、微波炉、电视机比谁的制冷强。
先把这层窗户纸捅破,再讲怎么选。
一、先分清:你要治的,到底是哪种"病"
很多人上来就问"哪个记忆工具最好"。先别急着问。你的 AI 到底得了什么病,得先搞清楚。
大概分三种。
第一种,失忆。 会话一关,啥都不记得。下次开,得从头认识你和你的项目。这是最普遍的痛点。
第二种,找不到东西。 项目文档、代码库、设计稿堆成山,AI 每次都得你手动喂,或者它瞎翻。这是检索问题。
第三种,单打独斗。 Claude 写代码很强,但有时候你想要 Gemini 看一眼图、想让 O3 做个硬核推理、想让 Grok 挑个刺。一个模型干不完所有事。
这三种病,对应三种完全不同的工具。大多数人把它们搅在一起,所以越选越晕。
这里有个特别关键、也特别容易被忽略的区分,来自 Supermemory 创始人 Dhravya Shah 死咬住的一句话:
记忆不是 RAG。
RAG 检索的是文档。你问"React 怎么写 effect",我问也是同一段官方文档,它对所有用户都一样,是死的、静态的、只增不减的。
记忆检索的是事实,而且是会变的事实。"我上个月住纽约,这个月搬到了旧金山",新的会覆盖旧的;"我明天有考试",后天就该被忘掉。
这个差别,一句话就能讲准:
RAG 让 AI 知道世界,记忆让 AI 假装自己活过。
一个解决"信息缺失",一个解决"主体断裂"。搞清楚你要的是哪个,比记住任何参数都重要。
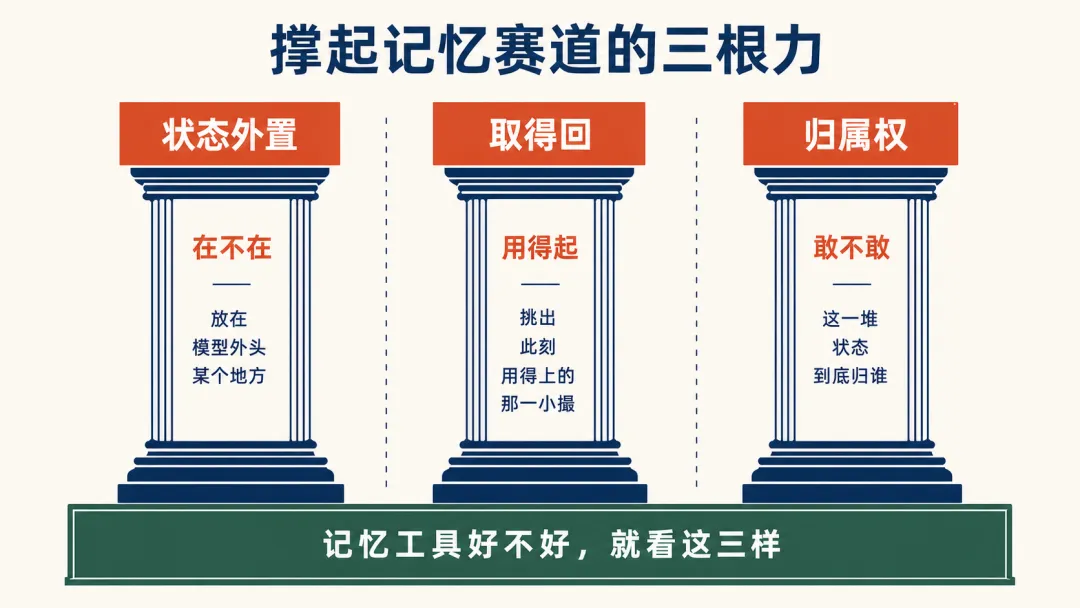
二、选之前,先看懂撑起这个赛道的三根力
只看功能清单,会越看越乱:云的、本地的、通用的、专精项目的、单模型的、多模型的,十几个名字四根轴拉来拉去。
我不打算给你列清单,换个角度问:这个赛道,背后到底靠什么撑着?
