 夜雨聆风
夜雨聆风





嵌入式AI框架与工具生态
TensorFlow Lite for Microcontrollers
TensorFlow Lite(TFLite)是Google为移动设备和嵌入式设备设计的轻量级推理框架,作为TensorFlow的轻量化版本,针对资源受限环境进行了深度优化。全球有超过40亿台设备支持TFLite,形成了庞大的嵌入式AI部署基础。
TFLite的核心架构包含两大组件。转换器(Converter)将TensorFlow/Keras模型转换为.tflite格式,执行量化、剪枝等优化,实现32位浮点到8位整数的转换,模型体积缩减75%。解释器(Interpreter)提供极简运行时环境,实现静态内存规划避免动态分配开销,支持惰性加载仅实例化必要操作符。
TensorFlow Lite Micro(TFLite Micro)专为微控制器设计,是嵌入式AI落地的核心引擎。其核心特性包括无动态内存分配设计、纯C++11实现、可在无操作系统环境运行、支持ARM Cortex-M0、ESP32、RISC-V等多种芯片架构。典型资源消耗为42KB Flash和不足9KB RAM,功耗仅为毫瓦级。
TFLite Micro支持多种硬件加速委托(Delegates),包括GPU委托(5-10倍性能提升,2.5倍能效比)、Hexagon委托(3-6倍性能提升,3.8倍能效比)、XNNPack(2-4倍性能提升,1.8倍能效比)和CoreML委托(8倍性能提升,4.2倍能效比)。
在STM32H743上启用CMSIS-NN加速后,TinyCNN模型推理时间仅需28ms。在儿童围棋培训班AI智能棋盘应用中,响应延迟小于50ms,仅需AA电池供电即可工作。
CMSIS-NN与ARM AI框架
CMSIS-NN是ARM提供的神经网络推理内核库,专门针对ARM Cortex-M系列处理器优化,可显著提升神经网络推理效率。其核心价值在于运行时间/吞吐量提升4.6倍,能效提升4.9倍,专为物联网边缘设备优化。
CMSIS-NN的架构包含NNFunction(神经网络函数)和NNSupportFunctions(支持函数)两个主要部分。NNFunction实现常用神经网络层类型,包括卷积(Convolution)、深度可分离卷积(Depthwise Separable Convolution)、全连接/内积(Fully Connected / Inner Product)、池化(Pooling)和激活函数(Activation)。NNSupportFunctions提供数据转换实用程序、激活功能表和复杂NN模块构造工具(如LSTM、GRU)。
CMSIS-NN提供基本版本和优化版本的内核函数。基本版本为通用实现,适用于任何图层参数。优化版本应用进一步优化技术,但对输入/参数有特定限制以实现性能最大化。ARM建议使用脚本自动分析网络拓扑,确定最优函数选择,针对特定芯片特性选择最优实现,平衡性能和内存需求。
ONNX Runtime Embedded
ONNX(Open Neural Network Exchange)是微软开发的AI模型通用标准,定义了人工智能模型的通用格式,所有主流AI框架都支持导入或导出ONNX格式模型。ONNX Runtime作为ONNX项目的推理引擎,提供模型优化和量化工具、跨硬件平台执行能力和高效推理性能。
ONNX Runtime在边缘计算中的应用场景包括实时视频分析(通过模型优化实现低延迟推理)、工业物联网数据分析(时序数据异常检测)和健康医疗图像处理(轻量化模型部署)。
2025年,Semidynamics宣布支持ONNX Runtime,推出RISC-V AI开发工具包Aliado SDK。该工具包集成ONNX Runtime对RISC-V硬件的支持,允许直接导入HuggingFace等开源模型库的ONNX模型,无需模型编译步骤,实现快速部署。
