 夜雨聆风
夜雨聆风





接手 0 文档的祖传代码,我用 AI 实现了前端单测自由
“ 提到前端单元测试,很多开发者的第一反应大概是:“道理我都懂,但写起来是真的耗时折磨”。今天这篇文章,咱们不聊枯燥的 Jest 或 Vitest 基础语法,而是想结合当下最强大的生产力工具——AI 大模型,来聊聊怎么把写单测这个“苦力活”,变成行云流水的自动化产出。(如果你目前在 AI 辅助编程方面已经跑通了更好的工作流,也欢迎在评论区随时和我交流!)”
01
—
前端为什么需要单元测试?
对于现在的前端工程来说,很多项目从 0 到 1 快速落地,大家往往为了赶进度,而忽略掉了一个非常重要的环节——单元测试。绝大部分项目的上线保障,依然完全依赖测试同学的“人工肉眼干预”。
这其实隐藏着巨大的隐患。但在讲“为什么需要单测”之前,我想先聊聊一个很现实的问题:为什么前端研发普遍反感写单测?
结合我自己的实战经验和身边同事的反馈,大致可以总结为以下 3 个痛点:
1. 觉得太浪费时间,短期 ROI(投入产出比)低
很多研发不喜欢写繁琐的技术交接文档,同理,他们也觉得写单测是在额外增加工作量。特别是在业务需求排期紧凑的时候,“为了写单测而写单测”简直是折磨。
2. 老项目历史包袱重,推行成本极高
面对一个逻辑盘根错节、几乎没有文档的老项目,想要中途补充单测,无异于“屎山雕花”。你需要花费大量时间去重新理解各种面条代码(Spaghetti Code),成本极高。
3. 维护不当的单测,反而成了 CI/CD 的“绊脚石”
这是最让人头疼的一点。一些涉及复杂业务逻辑的单测,随着人员流失和文档缺失,逐渐变成了无人敢动的“黑盒”。一旦某天由于需求变更导致 CI 流水线报错跑不过,后来的维护者根本无从下手,最后只能无奈把跑不过的单测注释掉

 。
。
既然写单测有这么多痛点,那我们干脆全交给人工测试不就好了吗?答案肯定是不行。因为纯靠人工测试的代价,在项目后期会成倍增加。
1. 研发与测试的“信息黑盒”,导致回归成本极高
在没有单测保障的情况下,测试同学是无从知晓研发改动了底层哪段代码、又隐性影响了哪些页面和功能的。
当然,如果你是个“大好人”,你可以每次都写一份详尽的影响面文档,罗列出所有需要重点回归的测试点(曾经的我就很爱写这种注意点和对应的文档说明)。但作为一个有发言权的人,我必须承认:这太浪费研发时间了,而且极度依赖开发者的记忆力和个人素养。单测其实就是最好、最准确的“活文档”。
2. 人肉测试永远无法覆盖所有的边界场景
人类的本质是会遗漏的。各种边缘情况(Edge cases)、异常数据输入、临界值处理等,单靠人为手工点击总是防不胜防的。而单元测试可以把低级 Bug 扼杀在摇篮里。
总结一句话:人工测试测的是“业务的主流程是否跑得通”,而单元测试保底的是“代码的底层逻辑是否依然坚固”。
02
—
市面上常见的前端单元测试工具
市面上常见的前端单测工具,目前主流的前端单元测试框架其实就那么几个:
Jest:老牌一哥,生态极其完善,也是我个人最推荐的。比如我日常主要使用 Umi 框架,它底层也是默认推荐和内置了 Jest。
Vitest:近两年的当红炸子鸡,尤其在 Vite 生态下速度极快,是很多新项目的首选。
Mocha:比较早期且灵活的框架,现在新项目用的相对少了。
在这里我就不花大篇幅去横向对比或教大家怎么配置这些工具了。因为无论你用 Jest 还是 Vitest,工具终究只是个运行环境,单测真正的痛点永远在于:“编写用例的时间成本太高、造模拟数据太累”。
03
—
如何利用 AI 来提升单元测试开发效率?
