 夜雨聆风
夜雨聆风





免费开源 RAG 方案:让 AI 助手记住你的知识库
免费开源 RAG 方案:让 AI 助手记住你的知识库

“给 AI 装上一个外接大脑,它就能记住你的一切。”
你的 AI 助手是不是每次对话都像失忆了?
刚聊过的内容,下次又忘了;精心整理的文档,它根本不知道;想让它基于你的知识回答,却只能无奈地说”我没有相关记忆”。
别急,今天教你用 RAG 技术,让 AI 拥有专属知识库。完全免费、开源、本地化。
💡 看完这篇文章,你将获得:
- • ✅ 理解 RAG 是什么、能做什么、为什么重要
- • ✅ 5 种免费开源 RAG 方案对比(附推荐)
- • ✅ WeKnora 知识库系统详细介绍
- • ✅ 从零部署的完整步骤指南
- • ✅ 与 OpenClaw AI 助手的集成方法
一、为什么 AI 助手需要 RAG?
大模型的”健忘症”
大语言模型(LLM)有两个天生的局限:
- 1. 知识有截止日期 – 训练数据之后发生的事,它不知道
- 2. 对话无长期记忆 – 每次对话都是”新开始”,之前的交流全忘
这就好比你有个很聪明的助手,但每隔几分钟就失忆一次。你需要不断重复背景信息,效率极低。
RAG:给 AI 装个”外接大脑”
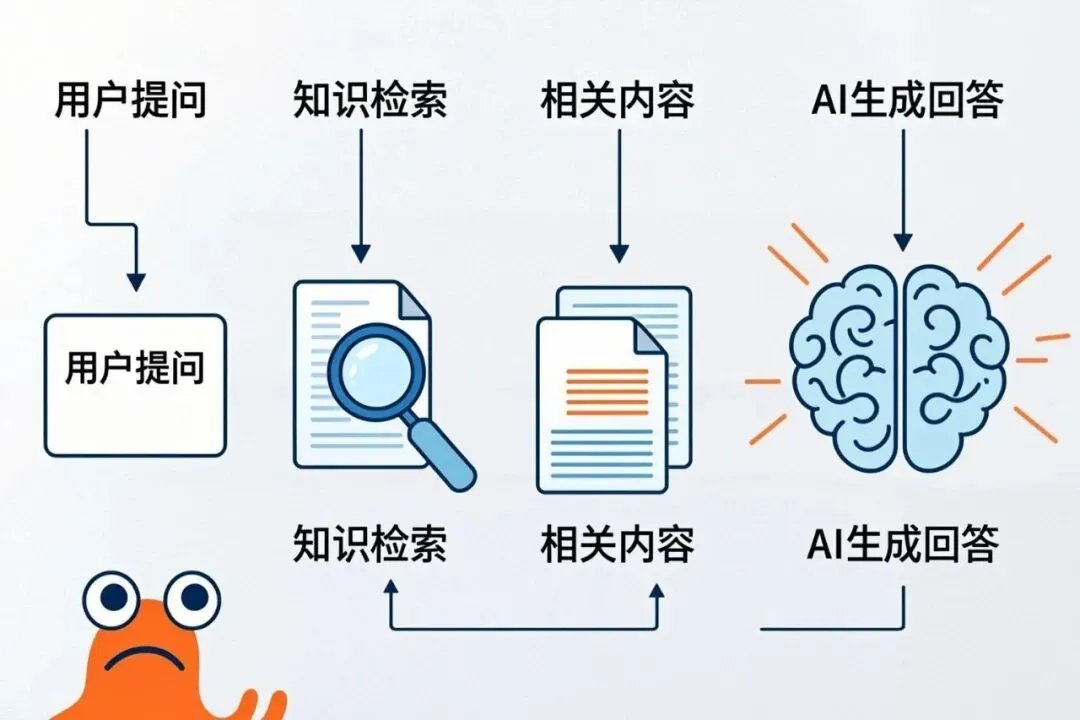
RAG(Retrieval-Augmented Generation,检索增强生成) 的原理很简单:
- 1. 把你的文档、笔记、资料存入知识库
- 2. 当你提问时,先从知识库检索相关内容
- 3. 把检索结果作为”参考资料”喂给大模型
- 4. 大模型基于这些资料生成回答
打个比方:RAG 就像给 AI 配了个图书馆。每次你问问题,它先去图书馆查资料,再回答你。
RAG 能做什么?
