 夜雨聆风
夜雨聆风





Claude Code内部使用心法合集?!来了
本文汇总了 Claude Code 核心成员 Thariq 分享的团队内部使用心得,包含架构设计、性能优化、工具设计、Skills 实战等核心主题。这些经验来自 Anthropic 团队构建生产级 AI Agent 产品的实践。
Claude Code 核心成员 Thariq 在 Twitter 上分享了一系列实战经验,我们将这些内容整合成了完整的使用指南,包含:
-
为什么非编码 Agent 也需要 Bash – 文件系统和 bash 工具的实战价值
-
Agent 应该使用文件系统 – 渐进式披露和上下文构建策略
-
Prompt Caching 就是一切 – 缓存安全的完整实践(包含 Compaction 策略)
-
像 Agent 一样思考 – 工具设计的演进案例和核心原则
-
如何使用 Skills – 9 大类型详解和最佳实践完整指南
-
使用 Claude Code 制作 Playgrounds – 创新交互方式的实现方法
-
Claude 编码的随机笔记 – 来自 Andrej Karpathy 的行业观察
话不多说,开整!
为什么要关注这些 Tips?
Andrej Karpathy 在使用 Claude Code 几周后写道:
“这是我近 20 年编程生涯中基本编码工作流程的最大变化,而且发生在几周内。我从 80% 手动编码 + 20% Agent,转变为 80% Agent 编码 + 20% 编辑润色。”
但他也坦言:模型仍然会犯微妙的概念错误,需要像鹰一样监视它们。 如何让 Agent 真正可用?Anthropic 团队的经验值得学习。
六个核心洞察
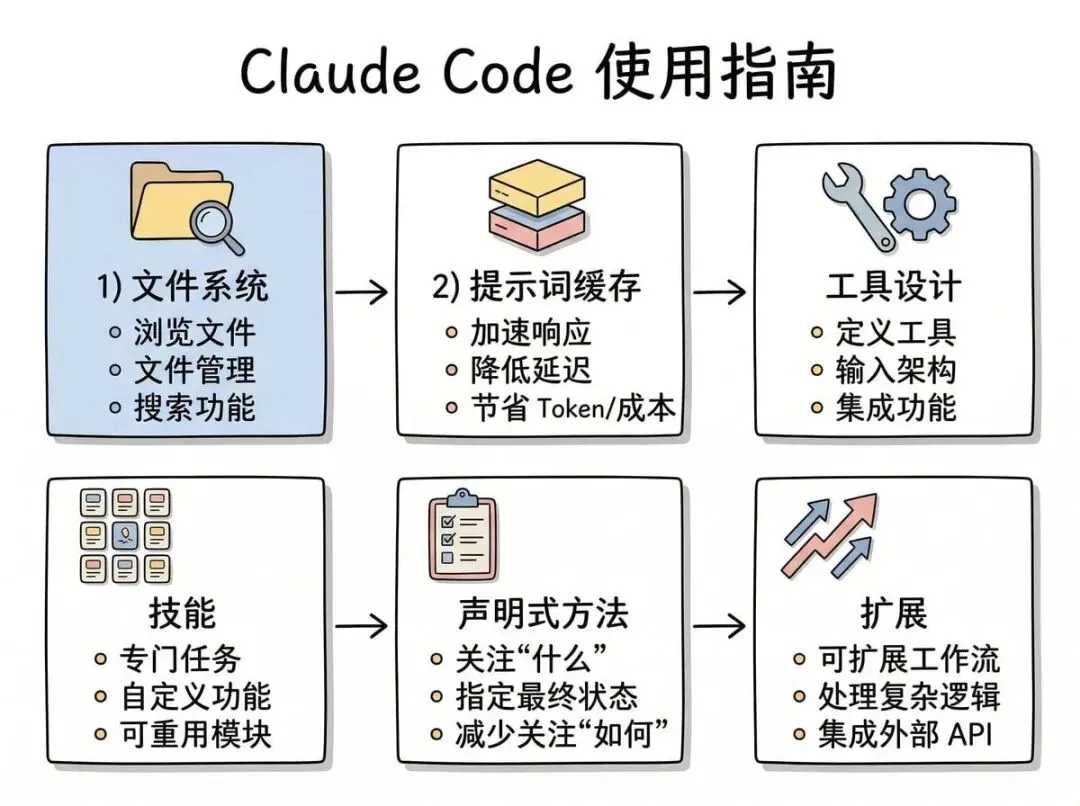
1. 文件系统是 Agent 的记忆
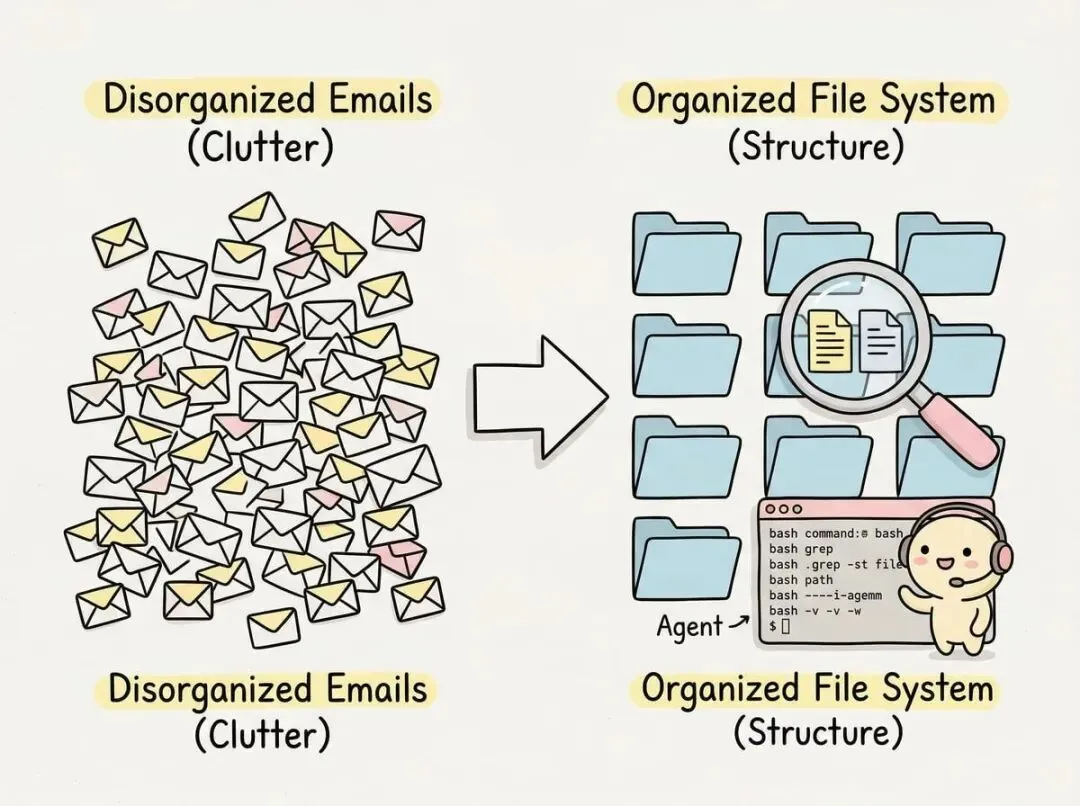
想象你要回答“本周打车花了多少钱”这个问题。
很多人的第一反应是把所有相关邮件都塞进上下文窗口,让模型从 100 封邮件里找答案。这听起来很合理,毕竟上下文窗口越来越大了,为什么不直接用?但其实这跟人类的工作方式完全相反。
你不会把所有文件都摊在桌上然后盯着看,你会先整理归档,需要的时候再去翻。
更接近现实的做法是用 bash 把这些邮件写入文件,然后让 Agent 用 grep 搜索关键词。第一次搜“Uber”,发现还有“Lyft”,再搜一次,把金额提取出来,验证一下总数对不对。
这个过程可能要来回好几次,但每次都是在明确的范围内操作,而不是在海量信息里碰运气。