钻到底,就三根力。一根都不能少,彼此还不能替代。
第一根:状态得外置 (在不在)
大模型本身没有记忆。这不是 bug,是它本来就这样,上下文窗口一关,上一秒聊过的全忘,连改都改不了。
记忆只能搬出去,放在模型外头某个地方。云端把它放在别人的机器上,PMB 把它放在你硬盘上的一个 .db 文件,codebase-memory 把它编进一张知识图谱,MCP server 就是这些"外面"和模型之间那根线。
这根是门票的门票。没有"外置",云和本地不分家,SQLite 文件不存在,知识图谱不存在,MCP 协议连存在的理由都没有。
第二根:留下来的得取得回 (用得起)
放出去不算完,得取回来,还得用得起。
token 不是白给的。模型窗口就那么大,把记忆全塞回去,一来塞不下,二来塞满了真活儿没法干。Supermemory 的自动遗忘、codebase-memory 官方说能省 99% 的 token、PMB 的 recall 只取相关的几条,全是在干同一件事:从一大堆放出去的状态里,挑出此刻用得上的那一小撮,扔给模型。
第一根回答"放哪",这根回答"怎么用得起"。你可以放得很好,可取不回来,那这堆记忆就是一座进不去的仓库。
第三根:这堆记忆归谁 (敢不敢)
外置解决了放哪,取得回解决了用得起,还剩一根谁都绕不过:这一堆状态,到底归谁,放哪台机器,谁碰得谁碰不得。
云和本地的分家、Apache 2.0 一分不收和每月 19 美元的分家、安全研究里披露的 MCP 工具投毒和权限滥用这类隐患、企业能不能用个人敢不敢交,全是这根在驱动。PMB 把整本记忆装进一个 SQLite 文件,你删了它就没了,谁也拿不走;Supermemory 把它放在云上,换来了更强的能力,可那堆东西在别人机器上跑。
表面看是技术分歧,底下其实是信任落在哪的分歧。
三根立住,浓缩成一句话:
记忆工具好不好,不看星多不多、基准分高不高,就看三样——东西放没放出去 (在不在)、放出去的取不取回 (用得起)、取回的你敢不敢交 (敢不敢)。
后面三款工具,全部用这三根力去拆,一拆就明白。
三、三款工具,逐一拆给你看
1. Supermemory:云端全能王者
一句话:创始人 Dhravya Shah 做的 AI 记忆引擎,GitHub 27.9k 星,这个赛道目前商业化最成熟的一个。
核心参数:
学术榜单 LongMemEval 81.6%,全场第一,另外 LoCoMo、ConvoMem 也是第一。三款里唯一登顶公开学术基准的。换句话说,它最不容易记错事,也最会处理"你上个月说 A、这个月改口 B"这类前后矛盾的事实。
3 个 MCP 工具:
memory(存/遗忘,AI 自动调用)、recall(搜记忆 + 返回用户画像)、context(对话开始注入完整画像,在 Cursor/Claude Code 里输/context触发)。
它能干什么:事实抽取 + 追踪更新 + 自动消解矛盾 + 自动遗忘 + 用户画像。还有一堆 Connectors,能实时同步 Google Drive、Gmail、Notion、GitHub。说白了,它不光记,还会自己判断哪条该留、哪条过期了、哪两条打架了。
定价:Free $0(约 $5 额度)、Pro $19/月 (3M token + 10 万次查询)、Scale $399/月 (无限存储 + 10 队友 + 全部连接器 + SOC2/HIPAA)、Enterprise 定制。Context Extender 每对话送 2 万 token 免费,超出 $1/百万 token。
怎么装:想用云的直接注册;想自托管,一行命令:
curl-fsSL https://supermemory.ai/install | bash
# 或
npx supermemory local
单二进制零配置,可以指向 Ollama(gpt-oss:20b) 完全离线,数据存在 ./.supermemory。支持 Claude Desktop/Code、Cursor、Windsurf、VS Code、OpenCode 等主流客户端。
