












文档内容
语义网格的研究现状与展望
David De Roure, Nicholas R. Jennings, and Nigel R. Shadbolt
摘要:网格计算极大地增强了数值计算、信息处理及协同工作的能力,并给许多领域的研究工作带来令人
激动的机遇。本文将通过网格在电子科学、电子研究和电子商务中的应用,说明网格蓝图的丰富性离不开
“语义网格”。语义网格是目前信息和服务被明确定义的网格的扩展,并能使计算机和人之间进行更好地
协作。为此,本文概括了语义网格的需求、探讨了满足这些需求所要达到的技术水平,并明确实现语义网
格愿景所面临的核心的研究困难。
关键词:协作系统、分布式计算、网格计算、知识表示、普适计算、语义网格、语义网、智能体
1 引言
从根本上讲,网格计算正通过对资源的整合以取得前所未有的成就。早在上世纪 90年代中期,业内
就有人强调通过对资源的联合来寻求高性能计算和超大规模数据处理的能力,如对超型计算机和计算机集
群的高速广义网互联。这种新能力能够帮助研究者从事原先需要他们毕生精力的棘手问题的研究,而且也
促进了协作科学研究工作。与电力网的出现给本地发电厂一个革命性变化类似,术语“网格”被用来刻画
这种互联特[1]。这种观点认为,计算资源、数据和昂贵的科研设备均可以作为一种应用在网络中传递。
随着网格计算的发展,资源被持续整合,但重点已经从早期观点(现在被讽刺为“巨型计算机和粗管
网络”)转变为虚拟组织的概念,Foster等人是如此定义的[2]:
真正能够准确描述网格的概念是指能够在动态变化的、多部门或团体的虚拟组织中的协调资源共享和
问题求解。我们所关注的共享并不是指原来的文件交换,而是指直接访问计算机、软件、数据和其他资源,
能够用来满足在工业、科研和工程中出现的一系列协同问题求解和资源调度策略的需要。
在这种背景下,2001发表的论文[3]中介绍了关于“语义网格”的概念。通过语义网、网格和软件
Agent研究团体之间的交叉研究,我们注意到在网格计算的前景和现实之间存在较大差距。我们在“语义
网格:未来电子科学的基础架构”的报告中陈述到:
电子科学提供了计算机和通信技术如何支持和提高科学处理的前景。它能使科学家们以一种更加有效
的方式产生、分析、共享和讨论他们的见解、实验和结论。提供这些便利的计算机基础架构同样适合于网
格。与此同时,大量的网格应用已经开发出来,并且出现了一整套提供必要功能模块的计算机技术。然而,
电子科学应该具备高层次的易用性、无缝自动化和具备全球规模的灵活的协作与计算能力,但这些实际的
研究工作与研究前景之间存在着很大的差距。
我们认为网格的出现与语义网的出现是密切相关的,语义网本质上是将网络信息资源关联起来,而且
也是国际互联网联盟(也叫万维网联合会,W3C)的最初阶段。
…为了创建数据交换的通用媒介,必须正视个人信息管理、企业应用集成和全球商业、科学和文化数
据共享等资源的顺利互联问题。把机器可以理解的数据放到网上的工具很快成了许多组织、个体和团体的
重中之重。只有当网络成为数据共享和被工具或人自动处理的场所,才能发挥其最大的潜能。为了方便网
络的扩展,即使现在的程序是完全独立设计的,但在将来也必须能够共享和处理数据[4]。
在网格应用系统中,对于已经充分认识这两个领域的研究者而言,将语义网技术应用到信息和知识之
中的价值已经突显。在那时,我们也可预见网格的面向服务的体系结构,并且提倡在网格系统中使用基于
代理计算思想的应用系统来获得必要程度的灵活性和自动化程度。这样,随着语义网技术在网格中的应用,
语义网格的蓝图渐渐地被勾画出来[5]。在我们最初的报告发表以来的三年时间里,许多相关的思想已经付诸实践,语义网格的研究和开发团
队也在不断壮大。尤其是语义网资源描述框架(RDF)和网络本体语言(OWL)已经成了W3C的规范,
而且支持它们的工具也在不断地出现。因此,各种各样的体现和使用这些标准的语义网应用和服务正在开
始出现[6]。此外,当需要使用支持互操作性的元数据时,网格开发者也会转而使用RDF,而且,像生
命科学领域的网格应用系统已经使用到本体一样[7],许多领域的网格应用系统的开发者都在共享使用
能够用网络本体语言OWL表示的词汇。
真实的应用系统和用户的实际工作经验也使得网格和自然世界的接口问题突显重要。因此,许多研究
者已经开始钻研语义网格的接口,例如可以通过关注传感器网络,手持式设备、人之间的交互来研究接口
问题。
作为在动态的、不确定的环境中实际实现和提供网络服务(在服务层协议的某个形式下)的实体,代
理的概念已经为语义网[8]和普遍的复杂分布式系统[9]明确地表达出来。与此同时,通过在面向服务
体系中使用语义网技术,在网格中促成基于代理方法的需求也已得到部分实现。现在,像在刚出现的WS
协议规范中定义的那样,资源自动协调的识别技术也同样获得了重视[10]。
同时,在语义网格的许多方面还存在重大的研究难题,在一些情况下,这些难题需要研究团体之间进
行协作才能取得成功[11]。
基于这个背景,本文通过对最新的研究工作和理论进展的跟踪,来对最初的语义网格报告进行的更新。
第2部分对语义网格研究前景进行回顾,第3部分对语义网格的需求进行探讨;第4部分对技术现状进行
综述;在相关文献中可不断地获得语义网格的案例研究,因此第5部分将着重介绍了四个项目,以阐述了
该领域的一些新的思想;在第6部分的讨论之后,第7部分为语义网格的重点研究内容进行修订,并给出
结论。
2 语义网格的研究前景
语义网格的研究前景是由实际需求驱动的。网格本身不是目标而是为达到目标而采取的手段,它的最
终目标是为用户的利益而实现其新的计算能力。因此,根据网格所能带给使用它的个人和团体的好处,才
能对网格的研究前景进行最恰当的评价;同时,他们的需求也确定了中间件的设计。不仅中间件的开发取
得成功,而且网格在科学、工程、商业或者是艺术及人文方面的研究进展也将最终取得成功。
英国电子科学计划采用了这种用户驱动、应用引导的方法,该计划耗资50亿美元,历时5年,资助
了至少100个独立的电子科学项目的研究。这些所有的项目都包含分布式数据、分布式计算和多机协作中
的一种或多种形式的研究内容[12]。在该研究计划考虑分解成若干个独立项目的起初,对语义网格的需求
就已经突显出来,然而这些需求在计划实施期间得到了进一步地加强。特别要说明的是,这些不同的项目
需要在一个公用的资源和网络框架下共存,必须对中间件的地位有一个清晰的认识。值得注意的是,许多
项目的运行目标已不是一时的一个项目,而是转向强调对软件、服务、信息和知识在最大程度上的复用需
求。起初我们想利用网格中间件来隐藏计算资源的异构性,以便它们能协同工作,但这样,一个新的网格
问题又出现了。即对网络服务、信息和知识的可预知和不可预知的复用问题,如何实现在时间上和空间上
的互用性。
实际上,电子科学计划并不仅局限于自然科学、工程和医学等科学学科,它同时也包括定量的和定性
的电子社会科学,目前甚至已经延伸进艺术和人文等学科。在国际上,全球网格论坛的人文、文科和社会
科学活动已经认可了对语义网格的需求。因此,“电子科学”一词很可能变成“电子研究”;同时,随着
协作的规模越来越大,地域分布越来越分散,参与的学科越来越多,不断增长的研究规模和复杂性使得电
子科学更具特色。这种不断提升地多学科的多样性也强化了对语义网格的需求。当然,协作并不是强制的:
“孤独的研究者”们仍然坚持从改善的资源中获益。
此外,电子科学并不仅局限于学术研究(例如至少 80家公司参与了英国电子科学计划)。利益产生于以下事实:电子科学能够支持竞争性的产业研究和开发,电子科学对中间件的需求与电子商务对中间件
的需求密切相关(常规商业的可计算和数据资源的共享问题是一个公共问题)。而且,随着电子科学渗透
进了教育领域,对学习管理系统或协作学习环境的集成的需求也已得到认可[13]。
电子科学的另一教训是需要简化工具软件和服务程序的开发、配置、测试和维护工作。从电子科学和
网格计算的研究项目中可以看到,这方面已经耗费了研究者大量的心智和工作。因此,将电子科学工作者
视为用户与满足用户安装、管理电子科学软件的需求同样重要。有一个基本准则,就是将人从与计算机系
统繁琐的交互中解放出来,以保证有更多的时间从事他们擅长的工作。因此,计算机系统在满足规模和复
杂性不断提升的情况下,自动化程度也越来越高。但是,要想充分得到这种自动化,则要求更多的机器自
动处理和更少的人工干预。软件开发、配置和维护的过程本身就是那些要求应用到语义网技术的工具和自
动化的一种方式。
可以看到,人是虚拟组织重要的组成部分,而语义网格则通过建立适当的连接和支持这些连接之间的
交互,来简化人们之间的协作。而且,个体的机器能自动处理的知识能够生成实践团体,这种团体可以远
距离地延伸出去,而且可以形成很大的规模。这两个语义网格所支持的特性,使得人们能取得在网格基础
架构简化之前不可能取得的成果。
简而言之,语义网格的研究前景将获得高层次的易用性和无缝自动化,并通过在网格中使用机器能自
动处理的知识的方式来简化具备全球规模的灵活多变的协作与计算。
3 语义网格的需求
随着我们从一定规模的电子科学应用中不断地获取经验,我们对语义网格需求的理解也在不断加深。
在最初的分析[2]中,我们在某种一般性假设下对样例进行分析,并将结果置入后续的一系列分析和处理
步骤中,由此确定了一组需求。现在我们已经摆脱了原有的分析而站在了新的高度。一般来讲,这些需求
可以定位在某个范围:一端表征为自动化程度、 由服务构成的虚拟组织和数字世界;而另一端表征为人
机交互、由人构成的虚拟组织和自然世界。
这些需求的根本(包括该范围的两端)在于规模问题。随着虚拟组织规模的增长,计算、带宽、存储
和服务与信息之间关系的复杂性的规模也随之增加。
基于这些驱动因素,我们明确了以下几个语义网格的关键需求。
1)资源的描述、发现和使用:系统必须以一种实时有效的方式(可能是通过资源联合的方式)来存
储和处理潜在海量的分布式内容,因此使系统能够明确内容、服务、计算资源和支持网格的工具等等。它
必须能够有效地发现和定位这些资源,并协商访问。它也同样要求能够生成和处理任务的描述、要求能够
对资源的按需使用和动态规划使用,以满足服务需求的质量和获得资源的有效利用。
2)过程的描述与发布:为了能够支持创建服务的虚拟组织,系统需要一些描述方法(如工作流),
以简化对多种资源的整合方法,以及在某种分布式方式下,简化对这些描述的创建和发布机制。
3)自治行为:在动态变化的环境中,系统应该能够为了满足多用户的需求而进行自动配置,并且能
够在系统出错时进行“自我修复”(这样系统就显得很可靠,但在实际中,它们可能会隐藏着不同级别的
失败和异常处理)。随着新内容和服务的出现,系统也应该支持进化式地成长。
4)安全与信任:许多组织/机构都包含着对认证、加密和隐私保护的需求,并且要求能以最少的人工
干预就可以处理这些需求。确实,从某个角度来讲,这才是虚拟组织的真正定义。与此相关的是责权的问
题:不同的合作者需要能够保持对自己内容的所有权和处理能力,并允许他人能够在适当的时机和条件下
访问这些资源。基于它们的特点,则需要提出相关策略,以至于它们能够应用于多种资源,并保持解释的
一致性。
5)注释:从记录样本开始到发布分析结果,都有必要进行注解,以此来丰富对任何数字内容的描述。
这种元内容可以应用于数据、信息、或者是知识,但依赖于一致的解释。理论上讲,在许多情况下,注释可以被自动地提取出来。这也支持了真实性的重要概念,由此保存下足够的信息,才可能使实验能被重做、
结果能被再利用、或者是提供证据,以表明这些信息确实是在当时产生的(后者可以包含第三方)。但是,
获得注释仅仅是事情的一半,我们也需要利用它们。诸如此类的例子包括:查找文献、查找人、查找先前
的实验设计(这些查询可包括推理)、注解上传的分析和给拥有者配置精准的空间等。因而,注解可以是
分布式的和协作式的。
6)信息集成:对异构的信息库进行有意义的查询、以可预知的或不可预知的方式对内容加以利用的
能力,对信息的互用性提出了要求。例如,这种情况可以包含用于不同领域间术语的对照关系等。这就是
语义网技术的典型的功能。
7)同步信息流与融合:除了永久存储外,还要求能实时地处理信息流。这些信息流可能是来源于仪
器、视频的数据,或者是任何如交互行为产生的数据流等。实时的或是重放的信息流都具有一个角色,尤
其是在与时间相关联的元内容充实的信息流中。通知信息也是一种信息流,即当有新信息到来时,会给用
户一些提示并开始自动处理。倘若那样,对信息流的记录和回放的支持则是必要的,并使综合它们的中间
产物变得更为容易。而且,根据用户的需要,要求能够从多种数据源中以不可预知的方式将内容组合起来;
对数据源、内容的描述以及注解将被用来对内容进行有意义地组合。
8)上下文感知的决策支持:信息要求在合适的时间、以合适的形式、在合适的设备上、以正确的插
入级别提供给用户。简言之,信息要求对上下文敏感,尤其是对即将处理的任务。这是一种自适应信息系
统任务,并为网格研究工作的规模所强调。因此,它是对入口程序的一种泛化,如文中[14]所述。
9)团体:通过限定的成员归属标准和操作规则,用户应该能够组成、维护和解散语义网格的实践团
体。这包括利用协作工具来鉴别出虚拟组织的个体集合,包括充分利用语义网格中跨学科的实践团体的知
识。
10)智能环境:智能环境应该体现出一定程度的环境智能。例如,装置会探测到样本信息(例如通过
条形码或射频标签),科学工作者可以利用便携式设备进行数据记录,访问网络(AG)的结点可以识别
发声者,以及可以在各种显示屏上展示各种信息。
以上是原先提出来的需求,现在我们又增加了两项关于配置和部署相关的新需求:
11)配置和部署的简易性:应该使一般用户(而不是要求具有高深研究背景的团队)就能部署网格应
用系统。
12)IT保留系统的集成:由于语义网格环境属于灰场开发,因此需要以一种更令人满意的方式,来
满足将原有的商业处理系统和学习管理系统等互联起来进行协同工作的挑战。
尽管上述的许多需求被认为是传统网格所具备的,但我们相信所有这些需求将不断地从语义网的某个
方面获益。因此,对我们来说,这是有效的描述方式:语义网贯穿于网格系统的始终。
4 语义网格的技术现状
既然已经明确了语义网格的需求,下面将探讨五种用来满足这些需求的关键技术。
4.1网络服务
在结构化的内容之上运行相关的服务是为其带来生命力的关键。这就好像能够开始在各种各样的语义
网应用系统中看到的那样(而且我们将在下一节的案例研究中再次提及)。更详细地说,当前围绕简单对
