122、WPS表格的正则表达式函数REGEXP:从原始字符串中提取出数字、英文字母、常用汉字
我们经常需要处理文本字符串。例如,从字符串中提取出需要的内容,或者将字符串中指定的内容替换为新内容。
常用的字符串处理函数有MID、LEFT、RIGHT、FIND、LEN、LENB、SUBSTITUTE、TEXTSPLIT等,这些函数能够处理一些比较规范的文本。但是,如果文本比较混乱,提取规则比较复杂,使用这些常规函数来处理就比较困难。这时,我们可以使用正则表达式(Regular Expression),它一种强大的文本处理工具。
单词regular的意思是”有规律的”。单词expression的意思是”表情,表示,表达式”。
Regular Expression译为”规则表达式,正则表达式”。
正则表达式是一种用来描述字符串模式的表达式。例如,”[0-9]+”表示连续出现的数字,”[A-Za-z]+”表示连续出现的英文字母,”[一-龟]+”可以表示连续出现的常用汉字。
通过正则表达式,我们可以检查一个主字符串是否包含符合给定模式的子字符串,如果存在,可以将其提取出来,或者替换为新的内容。
REGEXP(原始主字符串,正则表达式,[匹配模式],[替换内容])
0-提取,返回符合给定模式的子字符串。这是默认选择。
1-判断,判断是否存在符合给定模式的子字符串,返回TRUE或FALSE。
2-替换,将符合给定模式的子字符串替换为新内容,新内容通过第四参数来指定。
3-完整提取,当第一、二参数为数组时,提取全部匹配结果。
第四参数,[替换内容]:当[匹配模式]为”2-替换”时,指定新的内容。
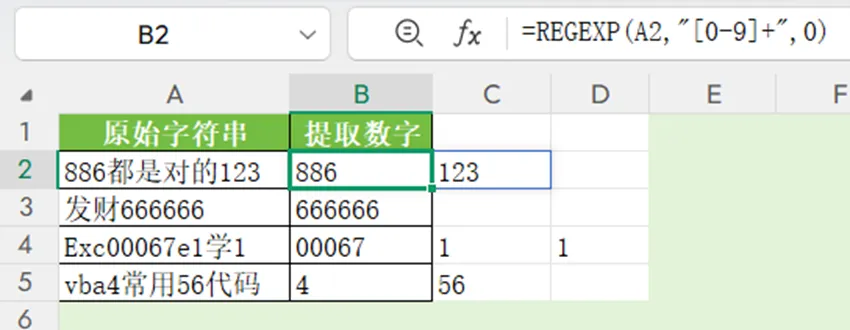
如下图,A列为原始字符串,其中混杂着数字、汉字、字母。需要提取出其中的数字。
子字符串模式的表达式用双引号包裹,本例为”[0-9]+”。其中,0-9表示0123456789十个字符。0-9放在了中括号[]内,在中括号内的字符构成了字符集合,表示匹配这些字符中的任意一个。之后的+为数量词,表示前面的字符要匹配1个或多个,直到不再连续出现。
公式会提取出原始字符串中所有连续出现的数字。当原始字符串中有多组连续数字时,得到的结果是一个单行数组。
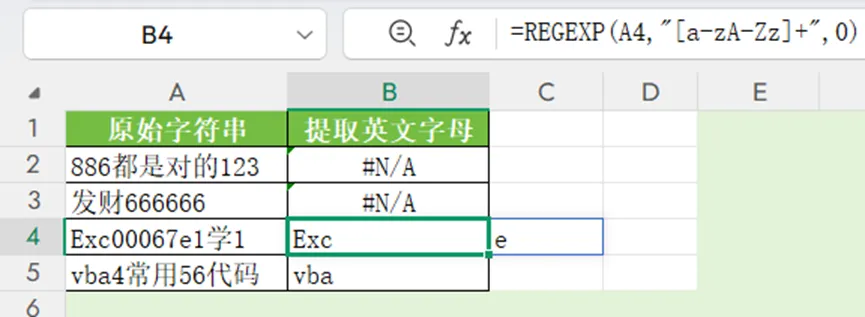
=REGEXP(A2,”[A-Za-z]+”,0)
A-Z表示所有大写英文字母,a-z表示所有小写英文字母。在正则表达式中,用短线连接的两个字符,左侧为开始字符,右侧为结束字符,表示从开始字符到结束字符之间的所有字符。注意,在计算机内部,开始字符的码点要小于结束字符的码点,否则无法正确识别。
在中括号[]内,各个字符的顺序没有要求,本例使用”[a-zA-Z]+”,结果相同。
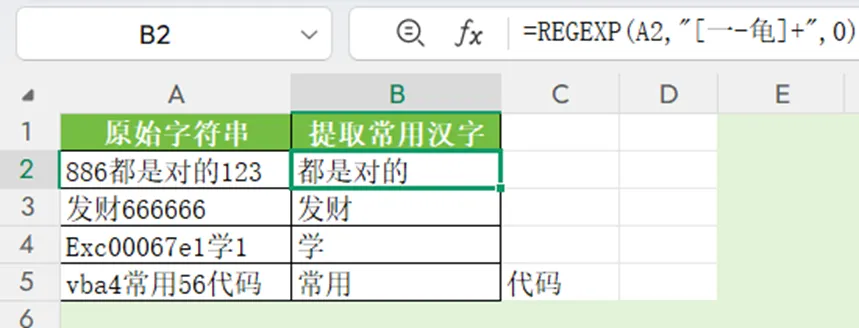
如下图,要提取常用的汉字,可以使用”[一-龟]+”。从”一”到”龟”,这个范围基本包括了常用的汉字。
 夜雨聆风
夜雨聆风