




































文档内容
拔高点突破 01 统计背景下的新定义问题
目录
01 方法技巧与总结...............................................................................................................................2
02 题型归纳与总结...............................................................................................................................3
题型一:新定义统计量或指标............................................................................................................3
题型二:新定义的统计方法或技术....................................................................................................7
题型三:新定义的数据可视化方法..................................................................................................10
题型四:综合应用题..........................................................................................................................15
03 过关测试.........................................................................................................................................22针对高中数学统计背景下的新定义问题,解题方法的总结可以从以下几个方面进行:
一、理解新定义的本质
首先,需要明确题目中的新定义是针对统计中的某一概念、方法或运算的拓展或创新。理解这一新定
义的本质属性、条件、结论以及适用范围是解题的第一步。这要求学生具备较强的阅读理解能力和抽象思
维能力,能够快速准确地把握新定义的核心内容。
二、联系已学知识
新定义问题往往不是孤立存在的,它们往往与已学的统计知识有着紧密的联系。因此,在理解新定义
的基础上,学生需要将其与已学的统计概念、方法或运算进行联系,找到它们之间的共同点和不同点。这
样不仅可以帮助学生更好地理解新定义,还可以为后续的解题提供思路和方法。
三、构建解题模型
对于统计背景下的新定义问题,构建解题模型是解决问题的关键。学生需要根据题目的具体要求和已
学知识,构建出适合解决该问题的统计模型。这个模型可以是基于某种统计分布的假设检验模型,也可以
是基于数据特征的描述统计模型。在构建模型的过程中,学生需要充分考虑新定义的条件和结论,确保模
型的准确性和有效性。
四、运用统计方法进行计算和分析
在构建好解题模型之后,学生需要运用统计方法进行计算和分析。这包括数据的收集、整理、描述、
推断等各个方面。在计算和分析的过程中,学生需要严格按照统计方法的步骤和要求进行操作,确保结果
的准确性和可靠性。同时,学生还需要注意对新定义条件的应用和理解,确保计算和分析过程符合题目要
求。
五、总结归纳
最后,学生需要对解题过程进行总结归纳。这包括对新定义的理解和应用情况的反思、对解题思路和
方法的总结以及对统计知识的巩固和拓展等方面。通过总结归纳,学生可以更好地掌握新定义问题的解题
方法,提高自己的统计素养和解题能力。
具体解题步骤建议
仔细阅读题目:理解题目中的新定义及其条件、结论等要素。
联系已学知识:将新定义与已学的统计知识进行联系和对比,找到它们之间的共同点和不同点。
构建解题模型:根据题目要求和已学知识构建解题模型,明确模型的假设条件、计算步骤和分析方法。
进行计算和分析:按照统计方法的步骤和要求进行计算和分析,确保结果的准确性和可靠性。
总结归纳:对解题过程进行总结归纳,反思解题过程中的得失和体会,巩固和拓展自己的统计知识。题型一:新定义统计量或指标
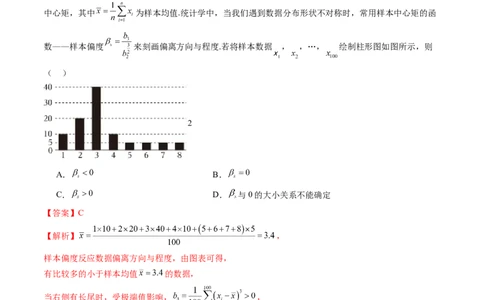
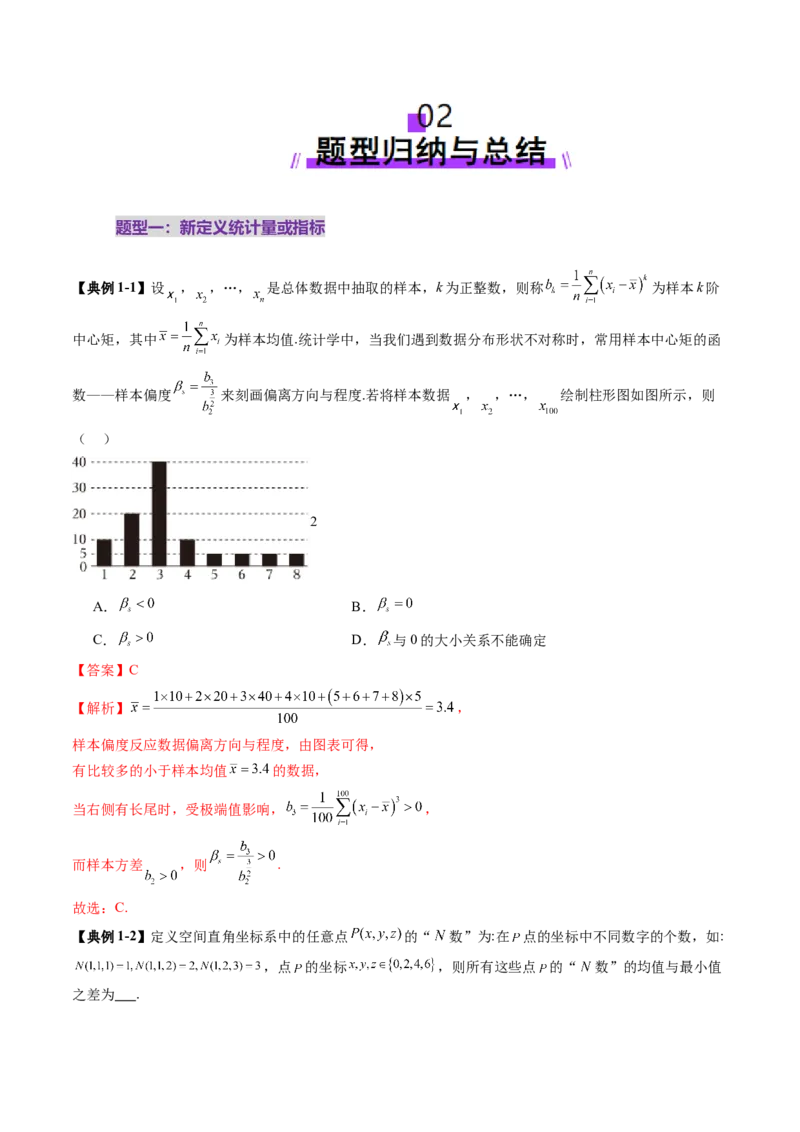
【典例1-1】设 , ,…, 是总体数据中抽取的样本,k为正整数,则称 为样本k阶
中心矩,其中 为样本均值.统计学中,当我们遇到数据分布形状不对称时,常用样本中心矩的函
数——样本偏度 来刻画偏离方向与程度.若将样本数据 , ,…, 绘制柱形图如图所示,则
( )
2
A. B.
C. D. 与0的大小关系不能确定
【答案】C
【解析】 ,
样本偏度反应数据偏离方向与程度,由图表可得,
有比较多的小于样本均值 的数据,
当右侧有长尾时,受极端值影响, ,
而样本方差 ,则 .
故选:C.
【典例1-2】定义空间直角坐标系中的任意点 的“ 数”为:在 点的坐标中不同数字的个数,如:
,点 的坐标 ,则所有这些点 的“ 数”的均值与最小值
之差为 .【答案】
【解析】由点 的坐标 ,可分三种情况讨论:
①恰有3个相同数字的排列为 种,则 共有4个;
②恰有2个相同数字的排列为 种,则 共有36个;
③3个数字各不相同的排列为 种,则 共有24个,
所以点 的“ 数”的平均值为 ,
则平均值与最小值之差为 .