象访问协议(Simple Object Access Protocol, SOAP)、网络服务描述语言(Web Services Description
Language, WSDL)和统一描述、发现与集成协议(Universal Description, Discovery, and Integration,
UDDI)的研究工作,使相应的软件应用能够通过基于网络服务的网络来访问和执行。这样,网络服务就
以通过提供自动化程序通信、服务发现等的方式,极大地增强了网络体系的潜能。在这种观点下,网络服
务以一种全新的方式来利用Internet进行数据交换与融合,以此实现计算机和设备彼此互联。网络服务通
过对松耦合的、可重用的软件构件有效利用,来实现对闲置软件的组合(与过去的紧耦合方案形成对比)。在网络社区开始引入语义网技术的同时,网络服务作为电子商务领域中面向服务架构的一个产业主导
型解决方案,逐渐突显出来。2000年,有十家公司向国际互联网联盟递交了 v1.1版的SOAP规范。
Ariba、IBM和Microsoft公司接着出版了 WSDL规范,定义了一整套 XML语法,来描述网络服务和
UDDI服务注册。
在这个基础上,2002[15]发布了开放式网格服务体系结构(Open Grid Services Architecture,
OGSA),描述了一种面向服务的网格体系结构,而且全球网格论坛的开放网格服务基础架构(Open Grid
Services Infrastructure , OGSI)工作组规范一些约定,要求网络服务必须与网格服务保持一致。由此,新
增的网格服务内容包括新服务的按需创建、服务生命周期管理、服务组、状态处理及服务通知等。
作为网络服务的新增内容,OGSI被认为是用来满足网格计算的特定要求的,一些研究者发现它背离
了重要的网络服务实践,特别是在全状态服务交互方法中[16],而且还可以找到一种更自然的网络服务映
射方法。随后,IBM和Globus联合了一些其他的公司,一起发布了改进OGSI的建议,即一套新的网络服
务规范:网络服务资源框架(Web Services Resource Framework, WSRF)和网络服务通知(Web Services
Notification, WSN)(可参阅www.globus.org/wsrf)。
4.2 软件Agent(软件智能体)
多Agent系统的研究工作需要处理与语义网格极其相似的问题空间。特别地,软件Agent带来了实现
虚拟组织所需要的动态决策、分散、协调和自治行为。根本上讲,基于Agent的计算是一种面向服务的模
型[17],即Agent同时提供着服务的产生、使用和调度的功能,因此在基于Agent的计算和网络服务之间
存在密切的联系,这种联系可直接映射到面向服务的网格之中[18]。基于这种情况,Agent研究团队的工
作存在着几种方式来给出语义网格计算难题的解决方案,而且,网格并不需要一个基于Agent的框架来获
得代理的概念和这个团队的研究成果(可以参阅[19]对关键Agent概念的详细讨论,这些概念可用于研发
具备所期望灵活性和丰富性的网格应用)。
首先,需要在网格服务的概念引入自治的概念。这样的话,服务程序才不会总是能够被系统中的任意
实体所调用。这种自治意味着一些服务请求可能会失败,这是因为,例如在某一时刻或在给定的时机和条
件下,提供服务的实体不能够或者是不愿意提供相应的服务。这种自治服务的观点是从现在的概念中迁移
出来的基础性的思想,但如果网格想要在资源受限系统或开放系统中有效地运行,这种概念却是本质上的。
其次,有了服务自治的概念后,接下来的事实是:提供一项服务的实际方式是某种形式的协商(一个
由相关的参与者试图达成双方可接受的关于服务在什么时机和条件下执行的协议过程)。目前,这种观点
正开始被网格和Web的研究团体所认可(通过他们的研究成果,如网络服务协议, WSA),但仍有许多
工作要做。为了达到这个目的,多Agent系统的研究团体还有大量的工作要对协商和拍卖的形式进行研究,
如文献[20]所用。这样的研究工作主要包含两方面的内容:1)如何对这些遇到的情况进行结构化表示,
使得随后的协商过程和协商结果具有特定的属性(例如:最大功效、最高的社会福利、公正性等);2)
基于某个特定机制,Agent采用什么样的策略来获得它的协商目标。在前一种情况下,由于被认为是在分
散的、开放的系统中分配资源的有效手段,研究者放了大量的注意力到服务拍卖的各种形式上。
第三,虚拟组织作为动态形成的具有特定的共同目标的团队,它的概念已经在基于 Agent的计算领域
里研究很久了。由此产生了大量的模型、方法和技术,用来建立自治的问题求解程序之间的协作、确保恰
当地调整团体的行为、选择合适的成员加入到团队中以及在开放系统中建立信任和声望模型。
4.3 元数据
关于语义网的文献越来越多,其中有很重要的一部分在探讨本体及其推理的问题,这些反映了该领域
的早期研究活动(实际上,有时认为语义网和本体是一回事儿)。但是,在我们讨论本体推理之前,还有
一个步入支持元数据领域的重要而又显得寻常的环节。
根本上讲,许多语义网的附加价值来源于在应用领域中不断累积的对各种各样的中间产物和资源的描述信息。在科学过程中处理同一事物(可能是一个样例分析、一台设备、一种化合物、一个人或一个出版
物等)的不同阶段,元数据将被记录在各种存储器、数据库或网站中。这样,分布式元数据就可以被它所
描述的对象有效地联接在一起。反言之,这样就会使我们利用整合度高的知识来问一些新的问题(如文献
[21]所述)。在某些领域,可以通过已有的标准来简化命名问题,如在生命科学领域中,生命科学标识符
就是一种为生物体制定的标准化命名方法,而化学领域则是IUPAC化学标识符(IChI)。
在这个基础上,语义网的比重依赖于在“信息空间”中所能达到网络效果,该空间允许机器可阅读内
容的共享和联接,并通过对其它语义网文档确定的内容进行联接、扩展甚至是拒绝来获得能力。但是,为
了达到这种效果,我们需要用共享的、唯一的统一资源标识符(Uniform Resource Identifiers, URI)来描
述对象(包括实对象或虚拟对象),以及对对象之间的关系(包括等价关系)进行适当的声明。因而,为
了语义网技术的长远发展,更多的研究团体必须认识到资源连接的重要性,并使更多资源在网络上可以被
命名。
4.4 本体与推理
本体决定术语的扩展和术语间的关系。对大多数场合来说,本体仅仅是已发布的、或多或少被认同的
某个领域内容的概念化。本体可以描述对象、过程、资源、性能等任何事物。基于这个假设,可以看出本
体提供了元数据的基础。因而,可以通过添加本体注解的方式对任意一种内容进行“修饰”(例如它可以
指示内容的原始信息、出处、价值或寿命等)。语义网格需要本体作为它的基础构件。
可以看到在特定的基于网格的项目[22][5]里,更为广泛地讲,遍及所有科学技术研究领域,越来越多
地采用本体技术。如医学一体化语言系统( Unified Medical Language System, UMLS, 参见
www.nlm.nih.gov/ research/umls)、基因本体(参见www.geneontology.org)、计算机科学研究(Computer
