 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:70% 触发压缩、LCS 差分快照、全局/项目双记忆 — 三层架构榨干 200K 窗口
💡 阅读前记得关注+星标,及时获取更新推送
「Claude Code 源码揭秘」系列的第七篇,上一篇《Claude Code 源码揭秘:6 种权限模式,如何做到该放就放该拦就拦》解决的是”什么操作能做”的问题。这一篇聊一个更基础的问题:上下文窗口就那么大,它是怎么塞下那么多信息的?
让它读几个大文件,跑几个命令,输出几千行日志… 按理说窗口早该爆了。但实际用下来,跑几十轮都没问题。
翻源码才发现,Claude Code 在上下文管理上下了大功夫。不是简单的”满了就清”,而是一套精细的压缩、摘要、记忆机制。
先说压缩触发的时机。网上有人说是 92% 才压缩,但翻源码发现不对,实际是 70%:
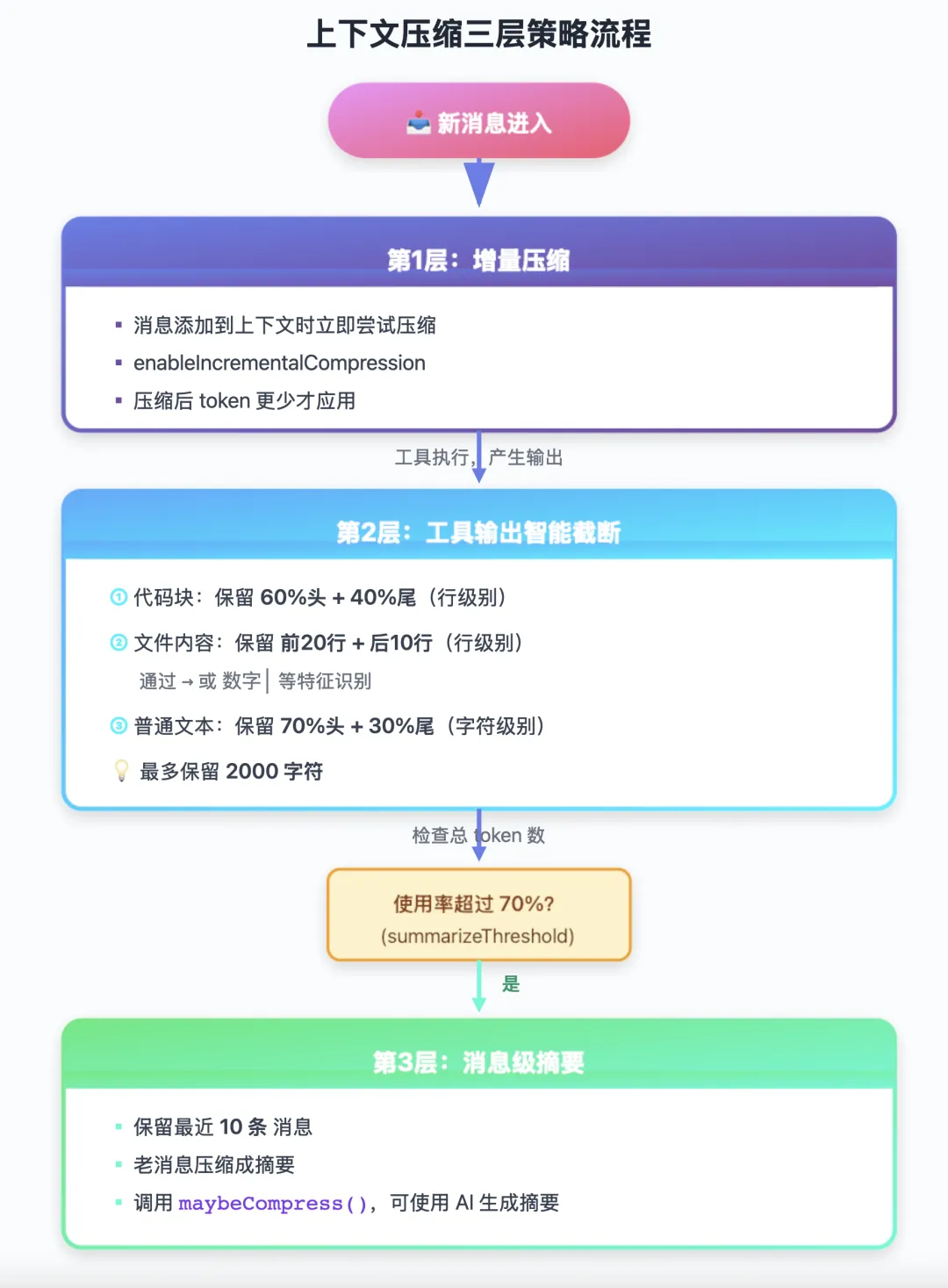
summarizeThreshold: config.summarizeThreshold ?? 0.7, // 70% 时开始摘要// 检查是否需要压缩const threshold = this.config.maxTokens * this.config.summarizeThreshold;const used = this.getUsedTokens();if (used < threshold) { return; // 还没到阈值,不压缩}压缩不是一刀切的,而是分三层策略。
第一层是增量压缩——消息进来的时候就压。不等到快满了才处理,而是每条消息添加到上下文时就尝试压缩:
if (this.config.enableIncrementalCompression) { processedUser = compressMessage(user, this.config); processedAssistant = compressMessage(assistant, this.config); // 压缩后 token 更少才应用 if (compressedTokens < originalTokens) { compressed = true; this.savedTokens += originalTokens - compressedTokens; }}这个思路很聪明。不是等问题出现再解决,而是在源头就控制增量。
第二层是工具输出的智能截断。你让 Claude Code 跑一个 grep,输出几千行,全塞进去太浪费了。它会智能处理:
function compressToolOutput(content: string, maxChars: number = 2000): string { if (content.length <= maxChars) { return content; } // 1. 检测代码块 - 代码优先保留 const codeBlocks = extractCodeBlocks(content); if (codeBlocks.length > 0) { // 逐个压缩代码块(代码块内部是60%头 + 40%尾) let result = content; for (const block of codeBlocks) { const compressed = compressCodeBlock(block.code); // 内部:60% + 40% const marker = block.language ? `\`\`\`${block.language}` : '```'; result = result.replace( `${marker}\n${block.code}\`\`\``, `${marker}\n${compressed}\`\`\`` ); } // 压缩后如果满足大小要求就返回 if (result.length <= maxChars) { return result; } } // 2. 