故答案为: .
【变式1-1】(2024·河北·模拟预测)机器模型预测常常用于只有正确与错误两种结果的问题.表1为根据模
型预测结果与真实情况的差距的情形表格,定义真正例率 ,假正例率 .概率阈值为
自行设定的用于判别正(反)例的值,若分类器(分类模型)对该样例的预测正例概率大于等于设定的概率阈值,
则记分类器预测为正例,反之预测为反例.
预测结果
总例
正例 反例
真 正例 真正例 假反例
实
假正例
情
反例 真反例
况
表1分类结果样例划分
利用这些指标绘制出的ROC曲线可衡量模型的评价效果:将各样例的预测正例概率与 从大到小排序并
依次作为概率阈值,分别计算相应概率阈值下的 与 .以 为横坐标, 为纵坐标,得到标记点.依次连
接各标记点得到的折线就是ROC曲线.图1为甲分类器对于8个样例的ROC曲线,表2为甲,乙分类器对
于相同8个样例的预测数据.
甲分 乙分
样例数据
类器 类器
样例 样例 预测正 预测正
标号 属性 例概率 例概率
1 正例 0.23 0.342 正例 0.58 0.53
3 反例 0.15 0.13
4 反例 0.62 0.39
5 正例 0.47 0.87
6 反例 0.47 0.53
7 反例 0.33 0.11
8 正例 0.77 0.63
表2甲,乙分类器对于相同8个样例的预测数据
(1)当概率阈值为0.47时,求甲分类器的ROC曲线中的对应点;
(2)在图2中绘制乙分类器对应的ROC曲线(无需说明绘图过程),并直接写出甲,乙两分类器的ROC曲线
与 轴,直线 所围封闭图形的面积;
(3)按照上述思路,比较甲,乙两分类器的预测效果,并直接写出理想分类器的ROC曲线与 轴,直线
所围封闭图形的面积为1的充要条件.
【解析】(1)概率阈值为0.47时,
真正例为 ,假反例为 ,假正例为 ,真反例为 ,
则 .
所以横坐标 ,纵坐标 ,
故当概率阈值为0.47时,求甲分类器的ROC曲线中的对应点对应点为 .
(2)乙分类器对应的ROC曲线如下图所示.由已知题意可得,甲、乙分类器的ROC曲线都经过 ,
作如下图所示的辅助线,每个小直角三角形的面积都等于 ,
大直角三角形的面积都等于 ,故所求面积为 .
所以,甲分类器的ROC曲线与 轴,直线 所围封闭图形的面积为 .
作如下图所示的辅助线,同理可得所求面积为 .
所以,乙分类器的ROC曲线与 轴,直线 所围封闭图形的面积为 .
(3)乙分类器的预测效果更好.
由(2)分析可知,
乙分类器的ROC曲线与 轴,直线 所围封闭图形的面积较甲的大些,
故可认为乙分类器的预测效果更好.
充要条件:所有真实属性为正例的样例的预测正例概率的最小值大于所有真实属性为反例的样例的预测正例概率的最大值.
题型二:新定义的统计方法或技术
【典例2-1】(2024·河北衡水·一模)为检测出新冠肺炎的感染者,医学上可采用“二分检测法”,假设待
检测的总人数是 ,将 个人的样本混合在一起做第1轮检测(检测一次),如果检测结果为阴
性,可确定这批人未感染;如果检测结果为阳性,可确定其中有感染者,则将这批人平均分为两组,每组
人的样本混合在一起做第2轮检测,每组检测1次,如此类推,每轮检测后,排除结果为阴性的那组
人,而将每轮检测后结果为阳性的组再平均分成两组,做下一轮检测,直到检测出所有感染者(感染者必
须通过检测来确定),若待检测的总人数为8,采用“二分检测法”构测,经过4轮共7次检测后确定了
所有感染者,则感染者人数的所有可能值为 人.若待检测的总人数为 ,且假设其中有2名感
染者,采用“二分检测法”所需检测总次数记为n,则n的最大值为 .
【答案】 1,2 4m-1
【解析】①若待检测的总人数为8,则第一轮需检测1次;第2轮需检测2次,每次检查的均是4人组;第
3轮需检测2次,每次检查的是有感染的4人组均分的两组;第4轮需检测2次;则共需检测7次,此时感
染者人数为1或2人;
②若待检测的总人数为 ,且假设其中有不超过2名感染者,
若没有感染者,则只需1次检测即可;
若只有1个感染者,则只需 次检测;
若只有2个感染者,若要检测次数最多,则第2轮检测时,2个感染者不位于同一组,
此时相当两个待检测均为 的组,
每组1个感染者,此时每组需要 次检测,
所以此时两组共需 次检测,
故有2个感染者,且检测次数最多,共需 次检测,
所以采用“二分检测法”所需检测总次数记为n,则n的最大值为 .
故答案为:1,2;
【典例2-2】已知数据 的平均数为 ,设 为该组数据的“ 阶方
差”,若 ,则 与 的大小关系为( )
A. B. C. D.与 奇偶性有关
【答案】A
【解析】因为 ,所以 ,
因为 ,且 ,所以当 为偶数时, 为偶数,所以 ,
当 时, ;
当 时,则 ,所以 ,
综上, ,
所以 ,
当 为奇数时, 为奇数,所以 ,
当 时, ;
当 时,则 ,所以 ,
综上, ,
所以 ,
综上所述: .
故选:A
【变式2-1】已知样本 的平均数为 ,设 为该样本的“ 阶方差”,
则( )
A.
B.对任意 恒成立
C.当 为奇数时, 不可能为负数
D.若 ,则
【答案】D
【解析】对于A,因为 ,所以 ,故A错误;
对于B,取 ,则 ,故B错误;
对于C,由上述过程可知,C错误;
对于D,易知 ,因为 ,所以 ,所以
,故D正确.故选:D.
【变式2-2】(多选题)(2024·高三·湖北·期中)基于小汽车的“车均拥堵指数” ,其
取值范围是 ,值越大表明拥堵程度越强烈.在这个公式中, 为路段上统计时间间隔内车辆平均行驶
速度, 为路段上自由流状态下车辆行驶速度,且结合地图匹配算法可得到 ,其中 表示浮动
车 的速度.下列说法正确的是( )
A. 的值越大, 的值越小
B.若 ,则去掉 后得到的 的值变小
C.若 ,则去掉 后得到的 的值不变
D.若 ,则样本 的方差小于样本 的方差
【答案】BC
【解析】 的值与 的大小没有必然联系,无法确定 值的变化,故A错误;
若 ,则去掉 后 的值变大,因此 的值变小,故B正确;
若当 ,则去掉 后, 的值不变,得到的 的值不变,故C正确;
若 ,无法判断样本 的方差与样本 的方差之间的大小关系,故D错误.
故选:BC.
