 夜雨聆风
夜雨聆风





3 个 .md 文件灭掉传统插件?10.4k Star obsidian-skills仓库凭什么
1. 你的 AI 还在”半自动”模式?
让 ChatGPT 帮你写一篇 Obsidian 笔记,粘贴进去——wikilink 变成了普通超链接,callout 语法写反了括号,frontmatter 缺了日期类型。10 处格式错误,3 分钟手动修。
这不是个别现象。
通用大模型不懂 Obsidian 的专有语法。[[双链]] 不是标准 Markdown,> [!tip] 不是普通引用,.canvas 文件是 JSON 不是随手画的涂鸦。你让 AI 帮忙,它写出来的东西看着像那么回事,但 Obsidian 不认。
Notion 的做法是把 AI 焊死在产品里。数据在云端,模型不可替换,公式引擎也只能在线跑。好用?好用。但你的数据不在你手里。
Obsidian 的 CEO Steph Ango 给出了一个完全不同的答案:不做官方 AI,不参与军备竞赛——发 3 个 Markdown 文件,让社区自己搞。
这 3 个文件,就是 SKILL.md。
❝
不写代码,写规范。不绑模型,定接口。这可能是 AI 时代软件扩展的新范式。
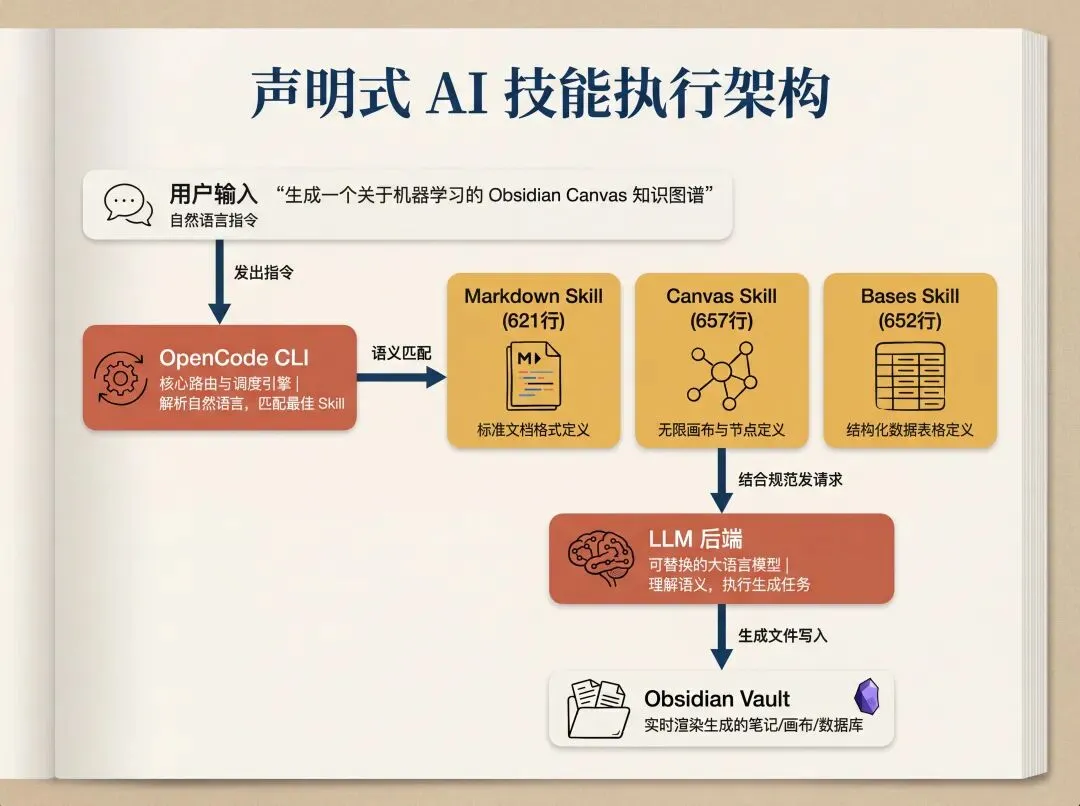
2. 声明式能力定义:写给 AI 的说明书
什么是 SKILL.md?