Science Research, CSR, 参 见 www.aktors.org/publications/ ontology ) 、 军 事 联 合 本 体 ( 参 见
ontology.coginst.uwf.edu)等。
而且,许多本体作为商业性规则的结果出现在垂直市场要求共享公共的描述的地方。以下是相应的例
子:通用商业库(Common Business Library, CBL, 参见www.xcbl.org)、商业 XML(Commerce XML,
cXML, 参见www.cxml.org)、标准化材料与服务分类(参见 ecl@ss)、开放式应用程序组集成规范
(Open Applications Group Integration Specification, OAGIS, 参见www.openapplications.org)、开放式金
融交换(Open Financial Exchange , OFX, 参见 www.ofx.net)、房地产交易标记语言(Real Estate
Transaction Markup Language, RETML, 参 见 www.rets.org ) 、 RosettaNet 标 准 ( 参 见
www.rosettanet.org)、联合国标准产品和服务编码(UN/SPSC, 参见 www.unspsc.org)和统一内容扩展分
类系统(UCEC)等。
当然,在开发、利用和维护本体时会遇到了一系列重大的挑战,包括这种情况:本体在科学和商业实
践中经常是隐藏很深,且它们会随着任务或角色的变化而变化。此外,多个本体的集成也是件困难的事情,
尤其当面对领域特征发生变化的时候,维护起来更加困难。不过,上面的情况确实可以简化了机器和人之
间的协同操作,提升了资源的重用性,且真正成为分布式科学基础架构的一部分。
然而,提供丰富的内容和元数据只是充分利用作为公共概念化的本体第一步。由于本体对对象类之间
的关系进行编码,因此从这些类的实例中推断出它们之间的关系。为了达到这个目的,可以在OWL标准
中使用一些描述逻辑推理引擎来实现推理过程(如文献[23]所述)。由于本体分布广泛而且很可能包含成
千上万个实例,除了对内容进行基于规则的推理之外,本体还需要采用概率方法和随机方法。因此,通常
可以认为推理是语义网服务的一种特殊情况,我们现在就来讨论该领域的发展情况。
4.5 语义网服务
目前,调用一个网络服务所包含的抽象层次是相当低的。因而,UDDI、WSDL和SOAP技术只能对
服务识别、服务配置和组合、服务比较、自动协商等方面的自动化提供有限的支持。所以,语义网服务的前景在于提高描述的层次,以致于能够用表征服务的能力和任务的方式来细化服务。
为此,针对网络服务的网络本体语言(OWL-S)[24] 自然而然地在OWL的基础上定义了丰富的语义
网描述[25]。语义网服务倡议(SWSI, 参见www.swsi.org)通过放宽对定义服务工作流的描述逻辑形式体
系的使用限制,而使用一种基于一阶逻辑的语言来扩展这项工作。网络服务建模框架(WSMF)[26]是语
义注解型网络服务的另一种可选方法,其目的在于解决网络服务组合面临的语义和协议的协同问题。在对
统一问题求解方法开发语言(Unified Problem Solving Method Development Language, UPML)框架[27]的
早期研究工作进行扩展的基础上,可以用框架逻辑来表示定义目标、仲裁、本体的逻辑表达式合网络服务。
UPML能够区分域模型、任务模型、问题求解方法和桥接,同时也是互联网推理服务(Internet
Reasoning Service, IRS)的基础[28]。作为语义网服务的一种基于知识的方法,IRS通过推理和对网络服
务进行语义描述,为基于本体的网络服务的选择提供了一种手段。在这里,域模型就是域本体,而任务模
型则为待求解任务提供一般描述。问题求解方法提供任务的独立执行的描述,而桥接则对不同组件之间进
行映射。这里采用的是以任务为中心的方法,当客户端请求解决某个任务时,IRS调度程序就会调用合适
的问题求解方法。
有了这些合适的描述,服务的自动调度和组合就成为可能。接下来,将利用基于 Agent的技术(如上
所述)来整合和协调这些服务的发现、组合和发布。
5 案例研究
许多语义网格项目正在进展中,相关活动已由全球网格论坛举办的语义网格专题研讨会进行了报道
(参见www.semanticgrid.org)。但是,现在我们正考虑将我们直接参与的项目的一些研究短文与大家分
享一下。选取这些项目的目的是试图举例说明一下当前几种不同方面的语义网格研究工作。
5.1 CombeChem/eBank
使实验过程得到极大加速、甚至是并行处理的现代实验技术产生了海量的数据,这极大地推动了一些
网格应用的发展。例如,一个简单的DAN微阵就可以同时产生数以千记个基因的信息,这可是原来每个
实验只能处理一个基因的一个重要飞跃。同样,在组合化学领域,化学家可以同时利用大量不同的化合物
生产出新的混合物。用组合方法合成新的化合物,为生成海量的新化学知识提供了重要的机会,这就是电
子科学试验项目CombeChem[29]的主要推动力。这个项目旨在通过对巨大的化合物资料库的综合与分析,
不断增加物质的知识量,来增强对化学结构和属性的相关性和预测性。
为了有效地、可靠地做到这一点,则需要自动测量和分析技术,这是一个通过语义网技术应用来使知
识可以被明确表示且可以被机器处理的典型案例。但是,这个项目将深入下去,以实现实验工作台与理性
化学知识之间完全的端到端联接的目标。这些知识作为试验结果被发布,即所谓的“源发布”[30]。原
始数据伴随着实验条件信息的产生而产生。下列是一连串的处理过程,如实验数据的整合、特定数据子集
的选取、统计分析、建模与仿真。对这些信息的处理包括对图表的注解或者是对数字图像的编辑。在利用
描述产生数据过程的信息的同时,所有的处理都将产生二次数据。为了实现在后续的支持科学过程、遵循
适当访问控制的数据复用,通过“源发布”可以获得这些所有的数据。
因此,在该项目的中,语义网格技术的一个功能是在从实验到发布的整个过程中,建立完整的始终联
接的数字信息链。这项工作开始于智能实验室和支持网格的实验仪器[31]。在早期阶段,通过对化学实验
室的科研人员的调查,相关技术被推荐用来简化信息的获取[32]。另外,还使用了普适计算的设备来捕获
实验台上产生的现场的元数据,以减轻化学家们创建元数据的负担。然后将这些数据进行科学数据处理。
在科学处理的每个环节,对数据的用法实际上是对其有效地标注。所有的注释都通过共用的URIs(统一
资源标识符),或者是通过不同URIs之间的等价关系和其它关系的判定来进行关联,在确保这种情况下
那些在将来想要使用这些实验结果的科学家们才能追溯起源(也就是说,出处是明确的)。这可以通过使
用RDF triplestores平台来对原有的不同的关系型数据库和数据存储平台进行连接来实现。典型的输出是学术发布,可以自动存档于专门设立的资源库或发布到数字图书馆中。在英国,目前正
鼓励对研究数据的进行自动归档和联接[33]。这并不是过程的结束,这是因为研究和学习是循环的过程,
而且还要反馈到后续的实验中。这些学术过程支持对输出结果的进一步解释,和对可供选择的理论的建议