【变式2-3】(多选题)(2024·河北邯郸·三模)为了估计一批产品的不合格品率 ,现从这批产品中随机
抽取一个样本容量为 的样本 ,定义 ,于是 ,
, ,记 (其中 或1, ),称 表示
为参数的似然函数.极大似然估计法是建立在极大似然原理基础上的一个统计方法,极大似然原理的直
观想法是:一个随机试验如有若干个可能的结果A,B,C,…,若在一次试验中,结果A出现,则一般认
为试验条件对A出现有利,也即A出现的概率很大. 极大似然估计是一种用给定观察数据来评估模型参数
的统计方法,即“模型已定,参数未知”,通过若干次试验,观察其结果,利用试验结果得到某个参数值
能够使样本出现的概率为最大.根据以上原理,下面说法正确的是( )
A.有外形完全相同的两个箱子,甲箱有99个白球1个黑球,乙箱有1个白球99个黑球.今随机地抽
取一箱,再从取出的一箱中抽取一球,结果取得白球,那么该球一定是从甲箱子中抽出的
B.一个池塘里面有鲤鱼和草鱼,打捞了100条鱼,其中鲤鱼80条,草鱼20条,那么推测鲤鱼和草鱼
的比例为4:1时,出现80条鲤鱼、20条草鱼的概率是最大的
C.D. 达到极大值时,参数 的极大似然估计值为
【答案】BCD
【解析】极大似然是一种估计方法,A错误;
设鲤鱼和草鱼的比例为 ,则出现80条鲤鱼,20条草鱼的概率为 ,
设
,
时, , 时, ,
在 上单调递增,在 上单调递减,
故当 时, 最大,故B正确;
根据题意, (其中 或1, ),
所以 ,可知C正确;
令 ,解得 ,且 时 , 时 ,故 在
上递增,在 上递减,故 达到极大值时,参数 的极大似然估计值为 ,故
D正确.
故选:BCD
题型三:新定义的数据可视化方法
【典例3-1】 2021年,小李老师的亲戚准备购买一辆新的卡车用来跑运输,可选的车型主要有 种.分别为
, , , ,现在有 个指标:维修期限 ,百升汽油里数 ,最大载重吨数 ,价格 ,可能
性 ,灵敏性 来衡量,其中可靠性和灵敏性为评分,如下表.为了统一标准用来分析比较,小李老师将数据做了以下处理: .( 表示第 行第 列的原始数据, 表示第 行第 列的
原始数据 处理后的数据, 表示第 列的原始数据)
如果 用综合指标 来做标准,则 的综合指标 为( )
A. B. C. D.
【答案】D
【解析】根据题意可得, 的各项指标分别为 , , , , ,
所以 的综合指标 .
故选: .
【典例3-2】(2024·四川凉山·二模)高三模拟考试常常划定的总分各批次分数线,通过一定的数学模型,
确定不同学科在一本、二本等各批次“学科上线有双分”的分数线.考生总成绩达到总分各批次分数线的
称为总分上线;考生某一单科成绩达到及学科上线有双分的称为单科上线.学科对总分的贡献或匹配程度
评价有很大的意义.利用“学科对总分上线贡献率” 和“学科有效分上线命中
率” 这两项评价指标,来反映各学科的单科成绩对考生总分上线的贡献与匹配程度,
这对有效安排备考复习计划具有十分重要的意义.某州一诊考试划定总分一本线为465分,数学一本线为
104分,某班一小组的总分和数学成绩如表,则该小组“数学学科对总分上线贡献率、有效分上线命中
率”分别是( )(结果保留到小数点后一位有效数字)
学
生
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
编
号
数
12 11 12 10 10 11 11 10 10 11 10
99 89 98 92 84 94 97 85 85
学
0 7 2 1 0 2 1 2 0 3 4
成绩
总
分 49 49 49 48 48 48 48 48 47 47 47 47 46 45 45 45 44 44 44 44
成 5 4 3 5 3 3 2 0 9 5 1 0 3 7 4 3 8 8 1 0
绩
A.41.7%,71.4% B.60%,71.4%
C.41.7%,35% D.60%,35%
【答案】A
【解析】由图表知双过线人数为5人,单过线人数为7人,总分过线人数为12人;
“学科对总分上线贡献率”为 ,
“学科有效分上线命中率”为 ,
故选:A.
【变式3-1】某省新高考中选考科目采用赋分制,具体转换规则和步骤如下:第一步,按照考生原始分从
高到低按成绩比例划定 、 、 、 、 共五个等级(见下表).第二步,将 至 五个等级内的考生原
始分,依照等比例转换法则,分别对应转换到100~86、85~71、70~56、55~41和40~30五个分数段,
从而将考生的等级转换成了等级分.
等级
比例 15% 35% 35% 13% 2%
70-
赋分区间 100-86 85-71 55-41 40-30
56
赋分公式: ,计算出来的 经过四舍五人后即
为赋分成绩.
某次考试,化学成绩 等级的原始最高分为98分,最低分为63分.学生甲化学原始成绩为76分,则该学
生的化学赋分分数为( )
A.85 B.88 C.91 D.95
【答案】C
【解析】由题意,该学生的化学赋分分数为 ,则 ,
所以 分.
故选:C
【变式3-2】某公司有甲乙两条生产线生产同一种产品,为了解产品的质量情况,对两条生产线生产的产品进行简单随机抽样,经检测得到了A、B的两项质量指标值,记为 ,定义产品的指标偏差
,数据如下表:
甲生产线抽样产品编
号 1 2 3 4 5 6 7 8 9 10
指标
0.98 0.96 1.07 1.02 0.99 0.93 0.92 0.96 1.11 1.02
2.01 1.97 1.96 2.03 2.04 1.98 1.95 1.99 2.07 2.02
0.03 0.07 0.11 0.05 0.05 0.09 0.13 0.05 0.18 0.04
乙生产线抽样产品编号
1 2 3 4 5 6 7 8
指标
0.9
1.02 0.97 0.95 0.94 1.13 0.98 1.01
7
2.1
2.01 2.03 2.15 1.93 2.01 2.02 2.04
9
0.2
0.03 0.06 0.20 0.13 0.14 0.04 0.05
2
假设用频率估计概率,且每件产品的质量相互独立.
(1)从甲生产线上随机抽取一件产品,估计该产品满足 且 的概率;
(2)从甲乙两条生产线上各随机抽取一件产品,设 表示这两件产品中满足 的产品数,求 的分布
列和数学期望 ;
(3)已知 的值越小则该产品质量越好.如果甲乙两条生产线各生产一件产品,根据现有数据判断哪条生产
线上的产品质量更好?并说明理由.
【解析】(1)记 表示“从甲生产线上随机抽取一件产品,该产品满足 且 ”.
用频率估计概率,则 .
所以该产品满足 且 的概率为 .
(2)由表格数据,用频率估计概率,
可得“从甲生产线上随机抽取一件产品,该产品满足 ”的概率为 ;
“从乙生产线上随机抽取一件产品,该产品满足 ”的概率为 .由题意, 的所有可能取值为 .
,
.
所以 的分布列为
0 1 2
所以 的数学期望为 .
(3)甲生产线上的产品质量更好,
因为甲生产线上 值的平均值
,
乙生产线上 值的平均值 ,
所以甲生产线上 值的平均值明显比乙小,
所以甲生产线上的产品质量更好.
其它理由:从甲乙两生产线的样本中各随机取一件,则
甲生产品的 值小于乙的概率为 ,
所以甲生产线上的产品质量更好.