STM32Cube.AI生态系统
STM32Cube.AI是STMicroelectronics提供的嵌入式AI完整解决方案,作为STM32CubeMX配置和代码生成工具的扩展包。ST Edge AI Developer Cloud(STEDGEAI-DC)是免费在线平台和服务,提供分析、优化、基准测试和生成嵌入式AI代码功能,支持STM32微控制器和微处理器、神经艺术加速器、Stellar微控制器和智能传感器。
STM32系列微控制器占据全球40%以上市场份额,是中国MCU市场第一名。2025年国内轻量化AI部署首选硬件平台,凭借低功耗、高性能、外设丰富优势。STM32Cube.AI的核心功能包括自动将AI算法(神经网络和经典机器学习模型)转换为优化代码、将生成的优化库集成到用户项目、支持多种AI框架模型导入。
X-CUBE-AI扩展包作为STM32Cube.AI生态系统的核心组件,支持神经网络模型自动转换,提供性能分析和内存估算工具,生成优化库直接集成到项目。
3.5 MicroPython与CircuitPython
MicroPython是Python 3编程语言的精简实现,专为微控制器和嵌入式系统设计,完整Python 3语法支持,配备交互式解释器(REPL)、内置文件系统和硬件外设访问能力。支持STM32系列、ESP32/ESP8266、Raspberry Pi Pico和RISC-V架构芯片。
MicroPython的AI库ulab是numpy的嵌入式替代方案,支持简单的线性代数运算,适用于原型验证和教育场景。
CircuitPython是Adafruit Industries主导的MicroPython分支,更注重易用性和快速原型开发,特点是自动拖放安装库、频繁更新、活跃社区支持。
Python框架适用于快速原型验证、教育学习环境、算法研究和小规模部署,但不适用于硬实时要求系统、安全关键应用(汽车、医疗)、资源极度受限环境和大规模生产部署。
框架综合对比
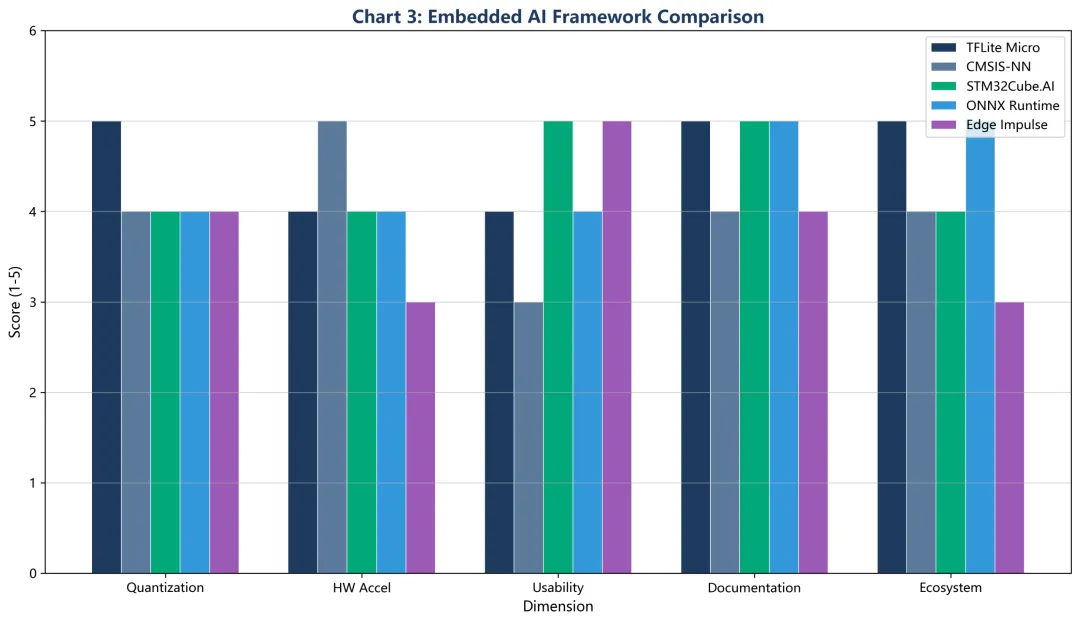
| 框架 | 厂商 | 模型格式 | 量化支持 | 最小Flash | 最小RAM | 适用场景 |
|---|---|---|---|---|---|---|
| TFLite Micro | .tflite | INT8/FP16 | ~42KB | <9KB | MCU/Embedded | |
| CMSIS-NN | ARM | Caffe/Keras/TF | INT8 | ~20KB | ~4KB | Cortex-M |
| ONNX Runtime | Microsoft | .onnx | INT8/FP16 | ~1MB | ~100KB | Cross-platform |
| STM32Cube.AI | ST | 多种 | INT8 | 几十KB | 几KB | STM32专用 |
| Edge Impulse | Edge Impulse | 多种 | 是 | 平台相关 | 平台相关 | 云端开发 |
| MicroPython | 社区 | Python | N/A | ~256KB | ~16KB | 原型/教育 |
框架选型建议:根据硬件平台选择,STM32优先考虑STM32Cube.AI或TFLite Micro + CMSIS-NN,ESP32适用TFLite Micro或MicroPython,RISC-V可选择ONNX Runtime或TFLite Micro。根据性能要求,极低延迟(<10ms)场景选择CMSIS-NN或硬件加速,低功耗(<100mW)场景选择TFLite Micro或MicroPython,高吞吐量场景选择ONNX Runtime或硬件加速。根据开发资源,有限AI知识者选择Edge Impulse或STM32Cube.AI,有充足资源者可选择TFLite Micro + 自定义优化。