 夜雨聆风
夜雨聆风你硬盘里应该也有几本这样的书——认真读过,甚至做过笔记。但真到项目里需要查一个具体知识点,翻半天也翻不到。书就在那里,知识就在里面,但关键时刻调不出来。
直接把书扔给 AI 对话也不是没试过。一本 400 页的 PDF 将近 20 万字,每次对话都得整个塞进去,塞得越多 AI 找得越不准。
开源项目 book-to-skill解决了这个问题。它会先将整本书「编译」一遍,提炼出核心框架、章节摘要、术语和方法模式,生成一个 Skill。编译完之后,可以通过 Skill 名调用它,问什么 AI 就按需加载对应章节来回答你。
编译完之后长什么样
运行完一本书,skills 的目录里会多出这些东西:
your-book-skill/├── SKILL.md # 全书心智模型 + 章节索引,约 4000 tokens├── chapters/ # 每章单独一个文件,各 800-1200 tokens├── glossary.md # 术语表,每个术语标了章节出处├── patterns.md # 设计模式 / 反模式清单└── cheatsheet.md # 决策规则速查精妙之处在于 chapters/目录。问哪章才加载哪章,不问就不占 token。 整本书只在第一次编译时处理一遍,之后每次查询大约只加载 5K 的核心章节——而不是每次对话都整个塞进去。
安装和使用
安装 book-to-skill
把下面内容发给 AI Agent,让它安装这个 Skill:
安装这个skill https://github.com/virgiliojr94/book-to-skill.git编译一本书
使用 book-to-skill 编译一本书
# /book-to-skill [需要转换的内容] [生成内容对应的 skill 名称]/book-to-skill ./attention-is-all-you-need.pdf attention-skill支持转换的格式:PDF、EPUB、DOCX、TXT、Markdown、reStructuredText、AsciiDoc、HTML、RTF、MOBI/AZW/AZW3。
除了单个文件,还支持以下用法:
/book-to-skill ~/papers/paper1.pdf ~/notes/export.txt unified-research # 多文件合成一个 Skill/book-to-skill ~/workspace/project-docs/ project-knowledge # 整个文件夹一起编译/book-to-skill "~/books/*.epub" my-library # 按 glob 模式批量匹配运行后它会根据内容类型走不同的提取管道——技术型(含代码、表格)走 Docling,慢一些但能保住结构和代码块;文字型走 pdftotext,几乎秒出。
调用生成的 Skill
编译完成后,产物(如 attention-skill)会生成在 Agent 的 skills 目录下。通过 Skill 名直接调用:
/attention-skill # 加载核心框架/attention-skill replication # 问某个主题/attention-skill ch05 # 深入第五章/attention-skill "what chapters do you have?"AI 会自动加载对应章节,基于书里的内容回答你,而不是凭训练数据瞎编。
增量更新
有了新版 PDF、读了新论文,可以直接合并到已有 Skill(如 attention-skill):
/book-to-skill ~/articles/new-paper.pdf ~/.workbuddy/skills/attention-skill它适合哪些书
项目本身并不挑内容类型。除了技术书,官方示例里就有《Working Backwards》——一本亚马逊的商业管理书,371 页,编译完之后你问它「PR/FAQ 流程怎么落地」,AI 基于原文框架回答。内部文档、研究论文、行业规范也都能跑。
一个简单的判断标准:你反复打开同一个文档、每次都感叹「明明读过但细节全忘了」——它就值得做成 Skill。
成本呢?低到忽略不计
作者用 Claude Sonnet 4.5 跑了实测数据:
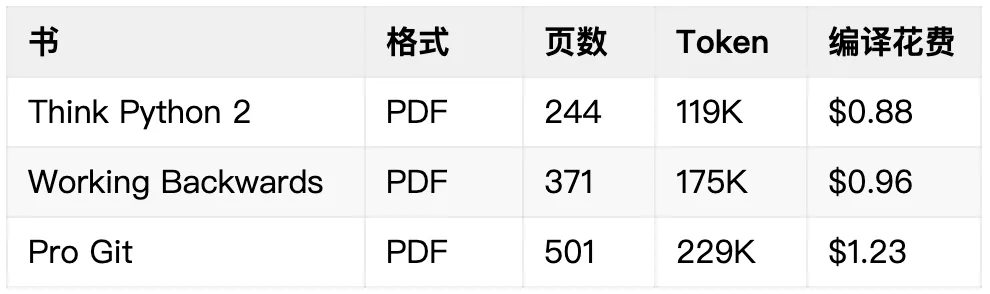
一本技术书编译一次 5-10 块钱,一次性的。之后每次查询只加载约 5K token,而不是 200K。Discovery Loop Tax 对比更直观——book-to-skill 比直接灌 PDF 省 24-51 倍 token,比让 AI 自己翻书省 2.4-15.6 倍。
不过这些数字背后,重点不是省钱。国内用 DeepSeek、Kimi 这些大模型,Token 本来就不贵。真正的价值是:上下文越干净,AI 回答越精准。 LLM 在接近满的上下文里检索具体事实时会丢精度,这个现象叫「lost in the middle」。你喂 5K 的高质量结构化提纲,远好过塞 200K 的噪点。
它跟 RAG 怎么选
很多人第一反应是「这不就是 RAG 吗」。其实是两套逻辑。
RAG 在查询时工作:切块 → 向量嵌入 → 相似度检索 → 把相关片段塞进 prompt。它擅长「找到提到 X 的那一段」。
book-to-skill 在编译时工作:让 LLM 通读全书 → 深度分析 → 提取作者的心智框架 → 做成结构化 Skill。它回答的是「作者构建了哪些思维模型,什么时候用哪个」。
选哪个取决于场景。几十本书需要快速检索 → RAG 合适。一两本书需要深度应用 → Skill 合适。它们不是替代关系,是有默契的好搭档。作者自己在 FAQ 里也是这么说的。
写在最后
book-to-skill 不卖概念不搞花活。它解决的就是一件很简单但很真实的事——你有知识,但 AI 调不动。 用一次编译的成本,把这条管道打通了。
如果你跟我一样,硬盘里躺着不少买了没读透的书,或者团队里总有人记不住那本规范文档的某条规则——这东西值得花一小时试试。
GitHub:https://github.com/virgiliojr94/book-to-skill
觉得有用的话,评论区聊聊——你最想先把哪本书或哪份文档变成 Skill?
往期回顾