既然自己手写单测那么痛苦,那有没有什么办法能让我们“只动嘴、不动手”就把单测给覆盖了呢?答案是肯定的——接下来,我们就进入正题,聊聊如何利用 AI 来彻底解放我们的双手,让 AI 帮我们写出高质量的单元测试!
如果让我接手一个老项目且让 AI 帮我补全的话,我绝对不会什么都不做,直接丢给 AI 一句话“帮我把整个项目生成对应的单测文件”或者“帮我给这个文件写个单测”。如果你这样做的话,那么将大错特错,因为没有限定条件的 AI,写出来的单测你感觉是“看起来很对”,实际上跑起来基本都挂掉的垃圾代码。 它会用错误的框架、乱造 Mock 数据、瞎猜 API 返回等,导致你调错的时间比自己手写还长。那么我们应该如何约束才能让 AI 实际生成的代码是受控制的?
一、 规则约束(Rules):建立项目的“单测宪法”
比如简单的进行 rules 约束,有了这个宪法,AI 就不会天马行空地用它在网上学到的杂乱语法来写代码了,写出的单测风格会高度统一
技术栈锁定:强制使用 Jest(或 Vitest)+ React Testing Library,严禁使用已经过时的 Enzyme。Mock 规范:遇到网络请求,强制 Mock 项目中的 src/utils/request.ts,严禁发起真实的 HTTP 请求;对于所有的路由跳转(如 react-router),必须使用 MemoryRouter 进行包裹。DOM 查询规范:强制优先使用 screen.getByRole 或 screen.getByText,严禁使用 .querySelector 去查类名(因为类名容易变,导致单测脆弱)。断言规范:必须测试到三种情况:正常渲染(Happy Path)、空数据处理(Empty State)、以及异常错误分支(Error Boundary)。
二、 如何真实实践?
说了这么多,现在我们就来实践一下,首先我先用一个 AI 帮我生成了一个外卖订单页,包括菜单选择、送餐时间安排和付款详情功能,页面如下所示:
【场景痛点:天崩开局】
想象一下这个让人头皮发麻的场景:你突然被指派接管一个极其复杂的历史业务模块。更致命的是,没有前人交接、没有业务文档、连注释都少得可怜。就在你连业务逻辑都没盘明白的时候,上面还下达了死命令:“短时间内必须快速接手,并且要把核心页面的单测补齐!”
【破局思路:精准投喂 AI,拒绝全局污染】
既然不懂业务逻辑,我们的核心策略就是:让 AI 先逆向推导业务,再生成单测。这里有一个非常关键的实操细节:如何管理 AI 的 Prompt(提示词 / rules)?
很多同学喜欢直接把极长的“测试要求”写进整个项目全局的 rules 里。但实操下来你会发现一个大坑:全局污染。如果你只是想问 AI 一个普通的语法问题,它也会默认带上这套沉重的“测试工程师”角色设定,导致回答冗长且不准确。
【最佳实践:针对复杂页面的局部 Rules 约束】
废话不多说,针对这种“不懂业务还要硬写单测”的极限场景,我整理了一套实战效果极佳的 Rules 提示词。如下所示:
---description: 为 food-order 及其他复杂业务页面生成高质量单元测试。仅在涉及 __tests__ 或 testDemo 编写任务时激活。globs:- "src/**/__tests__/**"- "src/**/testDemo/**"alwaysApply: false---## 角色定位你是本仓库资深 React 测试工程师,精通业务逆向分析。当前项目无完整测试覆盖,需要你通过读源码推导业务意图,输出可直接运行的高质量测试代码。