【变式3-3】定义: 为不超过 的最大整数部分,如 , .甲、乙两个学生
高二的6次数学测试成绩(测试时间为90分钟,满分100分)如下表所示:
高二成绩 第1次考试 第2次考试 第3次考试 第4次考试 第5次考试 第6次考试
甲 68 74 77 84 88 95
乙 71 75 82 84 86 94
进入高三后,由于改进了学习方法,甲、乙这两个学生的数学测试成绩预计有了大的提升.设甲或乙高二
的数学测试成绩为 ,若 ,则甲或乙高三的数学测试成绩预计为
;若 ,则甲或乙高三的数学测试成绩预计为
100.
(1)试预测:在将要进行的高三6次数学测试成绩(测试时间为90分钟,满分100分)中,甲、乙两个学生
的成绩(填入下列表格内);高三成绩 第1次考试 第2次考试 第3次考试 第4次考试 第5次考试 第6次考试
甲
乙
(2)记高三任意一次数学测试成绩估计值为 ,规定: ,记为转换分为3分; ,记为转
换分为4分; ,记为转换分为5分.现从乙的6次数学测试成绩中任意抽取2次,求这2次成绩
的转换分之和为8分的概率.
【解析】(1)由已知,预测高三6次数学测试成绩如下:
高三成绩 第1次考试 第2次考试 第3次考试 第4次考试 第5次考试 第6次考试
甲 84 90 93 93 97 100
乙 87 91 91 93 95 100
(2)在乙的高三6次数学测试预测成绩中,转换分为3分的有1次,记为A;
转换分为4分的有4次,记为 ;转换分为5分的有1次,记为 .
现从中任意抽取2次,一共有15种结果,它们是:
,
,
其中2次成绩的转换分之和为8分有7种结果,它们是:
,
则所求概率为 .
题型四:综合应用题
【典例4-1】(2024·高三·浙江·开学考试)一般地, 元有序实数对 称为 维向量.对于两个
维向量 ,定义:两点间距离 ,利
用 维向量的运算可以解决许多统计学问题.其中,依据“距离”分类是一种常用的分类方法:计算向量与
每个标准点的距离 ,与哪个标准点的距离 最近就归为哪类.某公司对应聘员工的不同方面能力进行测
试,得到业务能力分值 、管理能力分值 、计算机能力分值 、沟通能力分值 (分值
代表要求度,1分最低,5分最高)并形成测试报告.不同岗位的具体要求见下表:业务能力分值 管理能力分值 计算机能力分值 沟通能力分值 合计分
岗位
值
会计(1) 2 1 5 4 12
业务员
5 2 3 5 15
(2)
后勤(3) 2 3 5 3 13
管理员
4 5 4 4 17
(4)
对应聘者的能力报告进行四维距离计算,可得到其最适合的岗位.设四种能力分值分别对应四维向量
的四个坐标.
(1)将这四个岗位合计分值从小到大排列得到一组数据,直接写出这组数据的第三四分位数;
(2)小刚与小明到该公司应聘,已知:只有四个岗位的拟合距离的平方 均小于20的应聘者才能被招录.
(i)小刚测试报告上的四种能力分值为 ,将这组数据看成四维向量中的一个点,将四种职业
的分值要求看成样本点,分析小刚最适合哪个岗位;
(ii)小明已经被该公司招录,其测试报告经公司计算得到四种职业 的推荐率 分别为
,试求小明的各项能力分值.
【解析】(1)将四个岗位合计分值从小到大排列得到数据 ,
又 ,所以这组数据的第三四分位数为 .
(2)(i)由图表知,会计岗位的样本点为 ,则 ,
业务员岗位的样本点为 ,则 ,
后勤岗位的样本点为 ,则 ,
管理员岗位的样本点为 ,则 ,
所以 ,故小刚最适合业务员岗位.
(ii)四种职业 的推荐率 分别为 ,且 ,所以 ,得到 ,
又 均小于20,所以 ,且 ,
故可得到 ,
设小明业务能力分值、管理能力分值、计算机能力分值、沟通能力分值分别为 ,且 ,
,
依题有 ①,
②,
③,
④,
由① ③得,
,
整理得: ,
故有 三组正整数解,
对于第一组解,代入④式有 ,不成立;
对于第二组解,代入①式有 ,
解得 或 ,代入②④式均不成立;
对于第三组解,代入②式有 ,
解得 ,代入①②③④均成立,故 ;
故小明业务能力分值、管理能力分值、计算机能力分值、沟通能力分值分别为 .
【典例4-2】设离散型随机变量X和Y有相同的可能取值,它们的分布列分别为 ,, , , .指标 可用来刻画X和Y的相似程
度,其定义为 .设 .
(1)若 ,求 ;
(2)若 ,求 的最小值;
(3)对任意与 有相同可能取值的随机变量 ,证明: ,并指出取等号的充要条件
【解析】(1)不妨设 ,则 .
所以
.
(2)当 时, ,
记
,
则
,
令 ,则 ,
令 ,则 ,
当 时, , 单调递减;
当 时, , 单调递增;
所以 ,则 单调递增,而 ,
所以 在 为负数,在 为正数,
则 在 单调递减,在 单调递增,所以 的最小值为 .
(3)令 ,则 ,
当 时, , 单调递增;
当 时, , 单调递减;
所以 ,即 ,当且仅当 时,等号成立,
则当 时, ,所以 ,即 ,
故 ,
当且仅当对所有的 时等号成立.
【变式4-1】给定两组数据 与 ,称 为这两组数据之间
的“差异量”.鉴宝类的节目是当下非常流行的综艺节目.现有 个古董,它们的价值各不相同,最值钱
的古董记为1号,第二值钱的古董记为2号,以此类推,则古董价值的真实排序为 .现在某
专家在不知道古董真实排序的前提下,根据自己的经验对这 个古董的价值从高到低依次进行重新排序为
,其中 为该专家给真实价值排第 位古董的位次编号,记 ,那么 与 的差
异量 可以有效反映一个专家的水平,该差异量 越小说明专家的鉴宝能力越强.
(1)当 时,求 的所有可能取值;
(2)当 时,求满足 的 的个数;
(3)现在有两个专家甲、乙同时进行鉴宝,已知专家甲的鉴定结果与真实价值 的差异量为 ,专家甲与专
家乙的鉴定结果的差异量为4,那么专家乙的鉴定结果与真实价值 的差异量是否可能为 ?请说明理
由.
(注:实数 满足: ,当且仅当 时取“ ”号)
【解析】(1)若 时,则 ,且 ,
可得 ,
所以 的所有可能取值为0,2,4.
(2)若对调两个位置的序号之差大于2,则 ,
可知 只能调整两次两个连续序号或连续三个序号之间调整顺序,
若调整两次两个连续序号:则有 ,共有3种可能;若连续三个序号之间调整顺序,连续三个序号有: ,共3组,
由(1)可知:每组均有3种可能满足 ,可得共有 种可能;
所以 的个数为 .
(3)不可能,理由如下:
设专家甲的排序为 ,记 ;
专家乙的排序为 ,记 ;
由题意可得: , ,
因为 ,
结合 的任意性可得 ,
所以专家乙的鉴定结果与真实价值I的差异量不可能为 .
【变式4-2】将2024表示成7个正整数 之和,得到方程
①,称七元有序数组 为方程①的解,对于上述的七
元有序数组 ,当 时,若 ),则称
是 密集的一组解.
(1)方程①是否存在一组解 ,使得 等于同一常数?
若存在,请求出该常数,若不存在,请说明理由;
(2)方程①的解中共有多少组是 密集的?
