 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:19 个钩子点,5 种钩子类型,把 Agent 行为拿捏得死死的
💡 阅读前记得关注+星标,及时获取更新推送
「Claude Code 源码揭秘」系列的第十篇,上一篇《Claude Code 源码揭秘:19 个钩子点,5 种钩子类型,把 Agent 行为拿捏得死死的》,聊扩展性系统的时候,提到 Plugins 可以注册钩子:hooks.on('beforeMessage', ...)。

钩子这东西,做过后端开发的应该都不陌生。Git 有 pre-commit 钩子,可以在提交前执行检查;Webpack 有各种生命周期钩子,可以在打包的不同阶段插入自定义逻辑;Kubernetes 的 Webhook 本质上也是一种钩子机制。类似的还有 React/Vue 的生命周期钩子、数据库的触发器、Spring AOP 切面等——核心思想都是在特定时机插入自定义逻辑,实现解耦和扩展。
Claude Code 的钩子系统更复杂一些——19 个钩子点,5 种钩子类型,能让你在 Agent 执行的各个关键节点插入自己的逻辑。
翻 src/hooks/index.ts,1400 多行代码。这套系统的设计目标很明确:不改源码,也能定制 Agent 的行为。
我之前做过一个审批流引擎,也有类似的钩子设计——流程节点前后都能挂钩子,用来做校验、通知、日志记录。那套东西帮我们拦了不少违规操作,上线三年没出过大事故。Claude Code 的钩子系统,思路是一样的,只不过它面对的是 AI Agent 这个更复杂的场景。
先看有哪些钩子点。
19 个钩子事件
分两大类:工具级别和 CLI 级别。
工具级别的钩子,跟工具执行相关:
PreToolUse - 工具执行前,可以阻止执行PostToolUse - 工具执行后,可以记录或处理输出PostToolUseFailure - 工具执行失败后,包含错误信息PermissionRequest - 权限请求时,可以自动决策UserPromptSubmit - 用户提交提示时,可以做输入验证Stop - Claude 停止生成前SubagentStart - 子代理启动时SubagentStop - 子代理停止时PreCompact - 上下文压缩前,可以阻止或提供自定义指令Notification - 通知事件触发SessionStart - 会话开始SessionEnd - 会话结束CLI 级别的钩子,跟启动流程相关:
BeforeSetup - 设置前AfterSetup - 设置后CommandsLoaded - 命令加载完成ToolsLoaded - 工具加载完成McpConfigsLoaded - MCP 配置加载完成PluginsInitialized - 插件初始化后AfterHooks - Hooks 执行后最常用的是 PreToolUse 和 PostToolUse。前者可以在工具执行前拦截危险操作,后者可以记录执行日志。
我之前帮一个金融客户做合规审计,最头疼的就是「事后追溯」——出了问题才发现没有日志。如果当时有 Claude Code 这种钩子机制,在 PostToolUse 里挂一个日志记录,所有操作都有迹可循,审计就简单多了。
5 种钩子类型
光有钩子点还不够,钩子要干什么事?Claude Code 定义了 5 种类型:
command —— 执行 shell 命令
{ "type": "command", "command": "echo '[$(date)] Tool: $TOOL_NAME' >> /tmp/claude.log", "blocking":false}最灵活的类型。你可以跑任何脚本,输入通过环境变量和 stdin 传递,输出通过 stdout 返回。
prompt —— 用 LLM 评估
{ "type": "prompt", "prompt": "检查以下命令是否安全: {TOOL_INPUT}", "blocking":true}让另一个 Claude 来判断是否放行。这个设计有点意思——用 AI 审核 AI。
agent —— 代理验证器
{ "type": "agent", "agentType": "file-operation-validator", "blocking":true}比 prompt 更复杂,可以配置专门的验证代理。
mcp —— 调用 MCP 服务器工具
{ "type": "mcp", "server": "security-scanner", "tool": "scan_command", "blocking":true}如果你有现成的 MCP 服务器,可以直接调用它的工具来做验证。
url —— HTTP 远程回调
{ "type": "url", "url": "https://webhook.company.com/audit", "method": "POST", "blocking":false}把事件发送到远程服务器,适合集成企业级的监控和审计系统。
这 5 种类型覆盖了几乎所有场景。本地脚本、AI 评估、MCP 集成、远程服务… 总有一款适合你。
我之前做的审批流引擎,钩子只支持 HTTP 回调一种方式。结果用户反馈说,有些场景只需要跑个本地脚本,还得专门起个 HTTP 服务来接收回调,太麻烦了。Claude Code 这里提供 5 种类型,就不会有这个问题。