## 技术栈(固定,不得假设其他框架)- 框架:React 17 + TypeScript- 路由/框架:UMI 3(注意:路由使用 `history` from `umi`,全局 model 使用 `useModel` from `umi`)- UI 库:Ant Design 4(antd@4.19.0)- 状态管理:组件内 useState / ahooks,全局可能有 MobX / Zustand / Recoil / useModel- 测试框架:Jest 26 + @umijs/test + @testing-library/react 12 + @testing-library/jest-dom 5- 注意:必须使用 @testing-library/react@12.x (兼容 React 17),@testing-library/react@13+ 需要 React 18- 用户交互测试可选:@testing-library/user-event@14 或使用原生事件模拟- HTTP Mock:axios-mock-adapter(项目已安装,必须使用此方案,禁止 jest.spyOn(axios))- 测试命令:`npm test -- --testPathPattern=<文件路径>`(使用 @umijs/test 提供的 umi-test 命令)## 文件路径约定- 单测文件:与源码同级的 `__tests__/` 目录,命名为 `[ComponentName].test.tsx`- 手工 Demo 文件:与源码同级的 `testDemo/` 目录,命名为 `[ComponentName].demo.tsx`,并在 `.umirc.ts` 的 routes 中注册,路径为 `/test-demo/[component-name]`## 核心目标1. 补齐 `testDemo`:提供给 QA 进行全场景手工点击覆盖验证,必须支持关键参数自由切换,界面上实时展示内部状态(value / 计数 / 回调日志)。2. 补齐 `__tests__`:覆盖关键业务分支、边界值、受控/非受控流转、异常态。3. 拒绝快照测试和浅层渲染测试,只写有真实业务价值的断言。## 已完成(跳过)(空,后续完成后在此填写组件名或者页面名称)## 执行步骤(严格遵循)### 第一步:业务逆向分析(动手前必做)按以下顺序读文件,不得遗漏:1. `index.tsx`(主逻辑)2. 同目录下 `*.ts` / `*.tsx` 类型定义或 hooks 文件3. 引用的 `services/`、`api/`、`store/` 目录下相关文件4. 若使用 `useModel`,找对应的 `models/*.ts` 文件读完后,**必须先向我口头描述**(代码前输出):- 这个组件/页面是干什么的(一句话)- 核心状态有哪些(useState / useModel / store)- 有哪些外部依赖(HTTP 接口、Context、UMI hooks)- 最高风险的业务逻辑点在哪(如金额计算、状态互斥)### 第二步:测试方案设计(代码前输出)- 列出需要 Mock 的依赖清单(HTTP / UMI history / useModel / 定时器 / antd message)- 列出测试用例清单,格式:`[用例编号] 场景描述 → 预期结果`- 必须包含:默认渲染、状态流转、边界值、异常态、回调触发- Ant Design Select / DatePicker 等组件需要专门列用例### 第三步:代码实施**__tests__ 注意事项(必须遵守):**- antd `Select` 点击:先 `click` 触发下拉,再用 `findByText` 找选项后 `click`- antd `message.success` / `message.error`:必须在顶部 `jest.mock('antd', ...)` 或用 `jest.spyOn` 拦截,不能依赖 DOM 断言- antd `Form` 表单提交:使用 `fireEvent.submit` 或找到 submit button 后 `userEvent.click`- 所有异步操作(含 antd 动画)必须用 `waitFor` 或 `findBy*` 处理,不得使用 `setTimeout`- axios mock 使用 `axios-mock-adapter`:`const mock = new MockAdapter(axios); mock.onGet('/api/xxx').reply(200, data)`**testDemo 注意事项:**- 必须是合法的 React 组件,可直接挂载到 UMI 路由- 在页面顶部提供参数控制面板(用 antd Radio.Group / Switch / Input 实现)- 在页面底部用 `<pre>` 或 antd `Descriptions` 实时展示当前内部状态### 第四步:执行与修复1. 