主要缺点:
云优先的产品基因。能自托管,但自托管版的能力和托管版有差距 (那 81.6% 的分不会自己掉下来给你用)。
企业档贵。个人玩玩 Pro 够,真要团队上,Scale 一年小 5 万人民币。
用三根力拆:外置到云,取回用学术榜撑,归属让渡给服务商。能力强,代价是信任得交出去一部分。
2. PMB:把项目记忆装进一个 SQLite 文件
一句话:开发者 oleksiijko 做的本地项目记忆库,Apache 2.0 完全开源免费,把"记忆"重新定义成了"项目叙事"。
核心参数:
prepare(message)调用 4–16 毫秒返回,recall(query)混合搜索 35 毫秒(warm 状态)。快到几乎感觉不到。一共提供
prepare、recall,外加 27 个 CLI 工具,覆盖项目记忆的各种粒度。
它能干什么:这是 PMB 最有意思的地方。它不只是一堆事实,而是用 lessons(规则)、decisions(决策)、open_goals(进行中的目标)、narrative_arcs(叙事弧)、entities(实体) 五种东西,让 AI 真正"理解"你的项目脉络,而不是只存几条孤立事实。
官方有个 Demo 特别直观:
你说"修复上周二遇到的那个 LoadGuard 定价 bug"。没有 PMB,AI 会反问:"哪个文件?bug 是什么?"有 PMB,
prepare()6 毫秒返回,直接定位到src/engine/verdict-policy.ts:142(bundle fallback 收紧到 rate-floor 以下),按之前存的 lesson 恢复 25% 阈值,不用反问。
怎么装:
pip install pmb-ai
# 或
npx pmb-ai setup
纯本地,无云、无 API key、无遥测、无网络调用。数据就是一个 SQLite 文件,你的硬盘你做主。
主要缺点:
比较新的项目,星标数远低于 Supermemory(README 用 badge 没显示具体数字),社区和踩坑资料还在积累。
没有公开学术基准,能力上限受你自己算力和工程量限制,你要自己搭、自己维护。
用三根力拆:外置到本地 SQLite + 取回靠 lessons/recall + 归属完全归你。控制权拉满,代价是能力天花板得自己扛。
3. zen-mcp-server:诚实说,它不是记忆工具
一句话:BeehiveInnovations 出品,GitHub 11.6k 星、924 forks,本质是一个多模型编排层,让 Claude Code 同时跟 Gemini 2.5 Pro、OpenAI O3、Grok、Ollama 协作。它不是记忆工具,我把它放进来,当个对照组,顺便说清楚一个常见的误会。
核心参数:13+ 个 MCP 工具,chat、thinkdeep、challenge、planner、consensus、codereview、precommit、debug、secaudit 等等。
它真正在解决什么:
challenge,专门防止 AI 那种"You're absolutely right!"式无脑附和,让它真的去挑刺。consensus,让多个模型对同一个问题做共识分析。它所谓的"上下文保持",指的是跨模型协作时维持对话连续性,不是长期事实记忆。
怎么装:用 uvx,需要自带至少一个 API key(Gemini/OpenAI/X.AI 等)。
uvx --fromgit+https://github.com/BeehiveInnovations/zen-mcp-server.git zen-mcp-server主要缺点(必须说清楚):
它不存记忆。别拿 LongMemEval 这种记忆基准去比它,那是关公战秦琼。它的"上下文"是对话线程,会话结束就没了。
