 夜雨聆风
夜雨聆风





最新arXiv具身导航论文合集!机器人&无人机&智能体视觉语言导航全方面突破
本文整理arXiv平台近期发布的20篇具身导航领域最新研究论文,涵盖视觉语言导航、强化学习导航、无人机协同、特殊环境适配等多个核心方向,聚焦机器人、智能体、辅助设备等多类载体的导航技术突破!
视觉语言导航(VLN)核心突破
记忆增强型导航!HiMemVLN:开源模型如何突破视觉语言导航的“失忆”瓶颈?
基本信息
-
作者:Kailin Lyu, Kangyi Wu 等 -
单位:中科院自动化所、西安交通大学、华为、京东等 -
论文标题:HiMemVLN: Enhancing Reliability of Open-Source Zero-Shot Vision-and-Language Navigation with Hierarchical Memory System -
论文链接:https://arxiv.org/abs/2603.14807v1 -
代码链接:https://github.com/lvkailin0118/HiMemVLN
简要介绍
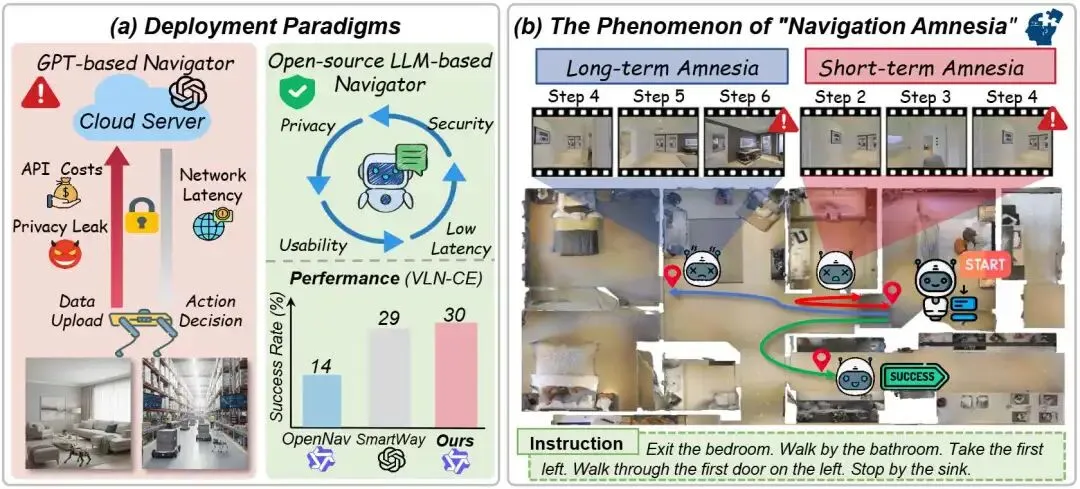 当前基于大语言模型的视觉语言导航系统多依赖闭源模型,存在成本高、数据泄露风险等问题。虽然已有研究尝试用开源模型结合时空推理框架,但其性能仍远逊于闭源方案。本文通过深入分析导航过程,发现了一个关键问题——导航失忆(Navigation Amnesia),即智能体在复杂环境中容易遗忘先前感知的视觉信息,导致定位失败。为解决这一痛点,研究团队提出HiMemVLN框架,通过引入分层记忆系统增强多模态大模型的视觉感知回忆与长期定位能力。实验表明,该方法在仿真和真实场景中均显著提升导航可靠性,性能达到现有开源最优方法的近两倍,为低成本、高可靠性的自主导航提供了新思路。
当前基于大语言模型的视觉语言导航系统多依赖闭源模型,存在成本高、数据泄露风险等问题。虽然已有研究尝试用开源模型结合时空推理框架,但其性能仍远逊于闭源方案。本文通过深入分析导航过程,发现了一个关键问题——导航失忆(Navigation Amnesia),即智能体在复杂环境中容易遗忘先前感知的视觉信息,导致定位失败。为解决这一痛点,研究团队提出HiMemVLN框架,通过引入分层记忆系统增强多模态大模型的视觉感知回忆与长期定位能力。实验表明,该方法在仿真和真实场景中均显著提升导航可靠性,性能达到现有开源最优方法的近两倍,为低成本、高可靠性的自主导航提供了新思路。
DecoVLN让AI在复杂环境中精准执行长指令
基本信息
-
作者:Zihao Xin, Wentong Li 等 -
单位:南京航空航天大学、山东大学 -
论文标题:DecoVLN: Decoupling Observation, Reasoning, and Correction for Vision-and-Language Navigation -
论文链接:https://arxiv.org/abs/2603.13133v1 -
代码链接:https://allenxinn.github.io/DecoVLN/
简要介绍
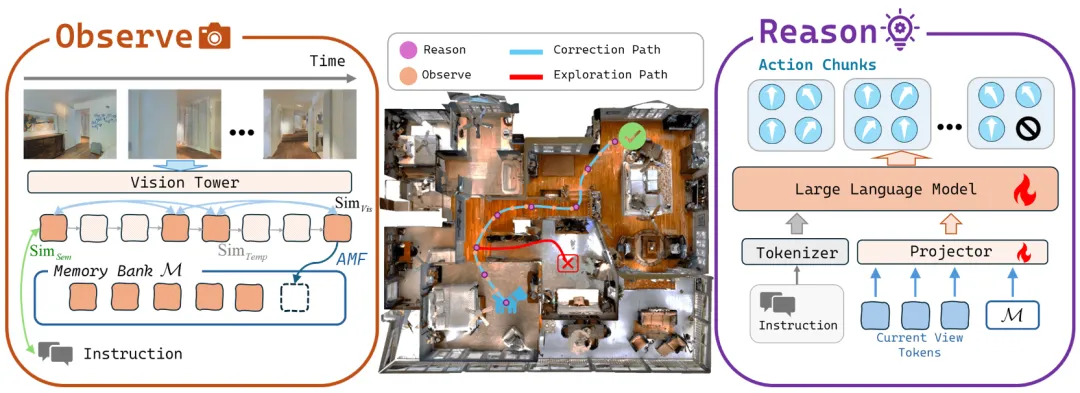 在视觉与语言导航任务中,AI智能体需要根据复杂的长指令在三维环境中进行精准导航。传统方法面临长期记忆构建困难和误差累积两大挑战。最新提出的DecoVLN框架通过创新性的解耦设计实现了突破性进展。该框架首先将长期记忆构建转化为优化问题,通过自适应优化机制从历史候选帧中筛选出语义相关性强、视觉多样性高且时间覆盖广的关键画面。其次,针对误差累积问题,研究团队提出了状态-动作对级别的纠错微调策略,利用状态间的测地距离精确量化偏离程度,在可信区域内收集高质量数据并过滤污染样本。实验证明该方法显著提升了导航的准确性和鲁棒性,并已成功应用于真实环境部署。
在视觉与语言导航任务中,AI智能体需要根据复杂的长指令在三维环境中进行精准导航。传统方法面临长期记忆构建困难和误差累积两大挑战。最新提出的DecoVLN框架通过创新性的解耦设计实现了突破性进展。该框架首先将长期记忆构建转化为优化问题,通过自适应优化机制从历史候选帧中筛选出语义相关性强、视觉多样性高且时间覆盖广的关键画面。其次,针对误差累积问题,研究团队提出了状态-动作对级别的纠错微调策略,利用状态间的测地距离精确量化偏离程度,在可信区域内收集高质量数据并过滤污染样本。实验证明该方法显著提升了导航的准确性和鲁棒性,并已成功应用于真实环境部署。
HaltNav让机器人学会“见机行事”
基本信息
-
作者:Pingcong Li, Zihui Yu 等 -
单位:上海科技大学 -
论文标题:HaltNav: Reactive Visual Halting over Lightweight Topological Priors for Robust Vision-Language Navigation -
论文链接:https://arxiv.org/abs/2603.12696v1
简要介绍
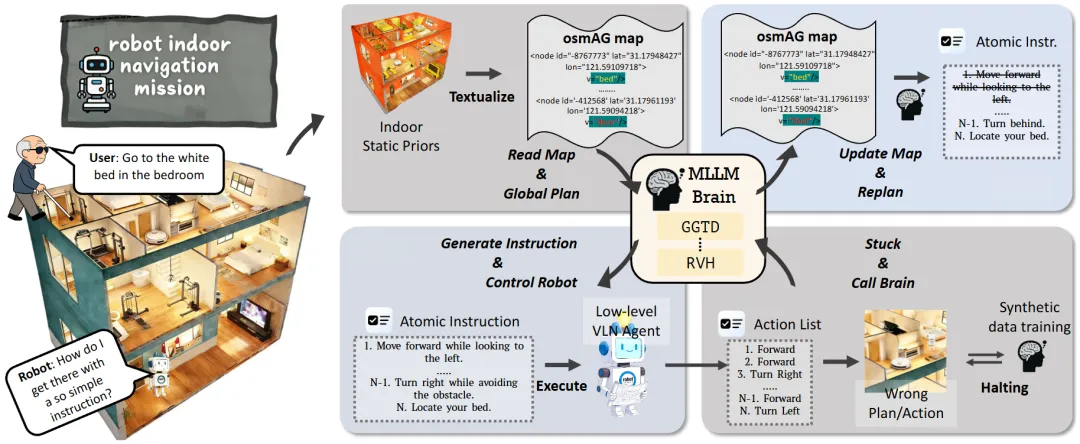 视觉语言导航(VLN)正从刻板的逐步指令跟随转向更具自主性的目标导向导航。最新研究HaltNav提出了一种创新解决方案,让机器人在复杂环境中真正实现“见机行事”。该研究巧妙结合了轻量级拓扑地图osmAG与多模态大语言模型的智能决策能力,构建了一个分层导航框架。其核心突破在于反应式视觉停止机制——当机器人检测到实际环境与预期不符(如门关闭或通道拥挤)时,能够主动暂停执行,实时更新地图并重新规划路径。研究人员还开发了数据合成流程,利用生成模型创造包含障碍物的训练场景,大幅提升了系统的异常处理能力。实验证明,该方法在无需繁琐语言指令的情况下,显著提升了长距离导航在环境变化下的鲁棒性,为智能机器人的实际部署提供了重要技术支撑。
视觉语言导航(VLN)正从刻板的逐步指令跟随转向更具自主性的目标导向导航。最新研究HaltNav提出了一种创新解决方案,让机器人在复杂环境中真正实现“见机行事”。该研究巧妙结合了轻量级拓扑地图osmAG与多模态大语言模型的智能决策能力,构建了一个分层导航框架。其核心突破在于反应式视觉停止机制——当机器人检测到实际环境与预期不符(如门关闭或通道拥挤)时,能够主动暂停执行,实时更新地图并重新规划路径。研究人员还开发了数据合成流程,利用生成模型创造包含障碍物的训练场景,大幅提升了系统的异常处理能力。实验证明,该方法在无需繁琐语言指令的情况下,显著提升了长距离导航在环境变化下的鲁棒性,为智能机器人的实际部署提供了重要技术支撑。
强化学习与鲁棒导航
智能体迷路怎么办?NavGRPO让AI导航抗干扰能力暴增14.89%!