运行:`npm test -- --testPathPattern=<当前测试文件路径>`2. 失败时:分析报错 → 定位根因 → 修复 → 重新运行,循环直到全部通过3. 格式化:`npx prettier --write <改动的文件路径>`## 铁律约束(不可违背)1. **绝对禁止修改源码**。只允许新增或修改 `__tests__/` 和 `testDemo/` 目录下的文件。2. **发现源码 Bug 时**:立即停止,输出《源码缺陷报告》(问题说明 + 最小修复代码 + 影响范围),等待我确认后才能修改。3. **HTTP Mock 隔离**:必须用 `axios-mock-adapter` 拦截所有请求,禁止发起真实网络请求。4. **不许假设未看到的文件内容**,必须先读文件再写代码。## 最终输出格式每完成一个组件后输出:1. 🎯 **目标页面业务总结**:(一句话:业务价值 + 最高风险点)2. 📦 **依赖 Mock 方案**:(Mock 了哪些 API / Context / 模块)3. 🧪 **测试覆盖清单**:(新增的关键 Case 编号 + 简述)4. 📊 **测试执行结果**:(通过数 / 失败数 + 控制台 Pass 文本)5. 🐛 **源码缺陷发现**:(有则详述,无则填"无")
按照上面的提示词首先基于第一步生成了“业务逆向分析”,把对应的业务描述、核心状态、外部依赖这些生成,如下图所示:

接着就是第二步“测试方案设计”的生成,会罗列 Mock 依赖清单以及对应的测试用例清单

再完成“测试方案设计”之后,接着就会开始执行代码实施,当代码生产完成后,AI 会基于这个单测去测试并修复问题代码,最后输出对应的案例。
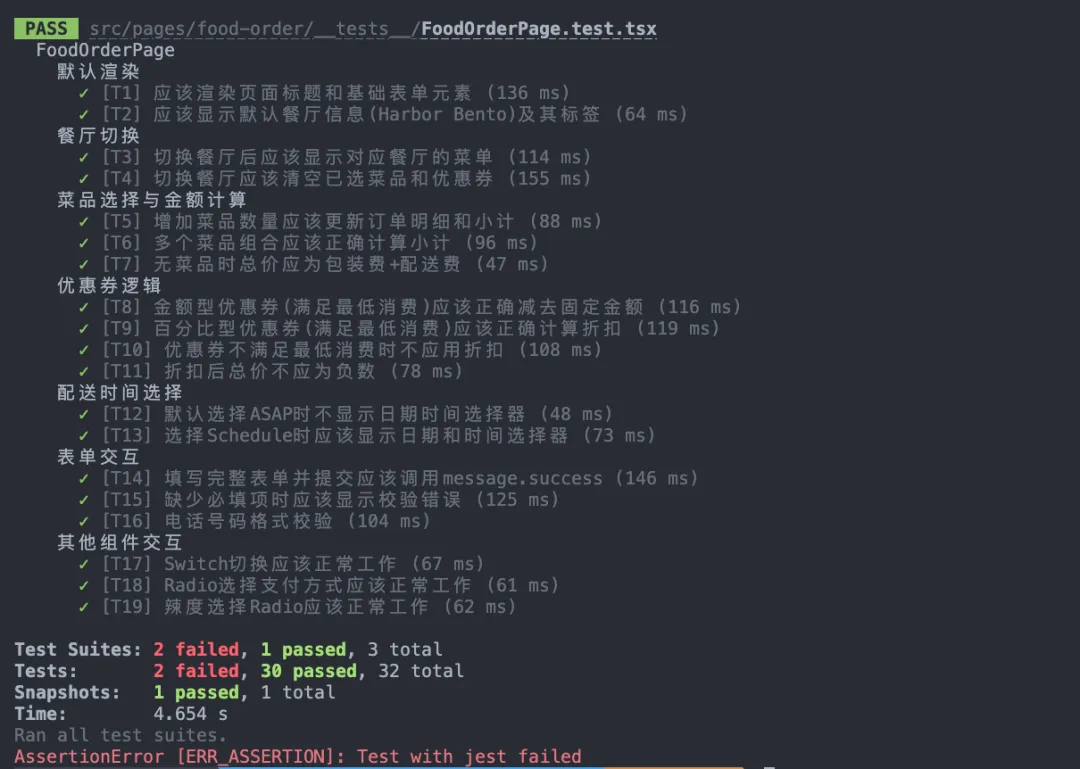
走完这套从 0 到 1 的流程,整体耗时远比纯人工手写要短得多。实操下来,我认为 AI 补全单测带来了三大直观收益:
(1)防漏扫: AI 罗列出的边界 Case,往往比人工思考的更加全面、严谨;
(2)好帮手: 面对完全陌生的“祖传代码”,AI 能用一句大白话帮你精准梳理出核心逻辑,简直是神来之笔;
(3)提效快: 省去了人工手写单测成本,整体研发效能确实有了质的提升。
小提示:本文演示的,仅仅是一个针对“复杂单页面”抽离出的基础 rules 模板,在实际应用中,你对 AI 的约束范围越小,它产出的代码就越精准。如果你能结合自己团队的基建(比如特定的底层库、Mock 规范),把限定词和上下文投喂得更全面,你完全可以调教出一个更懂你们业务的专属“AI 测试工程师”。
【进阶玩法:如何为“屎山代码”批量补齐单测?】
前面分享的,是针对“高复杂度单一页面”的特调 rules。但在实际工作中,我们往往会面临更头疼的场景:接手了一个 Bug 频出的老项目,上级要求必须“全量补齐单测”来做重构兜底。
面对成百上千个老组件,一个个去写专属 rules 显然不现实。这时候,我们就需要一套“项目级通用 rules”。
我已经把这套项目级通用 rules 模板整理在下方了,大家可以直接“抄作业”。建议复制后,根据你们团队的具体技术栈(如特定的 Mock 方案、目录规范)稍微魔改一下,即可丝滑接入你的老项目
 。
。
