 夜雨聆风
夜雨聆风





TextIn xParse Dify插件使用教程
2026
3/5
TextIn.com
TextIn
—— 专注智能文字识别19年 ——
TextIn xParse Dify插件简介
Dify是一个开源的大语言模型(LLM)应用开发平台,旨在简化和加速生成式AI应用的创建和部署。它结合了后端即服务(BaaS)和LLMOps的理念,为开发者提供了用户友好的界面和强大的工具,有效降低了AI应用开发的门槛。
TextIn xParse是一个端到端文档处理AI基础设施,致力于将非结构化文档高效转化为可查询、可分析的数据资产。
目前TextIn xParse插件已在Dify市场上架,帮助用户搭建工作流,提供强大的文档解析和处理能力。
-
Dify官网地址:https://dify.ai/zh -
xParse Dify插件下载地址:https://marketplace.dify.ai/plugins/intsig-textin/xparse
xParse在Dify中的使用方法
一、xParse Dify插件亮点
-
多种解析引擎支持:支持TextIn自研高性能解析引擎(推荐)、MinerU、PaddleOCR等多种行业内先进的解析引擎,可根据文档类型灵活选择。 -
强大的文档处理能力:支持PDF、Word、Excel、PPT、图片等多种格式,准确提取标题、公式、图表、表格等元素,保留文档的语义结构。 -
赋能工作流:让Dify的Agent拥有强大的文档”读写”能力,轻松处理复杂任务,支持RAG、知识库构建、信息提取等场景。 -
灵活的配置选项:支持自定义解析引擎、去水印、切边增强等参数,满足不同业务需求。
二、实战演练:两个案例带你快速上手
空谈不如实战。下面我们通过两个典型场景,向你展示xParse插件的强大之处。
准备
-
在Dify插件页面安装xParse插件(私有化部署的Dify同理) -
填写API配置信息
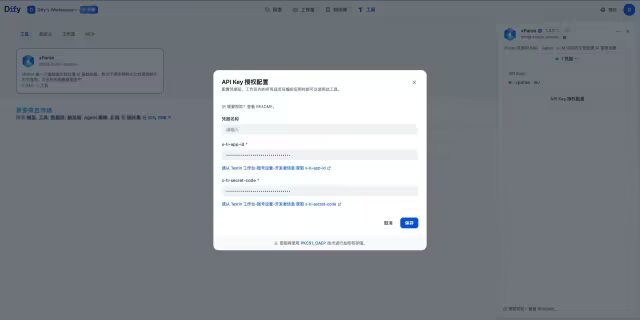
在插件配置页面,需要填写以下信息:
-
x-ti-app-id:xParse的应用 ID,必填 -
x-ti-secret-code:xParse的密钥,必填
提示:请前往TextIn工作台(https://www.textin.com/console/dashboard/setting)获取API Key,详细获取方式请参考API Key文档(https://docs.textin.com/pipeline/api-key)