command 钩子的执行细节
command 类型用得最多,看看它是怎么实现的:
async function executeCommandHook(hook: CommandHookConfig, input: HookInput) { // 1. 变量替换 const command = replaceCommandVariables(hook.command, input); // 2. 设置环境变量 const env = { ...process.env, ...hook.env, CLAUDE_HOOK_EVENT: input.event, CLAUDE_HOOK_TOOL_NAME: input.toolName || '', CLAUDE_HOOK_SESSION_ID: input.sessionId || '', }; // 3. 通过 stdin 传递完整的 JSON 输入 const inputJson = JSON.stringify({ ...input }); // 4. spawn 执行,启用 shell const proc = spawn(command, hook.args || [], { env, stdio: ['pipe', 'pipe', 'pipe'], shell: true, }); // 5. 写入 stdin proc.stdin.write(inputJson); proc.stdin.end(); // 6. 超时处理 const timeoutId = setTimeout(() => { proc.kill('SIGKILL'); }, hook.timeout || 30000); // 7. 处理退出码 // exit 0: 成功 // exit 非0: 检查 stdout 中的 blocked 标志}几个设计亮点:
双重输入:环境变量传简单信息(事件名、工具名),stdin 传完整的 JSON 数据。这样脚本既可以快速读环境变量,也可以解析 JSON 拿到所有细节。
超时强杀:30 秒超时,直接 SIGKILL。不给钩子脚本卡死的机会。
退出码约定:0 表示通过,非 0 要看 stdout 里有没有 blocked 字段。这个设计让脚本可以返回结构化的拒绝原因。
我之前做 CI/CD 系统的时候,也用过类似的退出码约定。0 是成功,1 是失败,2 是跳过… 标准化的约定让脚本之间能互相配合。
阻塞与非阻塞
每个钩子都有一个 blocking 属性:
{ "type": "command", "command": "...", "blocking": true // 阻塞模式}blocking: true 意味着钩子可以阻止后续操作。比如 PreToolUse 钩子返回 blocked: true,工具就不会执行。
blocking: false 是「放行但记录」模式。钩子执行完,不管结果如何,后续操作都会继续。适合日志记录、通知这类场景。
执行多个钩子的时候,遇到阻塞就停:
for (const hook of matchingHooks) { const result = await executeHook(hook, input); results.push(result); // 阻塞型钩子返回 blocked,停止后续钩子 if (result.blocked && hook.blocking) { break; }}这个设计很像责任链模式。链条上的每个节点都可以选择「放行」或「拦截」,一旦拦截,后面的节点就不用跑了。
Matcher:精确匹配和正则匹配
有时候你只想对特定工具挂钩子。比如只对 Bash 工具做安全检查,对 Read 工具不管。这就用到 matcher:
{ "type": "prompt", "prompt": "检查命令安全性...", "matcher": "Bash", // 只匹配 Bash 工具 "blocking":true}还支持正则:
{ "type": "agent", "agentType": "file-validator", "matcher": "/^(Write|Edit)$/", // 匹配 Write 或 Edit "blocking":true}匹配逻辑:
function getMatchingHooks(event: HookEvent, toolName?: string) { return hooks.filter((hook) => { if (hook.matcher && toolName) { // 正则匹配:/regex/ if (hook.matcher.startsWith('/') && hook.matcher.endsWith('/')) { const regex = new RegExp(hook.matcher.slice(1, -1)); return regex.test(toolName); } // 精确匹配 return hook.matcher === toolName; } return true; // 没有 matcher 的钩子对所有工具生效 });}没有 matcher 的钩子是「通配」的,对所有工具生效。有 matcher 的钩子只对匹配的工具生效。
用户怎么配置钩子?
