 夜雨聆风
夜雨聆风





百度新OCR模型,4B参数完成文档理解.腾讯预告 HY 3.0,Agent 评测与本地推理继续推进|「03.19」AI技术进展
速看今日 AI 能力进展|文档理解 / 模型预告 / Agent 评测 / 本地推理 / 算力基础设施
百度把 OCR 继续往“单模型、一遍过、可直接部署”推进,文档理解门槛明显下降。腾讯在财报后的媒体沟通中预告 HY 3.0,将把推理和 Agent 能力继续往上拉。 Amazon 开始把 Agent 评测做成更系统的方法框架。是 Ollama 继续补本地推理和轻量运行侧的工程能力。英伟达 Isambard-AI 上线,算力底座还在继续往上堆。
百度
Qianfan-OCR 把表格、公式、图表和关键信息提取合进一个 4B 模型
百度新模型 Qianfan-OCR,这是一款4B 参数的端到端文档理解模型。它把表格提取、公式识别、图表理解和关键信息提取这些原本常常要拆成多步处理的任务,合进了一个模型里,一次推理就能完成。
以后文档理解这件事会变得更简单。以前这类系统往往要拼很多模块,现在如果一个模型就能做完,部署门槛、维护成本和出错点都会下降,对做票据、报表、论文、合同处理的团队会更友好。

除了模型本身,百度还给出了部署信息:4B 参数可以单卡运行,W8A8 量化下单张 A100 每秒可处理 1.024 页,而且只需要单个 vLLM 实例,不需要多阶段编排。
这让这条能力更新不只是“实验室里更强了”,而是更接近真正能用起来。很多时候,模型有没有价值,不只看它能做什么,还要看它需不需要很重的工程才能跑起来。百度这次把能力和部署一起给出来,实际意义会更强。
腾讯
腾讯预告 HY 3.0 将于 4 月推出,重点拉升推理和 Agent 能力
腾讯在财报发布后的媒体沟通中透露,HY 3.0 正在内部业务测试中,计划于 4 月对外推出。按照目前披露的信息,这会是混元模型的一次重大升级,相比 HY 2.0,推理和 Agent 能力会有明显提升。
这条虽然还是预告,不是正式发布,但价值不低。因为它说明国内大模型竞争已经不只是比聊天和生成,而是在往“推理更强、能做更多事的 Agent”这条路上加速靠拢。后面谁先把这类能力真正做成可体验、可调用的产品,谁就更容易抢到下一阶段的注意力。

Amazon
Strands Evals 把 Agent 评测做成更系统的框架
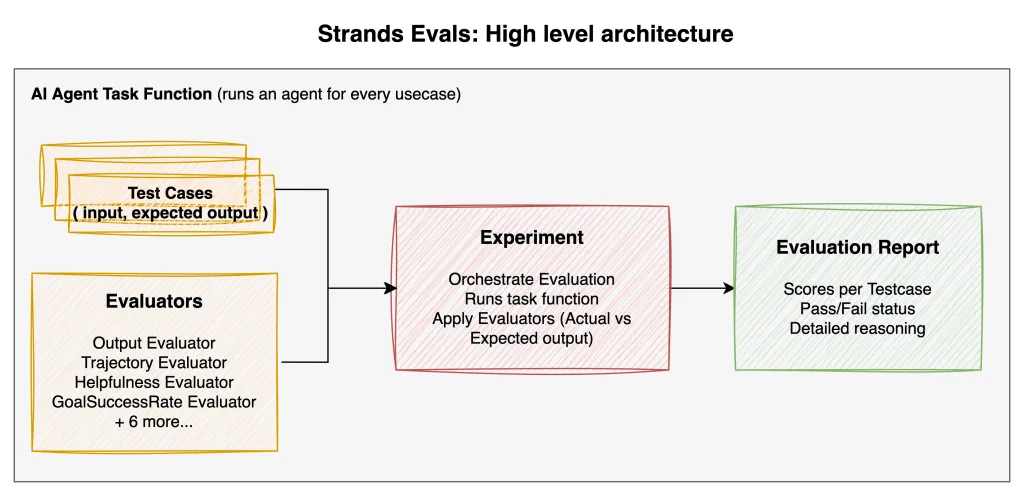
Amazon 这次放出的重点,不是新模型,而是一套更系统的 Agent 评测方法。Strands Evals 提供了案例、实验、评估器、用户模拟、多轮对话测试和工具调用评测这些能力,想解决的是:Agent 不像传统软件那样结果固定,应该怎么更稳定地衡量它到底好不好用。
这类变化对行业很重要,因为 Agent 现在最大的问题已经不只是“能不能跑”,而是“怎么知道它真的靠谱”。评测框架开始变成熟,意味着 Agent 正在从演示阶段往可交付、可上线、可持续优化的阶段走。
Ollama
Ollama 继续补本地推理工程能力,MLX、量化和 websearch 都在往前推
Ollama 这次更新看起来像一串工程项,但核心方向很清楚:
继续补本地和轻量运行能力。里面包括 MLX 相关优化、预量化 tensor packing、量化 embeddings、更快的 SwiGLU、运行时修复,以及给 OpenClaw 注册 websearch。
这类更新声量不一定最大,但它代表另一条很重要的路:不是所有 AI 能力都要往更大模型走,很多团队更在意的是能不能在本地、更轻、更便宜地跑起来。谁把这条路铺得更顺,谁就更容易吃到开发者和个人部署的长期需求。