基本信息
-
作者:Jiangyang Li, Cong Wan 等 -
单位:西安交通大学、深圳理工大学 -
论文标题:Trajectory-Diversity-Driven Robust Vision-and-Language Navigation -
论文链接:https://arxiv.org/abs/2603.15370v1
简要介绍
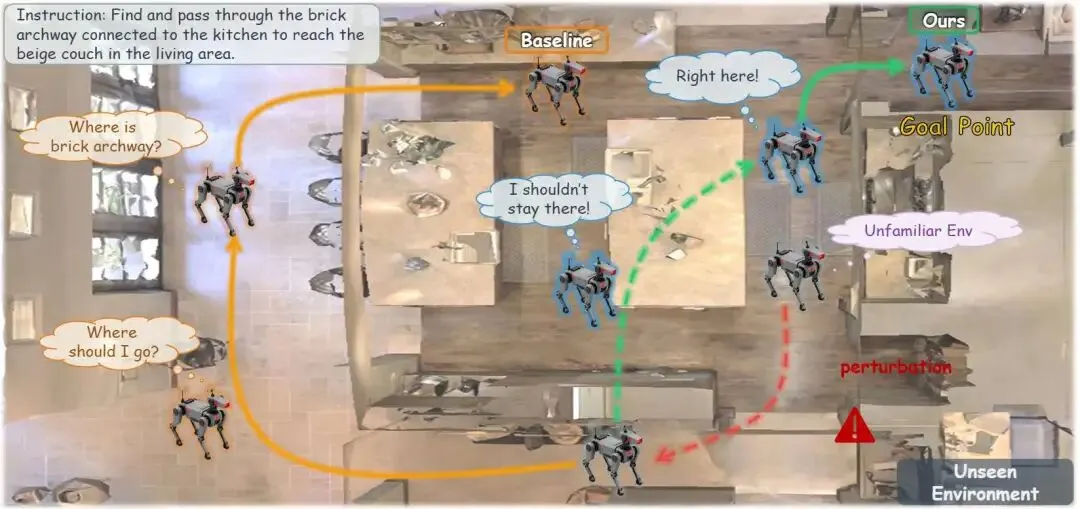 想让AI像人类一样根据语言指令在真实环境中导航?当前主流的模仿学习方法存在泛化能力弱、抗干扰性差的问题。本文提出NavGRPO强化学习框架,通过探索多样化轨迹并进行组内策略优化,让智能体学会辨别超越专家路径的有效策略。该方法在R2R和REVERIE基准测试中,未知环境下的导航成功率分别提升3.0%和1.71%。更令人惊喜的是,在极端干扰条件下,其导航稳健性比基线方法提升**14.89%**,证明目标导向的强化学习能显著增强智能体的抗干扰能力。这一突破为服务机器人、智能助手的实际应用奠定了重要基础。
想让AI像人类一样根据语言指令在真实环境中导航?当前主流的模仿学习方法存在泛化能力弱、抗干扰性差的问题。本文提出NavGRPO强化学习框架,通过探索多样化轨迹并进行组内策略优化,让智能体学会辨别超越专家路径的有效策略。该方法在R2R和REVERIE基准测试中,未知环境下的导航成功率分别提升3.0%和1.71%。更令人惊喜的是,在极端干扰条件下,其导航稳健性比基线方法提升**14.89%**,证明目标导向的强化学习能显著增强智能体的抗干扰能力。这一突破为服务机器人、智能助手的实际应用奠定了重要基础。
超越模仿:强化学习微调让机器人导航更智能
基本信息
-
作者:Junhe Sheng, Ruofei Bai 等 -
单位:南洋理工大学、新加坡科技研究局、新加坡国立大学 -
论文标题:Beyond Imitation: Reinforcement Learning Fine-Tuning for Adaptive Diffusion Navigation Policies -
论文链接:https://arxiv.org/abs/2603.12868v1
简要介绍
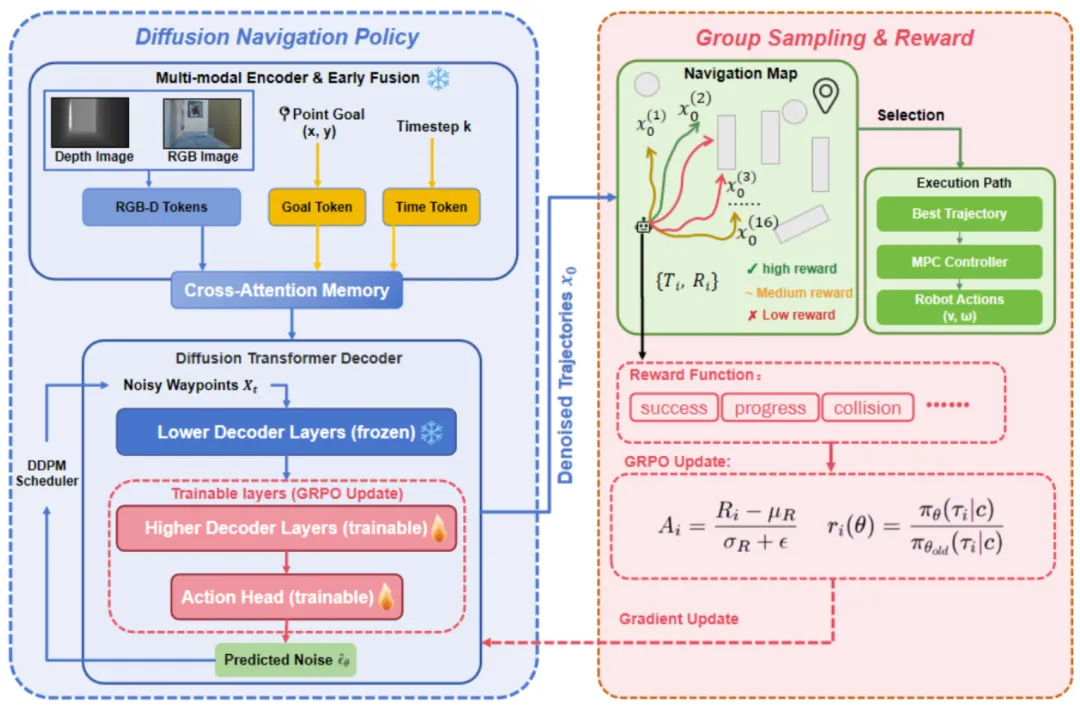 基于扩散模型的机器人导航策略通过大规模模仿学习训练,能够直接从视觉观察生成多模态轨迹,实现零样本泛化。然而,其性能受限于离线数据集覆盖范围,在未知环境中容易因分布偏移导致轨迹误差累积和安全风险。传统强化学习方法难以直接微调扩散策略,因为其迭代去噪结构阻碍梯度回传,且训练价值网络计算成本高、稳定性差。研究团队提出了一种专为扩散导航设计的强化学习微调框架。该方法利用扩散模型固有的多轨迹采样机制,采用组相对策略优化(GRPO),无需单独的价值网络即可评估轨迹间的相对优势。通过冻结视觉编码器并选择性更新高层解码器和动作头,在保持预训练表征的同时实现环境自适应。实验表明,该方法在未知场景中将成功率从52.0%提升至58.7%,路径长度指标从0.49优化至0.54,并显著降低碰撞频率。微调后的策略还能零样本迁移至真实四足机器人平台,在几何分布外环境中保持稳定性能,展现出卓越的适应性和安全泛化能力。
基于扩散模型的机器人导航策略通过大规模模仿学习训练,能够直接从视觉观察生成多模态轨迹,实现零样本泛化。然而,其性能受限于离线数据集覆盖范围,在未知环境中容易因分布偏移导致轨迹误差累积和安全风险。传统强化学习方法难以直接微调扩散策略,因为其迭代去噪结构阻碍梯度回传,且训练价值网络计算成本高、稳定性差。研究团队提出了一种专为扩散导航设计的强化学习微调框架。该方法利用扩散模型固有的多轨迹采样机制,采用组相对策略优化(GRPO),无需单独的价值网络即可评估轨迹间的相对优势。通过冻结视觉编码器并选择性更新高层解码器和动作头,在保持预训练表征的同时实现环境自适应。实验表明,该方法在未知场景中将成功率从52.0%提升至58.7%,路径长度指标从0.49优化至0.54,并显著降低碰撞频率。微调后的策略还能零样本迁移至真实四足机器人平台,在几何分布外环境中保持稳定性能,展现出卓越的适应性和安全泛化能力。
强化学习让机器人更智能地执行长距离任务
基本信息
-
作者:Mateo Haro, Julia Richter 等 -
单位:苏黎世联邦理工学院 -
论文标题:Path-conditioned Reinforcement Learning-based Local Planning for Long-Range Navigation -
论文链接:https://arxiv.org/abs/2603.13888v1
简要介绍
 在长距离机器人导航中,传统方法通常采用分层规划策略:先由全局规划器生成路径,再由局部规划器依次跟踪路径点。然而,这种方法高度依赖全局路径的质量,一旦遥感数据不准确,可能导致局部路径点不可行,严重影响执行效率。同时,局部规划器缺乏全局上下文信息,也限制了长距离导航的效果。为解决这一问题,研究团队提出了一种基于强化学习的局部导航策略,能够将路径信息作为上下文指导。该策略在训练过程中主要依赖目标到达奖励,而不使用显式的路径跟踪奖励。通过这种隐式条件化机制,策略学会了在高质量路径可用时有效利用路径信息,同时在路径信息质量下降甚至缺失时仍能保持鲁棒性。实验结果表明,该方法在高质量路径可用时显著提高了导航效率,在路径观测严重退化时仍能保持基准性能。这一特性使其特别适用于全局规划不精确、局部执行需适应不确定性的长距离导航场景。
在长距离机器人导航中,传统方法通常采用分层规划策略:先由全局规划器生成路径,再由局部规划器依次跟踪路径点。然而,这种方法高度依赖全局路径的质量,一旦遥感数据不准确,可能导致局部路径点不可行,严重影响执行效率。同时,局部规划器缺乏全局上下文信息,也限制了长距离导航的效果。为解决这一问题,研究团队提出了一种基于强化学习的局部导航策略,能够将路径信息作为上下文指导。该策略在训练过程中主要依赖目标到达奖励,而不使用显式的路径跟踪奖励。通过这种隐式条件化机制,策略学会了在高质量路径可用时有效利用路径信息,同时在路径信息质量下降甚至缺失时仍能保持鲁棒性。实验结果表明,该方法在高质量路径可用时显著提高了导航效率,在路径观测严重退化时仍能保持基准性能。这一特性使其特别适用于全局规划不精确、局部执行需适应不确定性的长距离导航场景。
动态社交导航与世界模型
NavThinker让AI学会”预见未来”的导航思维
基本信息
-
作者:Tianshuai Hu, Zeying Gong 等 -
单位:香港科技大学、香港科技大学(广州)、新加坡国立大学、中国科学院大学 -
论文标题:NavThinker: Action-Conditioned World Models for Coupled Prediction and Planning in Social Navigation -
论文链接:https://arxiv.org/abs/2603.15359v1 -
代码链接:https://github.com/hutslib/NavThinker
简要介绍
 在动态的人类环境中,机器人如何安全导航一直是个重大挑战。传统方法往往只关注当前观察,而忽视了机器人行动对未来场景的影响。NavThinker提出了一种革命性的解决方案:让机器人学会”预见未来“!该框架结合了动作条件化的世界模型和强化学习,能够预测不同行动下场景几何和行人轨迹的演变。通过Depth Anything V2特征空间进行自回归预测,系统不仅能生成未来深度图,还能评估通行可行性和交互风险。实验证明,NavThinker在单/多机器人场景中都达到了最先进的导航成功率,并成功实现了向新环境的零样本迁移和真实机器人部署。这一突破为机器人在复杂社会环境中的智能导航开辟了新路径。
在动态的人类环境中,机器人如何安全导航一直是个重大挑战。传统方法往往只关注当前观察,而忽视了机器人行动对未来场景的影响。NavThinker提出了一种革命性的解决方案:让机器人学会”预见未来“!该框架结合了动作条件化的世界模型和强化学习,能够预测不同行动下场景几何和行人轨迹的演变。通过Depth Anything V2特征空间进行自回归预测,系统不仅能生成未来深度图,还能评估通行可行性和交互风险。实验证明,NavThinker在单/多机器人场景中都达到了最先进的导航成功率,并成功实现了向新环境的零样本迁移和真实机器人部署。这一突破为机器人在复杂社会环境中的智能导航开辟了新路径。
跨越形态的智能导航新进展:FLUX让机器人更懂“社交”
基本信息
-
作者:Zeying Gong, Yangyi Zhong 等 -
单位:香港科技大学(广州)、香港科技大学、新加坡国立大学 -
论文标题:FLUX: Accelerating Cross-Embodiment Generative Navigation Policies via Rectified Flow and Static-to-Dynamic Learning -
论文链接:https://arxiv.org/abs/2603.12806v1 -
代码链接:https://zeying-gong.github.io/projects/flux/
简要介绍
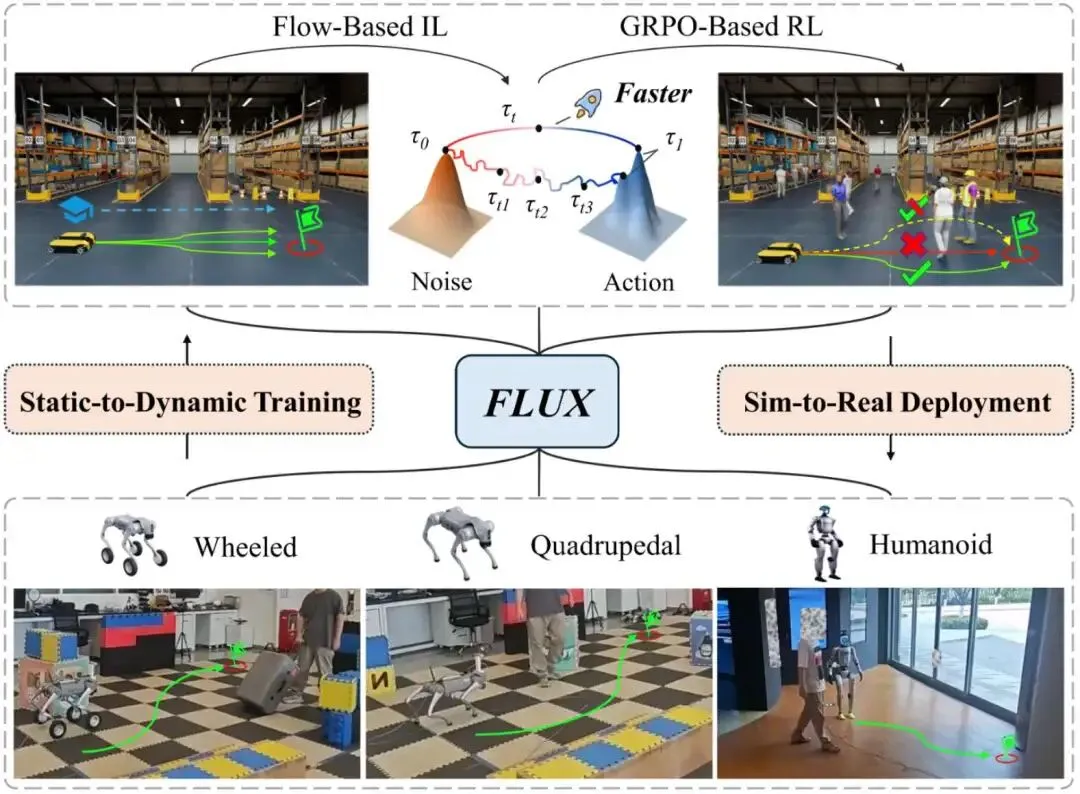 自主导航技术正面临从静态目标追踪到动态社交穿越的多重挑战,而现有评估体系却长期处于割裂状态。研究团队提出DynBench动态导航基准,结合物理真实的人群模拟,与现有静态协议共同构建了覆盖六大核心导航任务的完整评估体系。在此基础上,FLUX作为首个基于流模型(Flow)的统一导航策略应运而生。通过线性化概率流,FLUX用直线轨迹替代迭代去噪过程,单步推理效率较之前流方法提升47%,比扩散模型快29%。采用”静态到动态”课程学习策略,FLUX先建立几何先验知识,再通过强化学习在动态社交环境中微调。这种训练机制不仅强化了社交感知能力,还通过随机动作分布捕捉恢复行为,提升了静态任务的鲁棒性。FLUX在全部任务中实现最先进性能,并在轮式、四足和人形机器人上实现零样本仿真到现实迁移,无需任何微调。
自主导航技术正面临从静态目标追踪到动态社交穿越的多重挑战,而现有评估体系却长期处于割裂状态。研究团队提出DynBench动态导航基准,结合物理真实的人群模拟,与现有静态协议共同构建了覆盖六大核心导航任务的完整评估体系。在此基础上,FLUX作为首个基于流模型(Flow)的统一导航策略应运而生。通过线性化概率流,FLUX用直线轨迹替代迭代去噪过程,单步推理效率较之前流方法提升47%,比扩散模型快29%。采用”静态到动态”课程学习策略,FLUX先建立几何先验知识,再通过强化学习在动态社交环境中微调。这种训练机制不仅强化了社交感知能力,还通过随机动作分布捕捉恢复行为,提升了静态任务的鲁棒性。FLUX在全部任务中实现最先进性能,并在轮式、四足和人形机器人上实现零样本仿真到现实迁移,无需任何微调。
智能轮椅新突破:SAATT Nav让AI更懂”人情世故”的导航系统
基本信息
-
作者:Yutong Zhang, Shaiv Y. Mehra 等 -
单位:普渡大学 -
论文标题:SAATT Nav: a Socially Aware Autonomous Transparent Transportation Navigation Framework for Wheelchairs -
论文链接:https://arxiv.org/abs/2603.13698v1
简要介绍
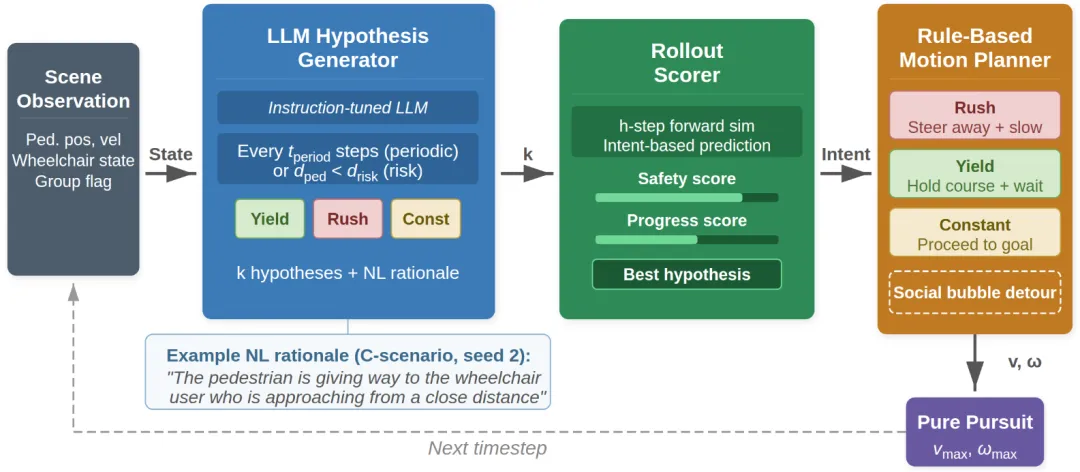 传统电动轮椅虽然减轻了行动不便者的体力负担,但在复杂社交环境中却给使用者带来巨大的认知压力。现有自动驾驶系统普遍缺乏社交意识,决策过程不透明,导致用户安全感降低。这项研究提出的SAATT导航框架创新性地采用大语言模型作为决策核心,能够理解用户意图并预测周围行人行为,智能应对诸如避让行人、绕过交谈人群等社交场景。更值得一提的是,系统会在每个路径点用文字说明其决策理由,实现完全透明的交互过程。在模拟环境中与主流导航系统对比测试显示,SAATT在安全性、社交合规性等八项指标中表现优异,特别是在社交场景下优势明显,为智能轮椅领域带来了突破性进展。
传统电动轮椅虽然减轻了行动不便者的体力负担,但在复杂社交环境中却给使用者带来巨大的认知压力。现有自动驾驶系统普遍缺乏社交意识,决策过程不透明,导致用户安全感降低。这项研究提出的SAATT导航框架创新性地采用大语言模型作为决策核心,能够理解用户意图并预测周围行人行为,智能应对诸如避让行人、绕过交谈人群等社交场景。更值得一提的是,系统会在每个路径点用文字说明其决策理由,实现完全透明的交互过程。在模拟环境中与主流导航系统对比测试显示,SAATT在安全性、社交合规性等八项指标中表现优异,特别是在社交场景下优势明显,为智能轮椅领域带来了突破性进展。
室内路标、仿真与特殊环境导航
让AI学会看路标!SignNav让机器人在复杂室内环境中实现智能导航
基本信息
-
作者:Jian Sun, Yuming Huang 等 -
单位:澳门大学科技学院、密歇根大学机器人系 -
论文标题:SignNav: Leveraging Signage for Semantic Visual Navigation in Large-Scale Indoor Environments -
论文链接:https://arxiv.org/abs/2603.16166v1
简要介绍
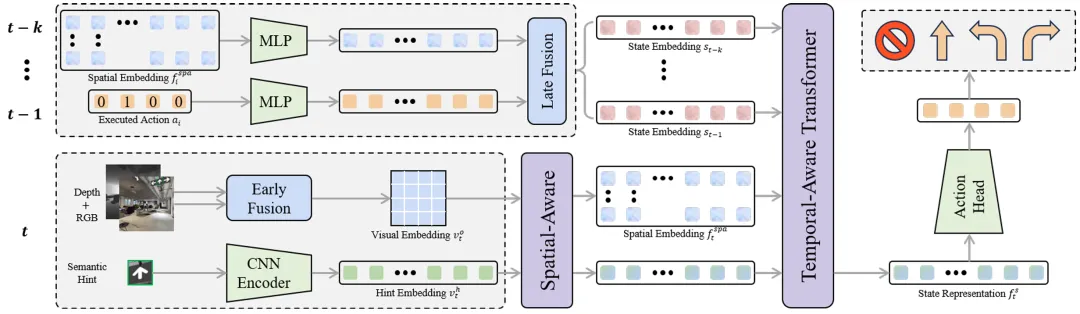 在大型室内场所如医院、机场中,人类能够轻松借助路标指示牌进行导航,但这一能力在机器人导航领域却鲜有研究。本文创新性地提出SignNav任务,要求智能体能够理解路标提供的语义信息,并根据当前观察决定下一步行动。为了推动该领域研究,团队构建了LSI数据集用于训练和评估各种SignNav智能体。面对路标语义动态变化和稀疏分布等挑战,研究人员提出时空感知Transformer(START)模型。该模型通过空间感知模块将路标语义信息与现实世界对应,时间感知模块则捕捉历史状态与当前观察之间的长期依赖关系。采用两阶段训练策略和数据集聚合方法,该方法在val-unseen数据集上取得80%的成功率和0.74的NDTW分数,并在真实环境中验证了其无需预建地图的实用性。这项研究为机器人在复杂室内环境中的自主导航开辟了新方向,有望在未来服务机器人、智能导览等场景发挥重要作用。
在大型室内场所如医院、机场中,人类能够轻松借助路标指示牌进行导航,但这一能力在机器人导航领域却鲜有研究。本文创新性地提出SignNav任务,要求智能体能够理解路标提供的语义信息,并根据当前观察决定下一步行动。为了推动该领域研究,团队构建了LSI数据集用于训练和评估各种SignNav智能体。面对路标语义动态变化和稀疏分布等挑战,研究人员提出时空感知Transformer(START)模型。该模型通过空间感知模块将路标语义信息与现实世界对应,时间感知模块则捕捉历史状态与当前观察之间的长期依赖关系。采用两阶段训练策略和数据集聚合方法,该方法在val-unseen数据集上取得80%的成功率和0.74的NDTW分数,并在真实环境中验证了其无需预建地图的实用性。这项研究为机器人在复杂室内环境中的自主导航开辟了新方向,有望在未来服务机器人、智能导览等场景发挥重要作用。
突破视觉极限!NavGSim:高斯溅射打造超逼真机器人导航仿真平台
基本信息
-
作者:Jiahang Liu, Yuanxing Duan 等 -
单位:北京大学、银河通用、北京智源人工智能研究院 -
论文标题:NavGSim: High-Fidelity Gaussian Splatting Simulator for Large-Scale Navigation -
论文链接:https://arxiv.org/abs/2603.15186v1 -
代码链接:https://github.com/2003jiahang/NavGSim
简要介绍
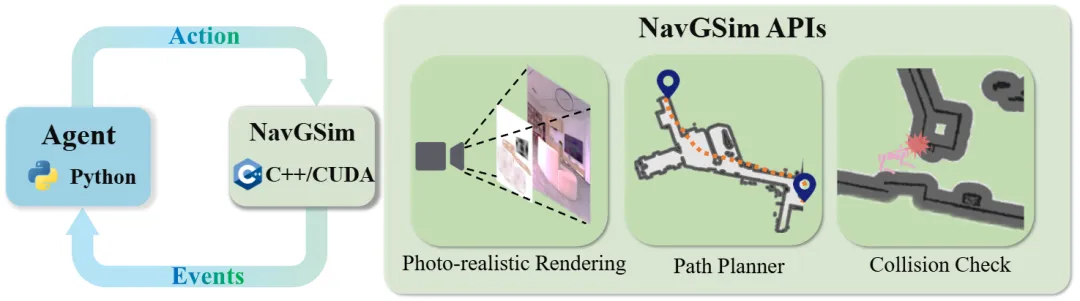 在机器人学习领域,如何构建逼真的仿真环境一直是个重大挑战。NavGSim创新性地采用高斯溅射技术,成功打造出首个支持百米级大范围场景的高保真导航仿真器。该平台基于分层3D高斯溅射框架,能够实现跨越多房间甚至整层楼的大规模场景照片级渲染。更令人惊喜的是,研究团队开发了基于高斯溅射的切片技术,可直接从重建的高斯模型中提取可行走区域,精准模拟导航碰撞。同时提供完整的多GPU开发API,支持自定义场景重建、机器人配置、策略训练和评估全流程。实验证明,在NavGSim上训练的视觉-语言-动作模型显著提升了场景理解能力,为机器人导航技术的突破性发展奠定了坚实基础。
在机器人学习领域,如何构建逼真的仿真环境一直是个重大挑战。NavGSim创新性地采用高斯溅射技术,成功打造出首个支持百米级大范围场景的高保真导航仿真器。该平台基于分层3D高斯溅射框架,能够实现跨越多房间甚至整层楼的大规模场景照片级渲染。更令人惊喜的是,研究团队开发了基于高斯溅射的切片技术,可直接从重建的高斯模型中提取可行走区域,精准模拟导航碰撞。同时提供完整的多GPU开发API,支持自定义场景重建、机器人配置、策略训练和评估全流程。实验证明,在NavGSim上训练的视觉-语言-动作模型显著提升了场景理解能力,为机器人导航技术的突破性发展奠定了坚实基础。
突破黑暗!eNavi:事件相机让机器人在低光环境下也能精准跟随
基本信息
-
作者:Prithvi Jai Ramesh, Kaustav Chanda 等 -
单位:亚利桑那州立大学 -
论文标题:eNavi: Event-based Imitation Policies for Low-Light Indoor Mobile Robot Navigation -
论文链接:https://arxiv.org/abs/2603.14397v1 -
代码链接:https://eventbasedvision.github.io/eNavi/
简要介绍
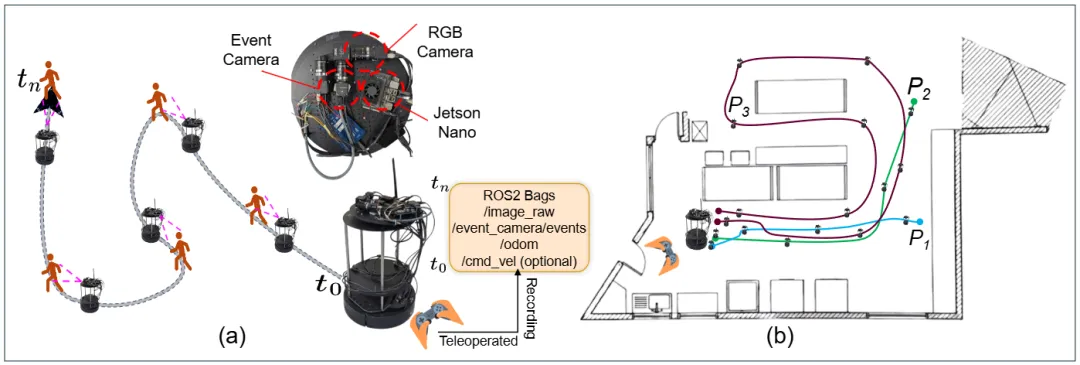 传统RGB相机在低光或快速移动场景下表现不佳,而事件相机凭借高动态范围和微秒级响应优势成为机器人导航的新选择。研究团队首次构建了包含同步事件流、RGB帧和专家控制动作的真实室内人跟随数据集,覆盖正常与低光多种场景。基于此,他们创新性地提出了一种基于Transformer的RGB-Event双模态融合导航策略,通过行为克隆训练实现端到端控制。实验结果表明,融合事件数据的策略在12种训练变体中表现最优,特别是在未见过的低光环境下,其动作预测误差显著低于纯RGB模型,展现出卓越的鲁棒性。这项研究为黑暗环境下的自主导航提供了重要技术突破。
传统RGB相机在低光或快速移动场景下表现不佳,而事件相机凭借高动态范围和微秒级响应优势成为机器人导航的新选择。研究团队首次构建了包含同步事件流、RGB帧和专家控制动作的真实室内人跟随数据集,覆盖正常与低光多种场景。基于此,他们创新性地提出了一种基于Transformer的RGB-Event双模态融合导航策略,通过行为克隆训练实现端到端控制。实验结果表明,融合事件数据的策略在12种训练变体中表现最优,特别是在未见过的低光环境下,其动作预测误差显著低于纯RGB模型,展现出卓越的鲁棒性。这项研究为黑暗环境下的自主导航提供了重要技术突破。
机器人如何「自学成才」?新型地图管理技术让长期导航更智能
基本信息
-
作者:Lucie Halodova, Eliska Dvorakova 等 -
单位:捷克理工大学、卡塔赫纳理工大学、昆士兰科技大学 -
论文标题:Predictive and adaptive maps for long-term visual navigation in changing environments -
论文链接:https://arxiv.org/abs/2603.12460v1
简要介绍
 在动态变化的环境中实现机器人长期自主导航一直是个重大挑战。传统视觉导航系统往往难以适应环境外观的持续变化,比如光照条件、季节更替或物体移动等。这项研究通过为期三个月的实验,对比了多种地图管理策略的性能表现。研究团队提出了一种创新方法:通过建模环境外观的周期性变化,预测在特定时间和地点哪些地图特征将会可见。实验结果表明,这种能够显式建模时间演变规律的策略,在机器人定位精度上显著优于不考虑时间因素的常规方法。该技术为服务机器人、自动驾驶等长期运行系统提供了更可靠的环境适应能力,让机器真正实现「与时俱进」的智能导航。
在动态变化的环境中实现机器人长期自主导航一直是个重大挑战。传统视觉导航系统往往难以适应环境外观的持续变化,比如光照条件、季节更替或物体移动等。这项研究通过为期三个月的实验,对比了多种地图管理策略的性能表现。研究团队提出了一种创新方法:通过建模环境外观的周期性变化,预测在特定时间和地点哪些地图特征将会可见。实验结果表明,这种能够显式建模时间演变规律的策略,在机器人定位精度上显著优于不考虑时间因素的常规方法。该技术为服务机器人、自动驾驶等长期运行系统提供了更可靠的环境适应能力,让机器真正实现「与时俱进」的智能导航。
当AI学会”脑补”导航:ImagiNav让机器人看懂指令自主寻路
基本信息
-
作者:Jie Chen, Yuxin Cai 等 -
单位:新加坡国立大学、新加坡科技研究局、南洋理工大学 -
论文标题:ImagiNav: Scalable Embodied Navigation via Generative Visual Prediction and Inverse Dynamics -
论文链接:https://arxiv.org/abs/2603.13833v1 -
代码链接:https://j1dan.github.io/ImagiNav
简要介绍
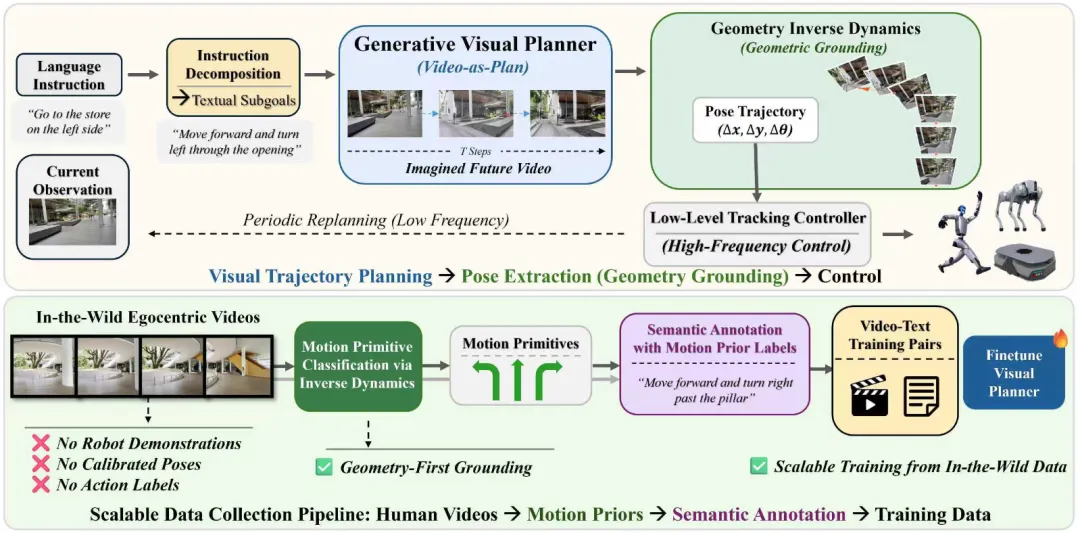 想让机器人听懂”去厨房拿杯水”这样的指令并自主导航?传统方法需要大量机器人专属数据训练,成本高昂且难以扩展。ImagiNav提出了一种革命性的模块化方案:首先通过视觉语言模型将复杂指令分解为文本子目标;然后利用微调后的生成视频模型”脑补”出通往子目标的未来视频轨迹;最后通过逆动力学模型从想象视频中提取可执行轨迹。更巧妙的是,团队开发了自动化数据流水线,能够利用海量未标注的野外导航视频进行训练。这种方法实现了真正的零样本迁移——无需任何机器人演示数据,就能让机器人在开放环境中自主导航,为通用机器人的发展开辟了新路径。
想让机器人听懂”去厨房拿杯水”这样的指令并自主导航?传统方法需要大量机器人专属数据训练,成本高昂且难以扩展。ImagiNav提出了一种革命性的模块化方案:首先通过视觉语言模型将复杂指令分解为文本子目标;然后利用微调后的生成视频模型”脑补”出通往子目标的未来视频轨迹;最后通过逆动力学模型从想象视频中提取可执行轨迹。更巧妙的是,团队开发了自动化数据流水线,能够利用海量未标注的野外导航视频进行训练。这种方法实现了真正的零样本迁移——无需任何机器人演示数据,就能让机器人在开放环境中自主导航,为通用机器人的发展开辟了新路径。
全天候多场景终身视觉语言导航!AlldayWalker让AI智能体学会“举一反三”
基本信息
-
作者:Xudong Wang, Gan Li 等 -
单位:中科院沈阳自动化所、中北大学、中国科学院大学、西安交通大学 -
论文标题:All-day Multi-scenes Lifelong Vision-and-Language Navigation with Tucker Adaptation -
论文链接:https://arxiv.org/abs/2603.14276v1 -
代码链接:https://ganvin-li.github.io/AlldayWalker/
简要介绍
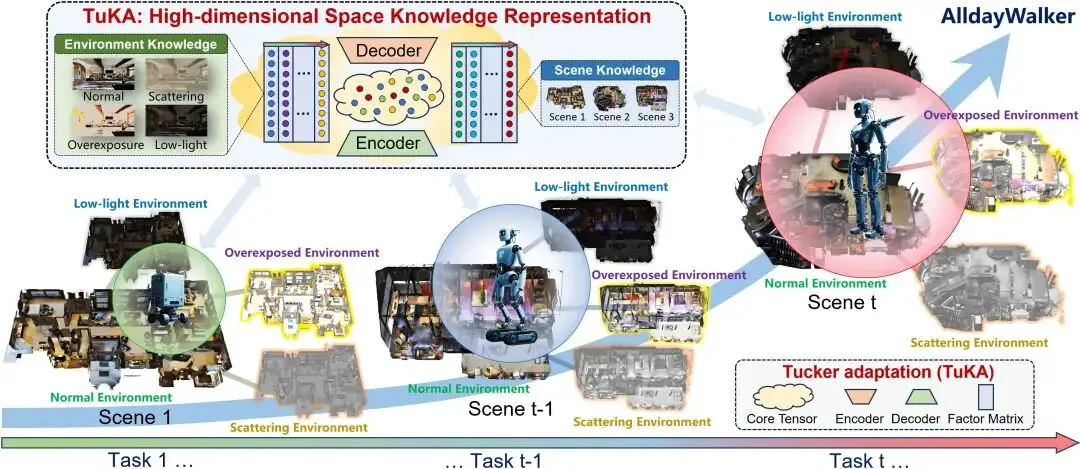 在视觉语言导航(VLN)任务中,智能体常面临一个关键挑战:当针对特定场景进行优化时,往往会遗忘在其他场景中学到的知识,限制了其长期灵活部署的能力。这项研究首次提出了”全天候多场景终身VLN”(AML-VLN)这一新问题,旨在让智能体能够持续学习并适应多样化的导航环境。为解决传统参数高效适配器(如LoRA)在捕获跨场景多层次导航知识方面的不足,研究团队创新性地提出Tucker Adaptation(TuKA)方法。该方法将导航知识表示为高阶张量,并利用Tucker分解将其解耦为共享子空间和场景特定专家。基于TuKA开发的AlldayWalker智能体,在持续学习多个导航场景方面表现出色,实验证明其性能显著优于现有最先进基线,为实现真正的全天候多场景自主导航提供了有力解决方案。
在视觉语言导航(VLN)任务中,智能体常面临一个关键挑战:当针对特定场景进行优化时,往往会遗忘在其他场景中学到的知识,限制了其长期灵活部署的能力。这项研究首次提出了”全天候多场景终身VLN”(AML-VLN)这一新问题,旨在让智能体能够持续学习并适应多样化的导航环境。为解决传统参数高效适配器(如LoRA)在捕获跨场景多层次导航知识方面的不足,研究团队创新性地提出Tucker Adaptation(TuKA)方法。该方法将导航知识表示为高阶张量,并利用Tucker分解将其解耦为共享子空间和场景特定专家。基于TuKA开发的AlldayWalker智能体,在持续学习多个导航场景方面表现出色,实验证明其性能显著优于现有最先进基线,为实现真正的全天候多场景自主导航提供了有力解决方案。
当AI有了「听觉」:Navig-AI-tion用空间音频实现精准步行导航
基本信息
-
作者:Mathias N. Lystbæk, Haley Adams 等 -
单位:谷歌 -
论文标题:Navig-AI-tion: Navigation by Contextual AI and Spatial Audio -
论文链接:https://arxiv.org/abs/2603.13200v1
简要介绍
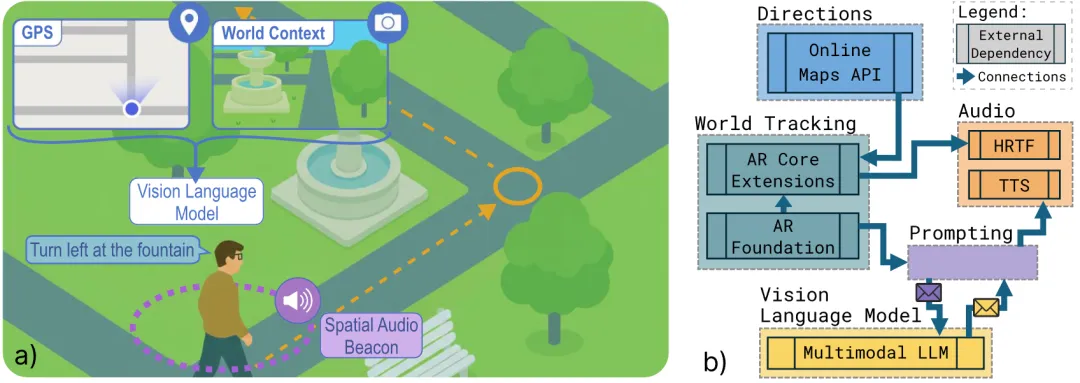 你是否曾因语音导航的模糊指示而走错方向?传统音频导航仅依赖「向左转」等简单指令,缺乏环境参照,容易让人迷失。这项研究提出了一种创新解决方案:将视觉语言模型与空间音频提示相结合。系统能实时识别环境中的地标作为导航锚点,并在用户朝向错误时,通过空间音频精准提示转向方向。实验显示,该方案比纯语音导航和谷歌地图的偏差率显著降低。用户反馈称,空间音频的定向提示大大提升了导航体验。这项研究为未来纯音频导航系统融入实时环境感知与方向纠正功能提供了重要思路。
你是否曾因语音导航的模糊指示而走错方向?传统音频导航仅依赖「向左转」等简单指令,缺乏环境参照,容易让人迷失。这项研究提出了一种创新解决方案:将视觉语言模型与空间音频提示相结合。系统能实时识别环境中的地标作为导航锚点,并在用户朝向错误时,通过空间音频精准提示转向方向。实验显示,该方案比纯语音导航和谷歌地图的偏差率显著降低。用户反馈称,空间音频的定向提示大大提升了导航体验。这项研究为未来纯音频导航系统融入实时环境感知与方向纠正功能提供了重要思路。
无人机、四足机器人与特种导航应用
无人机导航最新进展:AerialVLA实现端到端智能控制
基本信息
-
作者:Peng Xu, Zhengnan Deng 等 -
单位:电子科技大学深圳高等研究院、霍夫斯特拉大学计算机科学系 -
论文标题:AerialVLA: A Vision-Language-Action Model for UAV Navigation via Minimalist End-to-End Control -
论文链接:https://arxiv.org/abs/2603.14363v1 -
代码链接:https://github.com/XuPeng23/AerialVLA
简要介绍
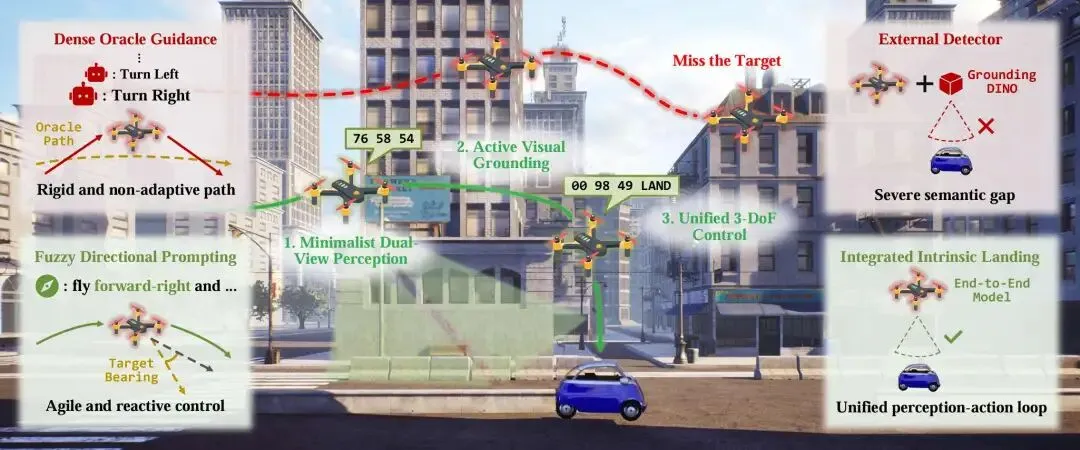 无人机在复杂三维环境中的视觉语言导航一直面临重大挑战。传统方法依赖密集的人工引导或额外物体检测器,导致语义鸿沟和自主性受限。研究团队提出AerialVLA这一创新框架,采用极简的端到端设计,直接将原始视觉观察和模糊语言指令映射为连续控制信号。该模型通过双视图感知策略减少视觉冗余,同时保留关键导航信息;采用基于机载传感器的模糊方向提示机制,彻底摆脱对人工引导的依赖;还构建了统一控制空间,集成3自由度运动指令和自主降落信号。在TravelUAV基准测试中,AerialVLA在已知环境中达到最优性能,在未知场景中的成功率更是领先基线方法近三倍,证明了简约自主范式相比复杂模块系统具有更强的鲁棒性。
无人机在复杂三维环境中的视觉语言导航一直面临重大挑战。传统方法依赖密集的人工引导或额外物体检测器,导致语义鸿沟和自主性受限。研究团队提出AerialVLA这一创新框架,采用极简的端到端设计,直接将原始视觉观察和模糊语言指令映射为连续控制信号。该模型通过双视图感知策略减少视觉冗余,同时保留关键导航信息;采用基于机载传感器的模糊方向提示机制,彻底摆脱对人工引导的依赖;还构建了统一控制空间,集成3自由度运动指令和自主降落信号。在TravelUAV基准测试中,AerialVLA在已知环境中达到最优性能,在未知场景中的成功率更是领先基线方法近三倍,证明了简约自主范式相比复杂模块系统具有更强的鲁棒性。
无人机群秒变“寻宝猎人”!GoalSwarm实现开放词汇目标导航
基本信息
-
作者:MoniJesu Wonders James, Amir Atef Habel 等 -
单位:俄罗斯斯科尔科沃科学技术研究院 -
论文标题:GoalSwarm: Multi-UAV Semantic Coordination for Open-Vocabulary Object Navigation -
论文链接:https://arxiv.org/abs/2603.12908v2
简要介绍
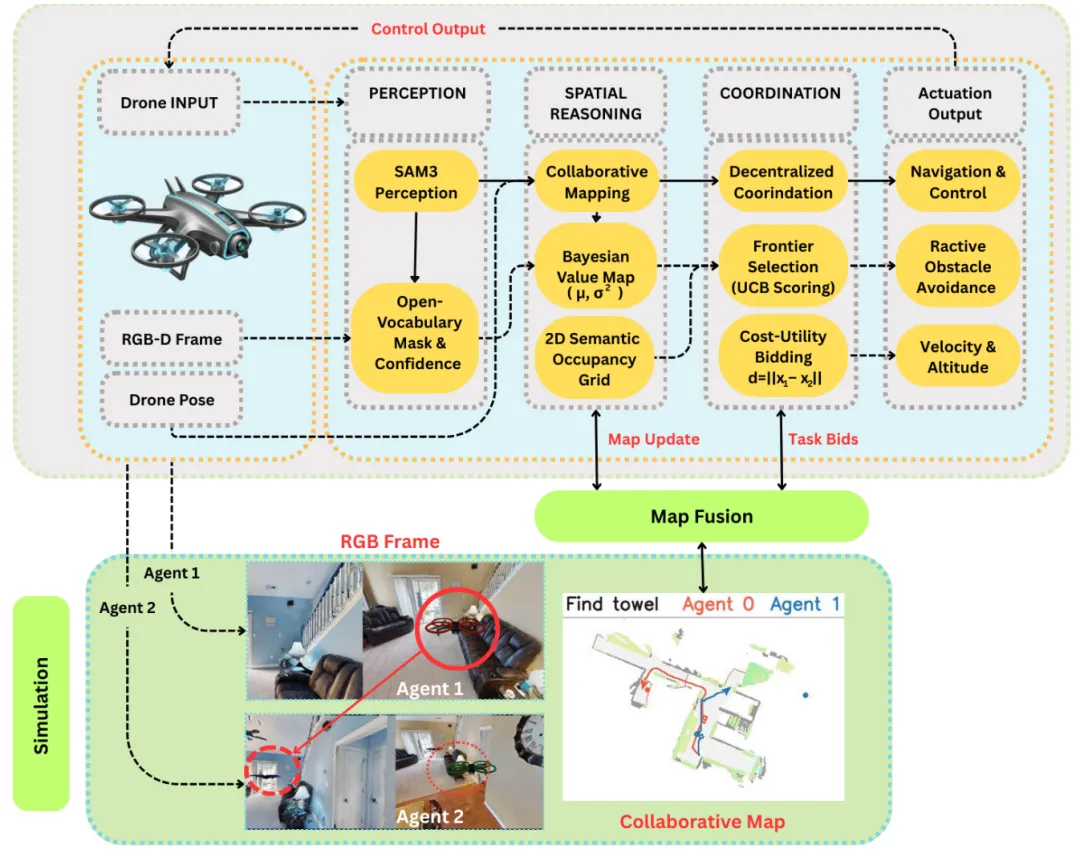 在无人机协同作业领域,如何让多架无人机高效协作寻找未知环境中的目标物体一直是个技术难题。传统方法往往受限于计算资源不足和协调策略复杂。最新提出的GoalSwarm框架给出了创新解决方案:通过部署零样本基础模型SAM3,无人机无需专门训练就能识别各种新物体;采用轻量级2D语义占据地图替代复杂3D建模,大幅降低计算负担;创新的贝叶斯价值地图融合多视角检测置信度,配合基于上置信界探索的边界评分机制,让无人机群能够智能决策。更值得一提的是其完全分布式的协调策略,通过语义边界提取、成本效用竞标和空间分离惩罚,有效避免了重复探索,让无人机群像训练有素的“寻宝猎人”一样协同工作。这一突破为未来无人机在搜救、巡检等实际应用场景中的自主导航能力提供了重要技术支撑。