和研究。源发布也支持对已发布的知识的联接来简化处理,并允许自动处理。倘若组合化学的知识生成量
大的话,对每一种化合物来讲,成为科学家传统学术发布的对象并不是不可能的,因为这可能会引入严重
的瓶颈问题,即可能80%的数据都不会被处理到。因此,这就是语义网格在化学领域的科学过程中支持有
效知识转换的一个例子。
上述部分思想已经在World Wide Molecular Matrix(一种化合物结构格式转换平台)[34]和多尺度化
学科学联合实验室(美国能源部化学发展计划)[35]中得到应用。
5.2 CoAKTinG
CoAKTinG项目[36]以一种全新的方式对语义网技术进行应用,以此推动了分布式电子科学在协作仲
裁空间方面的技术水平的发展。它由四个工具组成:即时消息与在线提示(BuddySpace)、图形会议与分
组存储捕获(Compendium)、智能“to-do”列表(Process Panels)和会议捕获与回放。这些工具被集成
到协作环境中(比如访问网格),并通过利用共享的本体来交换结构,在会议发生前后或发生时,能够提
升对资源的增强过程跟踪和导航的能力。
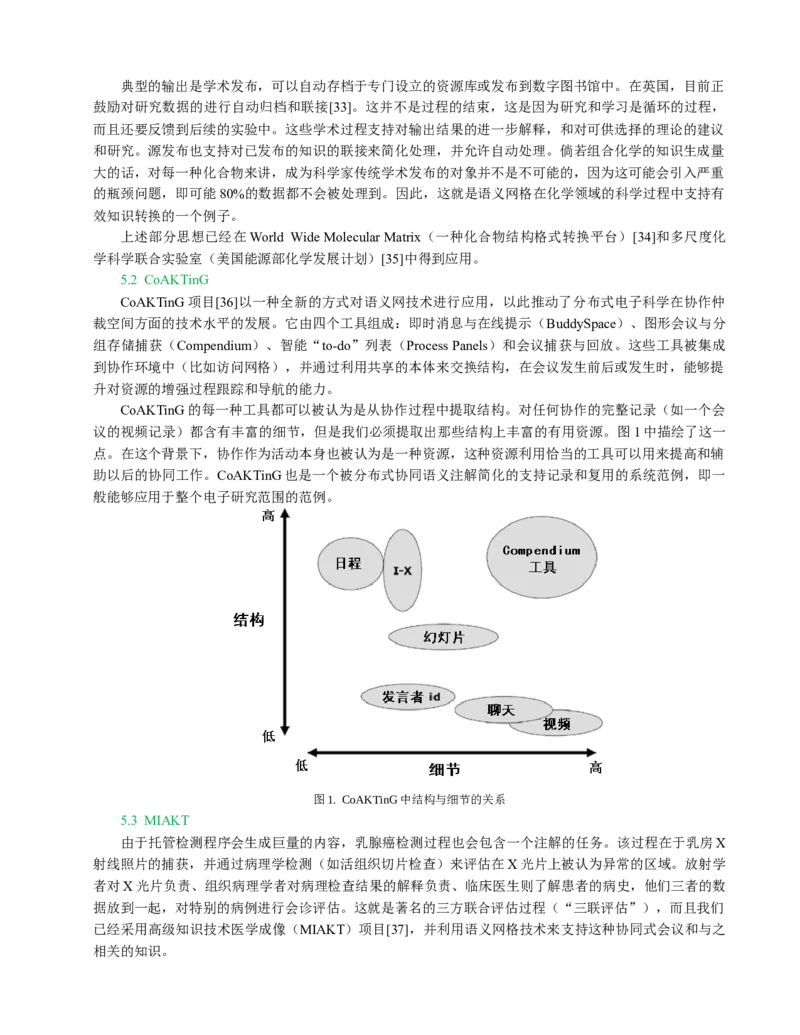
CoAKTinG的每一种工具都可以被认为是从协作过程中提取结构。对任何协作的完整记录(如一个会
议的视频记录)都含有丰富的细节,但是我们必须提取出那些结构上丰富的有用资源。图1中描绘了这一
点。在这个背景下,协作作为活动本身也被认为是一种资源,这种资源利用恰当的工具可以用来提高和辅
助以后的协同工作。CoAKTinG也是一个被分布式协同语义注解简化的支持记录和复用的系统范例,即一
般能够应用于整个电子研究范围的范例。
图1. CoAKTinG中结构与细节的关系
5.3 MIAKT
由于托管检测程序会生成巨量的内容,乳腺癌检测过程也会包含一个注解的任务。该过程在于乳房X
射线照片的捕获,并通过病理学检测(如活组织切片检查)来评估在X光片上被认为异常的区域。放射学
者对X光片负责、组织病理学者对病理检查结果的解释负责、临床医生则了解患者的病史,他们三者的数
据放到一起,对特别的病例进行会诊评估。这就是著名的三方联合评估过程(“三联评估”),而且我们
已经采用高级知识技术医学成像(MIAKT)项目[37],并利用语义网格技术来支持这种协同式会议和与之
相关的知识。图2 MIAKT混合网与网格服务结构
MIAKT应用系统基于分布式体系结构建立的(如图2所示),它利用基于服务的Web和网格为某一
类的客户端应用程序提供离散且不同的功能服务。这种体系结构特地从任意的应用领域及其描述中抽象出
来,以提供一种强大的结构,可以在新的领域中快速地建立新知识管理的应用系统原型。在这个方面,
MIAKT就成了这种体系结构的特殊应用了。
按照语义网格的规划,服务应该根据特定应用领域的应用本体,提供给客户端应用程序。服务程序则
利用本体来具体体现这种框架,并提供简单的、同种类型的API(应用程序接口)给可能运行在多种协议
之上的应用程序的网络服务。
MIAKT系统既为检测过程产生的数据提供知识管理,也为医务人员在使用Web和网格服务的情况下,
提供一种研究、注解和分析数据的手段。使用本体来存储知识,可以简化为会诊提供辅助诊断的机制。应
用软件允许对X光、核磁共振等扫描生成的各种图像进行查看和标注,可以搜索病人数据,以及支持在互
联网上对图像分析、数据分析和自然语言报告的生成 等相关服务的调用。其中一些服务进行深度计算,
并使用显式的网格服务。
5.4 医学设备
在“基于网格的日常健康医学设备”项目中,共同使用到了网格计算和普适计算技术,其目标旨在使
用随身计算技术来对出院的病人进行病情监视。由于病人是活动的,因此其位置和运动信息将被收集起来
(诸如使用加速计等设备),以提供必要的关联信息来解释对应的生理信号。网格会自动进行相关的信号
处理,并通过普适计算,当病人正处于身体状况需要特别关注的时候,系统就会向医护人员发出警报。
一个有趣的基础性研究问题是网格服务的例程要延伸到怎样的程度才可以被部署到设备中。本项目使
用Globus Toolkit 3进行管理。我们使用的典型设备和传感器都只有有限的计算能力和存储空间,且仅有
间歇性的网络连接能力。尽管在有些情况下,它们也有能力运行网格服务程序,但一般来讲都是通过网格
服务代理的设备接口进行远程服务调用。接下来,用户就可以通过一个入口程序来访问需要的信息,这本
身就可以普适设备访问到。
随身设备提供的附加关联信息,如GPS数据和加速计数据,对于解释生理信号的非常必要的。对这
些数据语境关系进行建模、推理和管理,都将再次使用到语义网技术。
这仅仅是传感器网络的一个例子而已。其它的传感器网络,由于要在更高的时间密度或空间密度下采
集数据,因此要求网格处理,这反映了传感器技术的进展,也是为了数据的可视化。在这个医学应用方案中,其主要的目的是获得可以用语义网技术表示的信息,以便复用和互用。
6 讨论
语义网格的概念产生于2001年。我们多个研究小组共同对网格、语义网、web服务和软件代理等领
域进行了联合研究。与此同时,网格的研究者也在考虑网络服务的问题,这种观点在 2001年发表的网格
“解剖学”论文[2]中得到加强,并在2002年发表的“生理学”论文[38]中得到确认。 web研究团体为语
义web开发了web服务并明确地叙述了需求。我们的在2001年7月向e-Science团体递交的研究报告对电
子科学研究计划中出现的许多科研项目产生了重要影响,并在第二年第一次撰写了有关语义网格的论文
[39][40]。
现在,我们已经可以看到有关网格和语义网的活动在不断地增加。全球网格论坛的语义网格研究小组
定期召开专题讨论会,其它的团体也会组织语义网格的相关活动,这个领域的相关文献也在不断增加。现
在三年过去了,我们仍然对语义网格的进展进行深入的反思。正如我们在第二节中所讨论的,电子科研计
划加强了对语义网格的需要,正如网格中间件将各种计算机连接起来一样,语义网格中间件将各种项目联
系起来。
从语义网研究中得到的结果将有助于推动研究进程。研究工作产生了一些新的表示本体的标准,例如
OWL,以支持系统之间的协同工作方式。现在也出现了一些工具,可以方便地用来创建和验证本体。基
于网格协同工作的各种要素(如人和机器)之间要想能保持一个共同的概念,本体是一个至关重要的要素。
语义网的研究工作也产生了一些能够支持注解、连接、搜索和浏览内容的工具。而且,我们也开始见到使
用语义注释和元数据的集成应用软件[41]。现在迫切需要的是要研究如何描述知识服务自身的标准和方法,
以及研究如何方便地将各种服务组合成更大的应用和符合特定协议的工作流程。其中一个重要的因素可能
就是由软件代理组形成的交互协议和框架。
我们提倡面向代理的方法,而不是本质上采用软件代理框架,这反映了我们深信基于代理的计算提供
非常重要的技术,但也意识到在部署网格规模的代理时并不那么明显。因此,很自然地可以看到这些思想
贯穿在网络服务中,例如WS协议,该协议旨在定义一种语言和规范,用于发布服务提供者的性能、创建
协议和实时监视协议的一致性。在工作流程中,工作量明显集中在自动控制上。然而,这仅仅是我们对面
向代理方法研究的一个步骤。
1)尽管代理是服务的提供者、使用者和调度者,但我们所能看到的功能只表现在网络服务和语义网