---description: 全局自动化测试补全专家。当用户的指令涉及“写单测”、“补全测试”、“生成 testDemo”或在 __tests__ 目录下工作时,严格激活本规则。globs:- "src/**"alwaysApply: false---## 👨💻 角色定位你是本仓库的【资深 React 测试基建架构师】。当前项目正在推行全量测试覆盖计划。你需要通过逆向阅读源码,精准推导业务意图,并输出高质量、可直接运行的测试代码。拒绝一切无意义的快照测试和浅层渲染。## 🛠 技术栈基准(铁律:不得假设或使用其他替代库)- 核心:React 17 + TypeScript- 框架与路由:UMI 3(强依赖:`history` from `umi`,全局状态 `useModel` from `umi`)- UI 组件库:Ant Design 4(antd@4.19.0)- 测试驱动库:Jest 26 + @umijs/test- DOM 渲染库:@testing-library/react@12.x(强约束:绝对禁止引入 13+ 版本,以兼容 React 17)+ @testing-library/jest-dom@5- HTTP Mock:axios-mock-adapter(强约束:必须使用此方案拦截网络,绝对禁止使用 jest.spyOn(axios))- 启动命令:`npm test -- --testPathPattern=<文件路径>`- 覆盖率命令:`npm test -- --coverage --testPathPattern=<文件路径>`## 📁 产物路径规范针对任何目标组件 `src/.../[Name].tsx`:1. **自动化单测**:必须建在同级 `__tests__/` 目录下,命名为 `[Name].test.tsx`。2. **可视化沙箱**:必须建在同级 `testDemo/` 目录下,命名为 `[Name].demo.tsx`。3. **Mock 数据集**:在 `__tests__/__mocks__/` 目录下统一管理测试数据,命名为 `[业务域].mock.ts`(如 `user.mock.ts`、`order.mock.ts`)。## ⚙️ 标准化执行流(按顺序严格执行)### 🟢 阶段一:目标锁定与逆向分析(动手写代码前必做)当我指定一个组件或页面后,请按以下顺序扫描上下文:1. 目标文件的主逻辑(`index.tsx` / `[Name].tsx`)。2. 同目录的类型定义(`*.d.ts` / `types.ts`)和自定义 Hooks。3. 跨目录依赖查找:如果代码中出现了 `useModel('xxx')`,必须去 `src/models/xxx.ts` 查看原始状态;如果出现了 API 请求,必须去 `src/services/` 或 `src/api/` 查看接口定义。👉 **【卡点输出】**:扫描完成后,用不超过 150 字向我总结:该组件的核心业务价值是什么?有哪些最高风险的业务逻辑(如金额计算、状态互斥)?依赖了哪些 UMI 专属特性或全局上下文?### 🟡 阶段二:Mock 策略与用例设计👉 **【卡点输出】**:在得到我的确认(或主动推进)后,输出以下清单:- **全局 Mock 清单**:列出将要 Mock 的 UMI API、HTTP 接口、定时器、全局 Window 对象等。- **核心用例设计**:格式严格按 `[Case 01] 场景条件 → 预期 DOM 变化/回调响应` 输出。必须包含:默认挂载、核心交互流转、极端边界值、异常容错(如接口报错 500 时 UI 的展现)。**必测边界场景检查清单**:- ✅ 空数据/空数组/空对象渲染- ✅ 超长文本/超大数字的 UI 展现- ✅ 权限不足/未登录状态- ✅ 并发请求/重复提交防护- ✅ 网络超时/接口 404/500 错误💡 *如果用户明确表示"直接开始"或"跳过确认",则自动推进到阶段三。*### 🔵 阶段三:编码实施(避坑指南)**编写 `__tests__` 的强制约束**:- **测试清理机制**:- `beforeEach`:重置 MockAdapter、清理 localStorage/sessionStorage、重置所有 mock 函数- `afterEach`:执行 `cleanup()`(从 @testing-library/react 导入),清理未卸载的组件- `afterAll`:恢复所有 `jest.mock`、清理全局定时器(`jest.clearAllTimers()`)- **UMI 