说白了,就是一份写给 AI 读的格式说明书。开头用 YAML frontmatter 声明自己的名字和用途,正文用 Markdown 写格式规范——字段定义、示例代码、边缘情况、常见陷阱。没有一行可执行代码。
kepano(Steph Ango 的 GitHub ID)在个人仓库 obsidian-skills 里发布了 3 个核心 Skill:
|
|
|
|
|
|---|---|---|---|
|
|
SKILL.md |
|
|
|
|
SKILL.md |
|
|
|
|
SKILL.md |
|
|
共计约 1930 行纯文本。没有编译,没有打包,没有 API 注册。AI 读完这 1930 行,就”学会”了生成 Obsidian 原生格式的内容。
仓库上线不到两个月,Star 数冲到 10.4k,Fork 超 551。坦白说,一个只放了几个 Markdown 文件的仓库能拿到这个数据,说明大家确实憋坏了。
❝
一个 SKILL.md 就是一个能力声明。1930 行文本定义 3 项能力,这效率比写插件高了两个数量级。
3. 两个数组、一棵语法树、一套公式引擎
三个 Skill 的技术底座完全不同,但设计哲学一脉相承:用最少的概念覆盖最多的场景。
Markdown Skill 基于 CommonMark + GitHub Flavored Markdown + Obsidian 扩展语法。它要处理的核心难题是 AI 用词的不确定性——同一种 callout,AI 可能叫它 tip,也可能叫 hint 或 important。规范里用一张 别名映射表 把 13 种 callout 类型和所有别名全部罗列,AI 随便用哪个都是合法的。
Canvas Skill 把整个无限画布抽象成两个数组:nodes[] 和 edges[]。4 种节点类型(text/file/link/group)覆盖了文字、附件、外链、分组。你发现没——没有 z-index 字段。节点在数组里的位置就是它的层级。第一个元素在最底下,最后一个在最上面。少一个字段就少一种出错的可能。
Bases Skill 是三者中最复杂的,它在 YAML 里嵌了一套类似 JavaScript 的公式语言。五层配置——filters → formulas → properties → summaries → views——从数据筛选到视图渲染,全部声明式。日期相减的结果不是数字,是 Duration 类型,必须先取 .days 才能做四则运算。这种类型约束直接写在规范里,连正反示例都给了。
4. 1200 行规范背后的 3 个防错设计
源码里最值得看的不是功能定义,而是防错设计。这些设计决策藏在细节里,不读源码根本发现不了。
防错 1:Callout 别名映射兜住 AI 的不确定性

AI 生成 callout 时可能用 > [!tip],也可能用 > [!hint] 或 > [!important]。在别名映射表的保护下,三种写法渲染效果完全一致。这张表的存在,让 AI 的”措辞自由”和”格式正确”不再矛盾。
防错 2:数组顺序即 z-index,消灭一个字段
Canvas 规范里写得很直白:
❝
Nodes are ordered by z-index in the array: First node = bottom layer, Last node = top layer.
没有 zIndex: 5 这种字段。AI 只需要把重要的节点放在数组后面就行。对人类来说这是个约定,但对 AI 来说这是个福音——少记一个字段,少犯一种错。
防错 3:Duration 类型的正反示例
Bases 规范中,日期相减返回 Duration 类型,不能直接调用 .round()。规范里同时给了正确和错误的写法:
# ✅ 正确:先取 .days 再 round"(date(due_date) - today()).days.round(0)"# ❌ 错误:Duration 不支持直接 round"((date(due) - today()) / 86400000).round(0)"坦白说,正反示例这个设计太聪明了。AI 见过错误写法之后,”踩坑概率”骤降。
❝