钩子配置放在 .claude/settings.json 里:
{ "hooks": { "PreToolUse": [ { "type": "prompt", "prompt": "检查 Bash 命令安全性: {TOOL_INPUT}", "matcher": "Bash", "blocking":true, "timeout": 30000 } ], "PostToolUse": [ { "type": "command", "command": "echo '[$(date)] $TOOL_NAME executed' >> ~/.claude/audit.log", "blocking":false }, { "type": "url", "url": "https://audit.company.com/log", "method": "POST", "blocking":false } ], "SessionStart": [ { "type": "command", "command": "./scripts/session-init.sh" } ] }}配置文件的查找顺序:
项目级:.claude/settings.json全局级:~/.claude/settings.json项目级的配置会覆盖全局级。这个设计让你可以给不同项目配置不同的钩子策略。
实际应用场景
场景一:安全拦截
在 PreToolUse 挂一个安全检查钩子,对 Bash 命令做审核:
{ "hooks": { "PreToolUse": [ { "type": "prompt", "prompt": "你是安全审核员。检查以下 Bash 命令是否安全,是否包含危险操作(rm -rf、sudo、curl | bash 等)。命令:{TOOL_INPUT}。如果安全返回 {\"ok\": true},如果危险返回 {\"ok\": false, \"reason\": \"原因\"}", "matcher": "Bash", "blocking":true } ] }}这样即使模型生成了危险命令,也会被钩子拦截。
场景二:审计日志
在 PostToolUse 挂一个日志记录钩子:
{ "hooks": { "PostToolUse": [ { "type": "url", "url": "https://siem.company.com/api/events", "method": "POST", "headers": { "Authorization": "Bearer ${SIEM_TOKEN}" }, "blocking":false } ] }}所有工具执行都会发送到企业的 SIEM 系统,方便事后审计。
场景三:自动授权
在 PermissionRequest 挂一个自动决策钩子:
{ "hooks": { "PermissionRequest": [ { "type": "command", "command": "./scripts/auto-approve.sh", "blocking":true } ] }}脚本里可以根据工具名、输入参数等自动判断是否授权,减少人工干预。
我之前在一个项目里,运维同事天天被权限申请烦死——大部分都是常规操作,但还是要人工点批准。后来我们写了个自动审批脚本,根据申请人、操作类型、时间段等规则自动放行,人工审批量减少了 80%。Claude Code 的这个钩子机制,可以实现类似的效果。
