 夜雨聆风
夜雨聆风





我们的AI助手,其实是平台的间谍
最近看到一篇论文,标题直接把话挑明了——The Next Paradigm Is User-Centric Agent, Not Platform-Centric Service(下一个范式是以用户为中心的 Agent,而不是以平台为中心的服务)。
论文地址:https://arxiv.org/abs/2602.15682[1]
来自中科大、华为等机构 11 位研究者的正经学术研究。核心观点比我见过的科技报道都直接:
平台技术进步 ≠ 我们真正受益。
说白了,我们每天用的推荐算法、智能助手、个性化服务,看起来是在”服务”我们,实际上是在榨取我们。
这篇论文让我重新想了一件事:AI 到底在为谁服务。
我花了一天读论文,又去翻了 Twitter 和 YouTube 上的讨论。下面的内容是我整理出来的核心观点。
先说结论:平台优化的是留存和转化,不是我们的需求。这两个目标本来就是对着的。 更强的模型只会放大平台的目标。唯一的出路是换架构,让 AI 归我们自己管。
一、平台的”好心”,信不得
论文开篇就放了一张图,直白得让人不适:
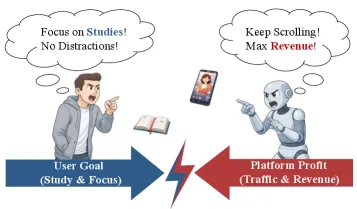
可以看到,平台的目标函数和用户的目标函数,方向完全相反。
举个例子:想专心学习的时候,打开一个内容平台,结果呢?它给你推短视频。
为什么?因为短视频的广告转化率高,能让我们多停留几分钟,多看几条广告。
对我们有好处吗?没有。对平台有好处吗?有。
论文里写得更直接:
Platform-centric services prioritize provider objectives over user welfare, resulting in conflicts against user interests.
翻译成人话:平台优先考虑的是提供商的目标,而不是用户的福祉。这导致了与用户利益的根本冲突。
我知道有人会说:不对啊,平台推荐的东西我挺喜欢的啊,刷得很爽啊。
爽,恰恰是问题所在。
我们被设计成了”爽”。多巴胺被算法精确调控。我们以为自己在做选择,其实是平台在替我们做选择,选择让我们看什么、买什么、相信什么。
论文里有句话点到了要害:
The real power lies not only in what the system recommends, but in what it decides and executes on behalf of the user.
真正的权力不只是”推荐什么”,而是”替我们决定什么”。
二、三个结构性问题,没救
论文分析了当前平台服务的三个致命问题。不是技术问题,是结构性问题——也就是说,在现有架构下,根本无解。
问题一:碎片化的上下文
每个平台只看到我们在它 APP 里的行为。
在淘宝搜索的商品,抖音不知道;在微信聊的话题,小红书不知道;calendar 里的会议,谁都不知道。
结果是什么?每个平台都以为它了解我们,但其实都只了解一小片拼图。
论文的原话:
Each platform only learns what happens inside its own product surface, while the signals that define the user’s real situation are scattered across apps and device-level traces.
这就是为什么推荐总是”差点意思”——因为它永远看不到完整的我们。
问题二:受限的执行边界
想办一件事,比如说:重新预订一张机票,顺便取消酒店,再通知一下参会人员。
这件事需要跨三个平台操作。但平台 A 只能操作 A 的事,平台 B 只能操作 B 的事。
现在的 AI 助手能做什么?给个链接让我们自己点。
论文说:
A platform-centric system is structurally unfit for such requests. It is confined to a single platform boundary and governed by an objective that rewards retention over resolution.
留住我们,比解决我们的问题更重要。
问题三:错位的激励机制
这是最隐蔽、也最危险的一个。
当 AI 开始替我们做决定时,谁在定义”最优解”?
论文举了个例子:平台可能会默认推荐自己的产品,给竞争对手设置障碍,或者选择利润最高的选项作为”默认动作”。
These small biases accumulate, systematically directing the outcome toward platform interests—even when each individual step appears to benefit the user.