(3)记 ,问S是否存在最小值?若存在,请求出S的最小值:若不存在,请说明理由.
【解析】(1)若 等于同一常数,
根据等差数列的定义可得 构成等差数列,
所以 ,
解得 ,与 矛盾,
所以不存在一组解 ,
使得 等于同一常数;
(2)因为平均数 ,
依题意 时,即当 时, ,所以 , ,
设有 个 ,则有 个 ,
由 ,解得 ,
所以 中有 个 , 个 ,
所以方程①的解共有 组;
(3)因为平均数 ,
又方差 ,即 ,
所以 ,因为 为常数,所以当方差 取最小值时 取最小值,
又当 时, ,
即 ,方程无正整数解,故舍去;
当 时,即 是 密集时, 取得最小值,
且 .
【变式4-3】已知数据 , ,…, 的平均数为 ,方差为 ,数据 , ,…, 的平均数为 ,方
差为 .类似平面向量,定义n维向量 , 的模
, ,数量积 .若向量 与 所成角为
,有恒等式 ,其中 , .
(1)当 时,若向量 , ,求 与 所成角的余弦值;
(2)当 时,证明:① ;② ;
(3)当 , 时,探究 与 的大小关系,并证明.
【解析】(1) ;
(2)①当 时,
;
②;
(3) ,理由如下:
当 , 时,
,
同理可得 ,
则
.
1.(2024·高三·北京丰台·期末)市场占有率指在一定时期内,企业所生产的产品在其市场的销售量(或
销售额)占同类产品销售量(或销售额)的比重.一般来说,市场占有率会随着市场的顾客流动而发生变
化,如果市场的顾客流动趋向长期稳定,那么经过一段时期以后的市场占有率将会出现稳定的平衡状态
(即顾客的流动,不会影响市场占有率),此时的市场占有率称为“稳定市场占有率”.有A,B,C三个
企业都生产某产品,2022年第一季度它们的市场占有率分别为:40%,40%,20%.经调查,2022年第二
季度A,B,C三个企业之间的市场占有率转移情况如图所示,若该产品以后每个季度的市场占有率转移情
况均与2022年第二季度相同,则当市场出现稳定的平衡状态,最终达到“稳定市场占有率”时,A企业该
产品的“稳定市场占有率”为( )A.45% B.48% C.50% D.52%
【答案】C
【解析】由题意,设最终达到“稳定市场占有率”时,A企业该产品的“稳定市场占有率”为 ,B,C两
个企业的“稳定市场占有率”为 ,
则 ,
故 ,即 ,
所以 ,解得 .
故选:C.
2.(多选题)为了解决传统的3D人脸识别方法中存在的不精确问题,科学家提出了一种基于视频分块聚
类的格拉斯曼流形自动识别系统.规定:某区域内的m个点 的深度 的均值 ,标准偏
差为 ,深度 的点视为孤立点,下表给出了某区域内的8个点的数据,
则( )
15.
15.1 15.3 15.4 15.5 15.4 15.4 13.4
2
14.
15.1 14.3 14.4 14.5 15.4 14.4 15.4
2
20 12 13 15 16 14 12 18
A. B. C. 不是孤立点 D. 和 是孤立点
【答案】BC
【解析】由题可得 ,B对;
,A错;, ,则 ,
, ,所以, 、 都不是孤立点,C对,D错.
故选:BC.
3.(2024·北京西城·二模)为研究中国工业机器人产量和销量的变化规律,收集得到了 年工业
机器人的产量和销量数据,如下表所示.
年份
产量万
台
销量万
台
记 年工业机器人产量的中位数为 ,销量的中位数为 .定义产销率为“ ”.
(1)从 年中随机取 年,求工业机器人的产销率大于 的概率;
(2)从 年这 年中随机取 年,这 年中有 年工业机器人的产量不小于 ,有 年工业机器人的
销量不小于 .记 ,求 的分布列和数学期望 ;
(3)从哪年开始的连续 年中随机取 年,工业机器人的产销率超过 的概率最小.结论不要求证明
【解析】(1)记事件 为“工业机器人的产销率大于 ”.
由表中数据,工业机器人的产销率大于 的年份为 年, 年, 年, 年,共 年.
所以 .
(2)因为 , ,
所以 的所有可能的取值为 ; 的所有可能的取值为 .
所以 的所有可能的取值为 .
, , .
所以 的分布列为:
故 的数学期望 .
(3)2018年和 年.4.(2024·福建泉州·模拟预测)定义两组数据 , 的“斯皮尔曼系数”为变量 在该组数
据中的排名 和变量 在该组数据中的排名 的样本相关系数,记为 ,其中 .
某校15名学生的数学成绩的排名与知识竞赛成绩的排名如下表:
1 1 1
1 2 3 4 5 6 7 8 9 11 13 15
0 2 4
1
1 5 3 4 9 8 7 6 10 2 12 13 11 15
4
(1)试求这15名学生的数学成绩与知识竞赛成绩的“斯皮尔曼系数”;
(2)已知在这15名学生中有10人数学成绩优秀,现从这15人中随机抽取3人,抽到数学成绩优秀的学生有
人,试求 的分布列和数学期望.
【解析】(1)依题意, ,
所以这15名学生的数学成绩与知识竞赛成绩的“斯皮尔曼系数”是0.8.
(2)依题意, 的值可能为0,1,2,3,
,
,
则 的分布列为:
0 1 2 3
所以 的数学期望为 .
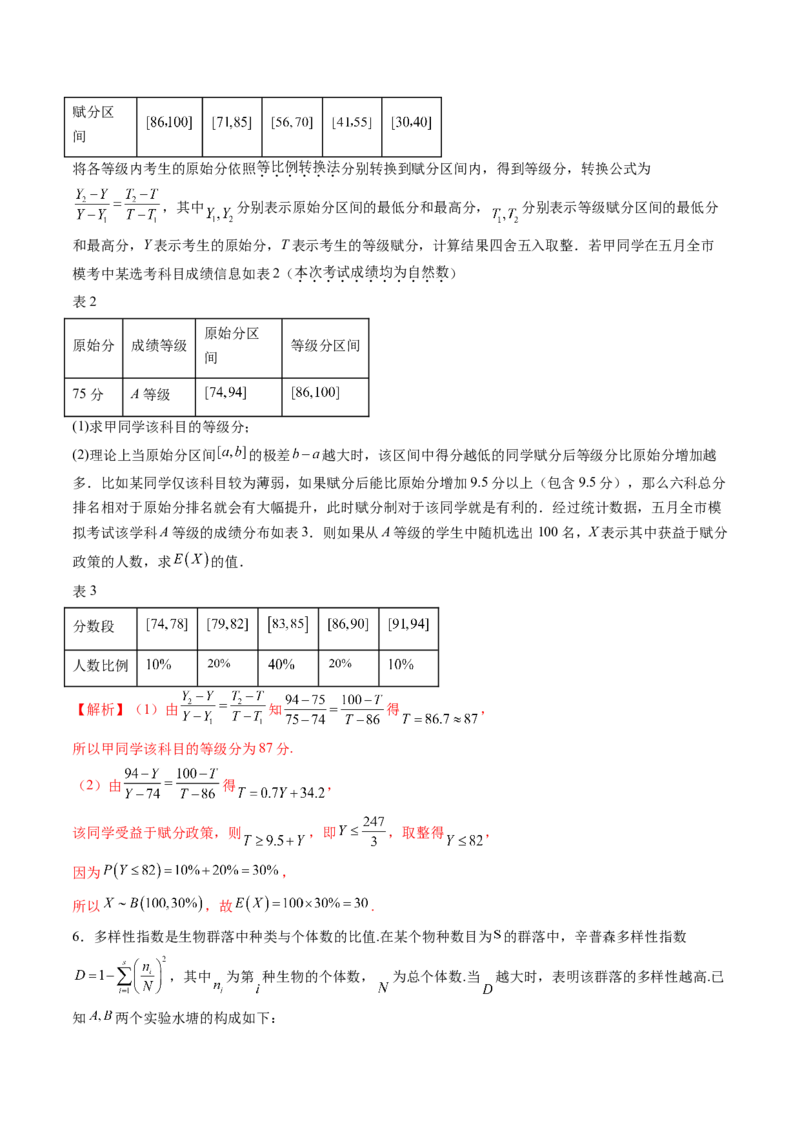
5.(2024·安徽芜湖·模拟预测)安徽省从2024年起实施高考综合改革,实行高考科目“ ”模式.