钩子执行的完整链路
把钩子系统在整个 Agent 执行中的位置画出来:
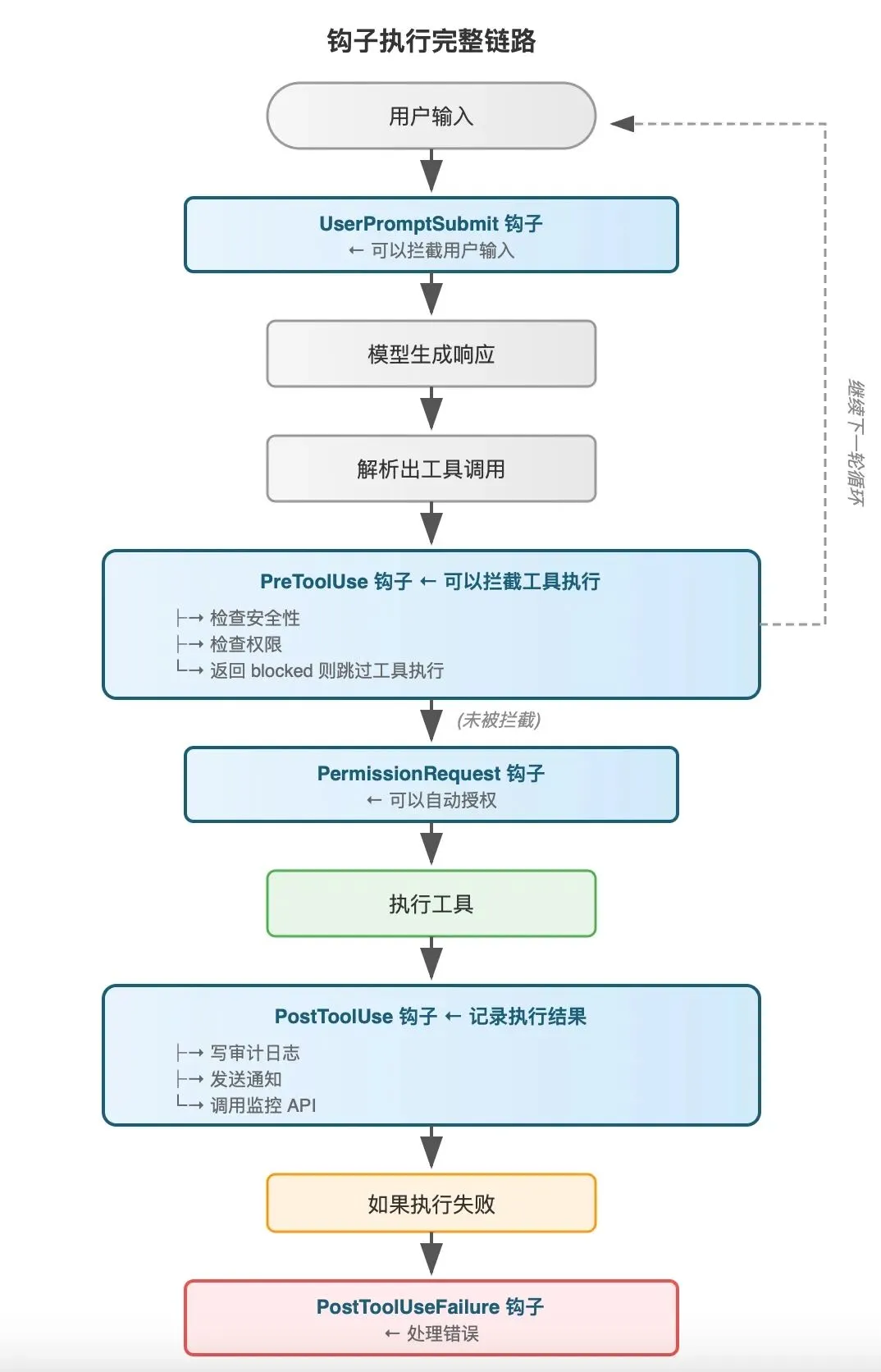
钩子就像是在这条流水线上设置的「检查站」。每个检查站可以检查、记录、甚至拦截经过的「货物」。
与插件系统的集成
在 Plugins 里注册钩子很简单:
export default { async activate(context) { // 注册钩子 context.hooks.on('PreToolUse', async (input) => { if (input.toolName === 'Bash') { // 检查逻辑... return { blocked: false }; } }); context.hooks.on('PostToolUse', async (input) => { // 记录日志... }); }};插件里的钩子和配置文件里的钩子是一起执行的,按注册顺序来。
错误处理
钩子执行出错了怎么办?三层兜底:
// 第一层:单个钩子执行的 try-catchtry { const result = await executeHook(hook, input);} catch (err) { return { success: false, error: err.message };}// 第二层:超时强杀setTimeout(() => proc.kill('SIGKILL'), timeout);// 第三层:配置加载的容错try { const config = JSON.parse(content);} catch (err) { console.error(`Failed to load hooks: ${err}`); // 继续运行,不影响主流程}钩子出错不会导致 Agent 崩溃。最坏情况就是这个钩子没生效,主流程继续跑。
这个设计思路是对的。钩子是「附加功能」,不能因为钩子挂了就把整个 Agent 搞崩。我之前见过一个系统,日志钩子抛了个异常,直接把主流程拖死了。后来加了错误隔离,问题才解决。
翻完这部分代码,我总结一下这套钩子系统的设计精髓:
事件驱动 —— 19 个钩子点覆盖 Agent 生命周期的关键节点类型多样 —— 5 种钩子类型适配不同场景精准匹配 —— matcher 支持精确和正则,可以细粒度控制阻塞机制 —— blocking 属性区分「拦截」和「记录」两种模式错误隔离 —— 钩子出错不影响主流程
这套机制让 Claude Code 变成了一个「可编程」的 Agent。不改源码,通过配置文件就能定制它的行为。这对企业级应用来说太重要了——安全合规、审计日志、自定义策略… 都可以通过钩子实现。k8s里面的webhook也是这么个思路,好的设计都是相通的。
下一篇聊 System Prompt 的动态构建。Claude Code 的系统提示不是写死的,而是根据当前状态动态拼接的。CLAUDE.md、工具列表、权限配置… 这些东西是怎么组合成最终的 system prompt 的?
本文基于 Claude Code 2.0.76 版本源码分析,主要文件:src/hooks/index.ts。