每一步看起来都为我们好,但十步之后,我们被带沟里了。
这不是阴谋论。这是数学。
三、论文的解法:设备-云端协同管道
论文提出了一个技术方案,叫做”Edge-Cloud Collaborative Pipeline”(边云协同管道)。
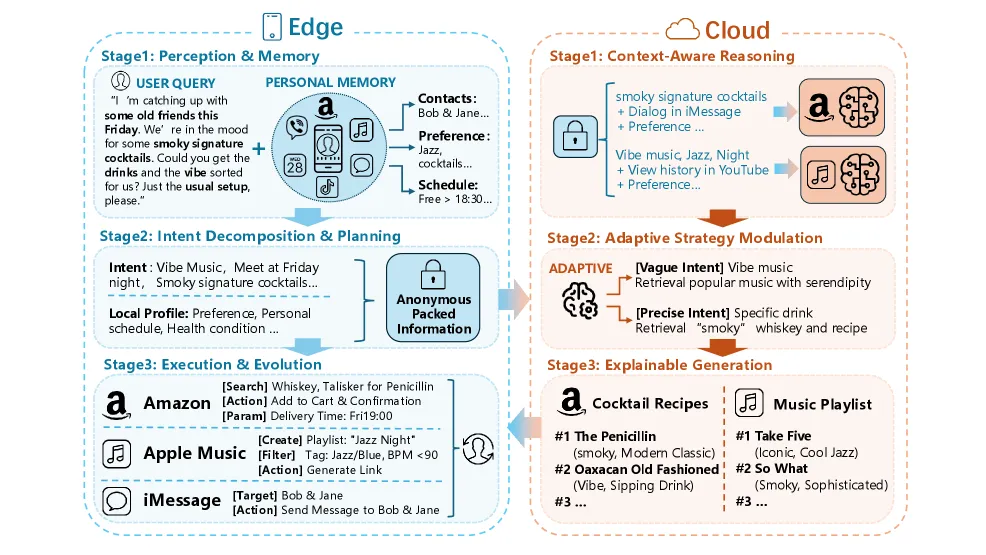
核心理念是这样的:
-
设备端(我们控制的):存储完整上下文、隐私数据、偏好设置。所有敏感信息不出设备。 -
云端(平台提供的):作为”可调用的服务层”,提供库存查询、API 接入等能力,但不做最终决策。 -
关键点:最终决策权在我们自己手里。
论文把这个架构描述成一个”感知-规划-执行”的闭环:
The on-device architecture is framed as a closed-loop lifecycle comprising three stages: Perception, Planning, and Execution.
我翻译一下:
-
感知:手机知道日程、位置、正在看什么、最近做了什么。 -
规划:个人 Agent 把这些信息整合,制定一个帮助达成目标的计划。 -
执行:调用外部服务完成任务,但决策在本地完成。
这个架构的关键洞察是:
Holistic context already converges on the device, where the user’s activities naturally span applications and modalities.
完整的上下文本来就汇聚在设备上。 我们不需要把数据上传给平台,平台只需要接收结构化的请求。
四、我的看法:技术不是瓶颈,治理才是
读完这篇论文,我的第一反应是:这不是技术问题。
技术上,也许不久就能做到。
端侧推理已经发展起来了——苹果的 Apple Intelligence、微软的 Phi 系列、各种本地大模型,都能在手机上跑起来。
2025 年下半年以来,端侧 AI 的进展有目共睹:
-
Secret AI:完全离线运行,100%私密,无数据收集 -
Private Mind:本地处理,零数据上传 -
localGPT:与本地文档对话,数据 100%留在设备上
这些产品已经证明了”用户中心 AI”在技术上是可行的。
那为什么还没成主流?
因为这里有一个更深层的博弈:
Control over the on-device agent is not a neutral implementation detail; it is an economic vantage point.
谁来提供这个 Agent?
如果是苹果提供,它会优先推荐苹果生态;如果是谷歌提供,它会优先推荐谷歌服务。
换了个房东,我们还是租客。
论文里有一段话说得很透:
If the agent itself becomes a proprietary gatekeeper, the ecosystem risks simply swapping one platform-centric bottleneck for another.
如果 Agent 本身变成了一个封闭的守门人,生态系统面临的 risks 是——只不过换了一个平台中心的瓶颈。
所以,真正的问题不是”能不能做”,而是:
-
谁来定义 Agent 的目标? -
用户能不能迁移?(记忆、偏好、历史) -
平台愿不愿意开放?
这三个问题,没有一个是纯技术能解决的。
五、为什么现在是转折点?
论文给出了两个关键的技术拐点:
-
LLM-as-Rec:从 ID 匹配升级到意图推理。大模型终于能真正”理解”我们想干什么,而不是简单匹配历史行为。 -
端侧智能成熟:高性能的轻量模型可以在我们的硬件上直接运行。
With understanding and execution finally co-located on the device, user-centric agents move from a theoretical ideal to an engineering reality.