关键在于,编程从来不是靠“记住所有东西”完成的,而是靠“知道去哪里找”。Claude Code 团队发现,即使是完全不写代码的 Agent,给它 bash 和文件系统,它的可靠性会提升一个量级。因为它可以反复验证、多次处理,而不是一次性赌对。
2. Prompt Caching 决定成败
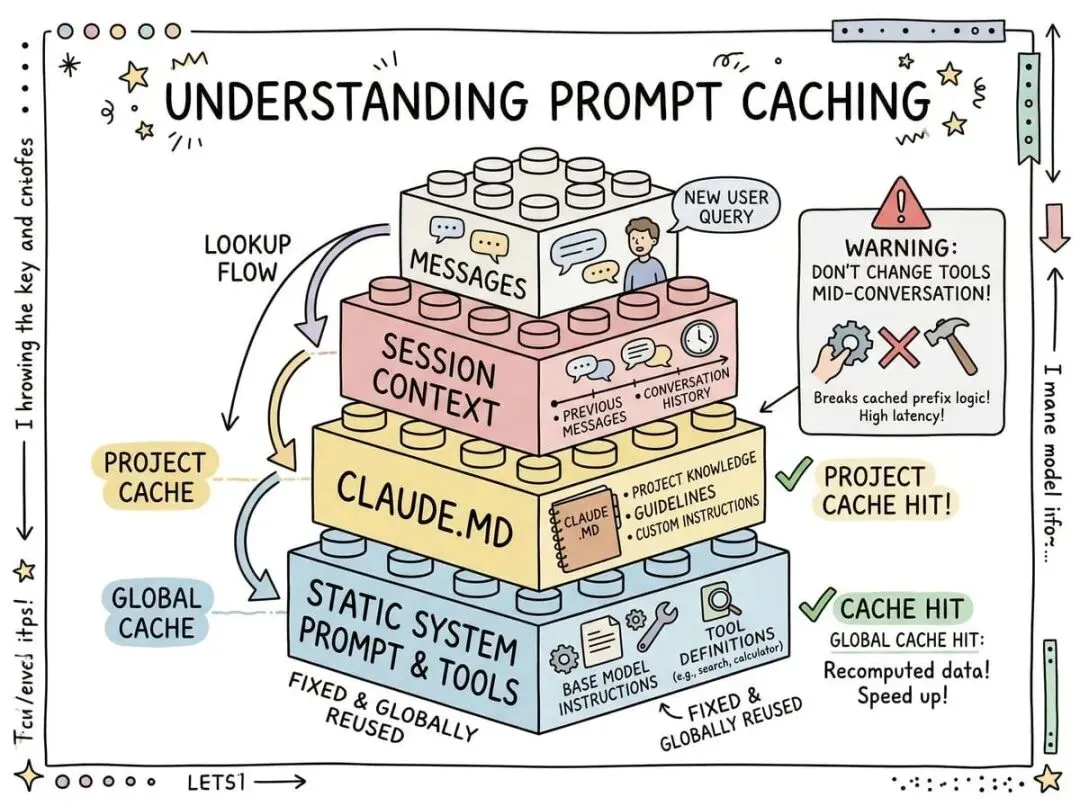
Claude Code 团队有个习惯,缓存命中率掉几个百分点就会拉警报,严重的时候直接声明 SEV(严重事件)。
这听起来有点夸张,但当你意识到几个百分点意味着成本翻倍、延迟加倍的时候,就明白为什么了。
大部分人对 prompt caching 的理解是“能省点钱”。但更接近现实的是,整个产品架构都得围绕它设计。因为 caching 的工作方式是前缀匹配,从请求开头一直缓存到 cache_control 断点。
这意味着如果你在中间改了一个字,后面全废。
团队最初犯过很多错。比如在系统提示词里放了详细时间戳,每次请求时间都不一样,缓存全部失效。比如工具定义的顺序是随机的,每次排列不同,又是缓存失效。后来他们学会了一个顺序:静态系统提示词和工具放最前面(全局缓存),然后是项目配置(项目内缓存),再是会话上下文(会话内缓存),最后才是对话消息。这样大部分会话都能共享前面的缓存。
但这还不够。当信息过时了怎么办?
比如时间变了,文件改了。直觉上应该更新系统提示词,但这会破坏缓存。团队的做法是在下一轮消息里加个 <system-reminder> 标签,告诉模型“现在是周三了”。缓存前缀保持不变,只是多了一条消息。
Plan Mode 的设计更能说明问题。正常思路是用户进入 plan mode 时,把工具集换成只读的。但这会破坏缓存。所以他们把 EnterPlanMode 和 ExitPlanMode 做成工具本身,工具定义从不改变,只是模型收到一条消息说“你现在在 plan mode 了”。
这样不仅保持了缓存,还让模型可以自己决定什么时候进入 plan mode,因为它可以主动调用这个工具。
Tool Search 也是同样的逻辑。Claude Code 可能加载了几十个 MCP 工具,全部放进去太贵,但中途移除又破坏缓存。
解决方案是发送轻量级存根,只有工具名和 defer_loading: true,模型需要的时候再通过 ToolSearch 加载完整定义。缓存前缀里始终是那些存根,稳定不变。
这整套设计的核心其实只有一句话:别在对话中途改任何东西。改工具会破坏缓存,切模型也会破坏缓存(因为缓存是按模型存的)。如果真要切模型,用子 Agent,让 Opus 准备一个“交接消息”给 Haiku。
因为这样至少 Opus 那边的缓存还在。
3. 工具设计要匹配模型能力
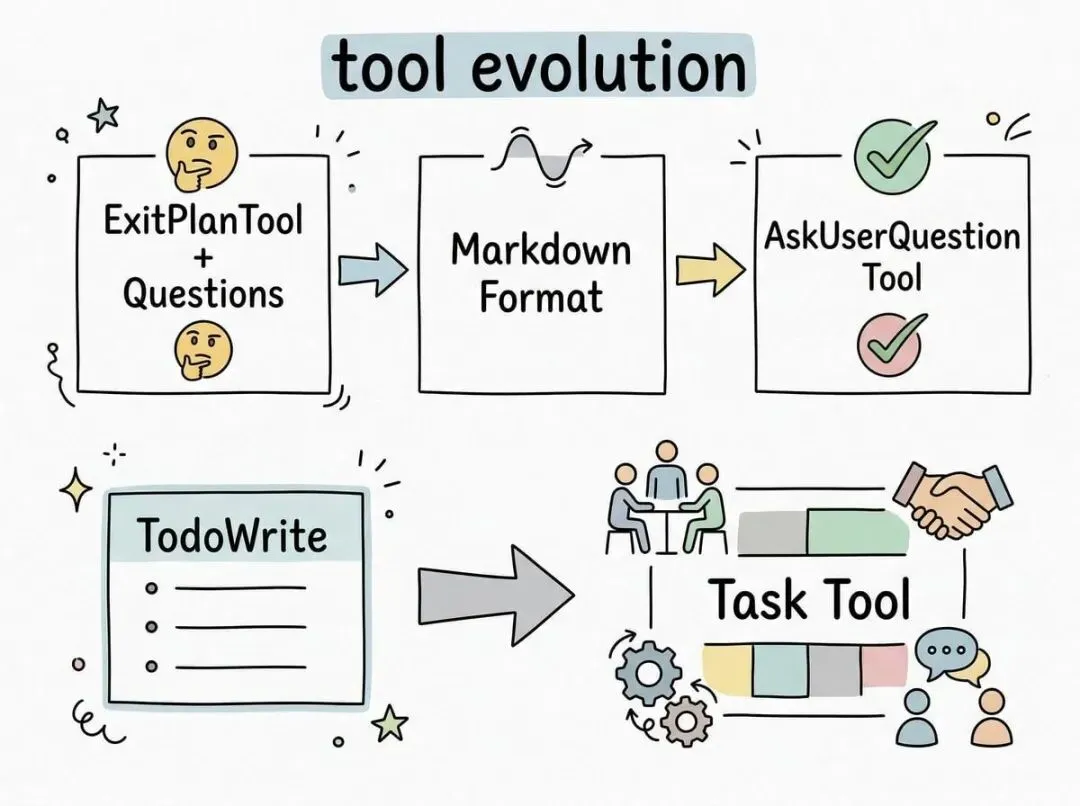
团队想让 Claude 更好地提问,最开始的想法很直接:在 ExitPlanTool 里加个参数,让它输出计划的同时也输出问题列表。
结果 Claude 完全搞混了,它不知道如果用户的回答跟计划冲突该怎么办,是不是要调用两次工具?