案例一:解析单文件,搭建Chat Document应用
想借助AI与你的文档对话吗?跟着下面几步,轻松实现。
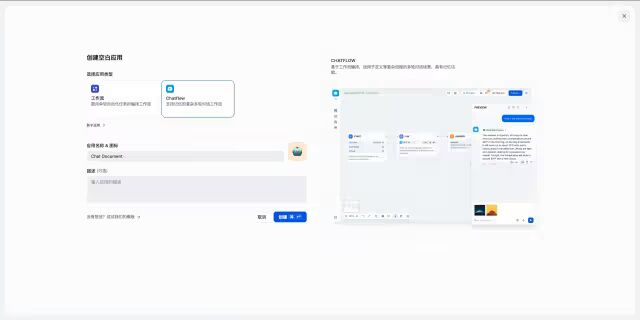
第一步:创建空白应用,选择“Chatflow”
输入应用名称与描述
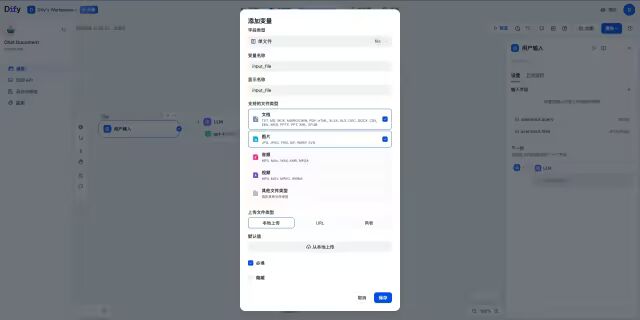
第二步:创建的初始模板中,选择“开始”节点
点击右侧“+”按钮添加变量,选择字段类型选为单文件,填写变量名称(此处填为input_file),支持文档类型选为文档与图片,上传文件类型选为本地上传。
第三步:添加工具节点——xParse插件来解析上一步开始节点上传的文件
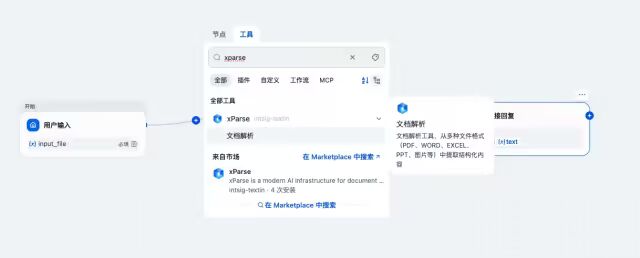
第四步:设置xParse的输入变量,选择上一步开始节点添加的input_file
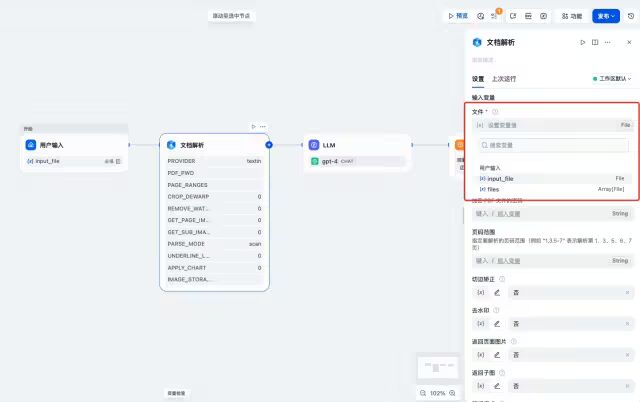
xParse插件支持以下配置选项:
-
文件输入:选择要解析的文件(必填) -
解析引擎:可选择 Textin(推荐)、Textin Lite、Mineru、PaddleOCR等(陆续接入中) -
预处理:可选择 切边矫正、去水印等
