 夜雨聆风
夜雨聆风





拥抱AI时代的文档管理体系怎么搞?
最近花了不少时间在思考和设计公司新一代的文档系统。
起因很简单:Confluence 越来越让我犹豫了。
尤其是最近我们在做内部的 AI 知识库,想把公司的技术文档喂给 LLM 做 RAG(检索增强生成)。结果发现,Confluence 里导出的那些富文本数据,简直是灾难。一大堆无效的 HTML 标签,混乱的层级结构,还有那些深埋在表格里的关键数据……清洗这些数据的工作量,比训练模型还大。
为了解决这个格式问题,我甚至被逼无奈,自己手写了一个 Confluence 插件,专门用来把它的 HTML 强转成 Markdown。但即便如此,每次格式微调还是要掉几根头发。
这时候我意识到,文档系统到了该换代的时候了。
在 2026 年,文档不应该只是写给人看的,更应该是写给 AI 看的。而Markdown,就是人与 AI 沟通的最好桥梁。
折腾了一圈,我初步锁定了一套设计方案:Markdown + Git + Outline。
今天想聊聊我的设计思路,以及为什么我认为这是未来的方向。
为什么是 Git + Outline?
其实市面上的文档工具多如牛毛,Notion 很强,飞书文档也很好用。但作为技术团队,我们有两个核心诉求是这些 SaaS 工具很难满足的:
- 数据必须掌握在自己手里:我不希望我的文档变成某个 SaaS 平台私有格式的囚徒。
- 要像管理代码一样管理文档:要有版本控制,要有 Code Review,要能自动化检查。
所以,Git是必须的。所有文档,归根结底都应该是一个.md文件,安安静静地躺在 Git 仓库里。
但是,你不能让产品经理和运营同学直接去 Git 里写 Markdown 吧?那体验太硬核了。
这时候Outline就进场了。它的编辑器体验极其丝滑(用过的都懂),原生支持 Markdown,而且界面干净得令人感动。
于是,一个“前后端分离”的想法诞生了:
- 前端(协作层):用 Outline。大家在这里写写画画,讨论问题,体验像 Notion 一样好。
- 后端(存储层):用 Git。所有内容最终都沉淀为 Git 里的 Markdown 文件。
为什么选择 Outline 作为前端?
在选择“前端”工具时,我几乎试遍了市面上所有的开源 Wiki,最后选择了 Outline,主要是因为它在以下几个方面做得太极致了,完美契合我的架构需求:
1. 极致的 Markdown 编辑体验
Outline 虽然是富文本编辑器,但它骨子里是 Markdown 原生的。输入#变标题,输入*变列表,粘贴代码块自动高亮。
最重要的是,它的界面极度干净,左侧是无限层级的目录树,右侧是自动生成的 TOC(目录),对于维护复杂的系统设计文档非常友好。
2. 真正的数据自由
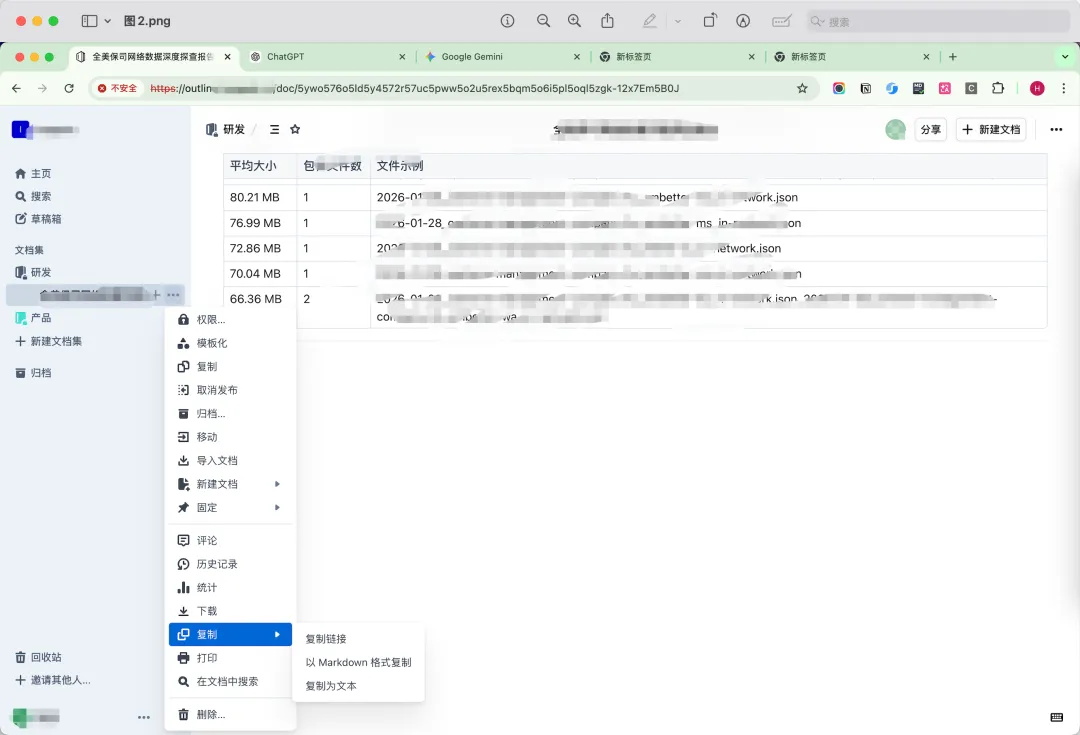
这是我最看重的一点。在 Outline 里,你可以随时把单篇文档甚至整个集合“Copy as Markdown”。它没有私有格式的壁垒,这让我把数据同步回 Git 变得非常容易。
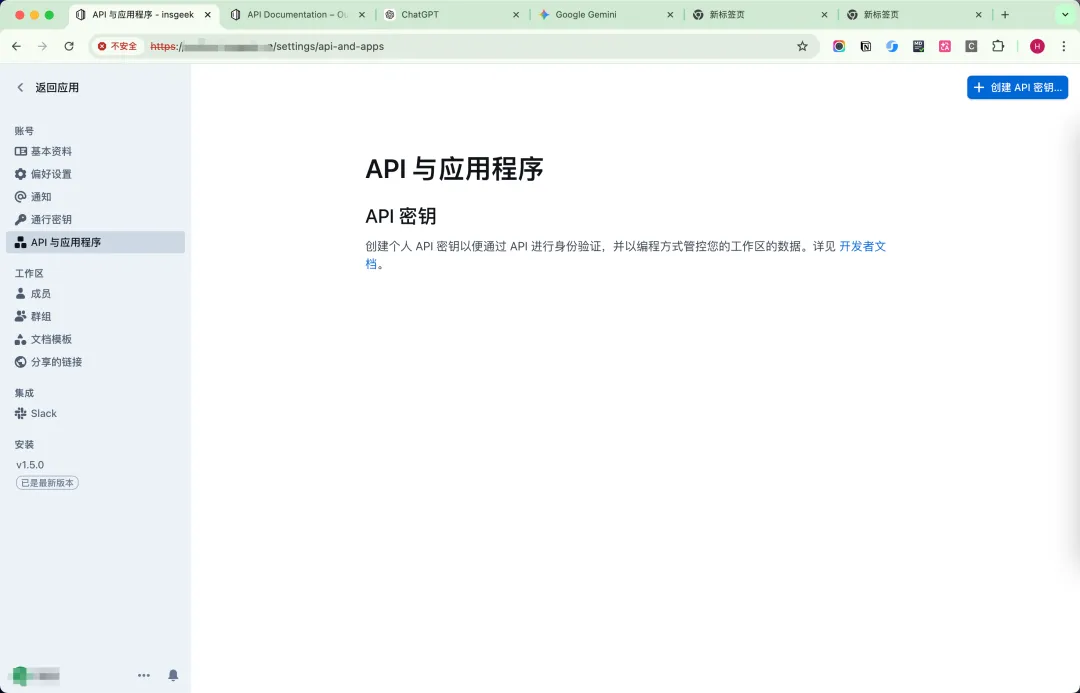
3. API First 的设计
Outline 提供了非常完整的 API,你可以通过 API 创建文档、读取文档、搜索文档。这就为我们后续开发“Git 同步脚本”提供了基础。比如,当 Git 里有代码合并时,可以通过 API 自动更新 Outline 里的 API 文档;或者反过来,Outline 里的文档变更后,通过 Webhook 触发 Git 的 Commit。
这套架构长什么样?
我画了个简单的图,但这玩意儿其实逻辑很简单,核心就是:别按文档类型分目录,要按业务系统分。
以前我们喜欢建一个巨大的“PRD 文件夹”,里面塞满了几百个系统的需求文档。结果就是,开发想找某个系统的 API 定义,得去另一个“API 文件夹”里翻。
现在我的建议是,以系统为核心。
company-docs/
│
├── systems/
│ ├── insurance-core/ ← 【保险核心系统】
│ │ ├── prd.md ← 它的需求在这里
│ │ ├── design.md ← 它的设计在这里
│ │ ├── api.md ← 它的接口在这里
│ │ └── runbook.md ← 它的运维手册也在这里
│ │
│ └── order-system/ ← 【订单系统】
│ └── ...
这样最大的好处是:AI 读得懂。
当你把这个目录喂给 Cursor 或者公司内部的 Copilot 时,它能清楚地知道:哦,这个prd.md是属于insurance-core的。以前那种大杂烩目录,AI 经常会张冠李戴。
给文档加点“元数据” (Front-Matter)
这是我在迁移过程中最强烈的建议:给每个 Markdown 文件头顶加个 YAML Front-Matter。
就像这样:
---
title: 保单管理模块 PRD
system: insurance-core
owner: @sosojust
status: draft
updated:2026-03-06
---
这玩意儿有什么用?用处大了去了。
- 自动催更:我可以写个脚本,每周一扫一遍 Git,把所有
status: draft且updated超过 3 个月的文档 Owner 抓出来,“公开处刑”。
- 精准检索:以后问 AI “保险系统的设计文档在哪”,AI 可以直接过滤
system: insurance-coreANDtype: design,准确率提升 100%。
- 避免“僵尸文档”:以前文档旧了就没人管了。现在我要求,文档废弃了别删,把
status改成deprecated,留作历史档案。
预期的效果
虽然这套系统还没正式上线,但在我的设计推演中,它能解决掉我现在最大的几块心病:
- 搜索快了:在 IDE 里搜文档,比在网页上转圈圈快一万倍。
- 质量高了:因为文档要进 Git,可以像代码一样走 Merge Request。写得烂的文档,Review 不通过,打回去重写。
- 自动化爽了:规划中会配置流水线,文档一提交,自动检查死链(Dead Link)。
- 网站化沉淀:这也是我非常看重的一点。既然所有的文档都已经是标准的 Markdown 了,我计划后续直接挂一个Docusaurus。
-
这样可以把沉淀下来的优质技术文档,直接生成一个内部(甚至对外)的文档网站。 -
不用再专门去维护一个 CMS,文档写完,网站就自动更新了。
当然,这套方案也有门槛。最大的阻力可能来自非技术团队。
我的经验是:别跟他们讲 Git,就让他们用 Outline。同步到 Git 的工作,让脚本在后台默默完成就好。
最后的一点碎碎念
其实工具只是载体,最难的永远是文档文化。
如果团队里的大佬们都不写文档,你换成什么神仙工具都没用。
但至少,用 Markdown + Git,我们把文档的使用权,从 SaaS 厂商手里夺回到了自己手里。在 AI 时代,这可能是最重要的一步资产保卫战。
参考资料
- Outline GitHub: https://github.com/outline/outline