第二次尝试更聪明一些。他们修改了输出指令,让 Claude 用特殊的 markdown 格式提问,比如“你想要 【选项 A】 还是 【选项 B】?”
然后解析这个格式生成界面。但 Claude 经常不按套路出牌,有时候多写几句话,有时候忘了加括号,有时候干脆换个格式。不是说它做不到,而是不稳定。
最后他们做了个独立的 AskUserQuestion 工具。Claude 可以随时调用,特别是在 plan mode 的时候。工具触发后弹出模态框,阻塞 Agent 循环直到用户回答。这个设计的关键不是技术上多高明,而是 Claude 真的喜欢用它。你看它的输出就能感觉到,它知道什么时候该问,问题也组织得很清楚。
这让人想起另一个演进。早期 Claude Code 给模型配了 TodoWrite 工具,帮它记住要做什么。团队甚至每 5 轮就插入一次系统提醒:“别忘了你的 Todo List”。但到了 Opus 4.5,情况反过来了。模型不仅不需要提醒,反而觉得这个列表是个束缚。它想改列表但又觉得不应该改,因为系统一直在提醒它“按列表做事”。更麻烦的是,子 Agent 之间怎么共享一个 Todo List?
所以他们把 TodoWrite 换成了 Task Tool。Tasks 可以有依赖关系,可以跨 Agent 同步,模型可以随时修改和删除。这不是简单的功能升级,而是从“帮模型记事”变成了“帮模型协作”。
其实工具设计没有固定答案。纸张、计算器、计算机,你选哪个取决于你的能力。模型也一样。曾经需要的工具,现在可能在限制它。你得不断观察它的输出,看它哪里卡住了,哪里用得顺手,然后调整。
4. Skills 的九大类型
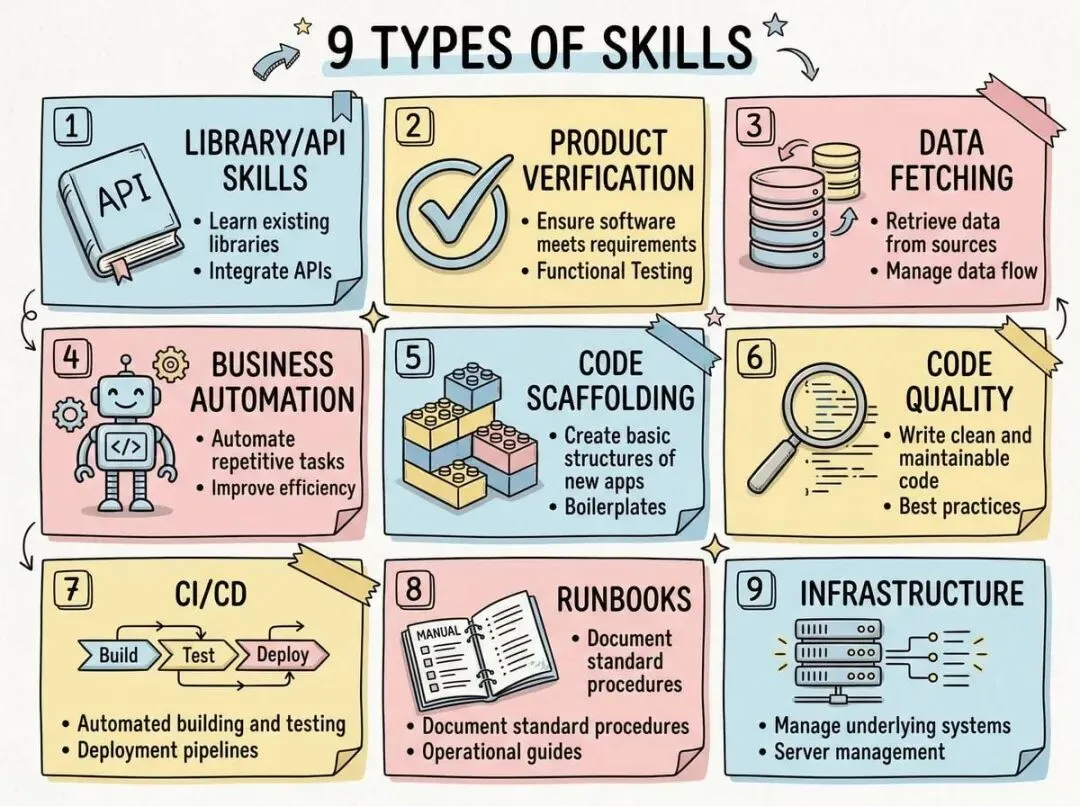
Anthropic 内部现在有几百个 Skills 在用,团队花了些时间把它们分类,发现大部分都能归到九个类别里。