其他参数详情可参考插件说明文档(https://marketplace.dify.ai/plugin/intsig-textin/xparse)。
第五步:配置LLM模型
选择“LLM”节点后,如果没有模型可用,需要单独在插件市场安装(这里使用gpt-5作为示例)
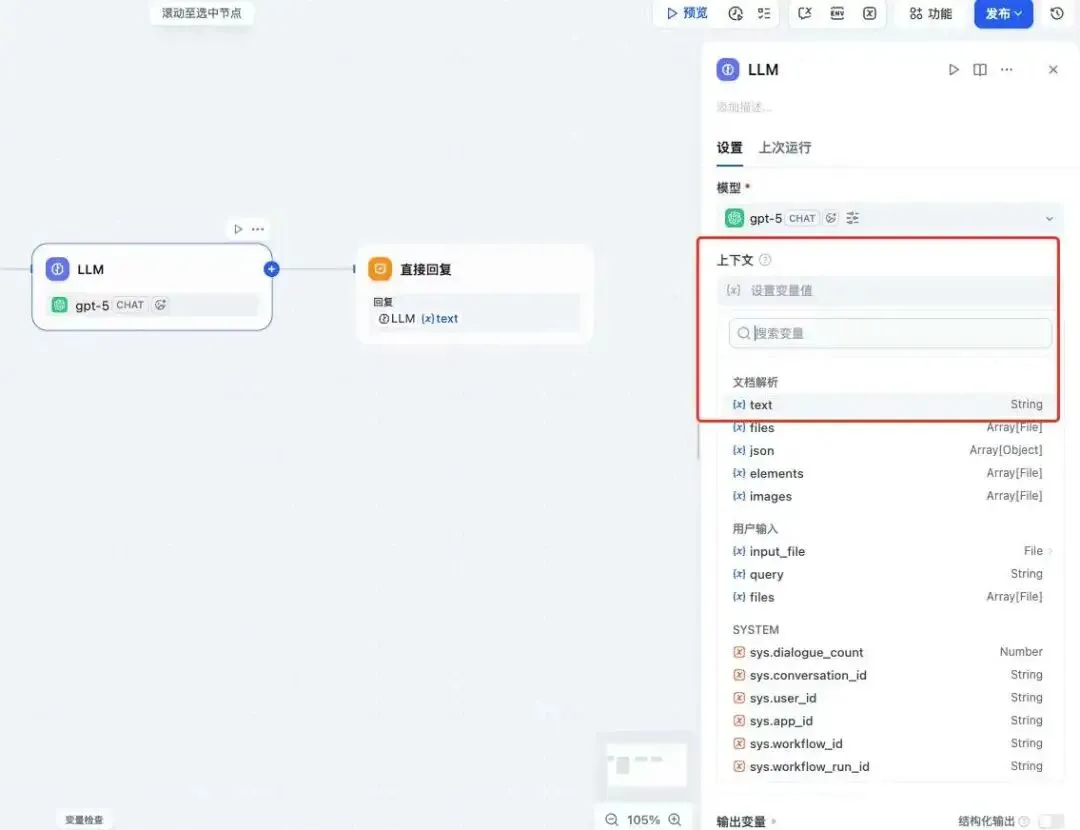
“上下文”选择xParse的输出变量text(xParse解析文档后的markdown格式)
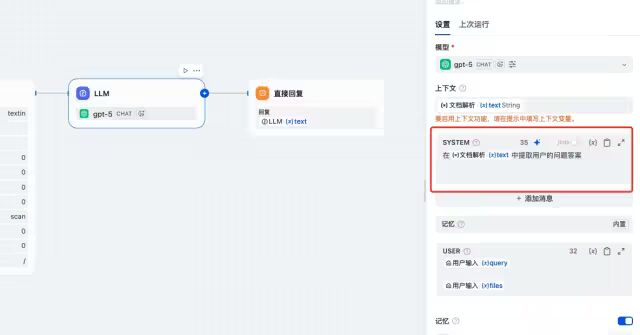
在“SYSTEM”区域根据实际需求填写提示词,可如图填写“在文档解析text中提取用户的问题答案”
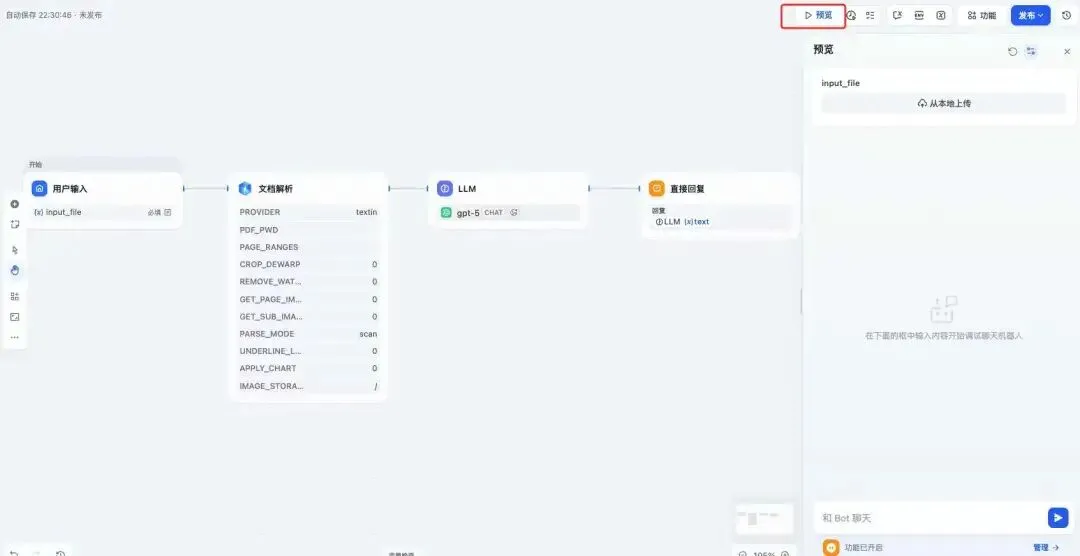
第六步:预览,上传文件并提问机器人关于文档的内容
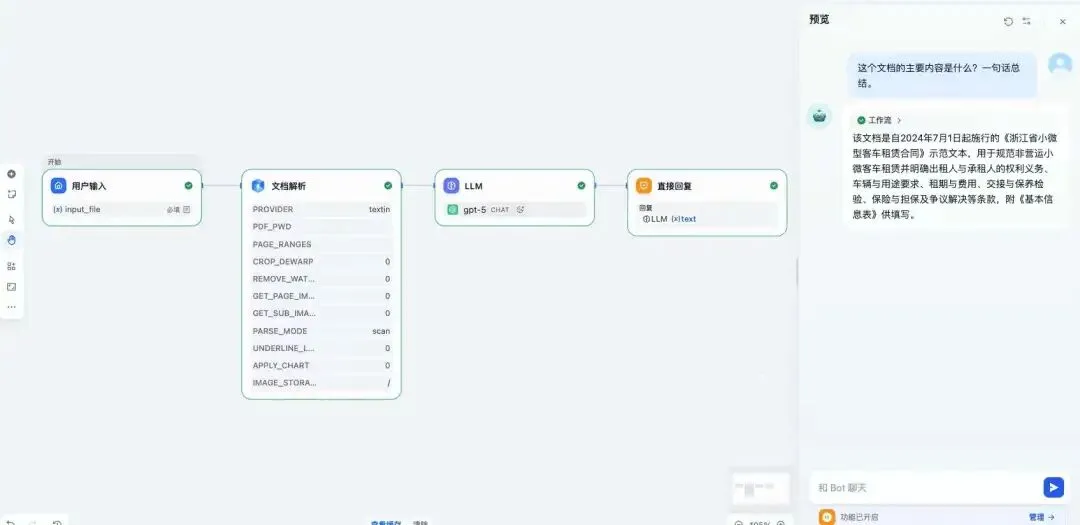
至此一个简单的文档问答应用Chat PDF搭建完成,点击“预览”,查看效果如何:
结果如下:
第七步:发布与测试
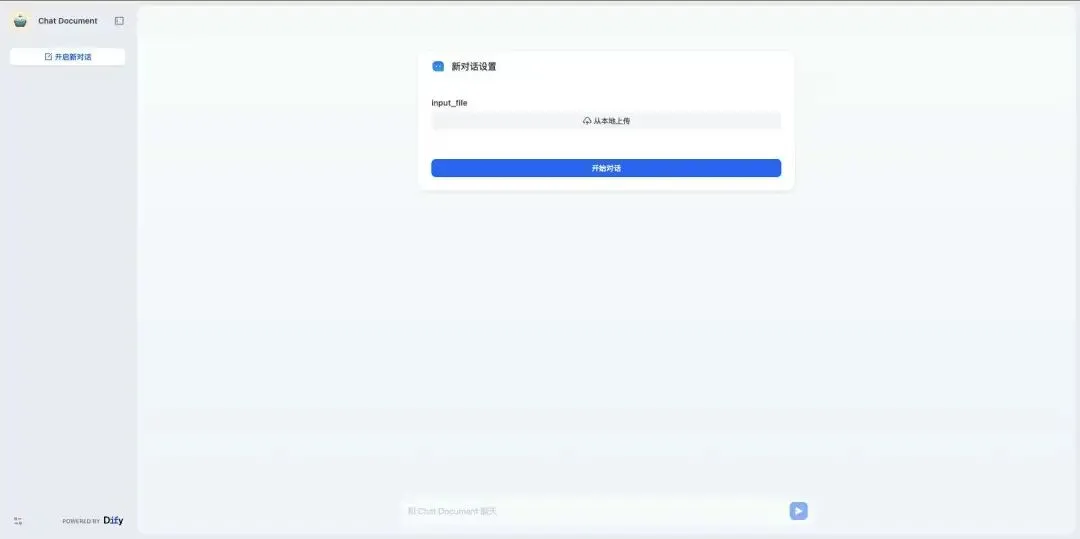
保存并发布你的应用。现在,上传一份PDF或图片,你就可以和它自由对话了!
案例二:自动化批量处理文档,并上传至云端S3
需要处理大量文档并归档?xParse插件同样能胜任。
第一步:安装S3插件
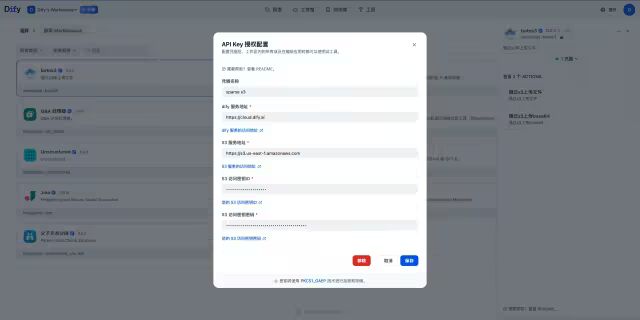
第二步:配置S3 bucket
第三步:创建工作流
选择字段类型为“文件列表”,填写变量名称(此处填为upload_files),支持的文档类型选为文档与图片
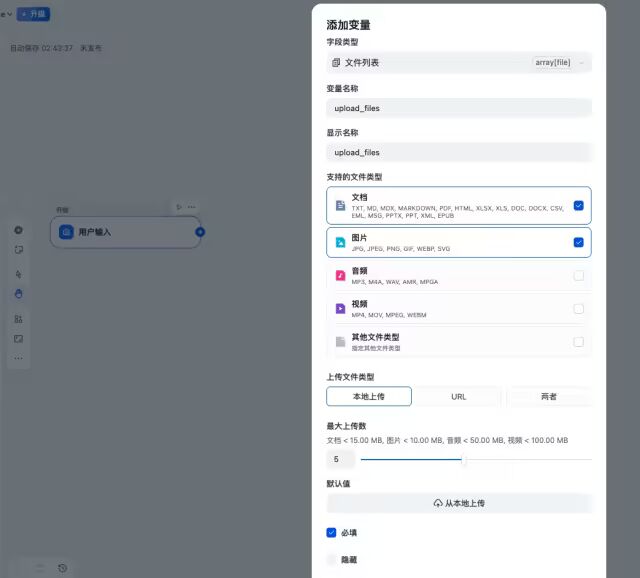
第四步:添加“迭代”
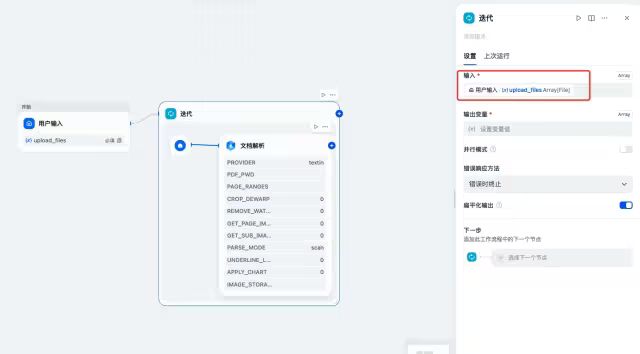
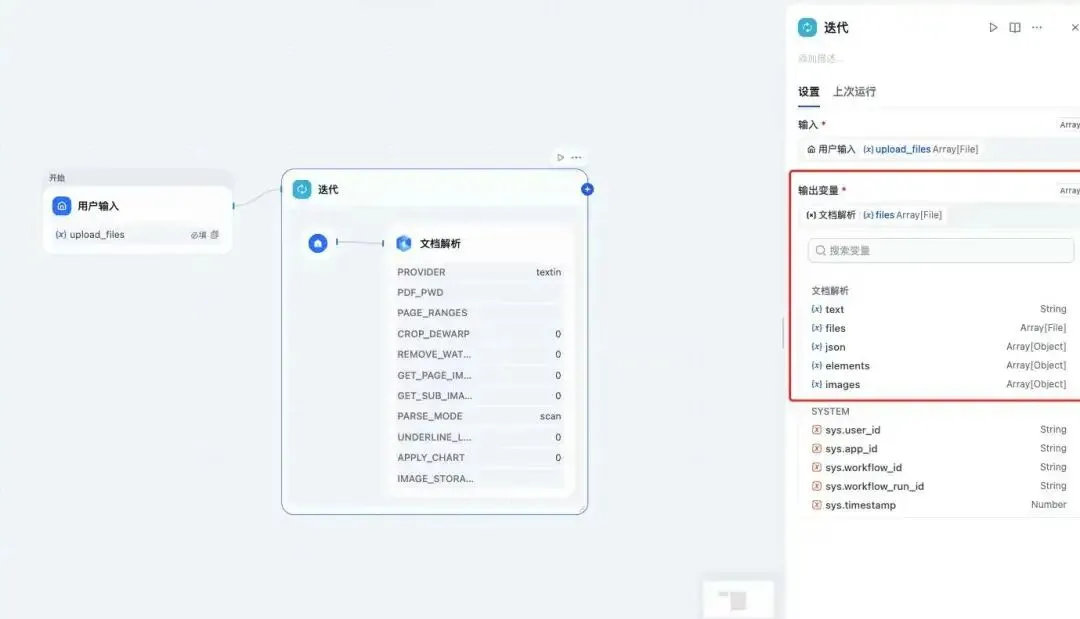
在“开始”节点后添加“迭代”,并配置迭代内的xParse节点,设置迭代的输入为上一步开始节点的upload_files,输出节点暂时不填写,在整个迭代配置完成后选择xParse节点文档解析的files
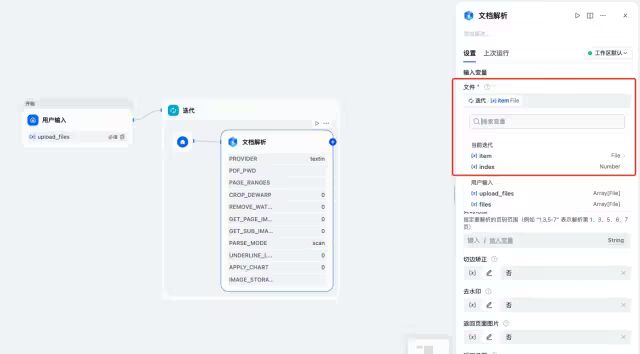
将xParse的输入参数文件(file)选择为迭代器的item
第五步:增加中间节点“代码执行”来转换xParse的解析结果
输入变量(变量名称需与代码定义一致)
-
text:选择xParse文档解析的输出变量 text -