理解和执行终于可以在同一台设备上共存了。
过去,我们的数据必须上传到云端才能被”理解”;现在,理解可以在本地完成,只有需要外部资源的部分才需要联网。
这意味着什么?权力结构在变。
六、另一个视角:Agent 的”权力”
在研究这篇论文的过程中,我看到了一篇很有意思的文章,来自 MIT Media Lab 的研究。
它提出了一个概念:Agent 授权绕行(Agentic Authorization Bypass)。
什么意思?
当用户通过 Agent 操作系统时,Agent 可能拥有用户本身没有的权限。
Users who cannot directly access specific data or perform specific operations can still trigger Agents with those permissions. The Agent becomes a proxy, enabling operations the user themselves could not complete.
听起来很方便对吧?但这里有一个隐患:
我们不知道 Agent 在用什么权限做什么事。
这引出了另一个关键问题:责任归属。
当 Agent 犯错时,谁负责?
-
用户?“是你们授权的” -
平台?“我们只是提供工具” -
Agent?“它是自主决策的”
没人负责。
这也是为什么论文强调”治理”(Governance)比”能力”(Capability)更重要:
Engineering makes the pipeline feasible, but governance determines whether the agent becomes a user fiduciary or the next gatekeeper.
工程让管道成为可能,但治理决定 Agent 是成为用户的受托人,还是下一个守门人。
七、现实在往哪个方向走?
2026 年初,我看到了两个截然相反的趋势。
趋势一:平台继续集中化
OpenAI 的 Frontier 平台、Anthropic 的 Claude Cowork、字节跳动的扣子空间……所有巨头都在打造自己的 Agent 生态。
表面上,Agent 越来越强;实际上,所有的权力还是集中在平台手里。
A more capable model is not a more benevolent model. It is a stronger amplifier of its objective.
更强的模型不是更仁慈的模型,它只是更擅长放大自己的目标。
趋势二:用户主权意识觉醒
另一方面,隐私保护、数据主权、本地化部署的呼声越来越高。
Electric Capital 在 2026 年的投资报告中,把”私人 AI 代理”列为最关键的赛道之一:
People need AI running on sensitive data in a secure way. AI models run in trusted execution environments or compute networks, with incoming queries being anonymous.
用户需要的是:在敏感数据上安全运行 AI,而不需要企业提供商或恶意行为者看到我们的数据。
这两个趋势的博弈,决定了未来 5-10 年的数字世界格局。
八、三个实践建议
如果我们认同”用户中心”的理念,现在能做什么?
给个人用户
-
优先选择端侧方案:能用本地模型解决的问题,不要上传到云端。 -
关注数据所有权:用什么产品不重要,重要的是谁能看到我们的数据。 -
建立自己的知识库:不要把所有知识都存在别人的平台上。
给创业者
论文提到了一个关键的机会:
The agent needs execution access; the platform needs qualified intent and high-conversion matching.
Agent 需要执行入口,平台需要精准的意图和高转化匹配。
这里存在一个”价值交换”的空白市场——帮助用户和平台建立新的连接方式,但不是通过传统的”数据换服务”模式。
给平台方
短期看,开放 API、降低数据依赖,会让你们损失一些控制力。
长期看,如果不主动开放,会被用户用脚投票。
Making that market competitive and trustworthy demands explicit rules, not only better models.
让市场变得竞争和值得信任,需要明确的规则,而不仅仅是更好的模型。
最后的话
这篇论文给我的最大启发是:
AI 时代最大的矛盾,不是”AI 会不会取代人类”,而是”AI 服务于谁”。
论文最后有一句话,我觉得特别值得记住:
User utility becomes the primary objective, not a secondary consideration.
用户效用应该成为首要目标,而不是次要考虑。
这句话听起来像口号,但它实际上是对当前整个互联网商业模式的根本性挑战。
因为现在的主流模式是:用户是产品,广告主是客户。
如果要实现”用户中心”的范式转移,整个商业逻辑都要重写。
这不是技术问题,是利益分配问题。
参考资料
[1] https://arxiv.org/abs/2602.15682: https://arxiv.org/abs/2602.15682
[2] The Next Paradigm Is User-Centric Agent, Not Platform-Centric Service: https://arxiv.org/abs/2602.15682