1️⃣ Library & API Reference,专门解释怎么用某个库或 CLI。不是那种官方文档式的完整说明,而是“Claude 经常在这里犯错”的那种。比如你们内部的计费库有哪些坑,哪些边缘情况会出问题。
2️⃣ Product Verification,教 Claude 怎么测试。这类 Skill 往往配合 playwright 或 tmux 这些工具,让 Claude 能真的跑一遍注册流程,在每一步验证状态对不对。
3️⃣是 Data Fetching & Analysis,连接你的数据栈。包含怎么用凭据拉数据,哪个仪表板 ID 对应哪个指标。
4️⃣ Business Process Automation,把重复工作自动化,比如每天发站立会议总结,自动从工单系统、GitHub、Slack 里抓信息。
5️⃣Code Scaffolding,生成框架代码,特别是那种有自然语言要求、纯代码搞不定的场景。
6️⃣ Code Quality & Review,强制执行代码规范。可以是确定性脚本,也可以是让 Claude 生成一个“对抗性审查”的子 Agent,专门挑毛病。
7️⃣ CI/CD & Deployment,帮你推代码、跑测试、监控部署。
8️⃣ Runbooks,接收一个症状(比如 Slack 里的报警),走完整个调查流程,输出结构化报告。
9️⃣Infrastructure Operations,日常运维操作,比如清理孤立资源,但加了护栏防止误删。
但分类只是开始。团队发现最重要的其实是 Gotchas 部分,就是 Claude 用这个 Skill 时经常踩的坑。这部分的信号密度最高,因为它是从实际失败中提炼出来的。
另一个关键是渐进式披露。很多人以为 Skill 就是个 markdown 文件,其实它是个文件夹,可以放脚本、数据、模板。你告诉 Claude 这个文件夹里有什么,它会在需要的时候自己去读。