fileName:选择“迭代”节点的 item的name
输出变量(变量名称需与代码定义一致)
-
fileName:String -
base64:String
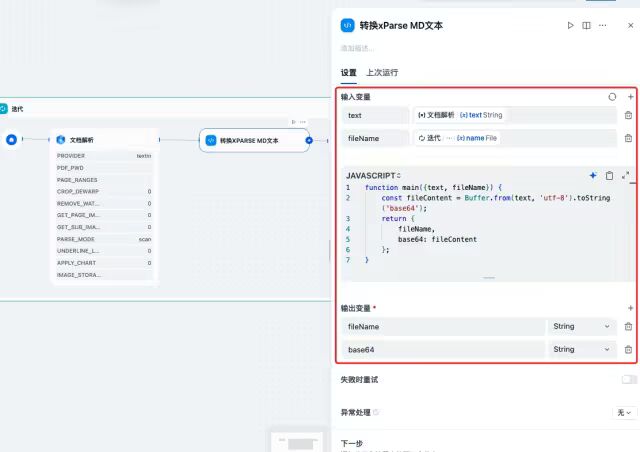
代码选择JavaScript,编写转换代码:
function main({text, fileName}) { const fileContent = Buffer.from(text, 'utf-8').toString('base64');return { fileName, base64: fileContent };}以下为Python版本:
import base64def main(text: str, fileName: str): base64_content = base64.b64encode(text.encode('utf-8')).decode('utf-8')return {'fileName': fileName,'base64': base64_content }第六步:配置S3插件来上传内容
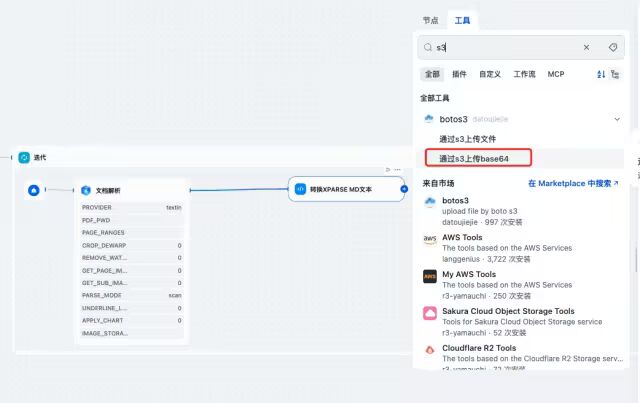
添加工具节点S3,选择“通过S3上传base64”