| 场景 | 没有RAG | 有RAG |
|---|---|---|
| 企业知识问答 | “我不知道公司政策” | 基于员工手册准确回答 |
| 个人知识管理 | “你没跟我聊过这个” | 从你的笔记中提取信息 |
| 技术文档查询 | “我训练数据里没有” | 直接引用最新文档 |
| 学术研究辅助 | 泛泛而谈 | 基于论文库精准回答 |
二、5 种免费开源 RAG 方案对比
市面上 RAG 方案很多,我们聚焦免费、开源、可自建的选项:
方案对比表
| 方案 | 难度 | 特点 | 适合人群 |
|---|---|---|---|
| LangChain + Chroma | ⭐⭐⭐ | 灵活但需编码 | 开发者 |
| LlamaIndex | ⭐⭐⭐ | 数据连接丰富 | 开发者 |
| Dify | ⭐⭐ | 可视化界面,功能全 | 团队/企业 |
| FastGPT | ⭐⭐ | 国产、中文友好 | 个人/小团队 |
| WeKnora | ⭐ | 极简部署、本地优先 | 个人用户 |
为什么推荐 WeKnora?
如果你是个人用户,想要:
- • ✅ 开箱即用,不想写代码
- • ✅ 完全本地化,数据不外传
- • ✅ 中文支持好,本地模型即可
- • ✅ 与 OpenClaw 等 AI 助手无缝集成
WeKnora 是最佳选择。
三、WeKnora 知识库系统介绍
什么是 WeKnora?
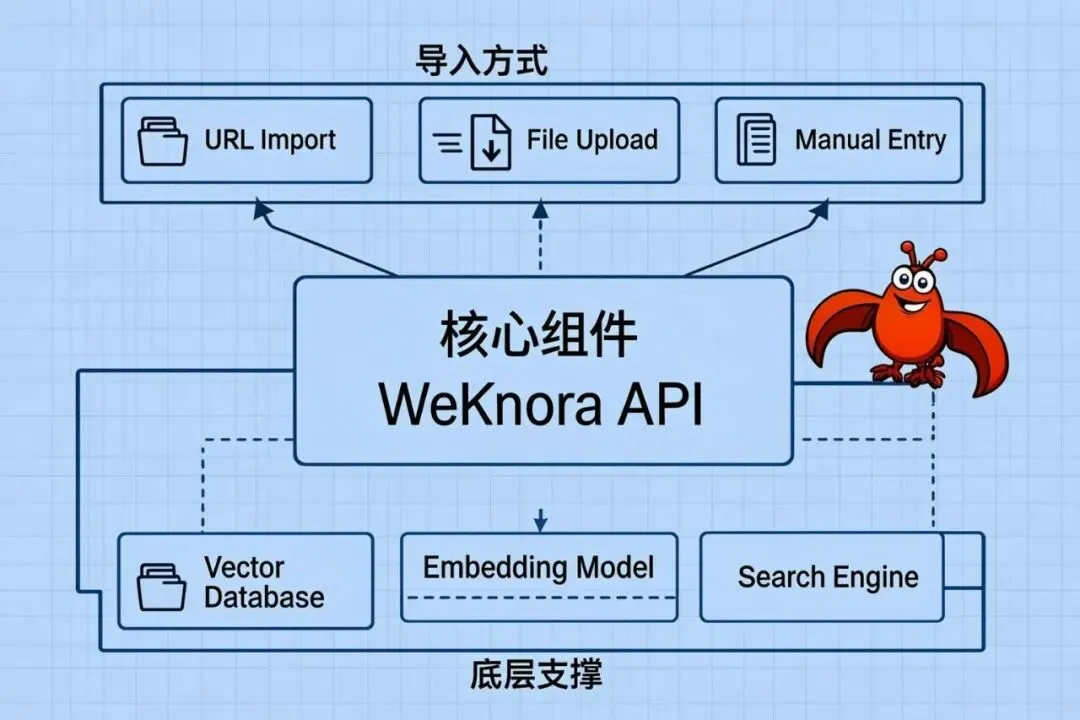
WeKnora 是一个轻量级、本地优先的知识库管理系统:
- • 开源免费:MIT 协议,代码完全透明
- • 本地部署:数据在自己服务器,隐私安全
- • 多模态支持:文本、图片、PDF 都能处理
- • 中文优化:默认使用 bge-large-zh 向量模型
- • 界面友好:Web UI 管理,无需命令行
核心功能
- 1.
- • URL 自动抓取(网页文章)
- • 文件上传(PDF、Word、Markdown)
- • 手动录入
- 2.
