 夜雨聆风
夜雨聆风





OpenClaw 记忆总丢?这个开源插件,想把 Agent 的长期记忆补到“能用”了
有在折腾 OpenClaw 的朋友,大概率都遇到过一个很现实的问题:对话一长,Agent 前面说过的话就开始掉。不是完全失忆,但那种“明明聊过,怎么又像第一次听见”的感觉,很明显。
最近看到一个专门补这块短板的开源插件:memory-lancedb-pro。它本质上还是做记忆检索,但思路已经不是那种“存进去,再靠向量模糊捞一捞”了,而是把整套长期记忆召回链路往生产环境那边拉了一截。它在 README 里明确写了,核心增强包括 混合检索(向量 + BM25)、Cross-Encoder 重排、时间衰减 / 新鲜度加权、MMR 多样性、多作用域隔离 和 管理 CLI,目标就是让 Agent 拿到的不是“沾边的记忆”,而是更近、更准、也更该出现的那几条。
这事听起来有点技术,但落到体感上其实很简单: 以前你问一句,Agent 可能只能凭语义相似度,从一堆旧记忆里摸几条出来。问题是,语义像,不代表现在最该用;关键词对,不代表上下文真相关。memory-lancedb-pro 做的,就是尽量别让它只靠单一路径“瞎蒙”。GitHub 页面列出来的特性里,除了混合召回,还有重排、长度归一化、噪声过滤、会话记忆、任务感知 embedding 这些东西。说白了,它不是只想“记住更多”,而是想让 Agent 记得更像回事。
我觉得这里最值钱的,其实不是“检索更强”这五个字,而是它把很多人实际踩过的坑直接补了。
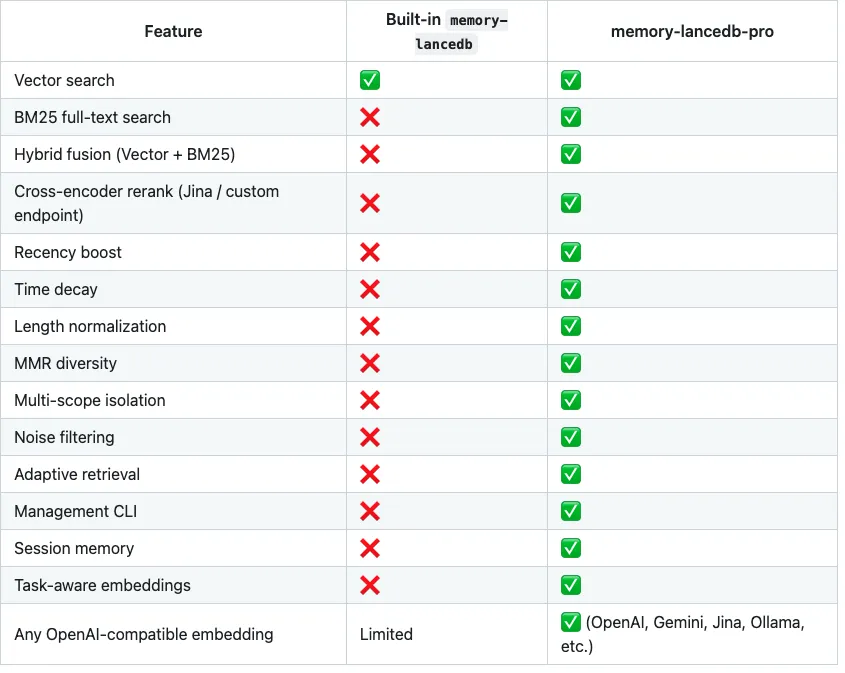
比如长对话里,旧信息会不断堆积,真正重要的那条反而容易被埋掉;又比如多 Agent 或多任务并行的时候,记忆很容易串味。这个插件专门加了 multi-scope isolation,就是把不同范围的记忆隔开处理。还有一点很实用,它兼容 OpenAI-compatible embedding,官方说明里提到可以接 OpenAI、Gemini、Jina、Ollama 等接口,配置空间比很多只绑死单一路线的插件大得多。
另一个我比较喜欢的地方,是它没把“记忆”只当成自动黑盒。项目自带了完整的 CLI 管理工具,你可以手动管理、查看、审计记忆数据。这个细节很重要。很多 Agent 系统的记忆问题,不是不会存,而是你根本不知道它存了什么、捞了什么、为什么捞错了。有 CLI,至少你还能下去翻账本。
所以如果你最近正好在折腾 OpenClaw,又对“小龙虾聊久了就忘事”这件事有点烦,这个插件确实值得看一眼。
它不一定能把长期记忆问题一次性解决掉,毕竟 Agent 的“记忆差”很多时候也不只是数据库的问题。但至少 memory-lancedb-pro 这条路子是对的:别再把长期记忆理解成“存向量 + 做相似度搜索”那么简单,而是把召回、排序、时效性、隔离、审计这些该补的环节都补上。项目目前插件描述里版本为 1.1.0-beta.6,还在 beta 阶段,不过方向已经很清楚了。
GitHub地址: win4r/memory-lancedb-pro