还有个容易忽略的点:Description 字段不是给人看的摘要,是给模型看的触发条件。
Claude Code 启动时会扫描所有 Skill 的描述,决定“这个请求需要哪个 Skill”。所以你写的应该是“什么时候用这个 Skill”,而不是“这个 Skill 是干什么的”。
5. 从命令式到声明式
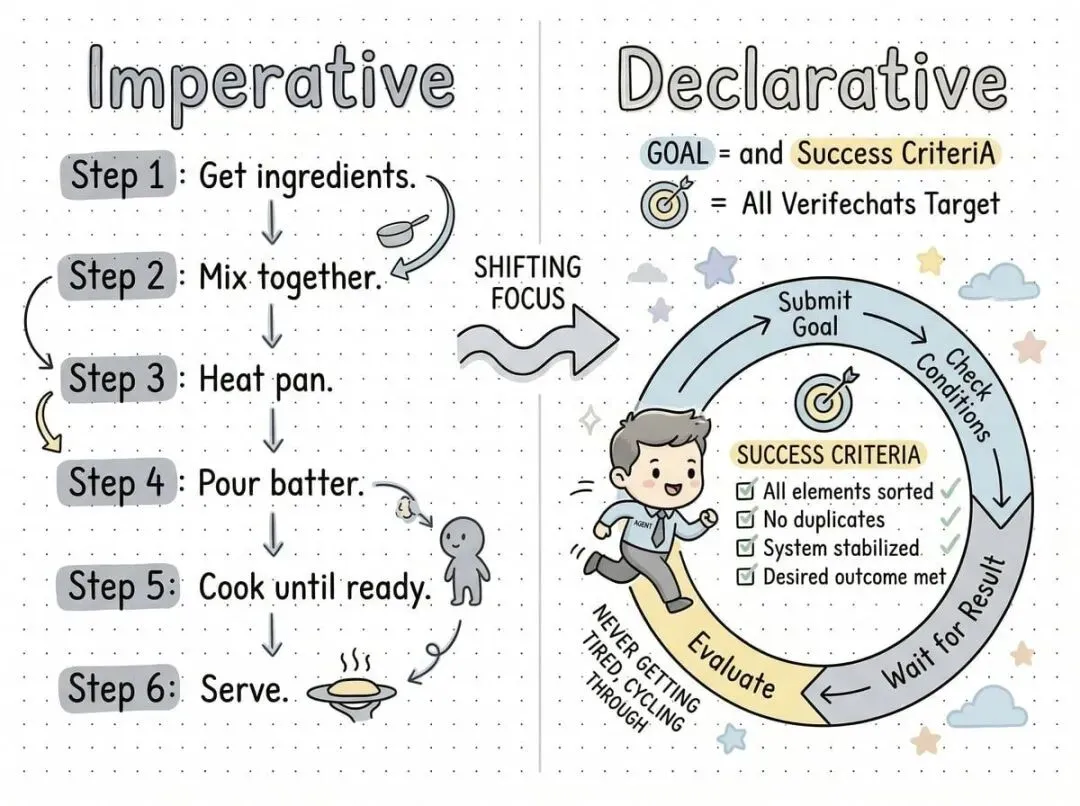
Karpathy 的关键洞察:LLM 特别擅长循环直到满足特定目标。
不要告诉 Agent 做什么,给它成功标准并看着它运行:
让它先编写测试然后通过它们;将它放在与浏览器 MCP 的循环中;先写朴素算法,再要求优化并保持正确性!
韧性创造价值: Agent 永远不会累,永远不会气馁。看着它挣扎 30 分钟然后成功,是真正“感受 AGI”的时刻。
6. 扩展大于加速
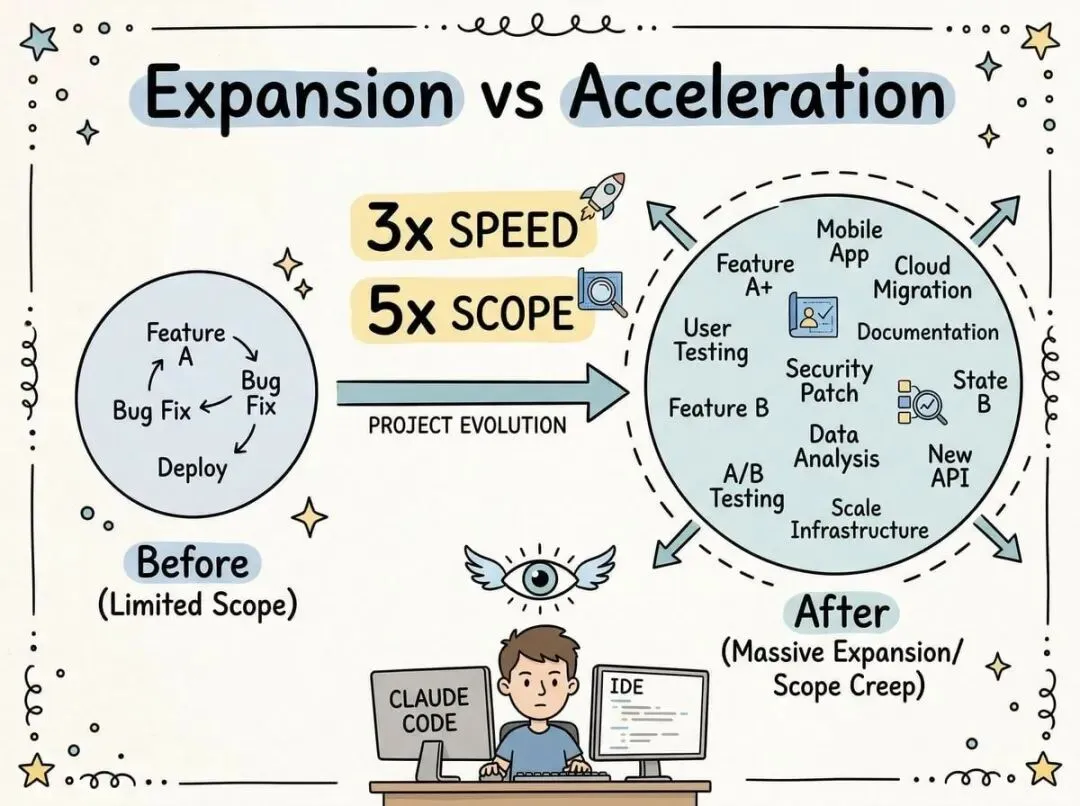
Karpathy 说他不知道怎么衡量 LLM 带来的“加速”。这听起来很奇怪,明明感觉快了很多,为什么测不出来?
因为真正发生的不是“同样的事情做得更快”,而是“做了完全不同的事情”。以前有个小工具想写但不值得花时间,现在 10 分钟就能让 Agent 搞定,那就写了。
以前有段代码看不懂也懒得研究,现在让 Agent 解释一下,顺便改改,那就改了。
所以表面上看是“编码速度提升了 3 倍”,实际上是“做的事情变成了原来的 5 倍”。
这不是加速,更像是扩展。
你的能力边界变大了,以前够不着的东西现在够得着了。
但这不意味着可以扔掉 IDE。Karpathy 的工作流是左边开几个 Claude Code 会话,右边开着 IDE 看代码、手动改。因为模型还是会犯错,不是语法错误那种明显的错,而是概念上的微妙问题。它会替你做假设然后一路跑下去,不会停下来问“这样对吗”。