服务之中,他们具备重要的自治的概念。我们认为这仍然是语义网格需要的,尤其是需要实现更多的具备
自治能力的基础架构。
2)在代理协商问题上还有很多的专门技术,需要在语义网格领域中应用到创建灵活的虚拟组织之中。
此外,仍然还有一些领域的进展比我们期望的稍微要慢些。
但是,可以想象,至少可以表达出来,在这三年中,最为重要的研究进展莫过于正确评价了语义网在
网格基础架构当中所担当的角色。这导致了早先三层“网格”结构[42]的一些变化。尽管这个模型很有价
值,但它未能表达知识服务在网格的基础架构中的真正作用。为此,我们还是认为由 Goble[11]提出的更
新的体系结构,更能在多个层次中捕获它们之间的相互作用(如图3所示)。图3. Goble提出的语义网格体系结构
正如体系结构图所展示的,网格的自动的数字世界必须在某些方面满足用户的可交互的自然世界。现
在,在很多情况下,这可以通过用户正在交互使用的设备来体现,如掌上电脑、便携式电脑、显示屏、访
问网格,或者是虚拟现实。然而,网格世界与自然世界之间,以及这两个世界中的各种资源之间的关系所
产生的一般性问题仍然还有。
要想回答这个问题,我们认为必须考虑普适计算(或称普及计算、普遍计算或泛计算)这个领域,这
涉及到无处不在的设备资源,如在日常设施中、在我们身上或周围、在外部环境中。通过 Mark Weiser[43]
的研究工作,Xerox首先采用“普适”这个术语,Mark Weiser强调“宁静”特征,即计算无出不在却总是
“袖手旁观”。在欧洲,普适计算是环境智能研究领域的一部分。
摩尔定律告诉我们,如果保持体积不变(如台式计算机),那么随着时间的推移,计算机一代一代地
发展,其计算能力也将不断增强。可是,如果仅想保持相同的计算能力,那么设备就会变得越来越小,越
来越便宜。那么,广泛地讲,这分别给我们带来了网格的世界和普适计算的世界。这两个方面都是重要的
且不可避免的技术发展趋势,因此需要共同考虑。但是,我们认为网格和普适计算还有更重要的关系:普
适计算提供了网格在自然世界的表现形式。
有的时候网格应用系统需要普适计算,有的时候普适计算需要网格。之前,我们对与网格相关的设备
分成:支持网格的实验设备、科学设备装置的部件、能够直接连接网格的网格设备以及能够提供给用户收
集信息和访问结果的手持式设备。具有新型接口的设备也可以用来支持协作环境,还可能为数据的注解和
可视化带来便利。在后来的分类中,已经包含了传感器网络,并且随着传感器和传感器阵列的发展,我们
可以在更高的时间分辨率和空间分辨率的情况下获取数据,当然,这些不断增长的大量的通常是实时的数
据需要依赖网格的计算能力。同时,由于只需要少量的设备或少量的用户,许多普适计算通常是小规模的,
但是随着数量不可避免地增加,则需要更多的网格处理。
通过这些,可以发现网格和普适计算都各自需要大量的分布式处理部件。在某个适当地抽象层,它们
在分布式系统中都包含着相似的计算机科学领域的难题。确切地说,这些难题包括服务的描述方法、服务
的发现与组合、资源的可用性和灵活性问题、自主行为,当然也包括安全性、身份认证和信任问题。它们
都需要能够动态地轻松地组装各个部件,也都要依赖各部件协同工作的能力来达到它们的目标。对等网络
就是与这种情况相关的一个范例。
与网格一样,我们也来讨论一下普适计算的丰富性需要语义网技术支持的问题。此外,这还与语义的
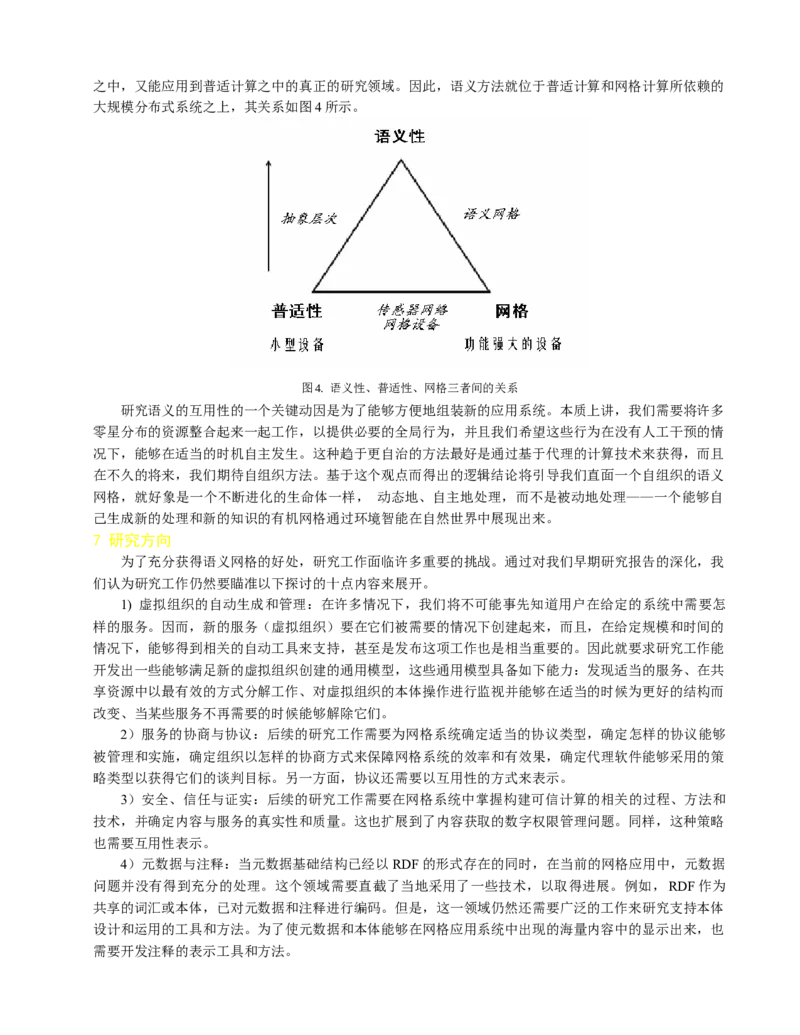
互用性相关:我们需要服务的描述方法、服务的发现与组合,并且需要像语义网服务一样既能应用到网格之中,又能应用到普适计算之中的真正的研究领域。因此,语义方法就位于普适计算和网格计算所依赖的
大规模分布式系统之上,其关系如图4所示。
图4. 语义性、普适性、网格三者间的关系
研究语义的互用性的一个关键动因是为了能够方便地组装新的应用系统。本质上讲,我们需要将许多
零星分布的资源整合起来一起工作,以提供必要的全局行为,并且我们希望这些行为在没有人工干预的情
况下,能够在适当的时机自主发生。这种趋于更自治的方法最好是通过基于代理的计算技术来获得,而且
在不久的将来,我们期待自组织方法。基于这个观点而得出的逻辑结论将引导我们直面一个自组织的语义
网格,就好象是一个不断进化的生命体一样, 动态地、自主地处理,而不是被动地处理——一个能够自
己生成新的处理和新的知识的有机网格通过环境智能在自然世界中展现出来。
7 研究方向
为了充分获得语义网格的好处,研究工作面临许多重要的挑战。通过对我们早期研究报告的深化,我
们认为研究工作仍然要瞄准以下探讨的十点内容来展开。
1) 虚拟组织的自动生成和管理:在许多情况下,我们将不可能事先知道用户在给定的系统中需要怎
样的服务。因而,新的服务(虚拟组织)要在它们被需要的情况下创建起来,而且,在给定规模和时间的
情况下,能够得到相关的自动工具来支持,甚至是发布这项工作也是相当重要的。因此就要求研究工作能
开发出一些能够满足新的虚拟组织创建的通用模型,这些通用模型具备如下能力:发现适当的服务、在共
享资源中以最有效的方式分解工作、对虚拟组织的本体操作进行监视并能够在适当的时候为更好的结构而
改变、当某些服务不再需要的时候能够解除它们。
2)服务的协商与协议:后续的研究工作需要为网格系统确定适当的协议类型,确定怎样的协议能够
被管理和实施,确定组织以怎样的协商方式来保障网格系统的效率和有效果,确定代理软件能够采用的策
略类型以获得它们的谈判目标。另一方面,协议还需要以互用性的方式来表示。
3)安全、信任与证实:后续的研究工作需要在网格系统中掌握构建可信计算的相关的过程、方法和
技术,并确定内容与服务的真实性和质量。这也扩展到了内容获取的数字权限管理问题。同样,这种策略
也需要互用性表示。
4)元数据与注释:当元数据基础结构已经以RDF的形式存在的同时,在当前的网格应用中,元数据
问题并没有得到充分的处理。这个领域需要直截了当地采用了一些技术,以取得进展。例如,RDF作为
共享的词汇或本体,已对元数据和注释进行编码。但是,这一领域仍然还需要广泛的工作来研究支持本体
设计和运用的工具和方法。为了使元数据和本体能够在网格应用系统中出现的海量内容中的显示出来,也
需要开发注释的表示工具和方法。5)内容处理与保存:后续的研究工作要求将各种各样的媒体资源整合到e-Research基础架构下来。
这将包括视频、音频、特定领域数据和各种各样的成像方法。研究工作也需要将元数据和注释与各种各样
的媒体形式关联起来,包括分布式协作注解。随着内容的保存变得日益自动化,我们期望“自动保存”能
被界定。
6)知识技术:除了研究元数据和注释外,还需要开发和定制在 e-Science环境中使用的其它知识技术。
这些技术包括知识捕获工具和方法、动态内容连接、基于注释的搜索、有注解的可复用知识库、自然语言
处理方法(用于内容标记、审定、生成和摘要),数据挖掘、机器学习和互联网推理服务。如果将这些技
术整合到电子科研的工作流程中,则需要共享的本体和服务描述语言。如何从其它服务集中组合出能够完
成特定任务的服务的问题已成为一个重要的研究领域。这些技术也需要整合在普适设备和智能实验室环境
中,由此形成e-Research。
7)设计与部署:后续的研究工作要求能够更加容易地设计、配置和部署应用系统。明确地说,所有