在无人机协同作业领域,如何让多架无人机高效协作寻找未知环境中的目标物体一直是个技术难题。传统方法往往受限于计算资源不足和协调策略复杂。最新提出的GoalSwarm框架给出了创新解决方案:通过部署零样本基础模型SAM3,无人机无需专门训练就能识别各种新物体;采用轻量级2D语义占据地图替代复杂3D建模,大幅降低计算负担;创新的贝叶斯价值地图融合多视角检测置信度,配合基于上置信界探索的边界评分机制,让无人机群能够智能决策。更值得一提的是其完全分布式的协调策略,通过语义边界提取、成本效用竞标和空间分离惩罚,有效避免了重复探索,让无人机群像训练有素的“寻宝猎人”一样协同工作。这一突破为未来无人机在搜救、巡检等实际应用场景中的自主导航能力提供了重要技术支撑。
让四足机器人「丝滑转向」:SmoothTurn算法实现高速敏捷导航
基本信息
-
作者:Zunzhi You, Haolan Guo 等 -
单位:悉尼大学计算机科学学院 -
论文标题:SmoothTurn: Learning to Turn Smoothly for Agile Navigation with Quadrupedal Robots -
论文链接:https://arxiv.org/abs/2603.12842v1
简要介绍
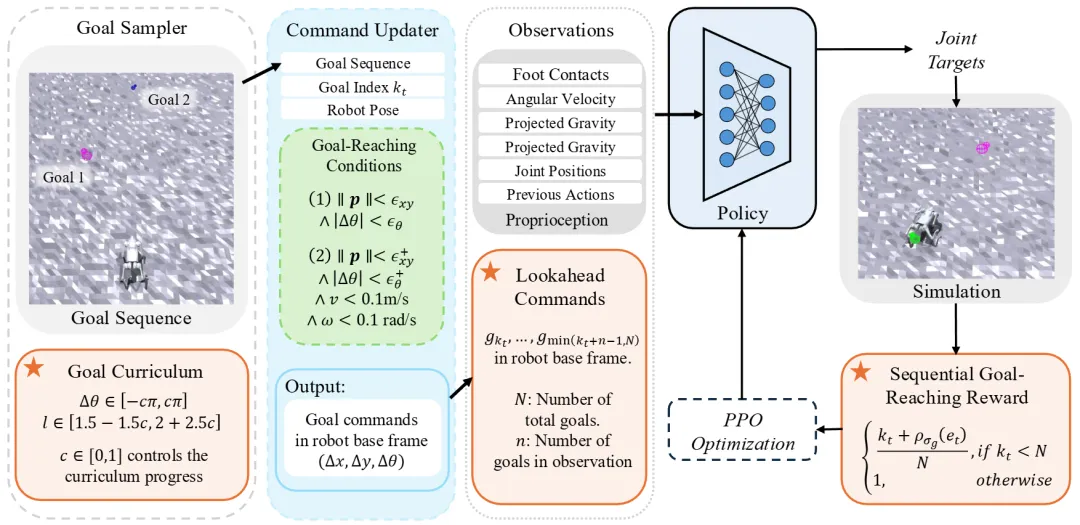 四足机器人在消防救援、工业巡检等实际应用中展现出巨大潜力,但这些场景往往要求机器人具备高速敏捷的导航能力。现有方法通常训练单目标到达策略,导致机器人在连续转向时无法预判后续动作或保持运动惯性,限制了其敏捷性发挥。本研究提出SmoothTurn框架,通过创新性地设计序列化目标到达奖励机制、扩展包含未来目标的观测空间,以及采用自适应目标难度课程,使机器人在高速奔跑中学会「丝滑转向」。实验证明,该策略能自主产生控制动量、提前面向未来目标等智能行为,在仿真和真实机器人上均展现出优异的路径规划能力。这一突破为四足机器人在复杂场景下的高效导航开辟了新途径。
四足机器人在消防救援、工业巡检等实际应用中展现出巨大潜力,但这些场景往往要求机器人具备高速敏捷的导航能力。现有方法通常训练单目标到达策略,导致机器人在连续转向时无法预判后续动作或保持运动惯性,限制了其敏捷性发挥。本研究提出SmoothTurn框架,通过创新性地设计序列化目标到达奖励机制、扩展包含未来目标的观测空间,以及采用自适应目标难度课程,使机器人在高速奔跑中学会「丝滑转向」。实验证明,该策略能自主产生控制动量、提前面向未来目标等智能行为,在仿真和真实机器人上均展现出优异的路径规划能力。这一突破为四足机器人在复杂场景下的高效导航开辟了新途径。
机器人导盲最新成果:协作完成开门、按电梯等精细任务
基本信息
-
作者:Shaojun Cai, Nuwan Janaka 等 -
单位:新加坡国立大学、香港城市大学、萨尔兰大学、中科院心理研究所等 -
论文标题:Navigation beyond Wayfinding: Robots Collaborating with Visually Impaired Users for Environmental Interactions -
论文链接:https://arxiv.org/abs/2603.14216v1
简要介绍
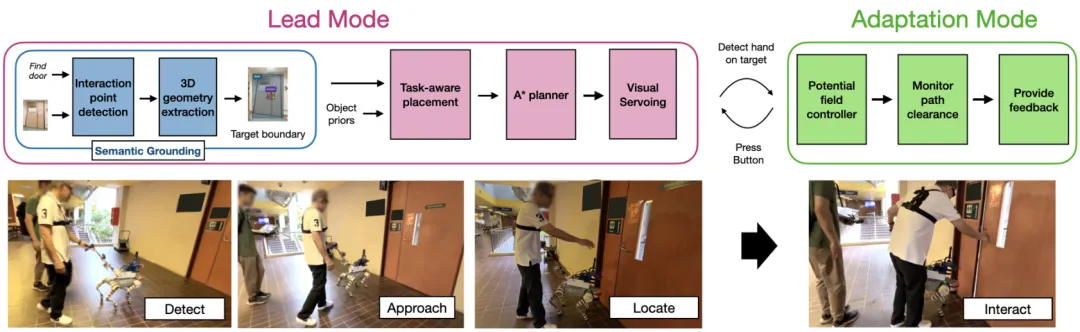 传统机器人导盲系统主要专注于路径规划和避障,却忽略了一个关键需求:视障人士在导航过程中经常需要与环境互动,例如按下电梯按钮、拉开椅子或开门。这类任务不仅需要精确定位目标物体,还要求机器人与用户之间实现动态动作协调。本研究提出了一种创新的协作式人机交互框架,通过两种模式交替运作:”引导模式”由机器人探测并引导用户至目标位置;”适应模式”则在用户操作环境时实时调整机器人运动轨迹。实验结果表明,该系统在安全性、流畅度和效率上均显著优于传统白手杖和非自适应导盲系统,尤其在需要精确定位的交互任务中优势更为突出。这一突破为辅助机器人技术向更通用、更实用的导航支持迈出了重要一步。
传统机器人导盲系统主要专注于路径规划和避障,却忽略了一个关键需求:视障人士在导航过程中经常需要与环境互动,例如按下电梯按钮、拉开椅子或开门。这类任务不仅需要精确定位目标物体,还要求机器人与用户之间实现动态动作协调。本研究提出了一种创新的协作式人机交互框架,通过两种模式交替运作:”引导模式”由机器人探测并引导用户至目标位置;”适应模式”则在用户操作环境时实时调整机器人运动轨迹。实验结果表明,该系统在安全性、流畅度和效率上均显著优于传统白手杖和非自适应导盲系统,尤其在需要精确定位的交互任务中优势更为突出。这一突破为辅助机器人技术向更通用、更实用的导航支持迈出了重要一步。