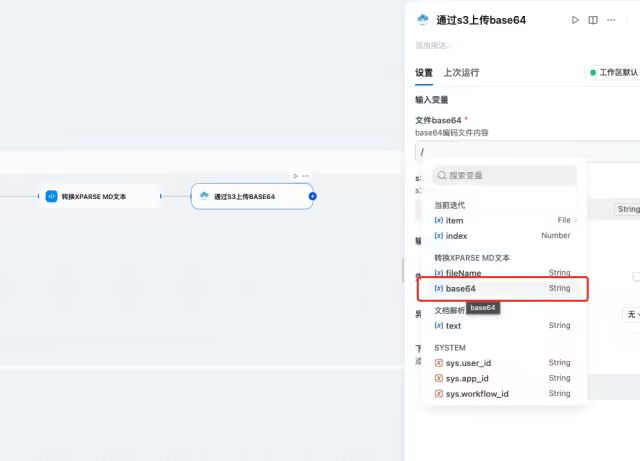
文件base64选择代码执行(图中为转换xParse MD文本)输出的base64字段
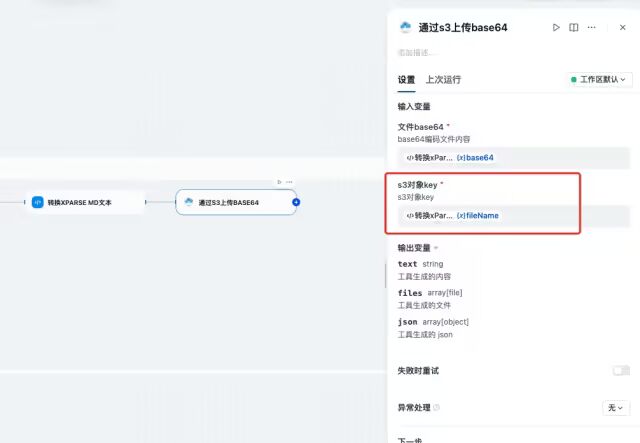
S3对象key填写文件存储的路径,在botos3插件配置界面已经填写了bucket名称,这里只需要填写在 bucket下存储的目录即可。选择代码执行(图中为转换xParse MD文本)的fileName
第七步:预览效果
连接结束节点,至此,一个简单的上传到s3的工作流配置完成,点击“运行”看看效果:
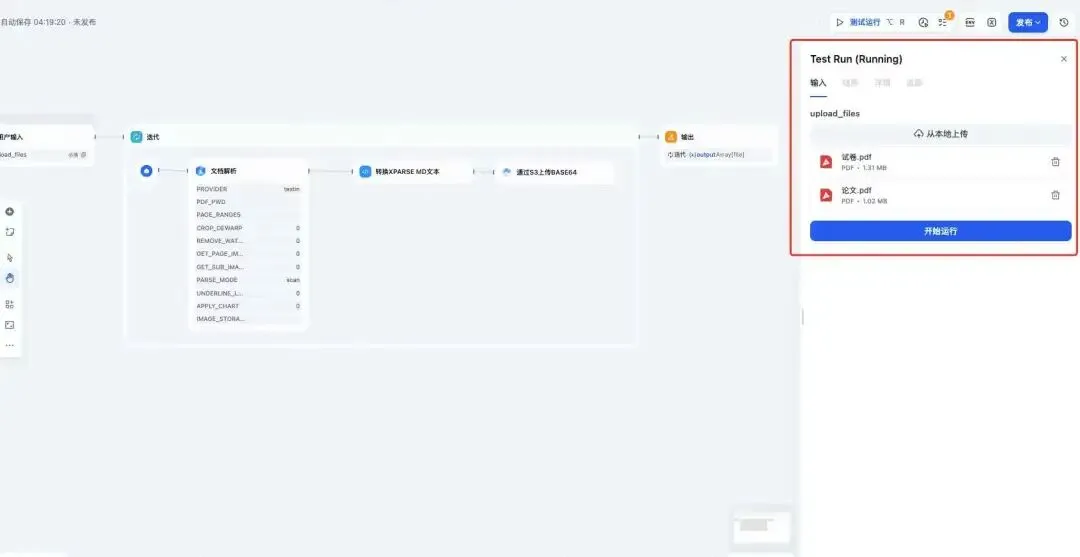
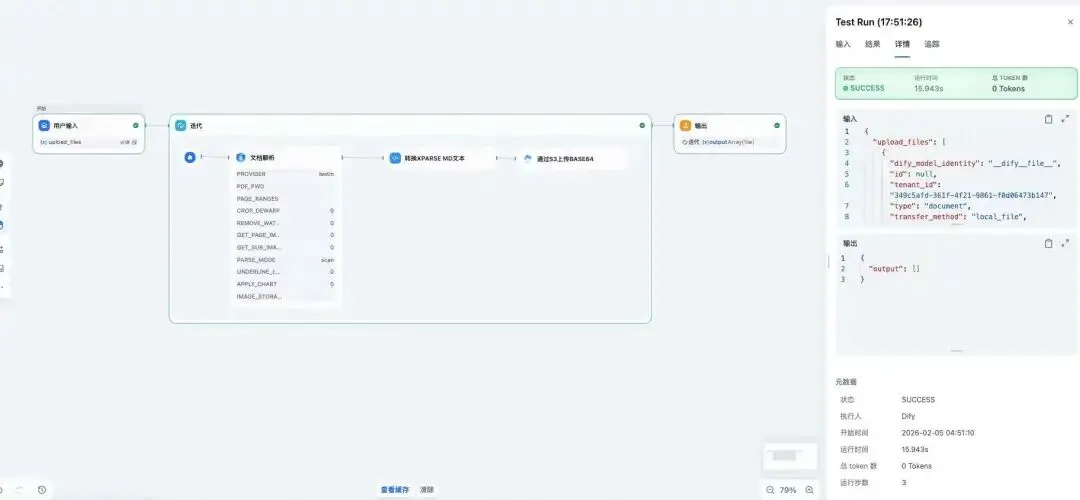
第八步:查看文档
运行结束,可在云存储服务后台查看S3桶内是否已上传解析后的md文件。
三、更多应用场景
xParse Dify插件还支持以下应用场景:
RAG应用构建
使用xParse解析文档后,结合Dify的知识库功能,构建智能问答系统。xParse的智能分块功能可以确保文档被合理切分,保留语义完整性,提升检索效果。
信息提取Agent
结合xParse的信息抽取能力,构建自动化的信息提取Agent,从合同、发票、订单等文档中提取结构化信息,自动完成数据录入和验证。
批量文档处理
使用迭代节点批量处理文档,结合xParse的多种解析引擎,根据文档类型自动选择最适合的解析方案,提升处理效率和准确性。
四、常见问题
Q: 如何选择合适的解析引擎?
A:
-
textin:适合大多数场景,速度和准确性俱佳(推荐) -
textin-lite:适合纯文本、表格图片、电子档PDF等场景,速度更快,价格更低 -
mineru:适合学术论文等场景,表现优异 -
paddle:适合多语言和复杂文档场景(如PPT),表现优异
Q: xParse支持哪些文件格式?
A: xParse支持PDF、Word、Excel、PPT、图片(JPG、PNG等)等多种格式。
Q: 如何获取API Key?
A: 请前往TextIn工作台(https://www.textin.com/console/dashboard/setting)获取x-ti-app-id和x-ti-secret-code,详细获取方式请参考API Key文档(https://docs.textin.com/pipeline/api-key)
Q: 解析后的结果格式是什么?
A: xParse默认返回Markdown格式的文本,同时支持返回JSON格式的结构化数据,包含文档元素、坐标信息等详细信息。