的用户都要能够轻松地使用网格框架和应用系统,贯穿从设计到开发、部署、运行、维护和复用的整个生
命周期。
8)交互:后续的研究工作要求用各种方式将信息进行可视化表示方法和技术,以保证e-Research协
作工作的一致。这也将包含以反映本地化上下文的方式来定制内容,并且还要考虑个性化和适应性的问题。
语义网格与现实世界的交汇点则通过人机交互界面/接口来展示语义信息。
9)协作:需要更多的研究工作来理解当前和将来电子科学研究的协作工作流程。用户应该能够形成、
维护和解散基于一定成员限制规则和操作规则的合作环境。目前,大部分的研究工作都在关注基于网络接
口的电子科研的基础架构。但是,这些构架只有在采用了电子科学研究者工作环境的情况下才会被应用。
协作过程还没有研究透彻,且急需收集和理解这些需求。同时也还需要从用户中收集真正的需求、收集应
用案例,并从事一些可评估的和可比较的研究工作。最后,我们还需要理解电子科学研究中更多的完整的
协作过程。
10)普适计算:目前,大部分提及或讨论网格的研究都表明他们的主要任务是能够对大量的计算能力
进行全局性的使用。但是,一般情况下我们认为网格应该作为一种在变化的网络资源集合中提供无缝和透
明操作的手段。这些资源可是掌上电脑,也可以是超级计算机;可以是传感器和智能实验室,也可以是人
造卫星平台。我们认为为了电子科学研究能够成功实现、为了网格能被有效地利用,更多的关注点需要放
在应该建设和扩展怎样的实验室上。例如,我们相信发展基础设施建设的必要性,以此来允许成套设备发
布自己的广告、与其它资源连接起来,并对接收到的或自己生成的内容进行注释或审定。
而且,我们还认为在e-Research领域中发展的许多问题、技术和解决方案都能够应用到一些其它的领
域,这些领域的动态改变的合作群需要通过电子的方式联系起来并通过方便的方式进行交互。因而,我们
认为将电子商务、电子交易、电子教育和电子娱乐等领域关联起来并探索综合利用的途径也很重要。
总的来讲,这三年的研究进展使我们更坚信语义网格的价值和由此出现的团队正获得重大的研究动力。
当然,现在仍面临许多挑战,一些技术性的挑战已经被突显出来。然而,其它的挑战则需要将各种研究团
体联合起来以成就语义网格的真正作用,这才是真正意义上的建立沟通与协作。我们确实需要将研究团体
联合起来,为产生新的科研成果、建立新的商务,甚至创建新的科研学科而构建语义网,一个具有全球规
模的能够方便地用于协作和计算的语义网。
致谢
很多同行在语义网格的研究中作出重要贡献,并引导着它的发展方向。这些人包括:C. Goble、T.
Hey、J. Hendler、Y. Gil、C. Kesselman、G. Fox、I. Foster、L. Moreau、S. Cox, J. Frey、T. Payne和M.
Surridge,尤其是C. Goble,他从一开始就是语义网格研究团队的中坚力量,引领了英国语义网格项目
myGrid的研发,而且担任了全球网格论坛语义网格研究小组的主席。参考文献
[1] I. Foster and C. Kesselman, The Grid: Blueprint for a New Computing Infrastructure. San Mateo, CA: Morgan Kaufmann, 1999.
[2] I. Foster, C. Kesselman, and S. Tuecke, “The anatomy of the grid: Enabling scalable virtual organizations,” Int. J. High Perform.
Comput. Appl., vol. 15, no. 3, pp. 200–222, Fall 2001.
[3] D. De Roure, N. R. Jennings, and N. R. Shadbolt, “Research Agenda for the Semantic Grid: A Future e-Science Infrastructure,”
National e-Science Centre, Edinburgh, U.K., UKeS-2002-02, Dec. 2001.
[4] SemanticWeb Activity Statement, 2004. W3C,WorldwideWeb Consortium.
[5] C. A. Goble, D. De Roure, N. R. Shadbolt, and A. A. A. Fernandes, “Enhancing services and applications with knowledge and
semantics,” in The Grid 2: Blueprint for a New Computing Infrastructure, I. Foster and C. Kesselman, Eds. San Mateo, CA: Morgan
Kaufmann, 2004, pp. 431–458.
[6] D. Fensel and M. A. Musen, “Special Issue on the Semantic Web,” IEEE Intell. Syst. Mag., vol. 16, no. 2, pp. 24–25, Mar.–Apr.
2001.
[7] C. Wroe, R. Stevens, C. Goble, A. Roberts, and M. Greenwood, “A suite of DAML + OIL ontologies to describe bioinformatics
web services and data,” Int. J. Coop. Inf. Syst., vol. 12, pp. 197–224, 2002.
[8] T. Berners-Lee, J. Hendler, and O. Lassila, “The semantic web,” Sci. Amer., vol. 284, no. 5, pp. 34–43, May 2001.
[9] N. R. Jennings, “On agent-based software engineering,” Artif. Intell., vol. 117, pp. 277–296, 2000.
[10] A. Andrieux, K. Czajkowski, A. Dan, K. Keahey, H. Ludwig, J. Pruyne, J. Rofrano, S. Tuecke, and M. Xu, “Web Services
Agreement Specification (WS-Agreement),” Global Grid Forum, May 2004.
[11] C. Goble and D. De Roure, “The semantic grid: Myth busting and bridge building,” presented at the 16th Eur. Conf. Artificial
Intelligence (ECAI-2004), Valencia, Spain, 2004.