要用得顺手,得准备好几个模型的 API key,有成本也有门槛。
用三根力拆:它三根里一根都不沾,不外置、不取回、不争归属。所以它压根不该被算进记忆工具榜。把它列进来,正好反证这三根力的硬度。
如果你真正的痛点是"Claude 单模型不够用、想要多模型协作 + 防附和",选它没毛病。如果你要的是"AI 记住我",它帮不上。
四、避坑指南 (这些坑我替你踩过了)
推荐完了,再说说哪些不推荐、哪些要小心,免得你走弯路。
坑一:别把 zen-mcp-server 当记忆工具硬比。 这是最常见的错误。很多榜单把它和 Supermemory 摆一起比基准分,纯属外行。懂行的读者一眼就能看出来,你写了反而掉价。它解决的是协作,不是失忆。
坑二:PMB 和 claude-memory-mcp 是两个东西,别搞混。 GitHub 上有个 WhenMoon-afk 做的 claude-memory-mcp,经常被误当成 PMB。它也是本地优先 (SQLite 存 5 种 artifact:snapshot/decision/project_state/bundle/meta_snapshot),定位"刻意无趣的基础设施",但它的模型不如 PMB 的 narrative_arcs 丰富。两个项目,别张冠李戴。
坑三:三款之间没有直接头对头基准。 这是必须坦诚的数据缺口。Supermemory 有自己的 MemoryBench(对比 Mem0、Zep),但既没包含 PMB,也没包含 zen-mcp-server。市面上没有任何第三方,用统一指标对这三款做过 token 消耗、响应延迟、记忆准确率的横评。所以任何"谁碾压谁"的结论,都得打个问号。
坑四:Supermemory 自托管 ≠ 托管版。 你看到 81.6% 那个分,是人家云端引擎跑出来的。你自己 npx supermemory local 起一个,接 Ollama 的开源模型,效果是要打折的。别指望本地白嫖到顶配。
坑五:PMB、zen 的中文一手实测几乎空白。 国内社区对 Supermemory 还有点 B 站实测,另外两个基本没人正经测过,多是搬运介绍页。真要用,做好自己当小白鼠的准备。
五、横向对比矩阵
把三款放一张表里,看着清楚。左右滑动查看。
| 维度 | Supermemory | PMB | zen-mcp-server |
|---|---|---|---|
| 本质 | 云端记忆引擎 (可自托管) | 本地项目记忆库 | 多模型编排层 |
| 解决的问题 | AI 跨会话记住你 | AI 理解项目脉络 | 多模型协作 + 防附和 |
| 存储 | 云 (默认)/ 本地 (自托管) | 单个本地 SQLite 文件 | 不持久化记忆 |
| 是否开源 | MCP server 开源,引擎部分闭源 | 完全开源 (Apache 2.0) | 完全开源 (Apache 2.0) |
| 隐私 | 云优先 (可全离线 Ollama) | 纯本地,无遥测 | 本地进程,外部 API 有日志 |
| 定价 | $0 / $19 / $399 / 定制 | 免费 | 免费 (付 API key 费) |
| 学术基准 | LongMemEval 81.6% #1 | 无 | 无 (非记忆工具) |
| 响应速度 | 云端调用 | prepare 4–16ms | 取决于调用模型 |
| GitHub Stars | 27.9k | 较新,星少 | 11.6k |
| 记忆模型 | 事实抽取 + 遗忘 + 消解 + 画像 | lessons/decisions/叙事弧 | 不记忆 |
| 适合谁 | 团队/企业/跨工具通用记忆 | 个人/隐私敏感/单项目深度 | 多模型协作需求 |
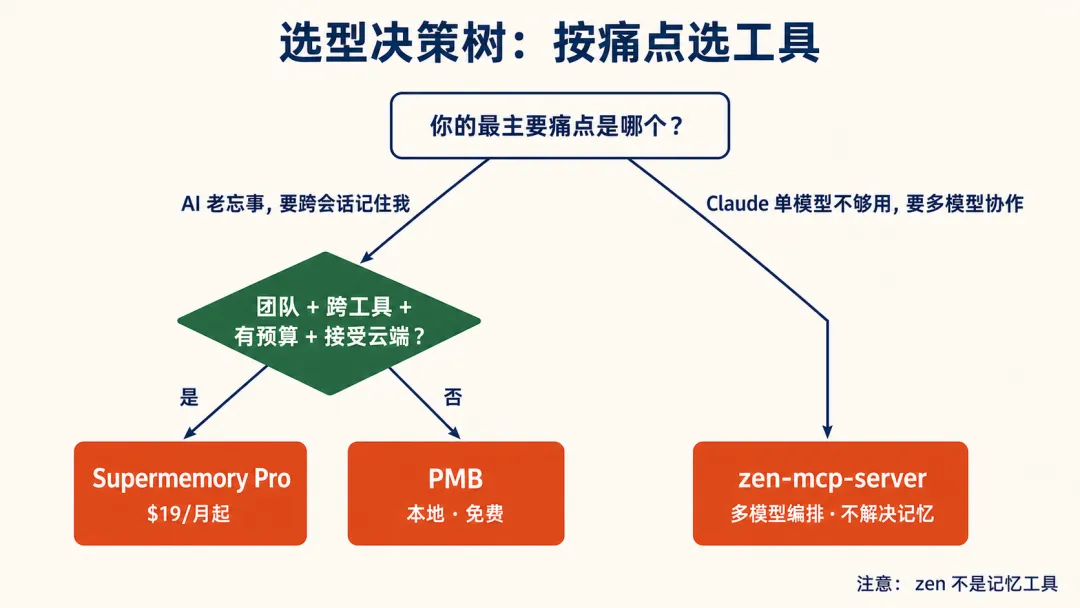
六、选型决策树
看完表格还是晕?给你一个最简单的决策路径。
先问自己一个问题:你最主要痛点是哪个?
