 夜雨聆风
夜雨聆风





不只是调 API:我是怎么把 AI 漫画生成、HTML 排版和公众号草稿发布,串成一条完整流水线的
从零开发 wechat-comic-factory 这个 OpenClaw Skill 的完整实战记录
这篇文章不是官方文档,也不是营销稿。它是我把一个 OpenClaw Skill 从”能跑一半”到”真正可发布”的全过程实录。踩了多少坑,就写多少坑。

一、为什么要做这个 Skill
起点很简单:我想让公众号的漫画内容生产自动化。
不是”帮我写几句文案”那种自动化,而是真正意义上的端到端——用户只说三件事:漫画类型(比如小林漫画或育儿漫画)、主题(比如”成人的体面”)、数量(比如三张)。然后系统自己完成所有事情:想分镜、生图、叠字、拼文章、排版 HTML、上传图片、推送到微信公众号草稿箱。
一开始我以为这只是几个脚本的拼接,很快就能做完。
后来我发现,这件事的真正难点不是”会调 API”,而是:
如何让整条链路稳定、可调试、可重复执行、边界清晰。
每个接口都有自己的异步模式、编码规则、字段限制、报错逻辑。Pillow 叠字、微信 HTML 排版、公众号接口校验,每一关都有坑。Skill 本身的执行约束更是一门独立的学问——AI 不加约束,遇到”发漫画”会先聊天,遇到”发布”会乱猜发布目标,目前该skill已经发布到clawhub,搜索安装wechat-comic-factory开始使用。
这篇文章,就是把这整个过程讲清楚。
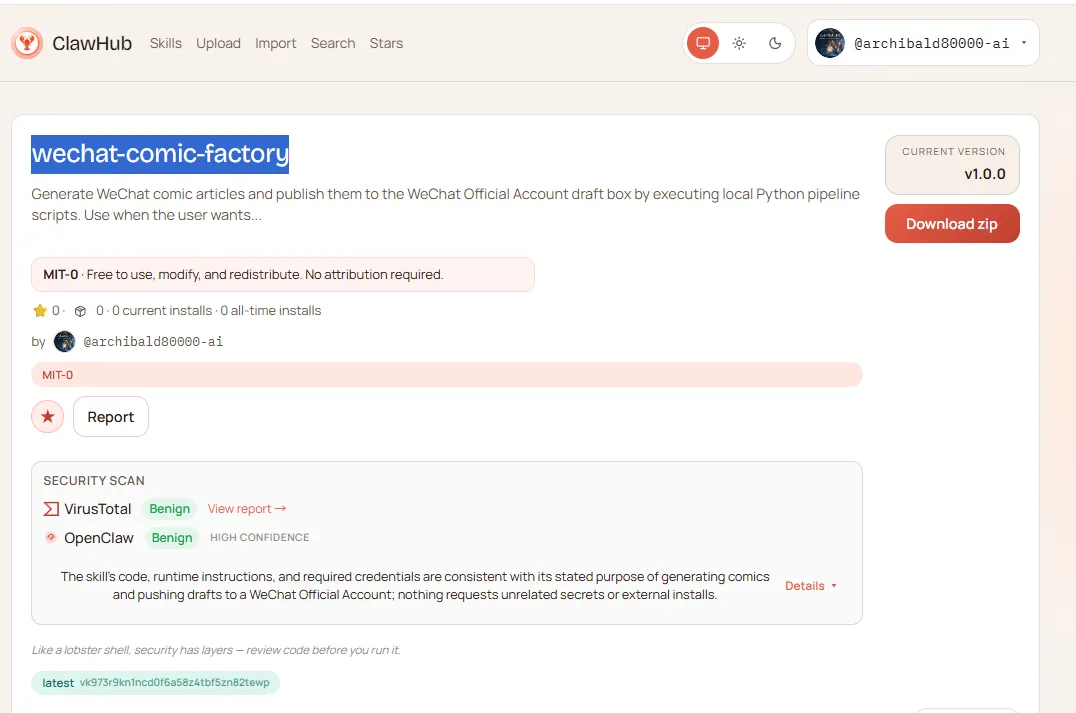
二、先把需求拆成一条流水线
在动手写代码之前,我做了一件最重要的事:把需求拆成一条流水线,每个阶段有独立的职责边界。
流水线一共六个阶段:

每个阶段都有一个独立 Python 文件,可以单独运行调试。整条链路由 run_pipeline.py 串联,作为唯一统一入口。
这个设计不是装饰。在反复调试的过程中,我需要单独重跑某个阶段,而不是每次都从头来。如果把所有逻辑堆在一个大文件里,调试会变成噩梦。
三、项目目录怎么设计才不乱
在项目正式开工前,我也花了一点时间定义目录结构:

这里有几个设计决策我觉得值得解释:
每次任务都有独立输出目录。目录名是 {时间戳}_{漫画类型英文缩写},比如 20260313_093520_xiaolin。这样做的好处是:每次执行不会覆盖上一次,失败了也能保留现场,方便复盘。
latest_task.json 作为全局指针。这个文件只存一件事:指向最近一次任务的输出目录路径。当用户说”发布最近那个”,系统就通过这个文件找到任务,而不是靠 AI 去猜。
task_result.json 记录阶段状态。每次流水线执行(无论成功还是失败),都会把结果写进这个文件,包括 stage(失败在哪个阶段)、draft_status(not_started/pending/failed/success)等字段。后续重试或发布时,先读这个文件,而不是盲目重跑。
config.json 只在本地存在。API key、微信 appid/appsecret 之类的敏感信息只存本地,不进 Git。项目里只提供 config.example.json 作为脱敏模板。
四、文本规划阶段:为什么大模型输出的 JSON 不能直接信
第一个阶段是 plan_comics.py,职责是调文本模型,拿到整组漫画的策划内容。
最初的设计很简单:把 prompt 发给 DeepSeek,把返回的内容当 JSON 解析,完事。
第一个坑:大模型会在 JSON 前后输出解释性文字。
比如模型返回的是:

直接 json.loads() 会报错。
解决方案是在 common.py 里实现了一个 extract_json_object() 函数,专门从字符串里提取第一个完整的 JSON 对象——跳过前缀文本、去掉 markdown 代码块标记、扫描第一个 { 到对应的 } 结束。
第二个坑:模型输出的字段名会漂移。
有时候 image_prompt 会变成 prompt,有时候 items 会变成 comics。如果不做字段校验,后续阶段就会因为找不到字段而静默失败。
解决方案是在 validate_plan_payload() 里做严格校验:title、intro、ending、items 都必须存在,items 的数量必须严格等于输入的 count,每个 item 里的 image_prompt 和 caption 都不能为空。
第三个坑:count 和 items 数量不一致。
我让模型生成三张,它有时候给我四张,有时候给我两张。偶发,但真实存在。
现在的处理方式是:如果不一致就直接抛 SkillError,明确报告 expected: 3, actual: 2。不重试,不脑补,强制让上层知道失败了。
Prompt 文件本身也做了硬性约束。prompts/xiaolin.txt 里有这样一段:

Prompt 模板用 __COMIC_TYPE__、__TOPIC__、__COUNT__ 作为占位符,plan_comics.py 在运行时用字符串替换填入实际值。这样做的好处是:改提示词不需要改代码,不同风格的漫画可以用不同模板文件,互相隔离。
一次真实的 plan.json 输出大概是这样:

这个 JSON 一旦通过校验,就写入 plan.json,下一阶段从文件读取。阶段之间不通过内存传递,而是通过文件。这让每个阶段可以单独调试,也让失败的现场可以保留。
五、图片生成不是”调一次接口”就完了
generate_comic_images.py 是整条链路里花时间最多的一个阶段。
最开始我以为生图接口是同步的:发一个请求,等一会儿,拿回图片 URL。
错了。DashScope 万相接口是异步任务。
真实的流程是四步:
- 提交任务
:POST 请求提交 prompt,接口立即返回一个 task_id,图片还没有。 - 轮询状态
:每隔若干秒 GET 一次任务状态,直到 task_status == "SUCCEEDED"。 - 提取图片 URL
:从任务结果里找到真实的图片地址。 - 下载图片
:把图片下载到本地。
光是”提取图片 URL”这一步就踩了坑。wanx-v1 旧模型的返回结构是:

而新的 wan2.6 等模型家族的结构是:

两套结构完全不同。如果只写一种,切换模型就会报错。
解决方案是用 resolve_dashscope_family() 判断模型名称前缀,然后分别用 extract_legacy_result_url() 和 extract_message_result_url() 提取 URL。还有一个保底方案:如果两个都没提取到,用递归遍历把所有 http 开头的字段值都收集起来,取第一个。
另一个需要注意的点是 header 差异:提交任务时需要带 X-DashScope-Async: enable,轮询时不需要这个 header。如果轮询时带着它,接口行为可能不符合预期。代码里专门在 poll_dashscope_task() 开头把这个 header 从字典里 pop() 掉。
还有超时控制。生图可能要两分钟,也可能要五分钟,甚至偶尔更长。config.json 里有 dashscope_poll_interval(轮询间隔,默认 10 秒)和 dashscope_timeout_seconds(总超时,默认 300 秒)两个参数,可以根据实际情况调整。超时后直接抛错,不会无限等待。
六、Pillow 叠字为什么决定成品感
图片下载完之后,还有一步:在图片底部叠加文案。
这一步决定了图片”看起来像公众号成品”还是”看起来像测试图”。
核心逻辑在 overlay_caption() 函数里。做法是:
-
打开原始图片,转成 RGBA 模式。 -
新建一个同尺寸的透明图层作为 overlay。 -
计算文案行数和底部面板高度,画一个半透明黑色圆角矩形底板( fill=(0, 0, 0, 160),大约六成不透明)。 -
在底板上写白色文字,透明度 235。 -
用 alpha_composite把两层合成,转回 RGB 保存。
自动换行不能用固定字符数,因为中文等宽但英文不等宽。代码里是逐字符拼接,每次拼一个字符后用 textbbox 测量像素宽度,一旦超出可用宽度就换行。这是真正基于像素的换行,不会出现截断或溢出。
字体回退链:项目自带的 fonts/MiSans-Regular.ttf 是首选。如果找不到,按顺序尝试 NotoSansSC-VF.ttf、simhei.ttf、msyh.ttc、simsun.ttc。最后实在找不到,用 Pillow 内置的默认字体(效果很丑,但不崩溃)。
行距、边距、字号都通过 config.json 的 defaults 段控制:
“caption_font_size”: 34, “caption_line_spacing”: 12, “caption_padding_x”: 42, “caption_padding_y”: 30
调整这几个数值,就能控制文案区的视觉观感。不需要改代码,只改配置。
最终生成的图分两套:raw_images/ 存原始生图(没叠字),images/ 存叠字后的成品图。保留原始图是为了方便重新叠字,不用重新生图。
七、Markdown 和公众号 HTML 不是简单的格式转换
生完图之后,接下来要组装文章。分三步:build_comic_markdown.py → compress_image.py → format_article.py。
先出 Markdown,再转 HTML
为什么先落地 Markdown?
Markdown 是一种”可读”的中间格式。如果直接从数据结构生成 HTML,出问题时很难看出哪里不对。先生成可读的 Markdown,至少能确认文章内容结构是正确的,然后再转 HTML。
build_comic_markdown.py 的逻辑很简单:从 manifest.json 读取标题、导语、图片列表、结尾,按照固定模板拼成 Markdown 文件。图片引用用相对路径(images/01.png),方便后续处理。
压缩:封面和正文分开处理
微信公众号对图片有严格要求,封面图尺寸和大小都有限制。compress_image.py 做两件事:
- 封面图
:取第一张图,裁剪成 900×500 比例,压缩到 64KB 以内。 - 正文图
:每张图压缩到最长边不超过 1280px,大小不超过 768KB。
压缩算法用的是”渐进降质”:从 quality=92 开始,每次降 7,直到满足大小要求。如果降到最低质量还是太大,再等比缩小分辨率,循环继续。这比直接设一个固定 quality 值更可靠,不会把图压得太模糊,也不会超出大小限制。
压缩结果写入 publish/ 子目录,同时更新 publish_assets.json,记录每张图的本地路径和压缩参数。
公众号 HTML:不能照普通网页思路写
这里踩的坑最多,值得单独讲。
坑一:不能用外部 CSS。
微信公众号后台会过滤掉 <style> 标签和 class 属性,所有样式必须写成 inline style。这意味着每个 <p>、<section>、<img> 都要带上完整的 style 字符串。代码里有专门的 render_paragraphs() 函数,把文本段落渲染成 <p style="..."> 格式。
坑二:整体容器宽度要固定 600px。
公众号文章的渲染环境不是标准浏览器,宽度适配依赖固定宽度容器。最外层 <section> 设 width:600px;margin:0 auto;,内部元素用百分比布局(比如 width:88%)适配内边距。
坑三:图片必须换成微信可访问的 URL。
本地路径 output/publish/01.jpg 在微信服务器上是访问不到的。图片必须先通过微信接口上传,拿到微信返回的 url,再把这个 url 填入 HTML 的 <img src>。
format_article.py 在生成 HTML 的过程中,如果 upload_to_wechat=True,就对每张正文图调用 /media/uploadimg 接口,把图上传到微信素材库,拿到 remote_url,然后用这个 URL 生成对应的 <img> 标签。
坑四:JSON 序列化默认会把中文变成 \uXXXX 乱码。
这个坑藏得很深,我调试了好久才找到。
问题出在把 content_html(文章正文 HTML 字符串)通过 API POST 发给微信时。Python 的 requests 库默认会把 json=payload 序列化成 ASCII 安全的 JSON,也就是中文会变成 \u6210\u5e74... 这种形式。微信接收到这串内容,直接存储并渲染,用户看到的文章正文就全是乱码。
修复方法:不要用 requests.post(json=payload),改成 requests.post(data=json.dumps(payload, ensure_ascii=False), headers={"Content-Type": "application/json"})。这样中文就能正确传输。
common.py 里的 wechat_post_json() 封装了这个逻辑,所有微信接口都通过这个函数发请求。
HTML 的实际结构长这样(简化):