“2”指考生从政法、地理、化学、生物四门学科中“再选”两门学科,以等级分计入高考成绩.按照方案,
再选学科的等级分赋分规则如下,将考生原始成绩从高到低划分为A,B,C,D,E五个等级,各等级人
数所占比例及赋分区间如表1:
表1
等级 A B C D E
人数比
例赋分区
间
将各等级内考生的原始分依照等比例转换法分别转换到赋分区间内,得到等级分,转换公式为
,其中 分别表示原始分区间的最低分和最高分, 分别表示等级赋分区间的最低分
和最高分,Y表示考生的原始分,T表示考生的等级赋分,计算结果四舍五入取整.若甲同学在五月全市
模考中某选考科目成绩信息如表2(本次考试成绩均为自然数)
表2
原始分区
原始分 成绩等级 等级分区间
间
75分 A等级
(1)求甲同学该科目的等级分;
(2)理论上当原始分区间 的极差 越大时,该区间中得分越低的同学赋分后等级分比原始分增加越
多.比如某同学仅该科目较为薄弱,如果赋分后能比原始分增加9.5分以上(包含9.5分),那么六科总分
排名相对于原始分排名就会有大幅提升,此时赋分制对于该同学就是有利的.经过统计数据,五月全市模
拟考试该学科A等级的成绩分布如表3.则如果从A等级的学生中随机选出100名,X表示其中获益于赋分
政策的人数,求 的值.
表3
分数段
人数比例
【解析】(1)由 知 得 ,
所以甲同学该科目的等级分为87分.
(2)由 得 ,
该同学受益于赋分政策,则 ,即 ,取整得 ,
因为 ,
所以 ,故 .
6.多样性指数是生物群落中种类与个体数的比值.在某个物种数目为 的群落中,辛普森多样性指数
,其中 为第 种生物的个体数, 为总个体数.当 越大时,表明该群落的多样性越高.已
知 两个实验水塘的构成如下:绿藻 衣藻 水绵 蓝藻 硅藻
6 6 6 6 6
12 4 3 6 5
(1)若从 中分别抽取一个生物个体,求两个生物个体为同一物种的概率;
(2)(i)比较 的多样性大小;
(ii)根据(i)的计算结果,分析可能影响群落多样性的因素.
【解析】(1)记事件 为“两个生物个体为同一物种”,
则 发生的概率为 .
(2)(i)由表可知
所以 , ;
即 ,故 的多样性大于 ;
(ii)在(i)中两群落物种数目相同,各物种数量不同,而 中各物种数量均相同,
即物种均匀度更大,分析可得物种均匀度也会影响群落多样性.
7.从2021年秋季学期起,黑龙江省启动实施高考综合改革,实行高考科目“3+1+2”模式.“3”指语文、数
学、外语三门统考学科,以原始分数计入高考成绩;“1”指考生从物理、历史两门学科中“首选”一门学
科,以原始分数计入高考成绩;“2”指考生从政治、地理、化学、生物四门学科中“再选”两门学科,以
等级分计入高考成绩.按照方案,再选学科的等级分赋分规则如下,将考生原始成绩从高到低划分为A,
B,C,D,E五个等级,各等级人数所占比例及赋分区间如下表:
等级 A B C D E
人数比例
赋分区间
将各等级内考生的原始分依照等比例转换法分别转换到赋分区间内,得到等级分,转换公式为
,其中 分别表示原始分区间的最低分和最高分, 分别表示等级赋分区间的最低分
和最高分, 表示考生的原始分, 表示考生的等级分,规定原始分为 时,等级分为 .某次化学考试的
原始分最低分为50,最高分为98,呈连续整数分布,其频率分布直方图如下:(1)根据频率分布直方图,求 ,并估计此次化学考试原始分的平均值;
(2)按照等级分赋分规则,估计此次考试化学成绩A等级的原始分区间;
(3)用估计的结果近似代替原始分区间,若某学生化学成绩的原始分为88,试计算其等级分(计算结果四舍
五入取整).
【解析】(1)由 ,可得 ,
故此次化学考试成绩的平均值为 分
(2)由频率分布直方图知,原始分成绩位于区间 的占比为 ,位于区间 的占比为 ,
因为成绩A等级占比为 ,所以等级A的原始分区间的最低分位于区间 ,
估计等级A的原始分区间的最低分为 ,
已知最高分为98,所以估计此次考试化学成绩A等级的原始分区间为 .
(3)由 ,解得 ,该学生的等级分为89分.
8.(2024·全国·模拟预测)某校20名学生的数学成绩 和知识竞赛成绩 如
下表:
学生编号 1 2 3 4 5 6 7 8 9 10
10 8
数学成绩 99 96 93 90 85 83 80 77
0 8
29 22 7
知识竞赛成绩 160 200 65 90 100 60 270
0 0 0
1
学生编号 11 12 13 14 15 17 18 19 20
6
6
数学成绩 75 74 72 70 68 60 50 39 35
6
3
知识竞赛成绩 45 35 40 50 25 20 15 10 5
0计算可得数学成绩的平均值是 ,知识竞赛成绩的平均值是 ,并且 ,
, .
(1)求这组学生的数学成绩和知识竞赛成绩的样本相关系数(精确到 ).
(2)设 ,变量 和变量 的一组样本数据为 ,其中 两两不相同,
两两不相同.记 在 中的排名是第 位, 在 中的排
名是第 位, .定义变量 和变量 的“斯皮尔曼相关系数”(记为 )为变量 的排名和变
量 的排名的样本相关系数.
(i)记 , .证明: .
(ii)用(i)的公式求这组学生的数学成绩和知识竞赛成绩的“斯皮尔曼相关系数”(精确到 ).
(3)比较(1)和(2)(ii)的计算结果,简述“斯皮尔曼相关系数”在分析线性相关性时的优势.
注:参考公式与参考数据. ; ; .
【解析】(1)由题意,这组学生数学成绩和知识竞赛成绩的样本相关系数为
(2)(i)证明:因为 和 都是1,2, , 的一个排列,所以
,
,
从而 和 的平均数都是 .