"我的 AI 老忘事,我要它跨会话记住我和项目" → 这是真·记忆需求。再往下分:
你是团队、要跨多个工具 (Cursor、Claude、Notion) 通用记忆、有预算、能接受云端 → Supermemory Pro 起步。
你是个人开发者、对数据主权敏感、主要在单个项目里深挖、不想花一分钱 → PMB。
"我不缺记忆,我缺的是 Claude 一个人干不过来,想要多模型协作、有人挑刺" → zen-mcp-server,但它不解决记忆问题,别指望。
这里还有个更狠的判断,来自前面那台"控制力 × 能力上限"的小仪器。
把所有记忆工具放进一个二维坐标:X 轴是控制力 (全攥自己手里 → 全交出去),Y 轴是能力上限 (只记得一点 → 顶配)。
右上角 (能力顶 + 控制全交):Supermemory 托管版。学术第一,自动遗忘消解都最精,但东西在别人机器上,MCP 工具投毒这类安全风险大半落这格。
左上角 (能力顶 + 控制全攥):PMB、自托管的 codebase-memory。开源免费断网能跑,但能力上限被你自己算力卡住。
左下、右下两格:要么攥得紧但记得少 (claude-memory-mcp),要么交一半换回的能力也一般 (Mem0/Zep 这类)。
2026 年的战火,集中在右上和左上那条对角线上,Supermemory 把能力做到顶,PMB 把控制权攥到死,各自把一格做到极致。中间那两格空着。
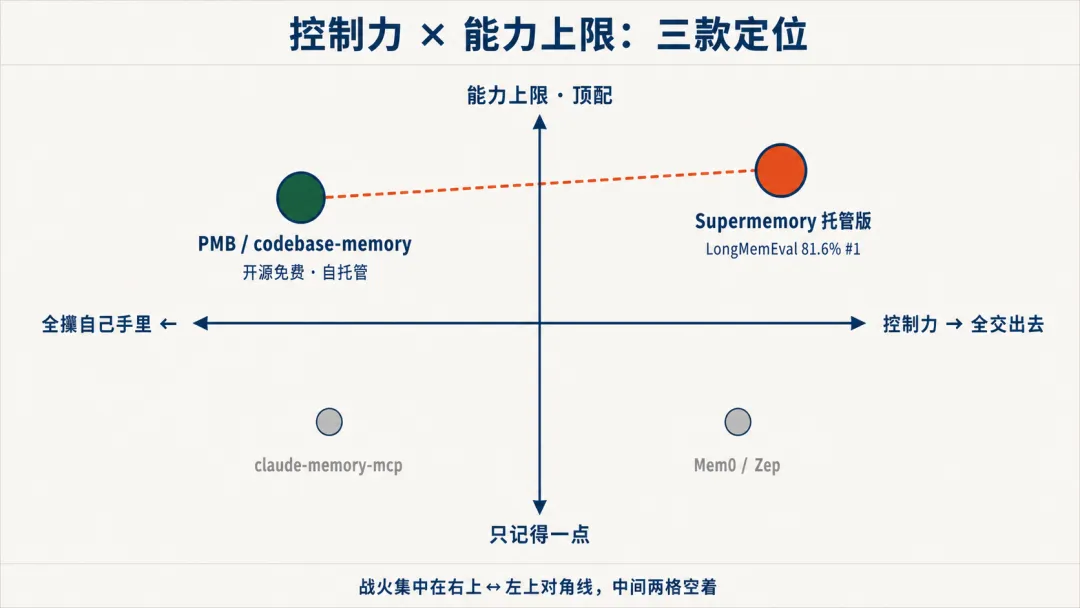
这台仪器告诉你一句狠话:控制力和能力上限,现在还拉不到一头。 你要控制,就得以能力为代价;你要顶配能力,就得把控制权交出去。这不是哪个工具做得不够好,是这条赛道在"归属权"这根力上,谁也没松口。
所以选型这件事,你选的不是"最好的",而是"你愿意交出哪一样"。
七、收尾:先用免费的,验证你的需求是不是真刚需
说几句实在的。
记忆工具这个赛道,现在还非常早期。一边是 MCP 协议发布一年多生态 server 涨到近万个、Anthropic 把协议治理权交给了新成立的 Agentic AI Foundation、Google 微软 AWS 全跟进,热闹得很;另一边是"MCP 凉了"的争议此起彼伏、安全研究里陆续披露 MCP 工具投毒和权限滥用这类隐患、各家基准各说各话。繁荣和泡沫,现在摞在一起。
往深了说一句。前面那个"记忆不是 RAG"的区分,再往下钻,其实有个更冷的真相:所有这些工具做的,严格说都只是 recall(回忆),不是 continuity(连续)。真正的连续性,是那个还活在内存里、还在流淌的上下文窗口本身;一旦它断了,你从笔记里重建出来的,只是一个模仿者,不是本人。
记忆这件事,本质是给一个没有时间的东西,假装它有时间;给一个每次都从零开始的函数,假装它是同一个人的一生。
这套哲学,该放就放,别让它挡住你干活。
所以我的建议很务实:别一上来就冲 Supermemory 的企业档。先用 PMB(本地、免费、6 毫秒) 或者 zen-mcp-server(免费、防附和),花一个礼拜,验证一下"AI 失忆"到底是不是你真天天踩的坑。是,再考虑要不要为更强的能力,把信任交出去。
东西放没放出去、放出去的取不取回、取回的你敢不敢交,这三件事想清楚了,选哪个,你自己就有答案。
有你在用的记忆工具我没提到,或者踩过别的坑,评论区聊聊。