它会把 1000 行代码写得很复杂,你得提醒它“能不能简单点”,然后它立刻缩减到 100 行。
所以 IDE 的作用变了。
不再是写代码的地方,而是监督 Agent 的地方。你得像鹰一样盯着,看它有没有走偏。这也是为什么扩展比加速更准确,因为你的角色从“执行者”变成了“指挥者”,能管的范围自然就大了。
创新实践:Playgrounds
Anthropic 发布了 playground 插件,帮助 Claude 生成独立的 HTML 文件,让你可以可视化问题、交互,并生成输出提示粘贴回 Claude Code。
适用场景:
可视化代码库架构
调整组件设计
头脑风暴布局
调整游戏平衡
Thariq 的建议是 想一个与模型交互的独特方式,然后要求它表达出来。
Claude Code 核心成员 Thariq 在 Twitter 上分享了一系列实战经验,我们将这些内容整合成了完整的使用指南,包含:
-
为什么非编码 Agent 也需要 Bash – 文件系统和 bash 工具的实战价值
-
Agent 应该使用文件系统 – 渐进式披露和上下文构建策略
-
Prompt Caching 就是一切 – 缓存安全的完整实践(包含 Compaction 策略)
-
像 Agent 一样思考 – 工具设计的演进案例和核心原则
-
如何使用 Skills – 9 大类型详解和最佳实践完整指南
-
使用 Claude Code 制作 Playgrounds – 创新交互方式的实现方法
-
Claude 编码的随机笔记 – 来自 Andrej Karpathy 的行业观察
以上内容涵盖了从架构设计、性能优化、工具设计到 Skills 实战的完整体系,包含大量实际案例和可操作的技巧。
所有内容已经整理完毕,欢迎添加助理微信获取完整版使用指南。反正详细的原文内容,悦己已经让小助理准备好啦,需要 pdf 的朋友可以找小助理

评论区看暗号,获取原文 link