夜雨聆风
夜雨聆风





GPT-4o文档识别暴跌35%!百度团队重磅开源新基准:涵盖弯曲、阴影五大场景!






以下文章来源于微信公众号:码科智能
作者:码科智能
链接:https://mp.weixin.qq.com/s/GYZrjTGUjRkSxnmb9I2qzA
本文仅用于学术分享,如有侵权,请联系后台作删文处理


文档解析五大容易翻车的场景!
真实世界中文档解析有多难?相较于干净的数字文档,现实中要处理的文档图像可能扭曲、模糊、倾斜、光照不均…
在之前的文章中,我们聊过字节团队开源的 WildDoc 首次用12000张真实拍摄的文档图像证明:大模型在真实世界面前不堪一击。
-
GPT-4o 在真实文档场景下性能平均下降35.3%!
-
PP-StructureV3更惨,倾斜场景直接跌到37.98分,跌幅超过55%!
但 WildDoc 只告诉我们模型表现变差了,却没能回答一个更关键的问题:到底为什么失败?是光照问题?弯曲变形?还是拍摄角度?

这就像医生告诉你你病了,却因为查不清病因而无法给予治疗。为了解决上述困境,百度Paddle团队开源了一个更具有挑战性的新基准!涵盖了五个关键的真实世界场景:扫描、弯曲、屏幕拍摄、光照和倾斜。
# 论文Real5-OmniDocBench# Arxivhttps://arxiv.org/pdf/2603.04205# 数据https://huggingface.co/datasets/PaddlePaddle/Real5-OmniDocBench一、数据:文档理解基准测试有哪些?
当前绝大多数文档理解基准,都建立在“干净”的数字文档或扫描件基础上。DocVQA、ChartQA、InfoVQA、OmniDocBench——这些标杆性基准测试中的图像,光照均匀、页面平整、无畸变无遮挡。
其中 OmniDocBench 凭借其定义的九种文档类型和三级评估框架(整页级、模块级和属性级),已成为评估 Qwen3-VL、Gemini 3 Pro 等文档解析能力的核心基准。
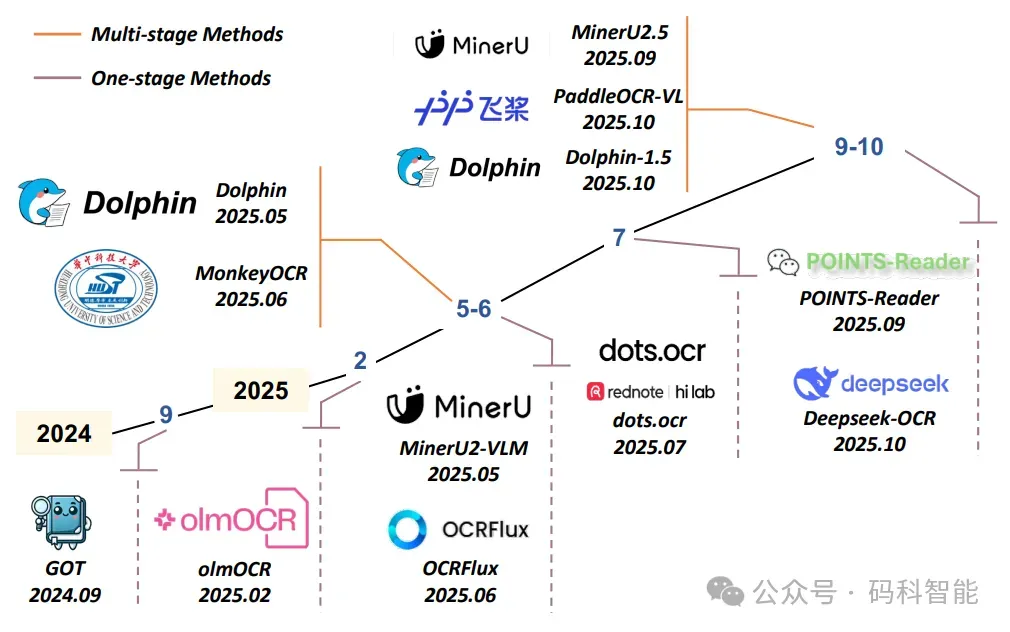
字节跳动联合华中科技大学开源了首个专注于自然场景下文档理解能力评估的基准数据集WildDoc。它收录了超过12,000张手动拍摄的真实文档图像,并通过不同光照、角度、变形等条件下的重复拍摄。
但有一个先天不足:每张图像都是独立拍摄的,没有与原始数字文档的一一对应关系,你无法知道性能下降到底是光照引起的,还是弯曲引起的,还是两者共同作用的结果。

Paddle团队这次开源的 Real5-OmniDocBench 把整个OmniDocBench v1.5测试集(1355张图像)进行了一次全尺度、一对一物理重建,并系统地解耦五个物理因素,即扫描、弯曲、屏幕拍摄、光照和倾斜,为视觉语言模型在真实世界部署中的可靠性提供了严格的诊断性评估标准。
每一张数字文档,都通过专业级打印和异构移动设备采集,生成五个物理场景的变体,总共6775张测试图像,且每张图像都完美继承原始数字文档的全部真值标注(版面、表格、公式、文本、阅读顺序)。
二、反直觉的发现:小模型反而更抗造?
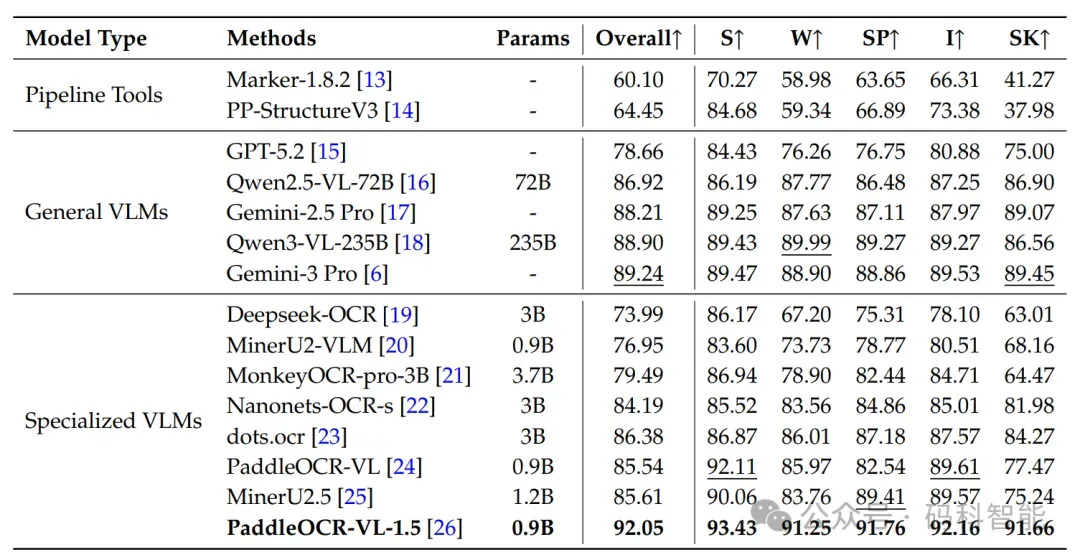
也就是增加参数规模主要提升字符识别准确率,但可能无法从根本上解决3D透视变换引入的几何歧义。那PaddleOCR-VL-1.5的成功,源于针对文档解析任务的专项优化:
-
在多任务训练中融入多样化的光照增强数据
-
学习利用全局上下文线索
-
针对几何变形进行专门的鲁棒性训练

总的来讲,在真实世界中,小而精的专用模型可能比大而全的通用模型更好用。因为其有着更低的部署成本、更高的推理效率、更稳定的实际表现。
江大白,安生股份(无锡)联合创始人。
深耕企业安全管理+AI领域,通过“技术+商业+内容”的融合视角,深度参与AI产业化落地。
全网20W+粉丝AI知识博主,人工智能技术文章超1000W+阅读,《30天入门人工智能》课程,全网2000+名学员。
主导构建的AI知识平台www.jiangdabai.com累计访问已超800万次;
思想阵地(深度洞察):知乎、CSDN @江大白
内容阵地(视频解读):抖音、快手、小红书 @江大白讲AI
实战阵地(产品纪实):抖音、快手、小红书 @安生江大白 | 记录“1年10个AI产品100个项目应用”的极限挑战

真诚分享AI落地过程(AI商机->项目签约->算法开发->产品开发->实施运维)中的各方面经验和踩过的坑。
大家一起加油!