 夜雨聆风
夜雨聆风





不规则 Excel"数据提取——教师课表自动汇总实战
今天用一个真实案例,带大家用python实战一下不规则的excel数据,怎么一步一步用 Python 把它”驯服”。
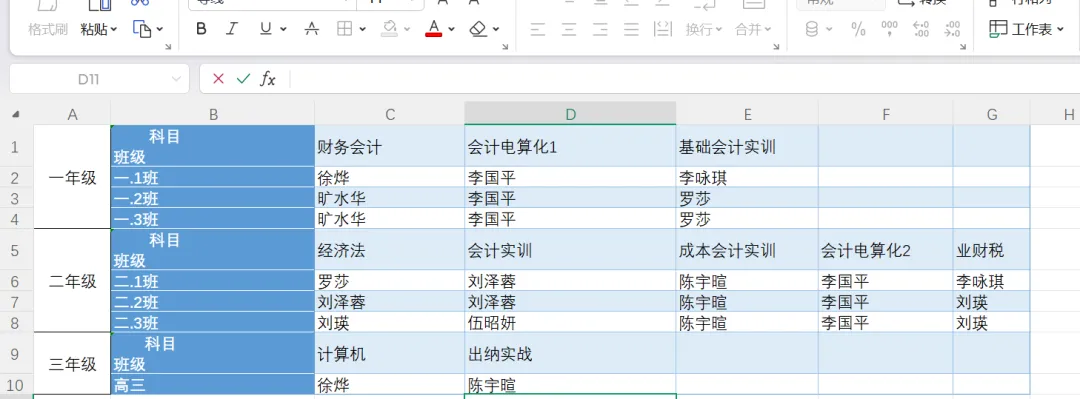
例如下表的excel(20260309.xlsx),结构大致如下:
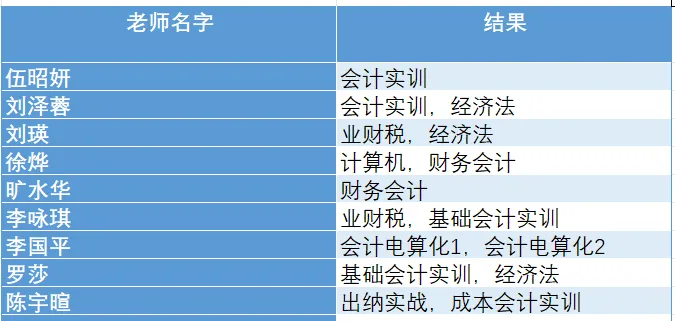
目标输出:每位老师对应教授了哪些不重复科目,格式如下:
这种表格的挑战在于:每个年级的科目数量不同、表头与年级合并在同一行,没有统一的固定格式,无法直接用 pd.read_excel 加表头一步读取。
思路分析
拿到这类”不规则”Excel,核心思路是逐行解析:
-
遇到”一年级/二年级/三年级”→ 读取该行第2列起的科目名,存入 current_subjects -
遇到含”班”字或”高三”的行 → 按列位置将教师姓名与 current_subjects对应 -
用 defaultdict(set)存储结果,set自动去重(同一老师教多个班的同一科目只记录一次)
完整代码解析
1. 数据读取
import pandas as pd
from collections import defaultdict
defread_excel_data(file_path):
"""读取Excel文件,返回原始DataFrame"""
df = pd.read_excel(file_path, header=None)
return df
使用 header=None 是关键。因为表格没有统一表头行,直接读取全部原始数据,保留每一行的原始结构。
2. 核心解析逻辑
defparse_teacher_subject_mapping(df):
teacher_subject_map = defaultdict(set)
current_subjects = []
for _, row in df.iterrows():
col0 = str(row[0]).strip() if pd.notna(row[0]) else""
col1 = str(row[1]).strip() if pd.notna(row[1]) else""
# 年级行:同时也是科目表头行
if col0 in ["一年级", "二年级", "三年级"]:
current_subjects = []
for i in range(2, len(row)):
subject = str(row[i]).strip() if pd.notna(row[i]) else""
current_subjects.append(subject)
continue
# 班级数据行:含"班"字或为"高三"
if col1 and ("班"in col1 or col1 == "高三"):
for i, subject in enumerate(current_subjects):
col_index = i + 2
if col_index >= len(row):
break
teacher = str(row[col_index]).strip() if pd.notna(row[col_index]) else""
if teacher and teacher != "nan"and subject and subject != "nan":
teacher_subject_map[teacher].add(subject)
return teacher_subject_map
几个细节值得关注:
-
pd.notna()判空:Excel 空白单元格读取后是NaN,必须先判断再str()转换,否则会出现字符串"nan" -
set去重:同一老师在多个班教同一科目,用set只记录一次 -
列位置对齐:科目从第2列开始,班级数据也从第2列开始,通过 col_index = i + 2保证对齐
3. 结果格式化与输出
defformat_result(teacher_subject_map):
rows = []
for teacher, subjects in sorted(teacher_subject_map.items()):
subject_str = ",".join(sorted(subjects))
rows.append({"老师名字": teacher, "结果": subject_str})
return pd.DataFrame(rows)
defsave_result(result_df, output_path):
result_df.to_excel(output_path, index=False)
对教师姓名和科目名称都进行了排序(sorted()),让输出结果稳定可预期,而不是依赖字典遍历的随机顺序。
通过上面的代码,就可以完美解决这种问题!!
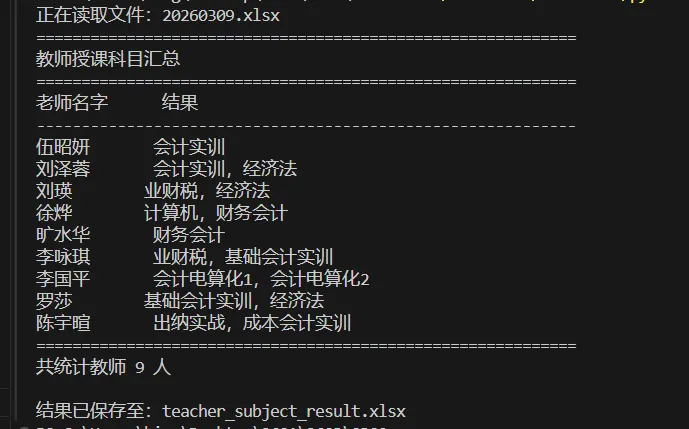
运行结果
代码总结
|
|
|
|---|---|
pd.read_excel(header=None) |
|
pd.notna() |
|
defaultdict(set) |
|
iterrows() |
|
sorted() |
|
举一反三
这套”逐行解析 + 状态机”的思路,适用于大量现实中的不规则表格场景:
-
多门店销售汇总:每个门店一个小表头,数据分段存放 -
项目周报:每周一个标题行,内容逐行展开 -
混合语言报表:中英文表头混合,列数不固定
核心思路不变:识别”分隔标志行”,动态更新当前上下文,逐行提取数据。
代码已整理为完整可运行脚本
analyze_teacher_subjects.py,直接放到 Excel 同级目录执行即可。有问题欢迎留言交流!
🔮 获取和交流
需要本章或其他文章的源码和数据的同学,关注+三连,在对应文章下评论“6666“,加下面微信,发你!也可以拉你进群交流学习,加群备注:IT小本本学习

为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇
