 夜雨聆风
夜雨聆风





无需标注自监督式将工业级软件工程领域文档转化为高质量知识图谱!代码已开源!

介绍一篇关于“如何用大语言模型自动构建领域知识图谱”的论文,题目是 LKD-KGC:基于大模型驱动的知识依赖解析,实现领域知识图谱构建。论文以工业级软件工程知识图谱构建为示例展开了详细的介绍:
(1) 自动“领域术语表/概念字典”需求文档里经常存在概念不一致:同一个东西在不同团队叫法不同。LKD-KGC 的 schema 定义模块,本质上就是在做“术语发现—聚类归一—生成定义”,这对需求一致性和跨团队对齐非常关键。
(2) 需求追踪与影响分析的底座当你能从 PRD、接口文档、架构设计、配置说明、告警手册中抽出实体与关系,就可以形成一张“可查询的工程知识图谱”。例如:
-
需求 → 涉及模块/接口 → 相关配置项 → 关键指标/告警规则
-
某配置项变更 → 影响的服务 → 关联的 SLO → 可能触发的告警这相当于把“追踪矩阵”从手工维护变成自动生长。
(3) 面向工程真实结构:文档顺序就是知识依赖顺序企业知识库的难点往往不是“没有信息”,而是“信息有,但结构混乱”。LKD-KGC 的“依赖评估”很像一种自动的“知识导航与学习路径规划”:先建立全局摘要索引,再推断阅读顺序,再用已学上下文理解新文档。这种思路对大型系统的新人上手、知识库重构、需求知识传承都很有帮助。
1. 背景:为什么“领域知识图谱”难做、但又很需要?
知识图谱把信息组织成三元组:(主体实体, 关系, 客体实体),再把大量三元组连接成图结构,从而支持检索、问答、推理等任务。对软件工程来说,知识图谱可以把“需求—设计—代码—配置—日志—运维实践”等分散信息连起来,用于:
-
需求追踪(某个需求对应哪些模块、哪些配置、哪些运行指标)
-
变更影响分析(改一个组件会影响哪些功能/告警/接口)
-
运维与故障诊断知识沉淀(现象—指标—根因—处理步骤)
但真正难点在于:领域知识图谱往往来自“企业内部文档/技术规范/运维案例”这类私有语料,人工构建慢、成本高;而且很多文档含大量缩写、术语、隐含前置知识,不熟悉领域的人很难准确抽取实体和关系。
论文把领域语料的挑战总结成三类:
-
知识依赖复杂:知识通常从基础概念到高级概念逐层推进,很多文档互相引用;
-
领域性强:术语密集、缩写多、实现细节复杂;
-
参考知识有限:企业内部系统资料往往无法从公开互联网或公共知识库获取。
这些特点使得“直接用大模型对单篇文档做抽取”经常效果不好:要么抽不到关键关系,要么会幻觉出不可靠的实体关系。
2. 现有方法的问题:为什么还需要新的框架?
论文回顾了三条主流路线:
-
微调模型生成三元组:需要训练数据,且领域更新快、标注难,现实中常缺数据。
-
Schema(本体/模式)引导抽取:如果有成熟 schema 能很好用,但很多企业文档并没有现成本体;手工定义 schema 又贵又慢。
-
引用外部知识(检索/公共KG)辅助抽取:对公开领域有效,但对企业内部系统常常“检索不到”或检索到无关信息,反而引发幻觉。
论文认为,关键缺口在于:大多数方法忽略了“跨文档的知识依赖顺序”。在软件工程里,这就像你让一个新人直接看“故障处理最佳实践”,但他没先看“系统架构与核心概念”,理解就会断层,抽取出来的知识也会乱。
3. 核心思路:像人学习一样“先基础后高级”,再自动长出 schema
这篇论文提出的框架叫 LKD-KGC,核心想法可以概括为一句话:
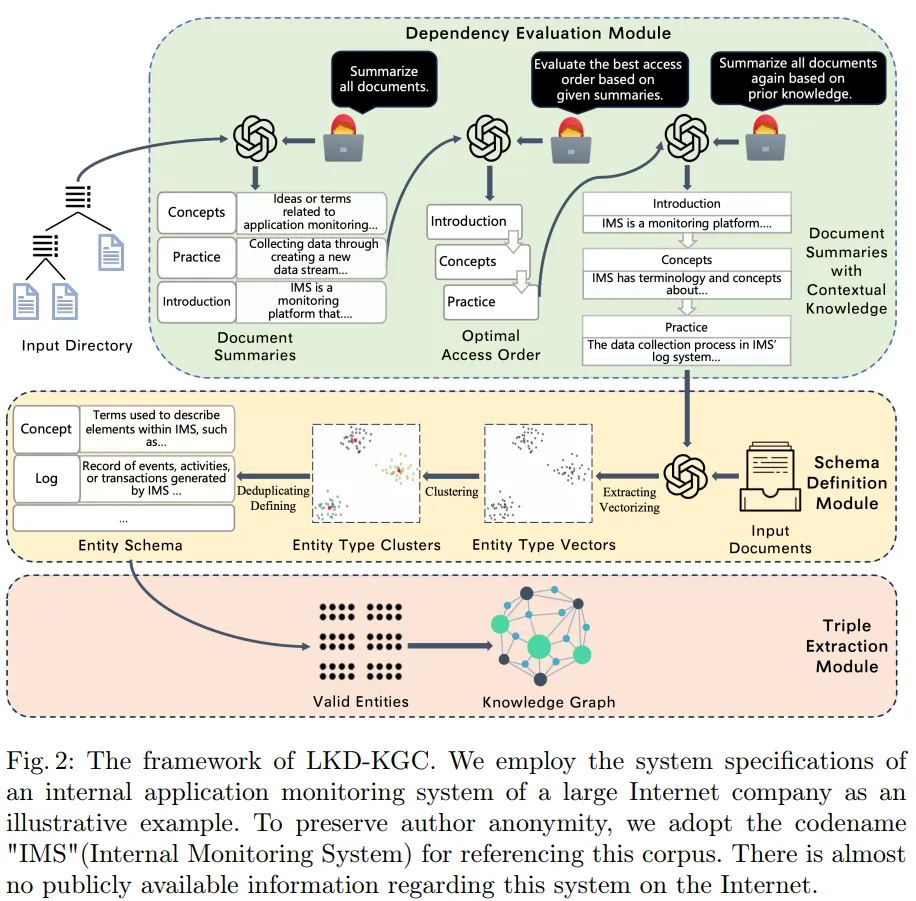
把文档库当作一个“知识体系”,先推断“最佳阅读顺序”,再利用按顺序积累的上下文,自动生成实体类型 schema,并在 schema 约束下抽取三元组。
它不是一上来就抽三元组,而是分三步走:
-
Dependency Evaluation(依赖评估):推断文档的“理解优先级/访问顺序”,并生成带历史上下文的摘要;
-
Schema Definition(模式定义):从“原文 + 摘要”抽取实体类型,聚类去重后形成 entity schema(类型+定义);
-
Triple Extraction(三元组抽取):在 schema 的约束下先抽实体,再抽实体间关系,得到知识图谱。
4. 模块一:依赖评估–如何推断“最佳阅读顺序”并生成上下文摘要?
很多软件文档天然有目录树结构:比如“Introduction / Concepts / Best Practices”。论文的观察是:领域知识存在“理想阅读顺序”,比如先读系统介绍,再读核心概念,最后读实践案例。这非常符合软件工程的知识组织方式,也很像需求工程里“先业务目标与范围,再需求分解,再设计与实现细节”。
依赖评估模块主要做三件事:
(1) 自底向上:先给每个文档/目录生成摘要
-
先遍历整个目录树,对叶子文档分别总结摘要;
-
再把子节点摘要汇总成父目录摘要,直到根目录。这一步相当于先粗读一遍建立“全局索引”。
(2) 自顶向下:用摘要来判断各层级的访问顺序
-
从根目录开始,针对同层目录/文档,利用已有摘要让大模型判断“先读哪个更有助于理解后续内容”;
-
遇到子目录就递归做同样的排序。最后得到一条“更符合知识依赖”的访问序列。
(3) 自回归增强摘要:后面的摘要会引用前面学到的知识当某篇文档被排到更靠后的位置时,它的摘要生成会把“之前已读文档的摘要”作为上下文一起输入,从而形成“上下文增强摘要”。这点非常关键:它让摘要不再是孤立的,而是带着已经建立的概念体系去总结新内容。
上下文太长怎么办?论文用了一个工程上很实用的做法:把已生成的摘要存入向量数据库;新文档到来时,把新文档向量化,检索 top-k(默认 10)个最相关摘要拼进 prompt,类似一种轻量的 RAG,解决上下文长度限制。
5. 模块二:模式定义——如何从文档里“自动长出 schema”?
有了上下文增强摘要后,框架进入第二步:自动构建实体 schema。在需求工程语境下,你可以把它类比为:从大量需求/设计/运维文档中,自动归纳出“概念字典/领域术语表”(比如:服务、接口、指标、告警规则、配置项、日志事件、故障类型、SLA 等),并给出简洁定义,供后续一致化抽取使用。
论文的 schema 定义分三段:
(1) 实体类型抽取对每篇文档,输入“原文 + 摘要”,让大模型列出所有有意义的实体类型(entity types)。摘要在这里的作用是“压缩重点、去冗余”,避免模型被长文本细节淹没。

(2) 去冗余与聚类:解决同义/近义类型爆炸初始抽取的类型会非常多、且重复严重。论文做了两步处理:
-
先过滤掉只出现一次的类型(认为噪声概率更高);
-
再把类型做向量化,用 K-means 聚类把语义相近的类型聚到一起;聚类数 k 由轮廓系数(silhouette coefficient)自动选择,使得类内更紧、类间更分离。

(3) 生成类型定义:把聚类结果“规范化”成最终 schema对每个聚类,把该簇的候选类型交给大模型:
-
合并同义类型(比如 “Configuration / Configures” 归并到同一个概念);
-
为合并后的类型生成一句话定义。同时,这一步也会从摘要知识库中检索与该簇相关的摘要作为“参考知识”,让定义更贴合语料实际语义,而不是泛泛而谈。

6. 模块三:三元组抽取–先“识别有效实体”,再抽“实体间关系”
很多 KGC 方法会直接在文本里抽关系,容易出现“关系看起来合理、但实体不靠谱”的问题。LKD-KGC的策略是:
先抽实体(并且必须落在 schema 允许的类型里),再抽关系。
具体流程:
-
给定文档和 entity schema,让大模型抽取属于 schema 的实体,并标注它们的类型;
-
再把“文档 + 已抽实体 + schema”一起输入,让模型判断哪些实体对之间存在明确、重要的关系,并输出三元组列表。
论文还指出:如果实体类型很多,理论上可能的关系类型会指数增长,因此它不强行预定义关系类型集合,而是直接抽取自然语言谓词(predicate)。从软件工程应用角度,你可以进一步在落地系统中做“谓词归一化/映射”(例如把 “defines / specifies / configures” 统一映射到更规范的关系集),但这属于工程增强。
7. 实验设计:在公开语料与企业私有语料上验证
论文选了三个数据集:
-
Prometheus 文档(公开,技术文档结构清晰、术语多)
-
Re-DocRED 的一个 Windows 子集(有标注三元组,可算 precision/recall/F1)
-
IMS(企业内部监控系统文档,几乎无公开参考知识)
使用两个基础大模型进行实验,并设置较低温度(0.1)保证输出稳定;摘要检索 top-k=10;文本向量模型用于摘要检索与类型聚类。
评估指标上,公开 Prometheus 与私有 IMS 因为缺少人工标注真值,论文采用“LLM-as-judge”:把抽取的三元组连同原文喂给评估模型,让它判断三元组是否被文本支持,从而估 precision;recall 则用“每文档真实三元组数量”这种更贴近工程的衡量方式。
8. 实验结果:整体提升明显,私有语料优势更突出
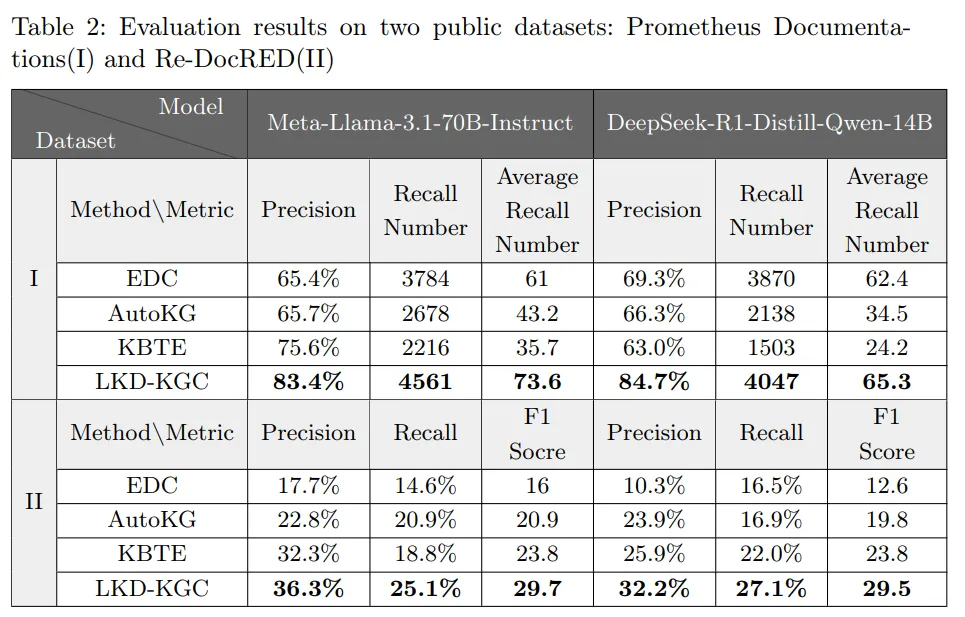
在 Prometheus 上,LKD-KGC 的 precision 明显高于基线,并且能抽到更多有效实体与关系;在 Re-DocRED 子集上,尽管无监督方法整体难以达到监督训练模型的水平,但 LKD-KGC 的 F1 仍优于对比方法,说明“先顺序、再 schema、再抽取”的设计确实能带来增益。
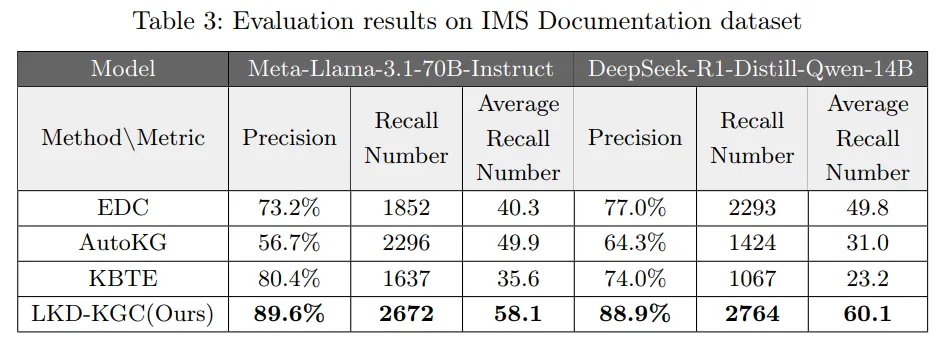
论文还分析了一个很有工程启发的现象:某些依赖互联网检索的方案,在私有语料上会检索到完全无关的概念,反而把模型带偏,导致幻觉增加;而 LKD-KGC 主要依赖“语料内部的上下文累积”,因此对企业内部知识更稳健。
10. 总结:这篇论文的贡献点是什么?
最后总结一下,这篇论文最核心的贡献在于把领域 KGC 的流程改成了更符合人类学习规律的三段式:
-
先推断知识依赖顺序(跨文档、层级化)
-
再利用上下文自动生成 schema(类型+定义)
-
最后在 schema 约束下抽取实体与关系(降低幻觉、提高准确性)
并且在公开与私有语料实验中都展示出稳定提升,尤其对企业内部这种“缺乏外部参考知识”的场景更有现实意义。
代码可见:https://anonymous.4open.science/r/KAD-KGC-DA17
详细内容可以参考论文原文.