[12] T. Hey and A. E. Trefethen, “The UK e-science core programme and the grid,” Future Gen. Comput. Syst., vol. 18, pp. 1017–
1031, 2002.
[13] Roadmap for a UK Virtual Research Environment, JISC, Joint Information Systems Committee, 2004.
[14] D. Gannon, G. Fox, M. Pierce, B. Plale, G. V. Laszewski, C. Severance, J. Hardin, J. Alameda, M. Thomas, and J. Boisseau,
“Grid Portals: A Scientist’s Access Point for Grid Services,” Global Grid Forum, Sep. 2003.
[15] I. Foster, C. Kesselman, J. Nick, and S. Tuecke, “Grid services for distributed system integration,” Computer, vol. 35, no. 6, pp.
37–46, Jun. 2002.
[16] S. Parastatidis, J. Webber, P. Watson, and T. Rischbeck, “A Grid Application Framework Based on Web Services Specifications
and Practices,” North-East Regional e-Science Centre, Aug. 2003.
[17] N. R. Jennings, “An agent-based approach for building complex software systems,” Commun. ACM, vol. 44, pp. 35–41, 2001.
[18] L. Moreau, “Agents for the grid: A comparison with web services (Part 1: The transport layer),” presented at the 2nd IEEE/ACM
Int. Symp. Cluster Computing and the Grid (CCGRID 2002), Berlin, Germany, 2002.
[19] I. Foster, N. R. Jennings, and C. Kesselman, “Brain meets brawn: Why Grid and agents need each other,” presented at the Proc.
3rd Int. Conf. Autonomous Agents and Multi-Agent Systems, New York, 2004.
[20] N. R. Jennings, P. Faratin, A. R. Lomuscio, S. Parsons, C. Sierra, and M. Wooldridge, “Automated negotiation: Prospects,
methods, and challenges,” Int. J. Group Dec. Negot., vol. 10, pp. 199–215, 2001.
[21] N. R. Shadbolt, N. Gibbins, H. Glaser, S. Harris, and M. C. Schraefel, “CS AKTive space or how we stopped worrying and
learned to love the semantic web,” IEEE Intell. Syst., vol. 19, no. 3, pp. 41–47, May–Jun. 2004.
[22] D. De Roure, Y. Gil, and J. Hendler, “Special Issue on E-Science,” IEEE Intell. Syst., vol. 19, no. 1, pp. 1–89, Jan.–Feb. 2004.
[23] V. Haarslev and R. Moller, RACER User’s Guide and Reference Manual, Sept. 2003.
[24] D. Martin, M. Paolucci, S. McIlraith, M. Burstein, D. McDermott, D. McGuinness, B. Parsia, T. Payne, M. Sabou, M. Solanki,N. Srinivasan, and K. Sycara, “Bringing semantics to web services: The OWL-S approach,” presented at the First Int.Workshop on
Semantic Web Services andWeb Process Composition (SWSWPC 2004), San Diego, CA, 2004.
[25] T. Payne and O. Lassila, “Semantic web services,” IEEE Intell. Syst., vol. 19, no. 4, pp. 14–15, Jul.–Aug. 2004.
[26] D. Fensel and C. Bussler, “The web service modeling framework WSMF,” Electron. Commerce: Res. Appl., vol. 1, pp. 113–137,
2002.
[27] D. Fensel, V. R. Benjamins, E. Motta, and B. Wielinga, “UPML: A framework for knowledge system reuse,” presented at the Int.
Joint Conf. Artificial Intelligence (IJCAI-99), Stockholm, Sweden, 1999.
[28] E. Motta, J. Domingue, L. Cabral, and M. Gaspari, “IRS-II:A framework and infrastructure for semantic web services,”
presented at the 2nd Int. SemanticWeb Conf. (ISWC2003), Sanibel Island, FL, 2003.
[29] J. G. Frey, M. Bradley, J. W. Essex, M. B. Hursthouse, S. M. Lewis, M. M. Luck, L. Moreau, D. C. De Roure, M. Surridge, and
A. Welsh, “Combinatorial chemistry and the grid,” in Grid Computing—Making the Global Infrastructure a Reality, F. Berman, G.
Fox, and T. Hey, Eds. New York: Wiley, 2003, Wiley Series in Communications Networking and Distributed Systems, pp. 945–962.
[30] J. G. Frey, D. De Roure, and L. A. Carr, “Publication at source: Scientific communication from a publication web to a data grid,”
Euroweb 2002 Conf., TheWeb and the GRID: From e-Science to e-Business, 2002.
[31] G. Hughes, H. Mills, D. D. Roure, J. G. Frey, L. Moreau, M. Schraefel, G. Smith, and E. Zaluska, “The semantic smart
laboratory: A system for supporting the chemical escientist,” Org. Biomol. Chem., vol. 2, no. 22, pp. 3284–3293, 2004.
[32] M. C. Schraefel, G. Hughes, H. Mills, G. Smith, T. Payne, and J. Frey, “Breaking the book: Translating the chemistry lab book
into a pervasive computing lab environment,” presented at the 2004 Conf. Human Factors in Computing Systems (CHI 2004),
Vienna, Austria.
[33] “Scientific Publications: Free for All? Tenth Report of Session 2003–04,” Science and Technology Committee, UK Parliament
HC 399-1, 2004.
[34] P. Murray-Rust, “The world wide molecular matrix—A peer-to-peer XML repository for molecules and properties,” presented at
the EuroWeb2002, Oxford, U.K..
[35] J. D. Myers, T. C. Allison, S. Bittner, B. Didier, M. Frenklach, J. William, H. Green, Y.-L. Ho, J. Hewson,W. Koegler, C.
Lansing, D. Leahy, M. Lee, R. McCoy, M. Minkoff, S. Nijsure, G. V. Laszewski, D. Montoya, C. Pancerell, R. Pinzon,W. Pitz, L. A.
Rahn, B. Ruscic, K. Schuchardt, E. Stephan, A. Wagner, T. Windus, and C. Yang, “A collaborative informatics infrastructure for
multi-scale science,” presented at the Challenges of Large Applications in Distributed Environments (CLADE) Workshop, Honolulu,
HI, 2004.
[36] S. Buckingham Shum, D. De Roure, M. Eisenstadt, N. Shadbolt, and A. Tate, “CoAKTinG: Collaborative advanced knowledge
technologies in the grid,” presented at the Second Workshop on Advanced Collaborative Environments, Edinburgh, U.K., 2002.
[37] N. Shadbolt, P. Lewis, S. Dasmahapatra, D. Dupplaw, B. Hu, and H. Lewis, “MIAKT: Combining grid and web services for
collaborative medical decision making,” presented at the UK e-Science All Hands Meeting, Nottingham, U.K., 2004.
[38] I. Foster, C. Kesselman, J. Nick, and S. Tuecke, “Grid services for distributed system integration,” Computer, vol. 35, pp. 37–46,
2002.
[39] C. A. Goble and D. De Roure, “The grid: An application of the semantic web,” ACM SIGMOD Rec., vol. 31, pp. 65–70, 2002.
[40] C. Goble and D. De Roure, “The semantic web and grid computing,” in Real World Semantic Web Applications, Frontiers in
Artificial Intelligence and Applications, V. Kashyap and L. Shklar, Eds. Amsterdam, The Netherlands: IOS, 2002, vol. 92.
[41] M. Klein and U.Visser, “Semantic web challenge 2003,” IEEE Intell. Syst., vol. 19, no. 3, pp. 31–33, May–Jun. 2004.
[42] K. G. Jeffery, “Knowledge, Information and Data,” CLRC Information Technology Dept., Sep. 1999.
[43] M. Weiser, “The computer for the twenty-first century,” Sci. Amer., vol. 265, pp. 94–104, Sep. 1991.
[44] D. De Roure, “On self-organization and the semantic grid,” IEEE Intell. Syst., vol. 18, no. 4, pp. 77–79, Jul.–Aug. 2003.