检测文件内容 - 保留头20行 + 尾10行 if (content.includes('→') || /^\s*\d+\s*[│|]/.test(content)) { const lines = content.split('\n'); const keepHead = 20; // 硬编码:前20行 const keepTail = 10; // 硬编码:后10行 if (lines.length > keepHead + keepTail) { const head = lines.slice(0, keepHead).join('\n'); const tail = lines.slice(-keepTail).join('\n'); const omitted = lines.length - keepHead - keepTail; return `${head}\n... [${omitted} lines omitted] ...\n${tail}`; } } // 3. 默认:70%头部 + 30%尾部(字符级) const keepHead = Math.floor(maxChars * 0.7); const keepTail = Math.floor(maxChars * 0.3); const head = content.slice(0, keepHead); const tail = content.slice(-keepTail); const omitted = content.length - maxChars; return `${head}\n\n... [~${omitted} chars omitted] ...\n\n${tail}`;}为什么是”头多尾少”?因为大部分情况下,开头的信息更重要——文件的开头是声明和导入,日志的开头是上下文,错误的开头是调用栈。尾部保留一些是为了看到最终结果。
注意这里有三个不同的策略:
-
1. 代码块:60%头 + 40%尾(行级别) -
2. 文件内容:固定前20行 + 后10行(行级别,通过 →或数字│等特征识别) -
3. 普通文本:70%头 + 30%尾(字符级别)
这个分层策略不是拍脑袋的,是经验值。代码块更重视完整性(60/40),文件列表固定保留头尾关键信息,普通文本更激进压缩(70/30)。
第三层是消息级摘要——当总量超过 70% 时,把老的消息压缩成摘要:
const recentCount = this.config.keepRecentMessages; // 保留最近10条const toSummarize = this.turns.slice(0, -recentCount); // 老消息要摘要// 用 AI 生成摘要if (this.config.enableAISummary && this.apiClient) { summary = await createAISummary(toSummarize, this.apiClient);} else { summary = createSummary(toSummarize); // 简单版本}注意最近 10 条消息是不压缩的。因为最近的对话往往是当前任务的上下文,压缩了模型就不知道自己在干嘛了。
把三层串起来看:
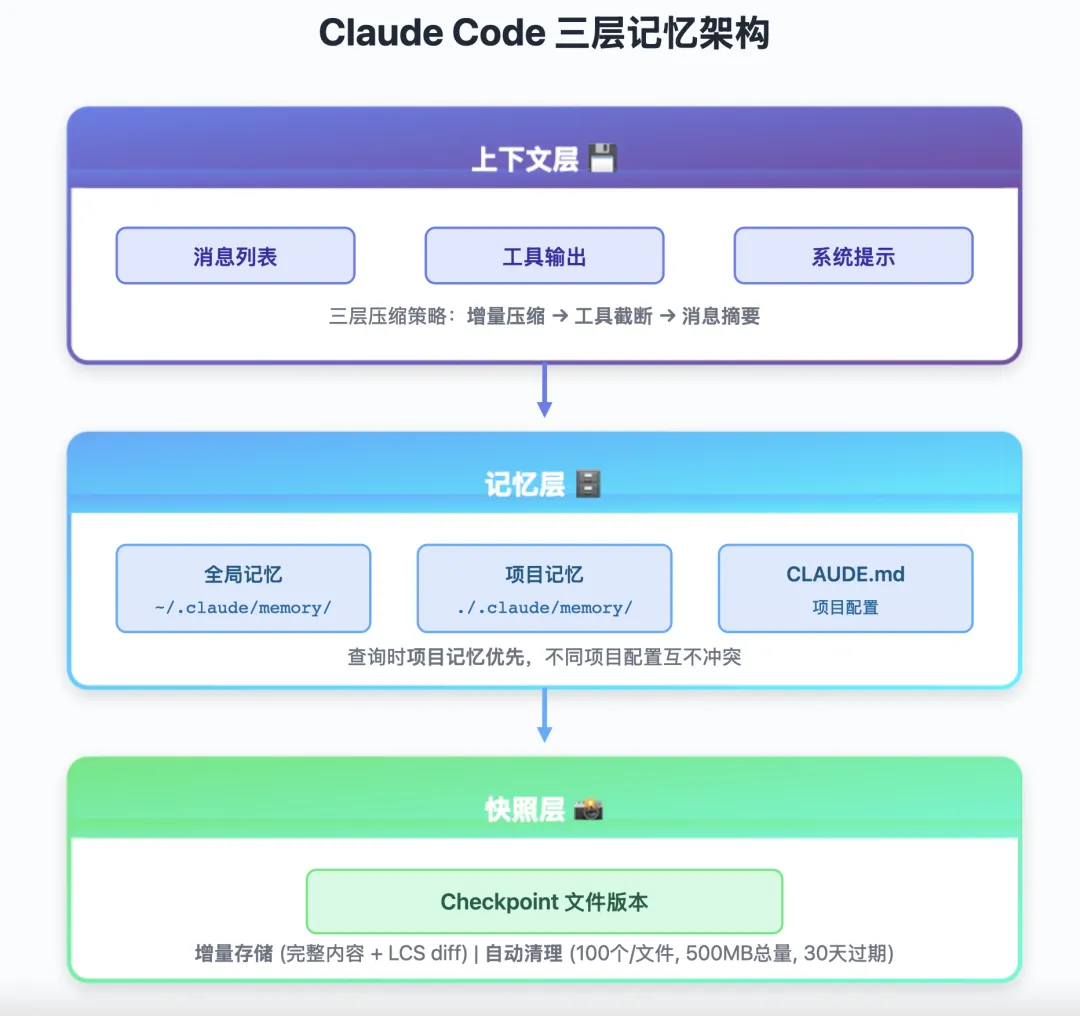
说完压缩,再聊记忆系统。
Claude Code 的记忆分两层:全局记忆和项目记忆。
function getGlobalMemoryDir(): string { return path.join(os.homedir(), '.claude', 'memory');}function getProjectMemoryDir(projectDir?: string): string { return path.join(projectDir || process.cwd(), '.claude', 'memory');}查询的时候,项目记忆优先:
get(key: string, scope?: 'global' | 'project'): string | undefined { if (scope === 'global') { return this.globalStore.entries[key]?.value; } if (scope === 'project') { return this.projectStore.entries[key]?.value; } // 默认:先查项目,再查全局 return this.projectStore.entries[key]?.value ?? this.globalStore.entries[key]?.value;}这个设计让你可以在不同项目里存不同的记忆。比如项目 A 用 MySQL,项目 B 用 PostgreSQL,各自的数据库配置不会冲突。
每条记忆还带时间戳:
store.entries[key] = { key, value, scope, createdAt: existing?.createdAt || now, // 保留创建时间 updatedAt: now, // 更新修改时间};这样可以追踪记忆的”冷热”程度。经常更新的是热数据,很久没动的是冷数据。以后做记忆清理的时候可以参考这个。
接下来是 CLAUDE.md 的加载机制。CLAUDE.md 也是两层架构:个人级和项目级。
function findClaudeMd(startDir?: string): string | null { let dir = startDir || process.cwd(); // 1. 从当前目录向上遍历,优先查找项目级 CLAUDE.md while (dir !== path.dirname(dir)) { for (const filename of [ 'CLAUDE.md', // 项目根目录 '.claude.md', // 隐藏文件 'claude.md', // 小写 '.claude/CLAUDE.md', // .claude 目录 '.claude/instructions.md' // 备选名称 ]) { const filePath = path.join(dir, filename); if (fs.existsSync(filePath)) { return filePath; // 项目级优先 } } dir = path.dirname(dir); } // 2. 如果项目级没找到,查找个人级 CLAUDE.md const homeClaudeMd = path.join(os.homedir(), '.claude', 'CLAUDE.md'); if (fs.existsSync(homeClaudeMd)) { return homeClaudeMd; // 个人级兜底 } return null;}查找优先级:
-
1. 项目级优先:从当前目录向上遍历,找到任何一个 CLAUDE.md 就立即返回 -
2. 个人级兜底:如果整个目录树都没找到,使用 ~/.claude/CLAUDE.md
这样设计的好处:
-
• 个人级 CLAUDE.md 可以放通用规则(编码习惯、常用工具偏好等) -
• 项目级 CLAUDE.md 可以覆盖个人规则,适配项目特性 -
• 不同项目的 CLAUDE.md 互不影响
找到 CLAUDE.md 后,会注入到系统提示里:
async function injectClaudeMd(systemPrompt: string, cwd: string): Promise<string> { const config = await parseClaudeMd(cwd); if (!config) return systemPrompt; const parts = [systemPrompt]; parts.push('\n\n## Project-Specific Instructions (CLAUDE.md)\n'); parts.push(config.content); // 如果引用了其他文件,也读进来(最多5个,每个最多5000字符) if (config.files.length > 0) { parts.push('\n\n## Referenced Files\n'); for (const filePath of config.files.slice(0, 5)) { try { const content = fs.readFileSync(filePath, 'utf-8'); const relativePath = path.relative(cwd, filePath); parts.push(`\n### ${relativePath}\n`); parts.push('```\n'); parts.push(content.slice(0, 5000)); if (content.length > 5000) { parts.push('\n... (truncated)'); } parts.push('\n```\n'); } catch (error) { // 忽略读取失败的文件 } } } return parts.join('');}这里有个限制:引用的文件最多 5 个,每个最多 5000 字符。不能无限塞,上下文窗口是有限的。这也是为啥很多实践建议,claude.md里面尽量写精华、不是写的越多越好,多了也记不住。
最后说说 Checkpoint 系统,这是文件版本快照。
你让 Claude Code 改了一个文件,改坏了想回滚怎么办?Checkpoint 就是干这个的。
const useFullContent = existingCheckpoints.length === 0 || // 第一个 checkpoint editCount === 0; // 编辑计数为 0if (useFullContent) { // 第一次:保存完整内容(超过1KB会压缩) checkpointContent = content.length > 1024 ? compressContent(content).toString('base64') : content;} else { // 后续:只保存增量 diff const lastContent = reconstructContent(path, existingCheckpoints.length - 1); checkpointDiff = calculateDiff(lastContent, content);}第一次保存完整内容,后续只保存变化的部分(diff)。这样既能回滚到任意版本,又不会占用太多空间。
Diff 计算用的是经典的 LCS(最长公共子序列)算法:
function calculateDiff(oldContent: string, newContent: string): string { const oldLines = oldContent.split('\n'); const newLines = newContent.split('\n'); // LCS 算法找出共同的行 const lcs = longestCommonSubsequence(oldLines, newLines); // 对比计算出 add/del 操作 // ... return JSON.stringify(diff);}恢复的时候,从最近的完整内容开始,逐个应用 diff:
function reconstructContent(filePath: string, checkpointIndex: number): string { // 找到最近的完整内容 checkpoint let baseIndex = checkpointIndex; while (baseIndex >= 0 && !checkpoints[baseIndex].content) { baseIndex--; } let content = checkpoints[baseIndex].content; // 逐个应用 diff for (let i = baseIndex + 1; i <= checkpointIndex; i++) { if (checkpoints[i].diff) { content = applyDiff(content, checkpoints[i].diff); } } return content;}存储也有限制:每个文件最多 100 个 checkpoint,总共最多 500MB,超过 30 天自动清理。
const MAX_CHECKPOINTS_PER_FILE = 100;const CHECKPOINT_RETENTION_DAYS = 30;const MAX_STORAGE_SIZE_MB = 500;把整个记忆架构串起来:
上下文压缩的完整原理:逆向分析 + 实际表现
通过逆向官方 Claude Code 2.0.76 的混淆代码(cli.js),结合实际使用表现,可以还原出完整的压缩机制。
核心压缩机制:三层压缩 + 两段式触发
逆向分析出的核心机制(注:逆向可能不全面,某些细节可能有偏差):
三层压缩策略:
-
1. 增量压缩:消息添加到上下文时立即尝试压缩( enableIncrementalCompression) -
2. 工具输出截断:代码块保留 60%头+40%尾,文件内容保留前20行+后10行,普通文本保留 70%头+30%尾 -
3. 消息级摘要:使用率达到 70% 时触发 maybeCompress(),保留最近 10 条消息,老消息压成摘要
基础配置:
-
• 上下文窗口:200,000 tokens -
• 保留空间:8,192 tokens -
• 第一次压缩阈值:70%( summarizeThreshold: 0.7) -
• 强制压缩阈值:100%(剩余 0% 时)
官方的高级特性(当前逆向实现尚未完全还原)
1. Prompt Caching 的使用
Prompt Caching 是 Anthropic API 的服务端功能,官方客户端在请求中标记了哪些内容需要缓存:
// API 返回的缓存统计"current_usage": { "input_tokens": number, "output_tokens": number, "cache_creation_input_tokens": number, // 写入缓存的 tokens "cache_read_input_tokens": number // 从缓存读取的 tokens(90%折扣)}官方实现在系统提示、工具定义、CLAUDE.md 等固定内容上加了 cache_control: {type: "ephemeral"} 标记,让 API 自动缓存这些内容,大幅降低成本。
当前逆向实现尚未在请求中加入 cache_control 标记,因此无法利用缓存降低成本。
2. 输出折叠机制(aboveTheFold)
// 默认只显示前 3 行{aboveTheFold: "前3行内容", remainingLines: 47}// 显示为:// 前3行内容// … +47 lines [ctrl+o to expand]官方使用行级折叠 + 可交互展开,比当前逆向实现的字符级截断体验更好。(当前逆向实现使用简单的字符截断)
3. Auto-Compact 自动压缩
官方在主循环中集成了自动压缩监控(当前逆向实现尚未完整还原此功能):
// 伪代码(从官方行为推测)const contextUsage = getContextUsage();const remaining = 100 - contextUsage.percentage;// 接近上限时显示警告if (contextUsage.percentage >= 94) { console.log(`Context left until auto-compact: ${remaining.toFixed(0)}%`);}// 0% 剩余空间时自动压缩if (remaining <= 0 && config.autoCompact) { console.log('Auto-compacting context...'); console.log('Compressing old messages...'); await compact(); console.log(`Freed tokens: ${freedTokens}`); console.log(`New usage: ${newPercentage.toFixed(1)}%`);}实际使用表现
用户在使用官方 Claude Code 时会看到:
情况 1:正常对话
(不显示任何提示)情况 2:接近上限(94-99% 使用率)
Context left until auto-compact: 6%Context left until auto-compact: 3%Context left until auto-compact: 1%情况 3:达到上限(100% 使用率,0% 剩余)
Context left until auto-compact: 0%Auto-compacting context...Compressing old messages... • Turn 1-15: 45,231 tokens → summary (1,234 tokens) • Turn 16-28: 38,492 tokens → summary (987 tokens) • Kept recent 10 turns unchangedFreed tokens: 81,502New usage: 65.3%Context compacted successfully之后继续对话,上下文使用率重新从 65% 左右开始增长。
逆向实现的完整度对比
|
|
|
|
|---|---|---|
| 70% 静默压缩 |
|
maybeCompress()
|
| 94-99% 警告提示 |
|
|
| 100% 自动压缩 |
/compact) |
compact(),输出压缩日志 |
| Prompt Caching 使用 |
|
|
| 输出折叠 |
|
|
| 三层压缩策略 |
|
|
为什么是 70% 压缩,0% 强制?
70% 预压缩:给后续对话留出空间。如果等到 90% 才压缩,可能连压缩本身需要的空间都没有了(生成摘要也要消耗 tokens)。
0% 强制压缩:这是最后的兜底机制。当上下文真的满了(剩余 0%),再不压缩就无法继续对话了。这时会强制执行 compact(),大幅压缩老消息,释放空间。
这个两段式设计保证了:
-
1. 大部分情况下静默压缩(70%),用户无感知 -
2. 极端情况下强制压缩(100%),保证能继续工作 -
3. 中间阶段显示警告(94-99%),让用户知道快满了
翻完这部分代码,我最大的感受是:上下文管理不是可有可无的优化,而是 Agent 能否长时间工作的关键。
没有压缩,跑几轮就爆了。没有记忆,每次都从头开始。没有快照,改错了没法回滚。
这套系统的设计思路是”空间换时间 + 智能取舍”——通过压缩、摘要、增量存储等手段,在有限的上下文窗口里塞下尽可能多的有效信息。官方完整实现还包括 Prompt Caching 和 Auto-Compact 等高级特性,进一步优化了成本和自动化程度。当前的逆向实现已经还原了核心压缩机制,但在缓存支持和自动监控方面并没有完全逆向出来。
下一篇聊子代理系统。Claude Code 怎么把复杂任务分给不同的子代理?主代理当”包工头”,子代理干活不污染上下文,这个设计也挺有意思的。
本文通过逆向分析官方 Claude Code 2.0.76(混淆文件:node_modules/@anthropic-ai/claude-code/cli.js),还原并实现了核心上下文管理机制。主要逆向实现文件:src/context/index.ts、src/memory/index.ts、src/checkpoint/index.ts。
如果这篇文章对你有帮助,欢迎点赞转发,关注不迷路⭐️