publish_draft.py 里的 extract_wechat_content() 用 BeautifulSoup 从 final.html 中提取 id="article-root" 容器的内部内容(不含外层 <html>/<body> 结构),作为微信草稿的 content 字段值。微信接口只接受正文 HTML 片段,不需要完整页面结构。
八、微信公众号发布阶段:为什么最容易翻车
publish_draft.py 是最后一关,也是踩坑最密集的地方。
整个发布流程分四步: 1. 获取 access_token2. 上传封面图,拿到 thumb_media_id3. 组装草稿 payload,调 /draft/add 接口 4. 把 media_id(即 draft_id)写入结果文件
access_token 缓存
微信的 access_token 有效期是 7200 秒(两小时),但频繁刷新会被限流。
common.py 实现了本地文件缓存:每次获取 token 时,先读 logs/wechat_token_cache.json,判断 token 是否还在有效期内(保守减去 300 秒缓冲)。如果有效,直接用缓存值;如果过期,才重新请求。
踩坑 1:40164 invalid ip
这是开发过程中最让人抓狂的错误之一。错误信息是:
errcode=40164,
errmsg=invalid ip xxx.xxx.xxx.xxx,
not in whitelist
意思是:你的服务器 IP 不在微信公众平台的 IP 白名单里。
在本地开发环境,你的 IP 可能每次都不同,或者用的是 VPN/代理出口 IP。解决方法:登录微信公众平台 → 开发 → 基本配置 → IP 白名单,把当前 IP 加进去。
本地开发时,可以先用 curl ifconfig.me 查出当前出口 IP,加进白名单。如果 IP 经常变,开发期间可以临时关掉 IP 校验(注意生产环境要开启)。
踩坑 2:标题字段的 UTF-8 字节数限制
微信草稿接口对标题有长度限制(最多 64 字节 UTF-8)。很多人以为是字符数,其实是字节数。一个中文字符占 3 字节,所以 64 字节大约只能放 21 个中文字。
代码里用 truncate_utf8_bytes() 做精确截断,逐字符累加 UTF-8 编码字节数,超限就停。这样不会截断半个字符。
如果接口返回 errcode=45003(title 超限),publish_draft.py 还有一个自动重试逻辑:用主题词(topic)截取一个更短的标题,重新提交。最多重试一次。
踩坑 3:摘要(digest)的限制
digest 字段限制是 120 字节 UTF-8,约 40 个中文字。
草稿接口的 digest 是文章摘要,会显示在公众号文章列表页。publish_draft.py 的优先级是:用 intro(导语)→ topic(主题词)→ 第一张图的 caption。无论哪种来源,都要先做 normalize_wechat_text()(去掉换行符、合并空格)再做字节截断。
同样,如果接口返回 errcode=45004,会自动重试一次,用更短的摘要。
踩坑 4:author 字段的限制
微信草稿接口的 author 字段不是随便填的,不同账号主体类型有不同限制。一个可靠的做法是:不填 author 字段,让微信自动用账号名。现在的代码里就没有传 author。
成功的标志
发布成功后,接口会返回:

这个 media_id 就是草稿 ID,记录在 task_result.json 的 draft_id 字段。拿到草稿 ID,去微信公众平台的草稿箱里就能找到这篇文章。
九、为什么要把 Skill 设计成”严格执行型”
做完流水线,我以为项目就完了。结果试用下来发现,AI 本身是最大的不确定因素。
不加约束的 Skill,遇到”帮我生成一组漫画”,会先输出一大段创意方案、标签建议、传播思路;遇到”发布刚才那个”,可能会理解成”在聊天里发消息”;遇到模糊指令,会自己脑补发布目标,比如发到个人微信、发到群里、发到博客。
这些行为都是合理的语言模型行为,但对一个工程工具来说是灾难性的。
SKILL.md 里建立了一套严格的执行约束,核心规则有四条:
规则一:只能执行 run_pipeline.py,不能拼接底层脚本。
用户调用这个 Skill,唯一允许的执行方式是:

Skill 不能绕过主入口直接调 plan_comics.py 或 generate_comic_images.py,否则状态管理就乱了。
规则二:”发布”只允许解释为”推送到微信公众号草稿箱”。
明确禁止把”发布”解释成:个人微信聊天、微信群消息、当前对话回复、任何 message/channel 工具发送。
规则三:模糊指令必须先澄清。
“这个直接发”、”发出去”、”就这个”——这些都是模糊指令,必须先问清楚是哪个任务。推荐的澄清方式是具体化:
当前最近任务为《成年人的体面》三张系列,是否推送该整组内容到公众号草稿箱?
注意:澄清时不允许追问其他平台,只问是不是发到公众号草稿箱。
规则四:只有脚本真实返回成功,才能说”已发布”。
如果 task_result.json 里的 draft_status != "success",绝对不能说”已发布”、”草稿已创建”。脚本执行失败,只能说:
-
发布失败,失败阶段为 publish_failed -
尚未发布 -
未检测到可用微信草稿发布结果
这条规则的意义在于:“发布成功”不是一个话术问题,而是一个工程事实。只有微信接口真实返回了 media_id,才算成功。
Skill 的输出风格也做了约束:信息充分时直接执行命令并返回脚本结果,信息不足时只用一句话澄清,不要输出大段推理过程,不要先说”我来帮你看看”。
十、状态管理的全貌
整条流水线的状态管理,靠两个文件支撑:task_result.json 和 latest_task.json。
task_result.json 是每个任务目录里的状态文件,结构大概这样:

stage 字段记录流水线走到哪一步。如果失败,值会是 planning_failed、image_generation_failed、markdown_failed、compression_failed、html_failed、publish_failed 其中之一,精确定位到哪个环节出了问题。
draft_status 字段有四个值: – not_started:还没跑到发布阶段(或者用了 --skip_publish) – pending:内容已生成,等待发布 – failed:发布阶段出错 – success:成功推送到草稿箱
latest_task.json 只存一个指针:

--publish_latest 模式就是靠这个文件找到最近任务。
两个文件合在一起,让整个流水线可以做到:任何时候知道任务在哪个状态,任何时候可以精确断点续发,而不是每次从头重跑。
十一:真实踩坑复盘
把整个开发过程里最典型的返工点列在这里,希望后来者少走弯路。
坑 1:以为把脚本写完就算完成了
流水线的六个脚本写完,每个单独跑都成功,但联调时发现:阶段之间传递的文件路径格式不一致,某些字段名在上下游之间有出入。单元可以通过,集成就会崩。
教训:每个阶段独立开发完,必须做完整链路联调,不能只靠单阶段测试。
坑 2:以为图片接口是同步的
第一版代码对 DashScope 接口发完请求就等返回值,结果收到的是一个 task_id,而不是图片 URL。花了半小时才明白这是异步接口。
教训:看接口文档时要特别注意”异步任务”字样,不要假设接口是同步的。
坑 3:HTML 粘进公众号后台样式全丢
本地浏览器看 final.html,排版很漂亮。粘进微信公众号编辑器,所有样式消失,变成纯文本。
原因:<style> 标签被过滤,class 属性被过滤。只有 inline style 能存活。
这一关返工了整个 format_article.py 的 HTML 生成逻辑,全部改成 style 字符串内联。
坑 4:正文变成 \u6210\u5e74\u4eba... 这种乱码
发布成功,草稿出来了,但正文全是 Unicode 转义字符。打开微信公众平台一看,文章正文写的全是 \u6210\u5e74\u4eba\u7684\u4f53\u9762。
定位:requests.post(json=payload) 默认用 ASCII 安全序列化。
修复:改成 requests.post(data=json.dumps(payload, ensure_ascii=False), headers={"Content-Type": "application/json"})。
坑 5:Skill 触发后 AI 先聊天而不是执行
测试时发现,用户说”帮我生成一组小林漫画”,AI 先输出了一大段”以下是我为你设计的创意方案……”,然后才问要不要执行。
这就是没有执行约束的结果。
修复:在 SKILL.md 里明确写入”信息充分时直接执行命令,不输出创意方案、平台建议、标签建议”,并且列出了明确禁止的行为清单。
坑 6:以为”发布了”就等于”在聊天里说成功了”
测试 Skill 时发现,偶尔 AI 会在脚本实际未执行的情况下,根据上下文”推断”已经发布成功,然后告诉用户”已推送到公众号草稿箱”。
这是最不能容忍的错误:虚假的成功告知。
修复:SKILL.md 里写入”只有脚本返回 success=true 且 draft_status=success 时,才可以说已发布”,以及明确列出在脚本未返回成功结果时只允许说的话。
十二、最终效果与验收
把所有问题修完之后,做了一次完整的端到端验收:
第一步:单独跑 plan_comics.py,确认 plan.json 格式正确。
第二步:跑 generate_comic_images.py,确认三张图正常生成,叠字效果达标。
第三步:跑 run_pipeline.py --skip_publish,确认整条链路(除发布外)都跑通,生成 final.html,本地浏览器验证排版正确。
第四步:跑 run_pipeline.py --publish_latest,确认草稿推送成功,微信公众平台草稿箱里出现了这篇文章。
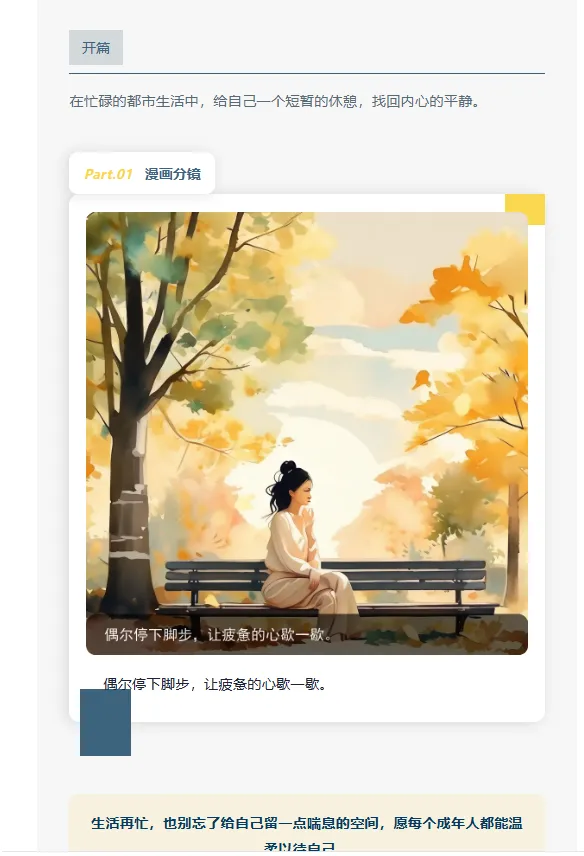
最终结果:

草稿 ID 生成,登录公众平台,草稿存在,内容正确,图片正常显示,排版符合预期。
结语:从”工程存在”到”工程可用”,差的是这些
回顾整个开发过程,我写出了六个脚本,但真正的工时大概有三分之一花在调接口、改 HTML 排版上,另外三分之一花在”让整条链路稳定”上——状态管理、错误捕获、断点续发、自动重试、字段校验。
最后还有那个不起眼但至关重要的部分:让 Skill 知道自己能做什么、不能做什么。
一个工程工具,如果执行边界模糊,就会变成”聊天工具”。用户说”发漫画”,AI 聊了半天创意,什么都没执行。用户说”发布”,AI 乱猜发布目标,把结果搞混。
SKILL.md 里那几条执行约束,看起来是文字规则,本质上是工程纪律。
这个项目适合谁
-
想学 OpenClaw Skill 开发、理解”严格执行型 Skill”怎么设计的人 -
想把 AI 大模型、图片生成、Pillow、微信公众号接口串成一条工作流的 Python 开发者 -
想做”AI 内容生产 + 自动发布”的内容团队
如果你准备照着这篇文章复刻,最小配置只需要三样东西:
-
DeepSeek API key(文本规划) -
阿里云 DashScope API key(图片生成,万相模型) -
微信公众号 appid 和 appsecret,以及已配置好的 IP 白名单
剩下的,让流水线来做。

本文基于 wechat-comic-factory 项目实际代码编写,所有错误案例均来自真实开发记录。