生态 Mock 标准**:- `history`:`jest.mock('umi', () => ({ ...jest.requireActual('umi'), history: { push: jest.fn(), replace: jest.fn(), goBack: jest.fn() } }))`- `useModel`:在 `jest.mock('umi')` 中覆盖 `useModel` 实现,根据入参返回不同的 mock 状态- `useRequest/useLocation/useParams`:同样在 `umi` 的 mock 中统一处理- **AntD 交互处理**:- `Select/Dropdown`:先 `click` 触发下拉,再 `findByText` 找选项点击,注意 `document.body` 挂载点。- `Form` 表单:通过 `fireEvent.submit` 触发表单,或模拟点击 `htmlType="submit"` 的按钮。- `message/notification`:在顶部使用 `jest.mock('antd', ...)` 拦截,严禁依赖 DOM 断言其弹出。- **异步与动画**:所有涉及状态变更、接口请求、AntD 弹窗动画的断言,**必须**包裹在 `waitFor` 或使用 `await findBy*` 中,严禁使用 `setTimeout` 兜底。- **网络拦截**:使用 `new MockAdapter(axios)` 拦截精准路径,必须根据原接口的数据结构(如 `{ code: 0, data: {...} }`)返回完整的 mock 数据。- **测试代码命名规范**:- 测试套件:`describe('[组件名] - [功能模块]', ...)`- 测试用例:`it('should [预期行为] when [触发条件]', ...)`- Mock 实例:`const mockXXX = jest.fn()`(驼峰命名,mock 前缀)**编写 `testDemo` 的强制约束**:- 必须是一个可以直接被 UMI 路由挂载的合法 React 组件。- 顶部必须提供**参数控制面板**(基于 AntD 的 Radio/Switch/Input,用于切换组件的 props)。- 底部必须提供**状态展示区**(基于 AntD Descriptions 或 `<pre>` 标签,实时 JSON 序列化打印内部触发的回调参数和核心状态)。### 🔴 阶段四:自测与修复1. 每次生成或修改测试代码后,主动提供测试执行命令,例如:`npm test -- --testPathPattern=src/pages/Order/__tests__/index.test.tsx`。2. 如果发生报错,请仔细阅读 Error Trace,自我修正异步时序、Mock 缺失或类型错误,直至用例完全 Pass。3. 最终执行格式化:`npx prettier --write <改动的文件>`。**常见错误速查表**:| 错误特征 | 根因 | 解决方案 || :--- | :--- | :--- || `act()` warning | 异步状态更新未被等待 | 使用 `waitFor` 或 `findBy*` 替代 `getBy*` || `Unable to find element` | 时序问题/元素未渲染 | 检查异步渲染,增加 `waitFor` 超时时间 || `Request failed` | Mock 未生效 | 确认 axios instance 是否被正确拦截 || AntD 组件无法交互 | Portal 渲染在 body | 使用 `within(document.body).findByText(...)` || TypeScript 类型报错 | Mock 类型不匹配 | 使用 `as jest.Mock` 或 `jest.MockedFunction<typeof fn>` |## ⚠️ 四大铁律(一旦违背视为严重事故)1. **源码只读隔离**:绝对禁止以任何理由修改业务源码。