规范的价值不在于告诉 AI 什么是对的,更在于告诉它什么是错的。
5. 5 分钟把你的 Obsidian 变成 AI 智能体
说了这么多,怎么用?5 步搞定。
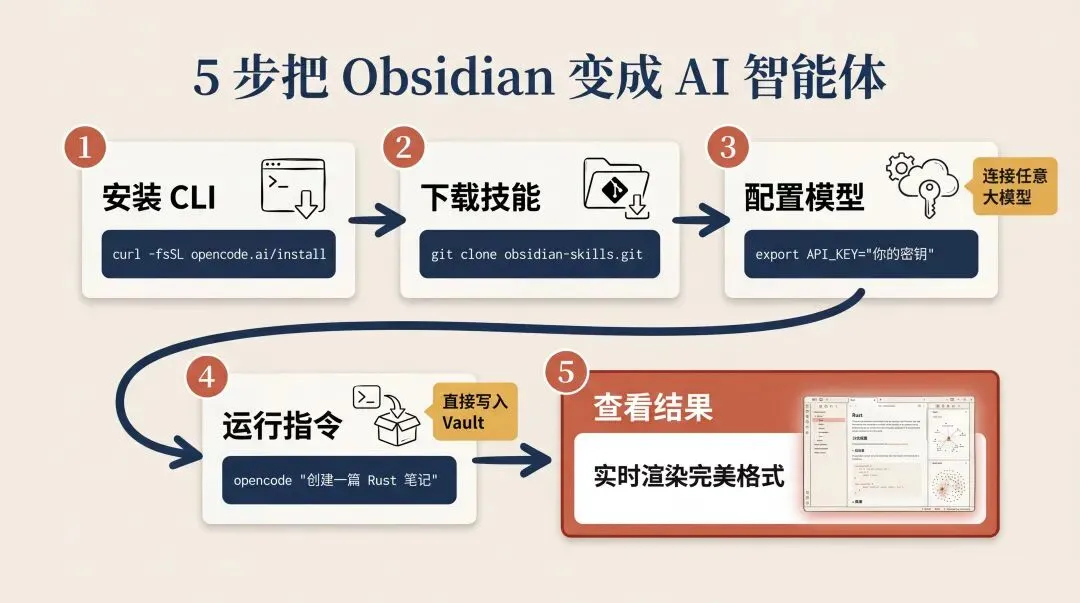
第 1 步:安装 OpenCode CLI
OpenCode 是开源 AI 编码工具,支持 75+ 个 LLM 后端(OpenAI、Anthropic、DeepSeek、智谱 GLM、Ollama 本地模型),不锁定厂商。
curl -fsSL "https://opencode.ai/install" | bash第 2 步:下载 3 个 Skill 文件
mkdir -p ~/.opencode/skillscd ~/.opencode/skillsgit clone https://github.com/kepano/obsidian-skills.git第 3 步:配置 LLM 后端
以智谱 GLM 为例,设置两个环境变量:
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/paas/v4"export ANTHROPIC_API_KEY="你的API密钥"DeepSeek 或 Ollama 同理,换个地址就行。
第 4 步:在 Obsidian Vault 目录下运行
cd ~/my-vaultopencode "创建一篇关于 Rust 异步编程的笔记,包含 wikilink、callout 和 frontmatter"第 5 步:回到 Obsidian 查看结果
OpenCode 会按照 Markdown Skill 的规范生成 .md 文件,直接写入 Vault。打开 Obsidian,笔记已经在那了——wikilink 可点击,callout 有颜色,frontmatter 字段类型正确。
如果你想生成画布:
opencode "用 Canvas 画一张 Rust 所有权系统的知识图谱"想创建数据库视图:
opencode "创建一个按状态分组的任务追踪 Base"三种文件格式,一条命令搞定。
6. 写规范而不写代码,会是 AI 扩展的终局吗?
我认为 SKILL.md 模式触碰到了一个根本性问题:AI 时代的软件扩展,到底应该面向机器还是面向 AI?
传统插件面向机器——你得写代码、调 API、处理异常、打包发布。SKILL.md 面向 AI——你只需要写一份规范,描述”做什么”而不定义”怎么做”,AI 通过阅读理解来执行。
这个思路不新。OpenAPI Spec 早就在做类似的事——用 YAML 描述 API 接口,让工具自动生成客户端。但 OpenAPI 的读者是代码生成器,SKILL.md 的读者是大语言模型。后者的理解力更强,也更不可预测。
局限性是有的。LLM 的阅读理解能力有上限,规范写得太复杂可能适得其反。Bases Skill 里那套公式引擎(Duration 类型、this 上下文、递归筛选器)已经接近复杂度天花板了。而且,Claudian 插件还没进 Obsidian 官方市场,安装门槛对非技术用户偏高。
但方向是对的。当 10.4k 个 Star 替一个”只有 Markdown 文件”的仓库投票,当社区开始写自己的 SKILL.md 扩展 AI 能力——你不得不承认,软件扩展的成本正在从”写代码”降到”写文档”。
这个趋势刹不住了。
❝
声明式能力定义会不会成为下一个范式?我不确定。但”任何人写个 Markdown 就能教 AI 一项新技能”这件事,已经在发生了。
❝
专家建议:先把 3 个核心 Skill 跑通,再考虑写自己的 SKILL.md——理解规范的颗粒度比掌握语法更重要。
📚 Obsidian Skills 系列
|
|
|
|
|---|---|---|
|
|
3 个 .md 文件灭掉传统插件?10.4k Star 仓库凭什么 |
|