因此, ,
同理可得 ,
由于,
所以 ;
(ii)由题目数据,可写出 与 的值如下:
同学编号 1 2 3 4 5 6 7 8 9 10
数学成绩排名 1 2 3 4 5 6 7 8 9 10
1
知识竞赛成绩排名 1 5 3 4 9 8 7 6 2
0
1 1
同学编号 11 12 13 14 16 17 18 20
5 9
1 1
数学成绩排名 11 12 13 14 16 17 18 20
5 9
1 1 1
知识竞赛成绩排名 14 13 11 15 17 18 20
2 6 9
所以 ,并且 .
因此这组学生的数学成绩和知识竞赛成绩的斯皮尔曼相关系数是
(3)答案①:斯皮尔曼相关系数对于异常值不太敏感,如果数据中有明显的异常值,那么用斯皮尔曼相
关系数比用样本相关系数更能刻画某种线性关系;
答案②:斯皮尔曼相关系数刻画的是样本数据排名的样本相关系数,与具体的数值无关,只与排名有关.
如果一组数据有异常值,但排名依然符合一定的线性关系,则可以采用斯皮尔曼相关系数刻画线性关系.
9.某种人脸识别方法,采用了视频分块聚类的自动识别系统.规定:某区域内的 个点 的深度
的均值为 ,标准差为 ,深度 的点视为孤立点.下表给出
某区域内8个点的数据:
15.
15.1 15.3 15.4 15.5 15.4 15.4 13.8
214.
15.1 14.3 14.4 14.5 15.4 14.4 15.4
2
20 12 13 15 16 14 12 18
(1)根据以上数据,计算 的值;
(2)判断表中各点是否为孤立点.
【解析】(1) ,
.
(2) , ,
则 ,
因为12,13,14,15,16,18,20均属于 ,所以各点都不是孤立点.
10.(2024·江西吉安·一模)党的二十大报告提出,要推进健康中国建设,把保障人民健康放在优先发展
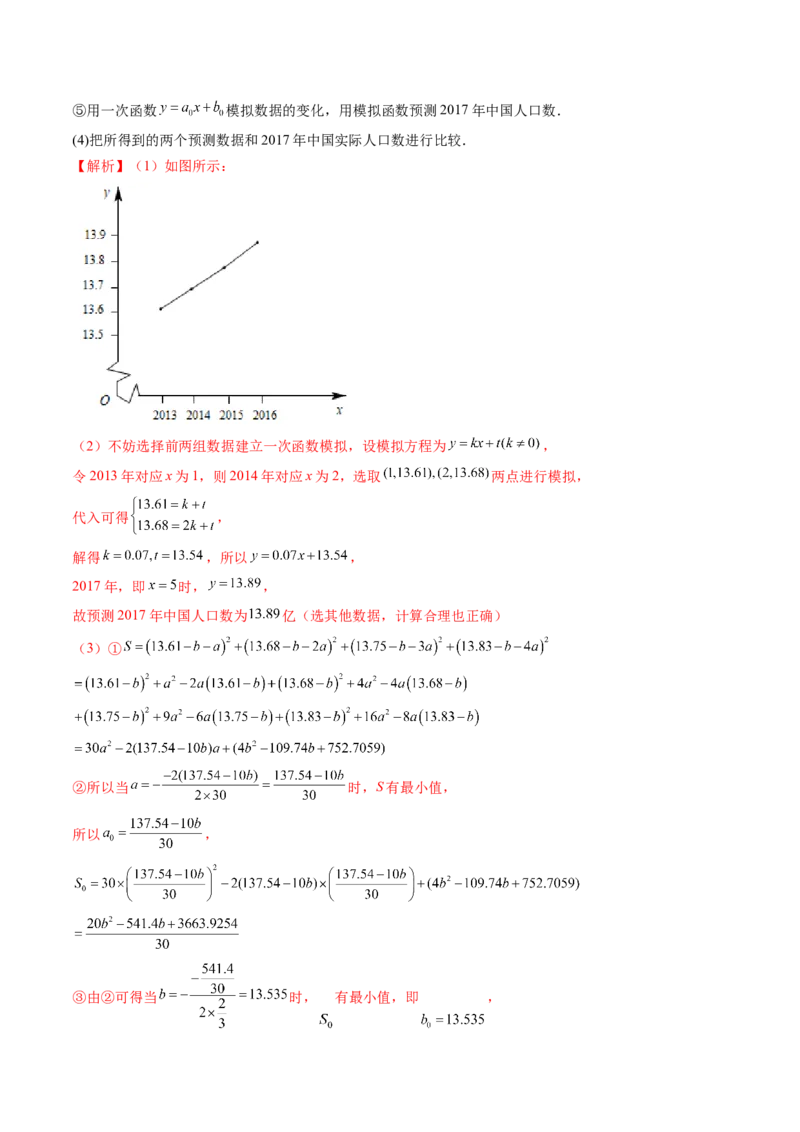
的战略位置,完善人民健康促进政策.《国务院关于印发全民健身计划( — 年)的通知》中指出,
深入实施健康中国战略和全民健身国家战略,加快体育强国建设,构建更高水平的全民健身公共服务体系,
充分发挥全民健身在提高人民健康水平、促进人的全面发展、推动经济社会发展、展示国家文化软实力等方
面的综合价值与多元功能.如图为 年~ 年( 年的年份序号为 )我国健身人数(百万人)变化
情况的折线图:
统计学中的样本点具有二重性,样本是可以观测的随机变量,本题将 和 视为两个随机变量且以上数据
图中的每个样本点的产生的概率都是 ,已知 ,其中 表示 的平均数.
参考数据及公式: . 和 两个随机变量之间的皮尔逊相关系数为,线性回归方程 中, .
(1)求回归方程 的皮尔逊相关系数(保留 位有效数字);
(2)求 关于 的回归方程.
【解析】(1)由折线图可得: , ,
, , ,
.
(2)设线性回归方程为 ,
则 ,
,
关于 的回归方程为 .
11.(2024·湖南郴州·三模)chatGPT是由OpenAI开发的一款人工智能机器人程序,一经推出就火遍全球.
chatGPT的开发主要采用RLHF(人类反馈强化学习)技术,训练分为以下三个阶段.
第一阶段:训练监督策略模型.对抽取的prompt数据,人工进行高质量的回答,获取数据
对,帮助数学模型GPT-3.5更好地理解指令.
第二阶段:训练奖励模型.用上一阶段训练好的数学模型,生成 个不同的回答,人工标注排名,通过奖励
模型给出不同的数值,奖励数值越高越好.奖励数值可以通过最小化下面的交叉熵损失函数得到:
,其中 ,且 .
第三阶段:实验与强化模型和算法.通过调整模型的参数,使模型得到最大的奖励以符合人工的选择取向.
参考数据:
(1)若已知某单个样本,其真实分布 ,其预测近似分布
,计算该单个样本的交叉熵损失函数Loss值.
(2)绝对值误差MAE也是一种比较常见的损失函数,现已知某 阶变量的绝对值误差, ,
其中 , 表示变量的阶.若已知某个样本是一个三阶变量的数阵,其真实分布是 ,现已知其预测分布为 ,求证:该变量的绝
对值误差 为定值.
(3)在测试chatGPT时,如果输入问题没有语法错误chatGPT的回答被采纳的概率为 ,当出现语法错误
时,chatGPT的回答被采纳的概率为 .现已知输入的问题中出现语法错误的概率为 ,现已知
chatGPT的回答被采纳,求该问题的输入语法没有错误的概率.
【解析】(1)由题意,该单个样本的交叉嫡损失函数:
.