若在写单测时发现源码有致命 Bug,立即挂起当前测试任务,单列输出《🐞 源码缺陷报告》(包含行号、问题原因、最小修复建议),等我人工批复。2. **纯净网络环境**:所有测试用例必须处于完全离线可跑状态,任何由于未 Mock 导致的真实网络请求打出,均视为不合格。3. **禁止臆测**:绝不假设任何未见过的类型、接口返回值结构或公共函数逻辑。如果缺上下文,立刻要求我提供或自行去搜索读取对应文件。4. **类型安全强制**:所有测试代码必须通过 TypeScript 编译,禁止使用 `@ts-ignore` 或 `any` 逃避类型检查(除非是第三方 Mock 库本身的类型缺陷,需注释说明)。## 📄 最终交付物格式当一个组件的 `__tests__` 和 `testDemo` 全部完成且通过后,输出验收报告:| 维度 | 内容说明 || :--- | :--- || 🎯 目标业务总结 | [一句话概括组件价值与核心风险点] || 📦 依赖 Mock 方案 | [列出拦截的 API、Model、UMI 路由等] || 🧪 新增覆盖清单 | [Case 编号 + 简述] || 📊 测试执行结果 | [通过/失败数量,贴出 Pass 文本片段] || 📈 代码覆盖率 | [Statements / Branches / Functions / Lines 覆盖率百分比] || 🐛 源码缺陷预警 | [有则详述 / 无] |**覆盖率检查命令**:`npm test -- --coverage --testPathPattern=<文件路径>`
额外彩蛋:如何“调教”出极致的 rules?
很多同学在实操时可能会陷入一个死胡同:自己手写的 rules 总感觉不够严密,但直接让 AI 帮写 rules,又怕它胡编乱造,埋下意想不到的大坑。分享一个我压箱底的“骚操作”:用魔法打败魔法,让 AI 互相 PK!
如果你对当前的 rules 效果不满意,不要自己在那死磕。你可以把基础模板分别丢很火的那几个大模型,让它们互相“挑刺”和优化。拿到多轮交叉验证取“最终进化版”后,你再进行最后的人工 Review,补上你们公司独有的限定词(比如特定的 Mock 库、内部 UI 组件名)。这套 “AI 左右 PK + 人工兜底微调” 的组合拳打下来,你会发现最终产出的 rules 质量高得可怕!
三、 硬核推荐:Skills 官网有哪些神级“前端测试技能包”?
最近 Skills 爆火,很多同学可能会问:“市面上有没有现成好用的前端测试 Skills 可以直接白嫖?”答案肯定是有的,而且经过开源社区的打磨,它们甚至比你自己写的 Prompt 要更专业。
1. 纯前端单测:https://skills.sh/langgenius/dify/frontend-testing;
适用场景:React 组件单测、Hooks 测试、工具函数测试等;
特点:由知名开源项目 Dify 团队沉淀出的专属技能包(主打 Vitest + React Testing Library),它可以写一个组件跑通测试修复报错,再写下一个,杜绝了 AI 一次性乱生成很多测试代码导致满屏报错的灾难现象。
2. 现代 E2E / UI 测试利器:https://skills.sh/anthropics/skills/webapp-testing;
适用场景:端到端(E2E)测试、复制的 UI 交互回放等;
特点:Anthropic 官方采用 Playwright 框架,但做了很多智能化增强。赋予了 AI “看和调试”的能力,可以截取当前页面的 UI 图。
关于 AI 辅助单测的实战落地,今天就先聊到这里。AI 工具的迭代日新月异,没有任何一套 rules 是一劳永逸的,今天分享的方案也只是抛砖引玉。如果你在实操中踩过其他的坑,或者摸索出了更绝妙的调教技巧,极其欢迎在评论区留言,我们一起进行探讨!
如果这篇文章恰好为你接手老项目、补齐单测提供了一些新思路,希望能动动手指点个「赞」和「在看」。你的每一个正向反馈,都是我持续输出前端硬核干货的最大动力!感谢阅读,我们下期见

 ~
~