- • 自动按语义切分文档
- • 可配置分块大小和重叠度
- • 支持自定义分隔符
- 3.
- • 本地嵌入模型(无需 API)
- • 混合检索(向量 + 关键词)
- • 重排序优化结果
- 4.
- • 创建多个知识库分类管理
- • 支持知识库搜索
- • 自动分类整理
知识导入
智能分块
向量检索
多知识库管理
技术架构
用户提问
↓
OpenClaw AI 助手
↓
WeKnora API
↓
向量数据库(本地)
↓
返回相关知识片段
↓
AI 基于知识生成回答四、WeKnora 部署指南
环境要求
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| CPU | 2核 | 4核+ |
| 内存 | 4GB | 8GB+ |
| 存储 | 20GB | 50GB+ |
| 系统 | Linux/Docker | Linux |
方法一:Docker 部署(推荐)
# 1. 克隆项目
git clone https://github.com/your-org/weknora.git
cd weknora
# 2. 配置环境变量
cp .env.example .env
# 编辑 .env 设置密码、端口等
# 3. 一键启动
docker-compose up -d
# 4. 访问 Web 界面
# http://localhost:8280方法二:源码部署
# 1. 安装依赖
pip install -r requirements.txt
# 2. 配置
cp config.yaml.example config.yaml
# 3. 启动服务
python main.py首次配置
- 1.
- • 访问 Web UI
- • 设置用户名密码
- 2.
- • 默认使用本地 bge-large-zh
- • 也支持 OpenAI、智谱等 API
- 3.
- • 点击”新建知识库”
- • 命名并选择配置
创建管理员账号
配置嵌入模型
创建第一个知识库
五、与 OpenClaw 集成使用
配置 OpenClaw 连接 WeKnora
在 OpenClaw 的配置中添加 WeKnora 连接:
# ~/.openclaw/config.yaml
tools:
weknora:
api_url: http://localhost:8280/api/v1
api_key: YOUR_API_KEY实际使用场景
场景 1:个人知识库
你:帮我查一下上周整理的那篇关于 Docker 的笔记
AI:根据你的知识库,你上周整理的 Docker 笔记主要内容包括...
[准确引用你的笔记内容]场景 2:技术文档查询
你:WeKnora 的默认嵌入模型是什么?
AI:根据 WeKnora 文档,默认使用的是 bge-large-zh-v1.5 模型...
[直接从你导入的文档中提取答案]场景 3:学习资料整理
你:帮我把这篇关于 RAG 的文章要点整理一下
AI:[自动导入文章到知识库]
文章已保存到你的"技术学习"知识库,核心要点包括...六、进阶技巧
1. 优化检索质量
- • 调整分块大小:512-1024 tokens 是中文的甜蜜点
- • 增加重叠度:10-20% 重叠避免语义断裂
- • 使用重排序:二次筛选提高准确率
2. 多知识库策略
| 知识库类型 | 用途 |
|---|---|
| 收件箱 | 新知识暂存,定期整理 |
| 技术文档 | API 文档、教程 |
| 项目笔记 | 工作相关资料 |
| 个人成长 | 学习笔记、读书摘录 |
3. 定期维护
- • 清理过时内容
- • 合并重复知识
- • 调整分类结构
七、常见问题
Q1:RAG 和微调(Fine-tuning)有什么区别?
| 对比 | RAG | 微调 |
|---|---|---|
| 成本 | 低(只需存储) | 高(需要 GPU 训练) |
| 时效性 | 实时更新 | 需重新训练 |
| 适用场景 | 知识检索 | 风格/能力定制 |
| 推荐优先级 | 优先使用 | 特殊需求时 |
Q2:本地模型效果够用吗?
够用。 bge-large-zh 等开源模型在中文场景表现优秀,日常使用完全足够。如有更高要求,可接入商业 API。
Q3:数据安全吗?
完全本地化 = 数据不出你的服务器。 只要服务器安全,数据就安全。这也是自建 RAG 的核心优势。
💬 互动时间
你最想用 RAG 管理什么类型的知识?
- • [ ] A. 工作项目资料(文档、会议记录)
- • [ ] B. 个人学习笔记(读书、课程)
- • [ ] C. 生活信息(账单、证件、健康记录)
欢迎在评论区留言:
- 1. 你目前用什么工具管理知识?
- 2. 部署过程中遇到什么问题?
- 3. 希望下期介绍哪个 RAG 方案?
觉得有用?点个「在看」让更多人看到 👇
本文是「OpenClaw 免费工具/助手」系列第 3 篇。
关注公众号,获取更多 AI 助手技巧!