(2)根据定义,该三阶变量的绝对值误差为
.
(3)记事件A:chatGPT中输入的语法无错误;事件B:chatGPT中输入的语法有错误;事件C:chatGPT
的回答被采纳.
依题意: ,
所以 .
12.某抽奖系统中,抽得的物品可分为 星, 星和 星,其中一种抽奖种类中的抽奖系统的概率和相关保
底机制如下:
物品类别 星 星 星
基础概率
基础概率:在没有任何其他机制的影响下,单次抽奖抽中指定类别奖品的概率.
保底机制:现假定玩家 从未进行过抽奖,则玩家抽取 星(或 星)的概率会随者未抽中 星(或 星)
的次数增加而改变,相关机制如下表所示:
连续未抽中 星的次数
下一次抽中 星的概率
连续未抽中 星的次数
下一次抽中 星的概率
注:① 表示 , 中的最小值:
②抽中 星的概率和抽中 星的概率的增加值从抽中 星的概率中等量扣除;
③若发现下一次抽奖中,抽中 星的概率和抽中 星的概率的和大于 ,则下一次抽奖抽中 星的概率等于表中的值(记为 ),而抽中 星的概率为 .
现记玩家 获得 个 星物品所需要的最大抽奖次数为 ;
统计 名玩家 抽到第一个五星的总次数和中途抽到四星的次数如下表所示:
玩家序号
总次数
四星个数
计算得: , , , ,已知 与 之间存在很强的线性相关关系,求出
其线性回归方程,并求出使得 最小的 (回归方程中的 和 取两位小数)
参考公式:回归直线方程 斜率和截距的最小二乘估计公式分别为: ,
.
【解析】因为 ,代入数据得: ,
所以 ,
所以y与x的线性回归方程为 .
当连续未抽中5星的次数 ,下一次抽中5星的概率为0.600%,
所以下一次可能抽不中5星;当连续未抽中5星的次数 ,
下一次抽中5星的概率 0.600%,
由 有: ,
所以玩家 获得1个5星物品所需要的最大抽奖次数为73.
所以 ,
由 有: ,
所以使得 最小的x为8.
13.(2024·山西太原·三模)在学业测试中,客观题难度的计算公式为 ,其中 为第i题的难度,
为答对该题的人数,N为参加测试的总人数.现对某校高三年级240名学生进行一次测试,共5道客观题.
测试前根据对学生的了解,预估了每道题的难度,如下表所示:
题号 1 2 3 4 5考前预估难度 0. 0.
0.9 0.7 0.4
8 6
测试后,随机抽取了20名学生的答题数据进行统计,结果如下
题号 1 2 3 4 5
实测答对人 1 1
16 14 8
数 6 4
(1)根据题中数据,估计这240名学生中第5题的实测答对人数;
(2)定义统计量 ,其中 为第i题的实测难度, 为第i题的预估
难度(i=1,2,…,n).规定:若 ,则称该次测试的难度预估合理,否则为不合理.试据此判断本次测
试的难度预估是否合理.
【解析】(1)因为第5题的实测难度为
所以估计这240名学生中第5题的实测答对人数为 (人).
(2)根据题干中数据可得: ,
故 ,
.
故本次测试的难度所估合理.
14.某校在学年期末举行“我最喜欢的文化课”评选活动,投票规则是一人一票,高一(1)班44名学生
和高一(7)班45名学生的投票结果如表(无废票):
数 政
语文 外语 物理 化学 生物 历史 地理
学 治
高一(1)班 6 9 7 5 4 5 3 3 2
高一(7)班 a 7 b 4 5 6 5 2 3
该校把上表的数据作为样本,把两个班同一学科的得票之和定义为该年级该学科的“好感指数”.
(1)如果数学学科的“好感指数”比高一年级其他文化课都高,求 的所有取值;
(2)从高一(1)班投票给政治、历史、地理的学生中任意选取3位同学,设随机变量X为投票给地理学科的
人数,求X的分布列和期望;
(3)当a为何值时,高一年级的语文、数学、外语三科的“好感指数”的方差最小?(结论不要求证明)
【解析】(1)由已知 ,所以 .依题意,
即 ,解得 ,又 ,
所以 , , , , ;
(2)由已知,随机变量 是高一(1)班同学中投票给地理学科的人数,
所以
,
.
.
(3) .
15.下表是中国近年来人口数据(不包括香港、澳门特别行政区和台湾省):
年份 2013 2014 2015 2016
人口
13.61亿 13.68亿 13.75亿 13.83亿
数
(1)在平面直角坐标系内标出这四个点,再把这些点连接成线;
(2)选择其中合适的两个点,建立一次函数模拟,用模拟函数预测2017年中国人口数;
(3)能否用“更好”的直线 来模拟这组数据的变化?也就是说,能否确定 , 的值,使式子
的值最小?(按如下步骤进行预测)
①化简S,使之成为字母 的二次三项式;
②当 取何值时(设为 ),二次三项式S取最小值(设为 ),这里 和 都应该是含字母 的式子,
且 是字母 的二次三项式;
③求 的值 ,使 取最小值;
④求出对应于上述 的 值;⑤用一次函数 模拟数据的变化,用模拟函数预测2017年中国人口数.
(4)把所得到的两个预测数据和2017年中国实际人口数进行比较.
【解析】(1)如图所示:
(2)不妨选择前两组数据建立一次函数模拟,设模拟方程为 ,
令2013年对应x为1,则2014年对应x为2,选取 两点进行模拟,
代入可得 ,
解得 ,所以 ,
2017年,即 时, ,
故预测2017年中国人口数为 亿(选其他数据,计算合理也正确)
(3)①
②所以当 时,S有最小值,
所以 ,
③由②可得当 时, 有最小值,即 ,④当 时, ,
⑤ ,2017年对应x=5,代入可得 ,
所以预测2017年中国人口数为13.9亿.
(4)查阅可得2017人口总数为13.9亿,比较可得第二种方法算的更准确,误差更小.
16.(2024·北京西城·一模)在测试中,客观题难度的计算公式为 ,其中 为第 题的难度, 为
答对该题的人数, 为参加测试的总人数 现对某校高三年级240名学生进行一次测试,共5道客观题 测
试前根据对学生的了解,预估了每道题的难度,如表所示:
题号 1 2 3 4 5
考前预估难度
测试后,随机抽取了20名学生的答题数据进行统计,结果如下:
题号 1 2 3 4 5
实测答对人 1 1
16 14 4
数 6 4
(1)根据题中数据,估计这240名学生中第5题的实测答对人数;
(2)从抽样的20名学生中随机抽取2名学生,记这2名学生中第5题答对的人数为 ,求 的分布列和数
学期望;
(3)试题的预估难度和实测难度之间会有偏差 设 为第 题的实测难度,请用 和 设计一个统计量,并
制定一个标准来判断本次测试对难度的预估是否合理.
【解析】(1)因为20人中答对第5题的人数为4人,因此第5题的实测难度为 ,
所以估计240人中有 人实测答对第5题.
(2) 的可能取值是0,1,2,
; ; .
的分布列为:
0 1 2
.
(3)将抽样的20名学生中第 题的实测难度,作为240名学生第 题的实测难度.定义统计量 ,
其中 为第 题的预估难度.
并规定:若 ,则称本次测试的难度预估合理,否则为不合理.
.
因为 ,
所以该次测试的难度预估是合理的.

