 夜雨聆风
夜雨聆风





Java 集合框架源码深度拆解:架构选型黄金法则 & 线程安全避坑全攻略
Java集合框架是JDK中使用频率最高的核心类库,也是90%以上Java线上业务Bug的发源地。无论是日常业务开发、架构设计还是面试进阶,对集合框架的源码级理解,都是区分普通开发者和资深工程师的核心分水岭。本文基于JDK 17,从底层源码、架构选型、线程安全三大维度,拆解集合框架的核心逻辑,给出选型法则和避坑指南。
一、Java集合框架整体架构
Java集合框架分为两大根体系:Collection单元素集合体系和Map键值对集合体系,所有集合类均基于这两个根接口扩展实现,整体架构如下:
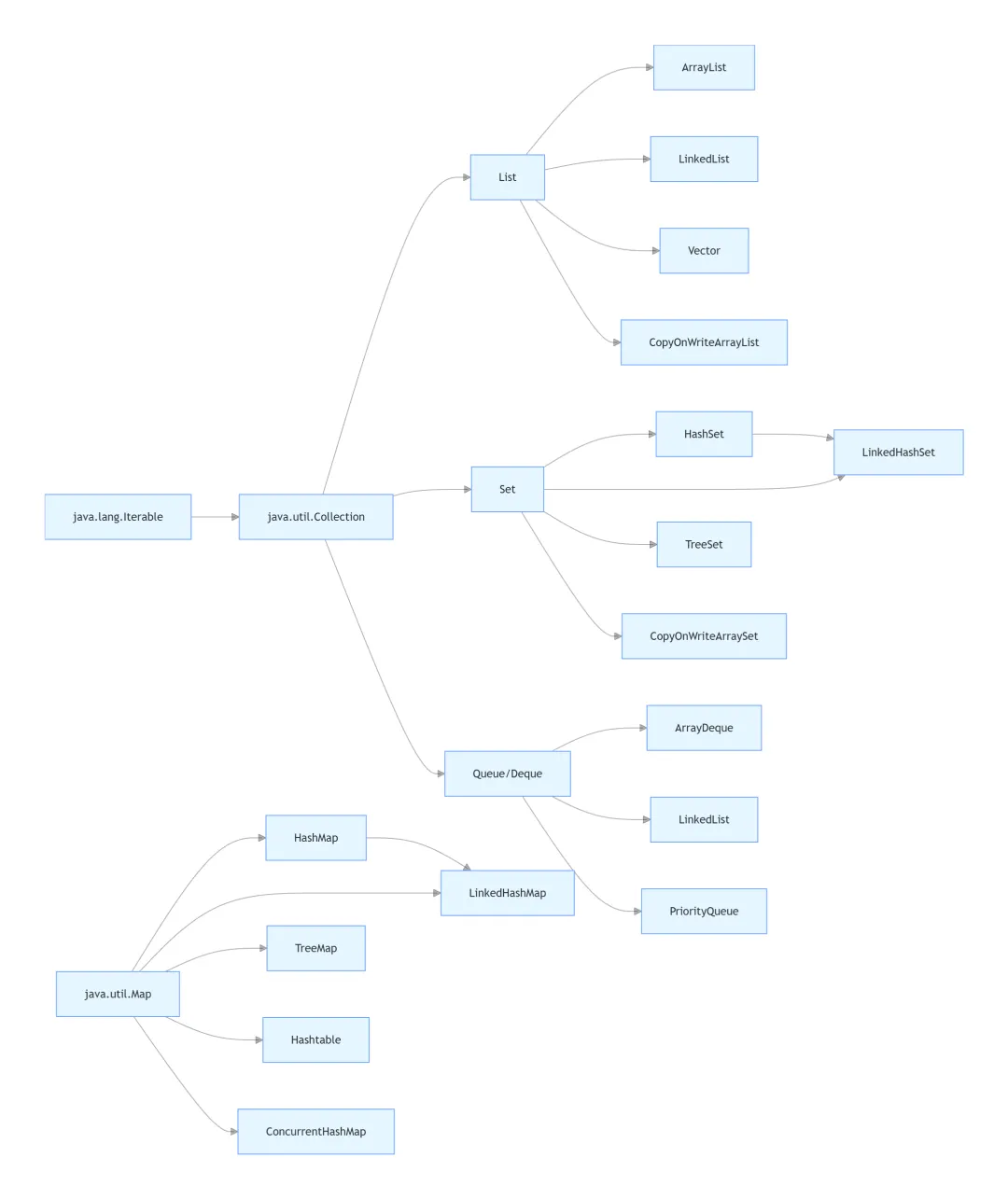
各分支核心职责:
-
Collection:单元素集合的根接口,定义了所有单元素集合的通用方法,如add、remove、contains、size等 -
List:有序、可重复、支持下标随机访问的集合 -
Set:无序、不可重复的集合 -
Queue/Deque:队列/双端队列,用于实现FIFO/LIFO数据结构 -
Map:键值对集合的根接口,key不可重复,每个key对应唯一value
二、核心集合源码深度剖析
2.1 List体系源码核心拆解
List的核心特性:元素插入顺序与取出顺序一致、可重复、支持通过下标随机访问,核心实现类包括ArrayList、LinkedList、Vector、CopyOnWriteArrayList。
2.1.1 ArrayList 源码核心逻辑
ArrayList底层基于动态扩容的Object数组实现,是日常开发中使用频率最高的集合类,JDK 17中核心源码特性如下:
核心成员变量
// 默认初始容量privatestaticfinalint DEFAULT_CAPACITY = 10;// 无参构造使用的空数组privatestaticfinal Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};// 存储元素的底层数组,transient修饰避免序列化整个空数组transient Object[] elementData;// 集合中实际元素的数量privateint size;懒加载初始化机制
多数开发者误以为无参构造的ArrayList初始容量为10,实际上JDK 17中,无参构造创建的ArrayList,底层数组初始化为空数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA,仅在第一次调用add方法时,才会触发扩容并将数组初始化为默认容量10,通过懒加载节省内存开销。
扩容核心机制
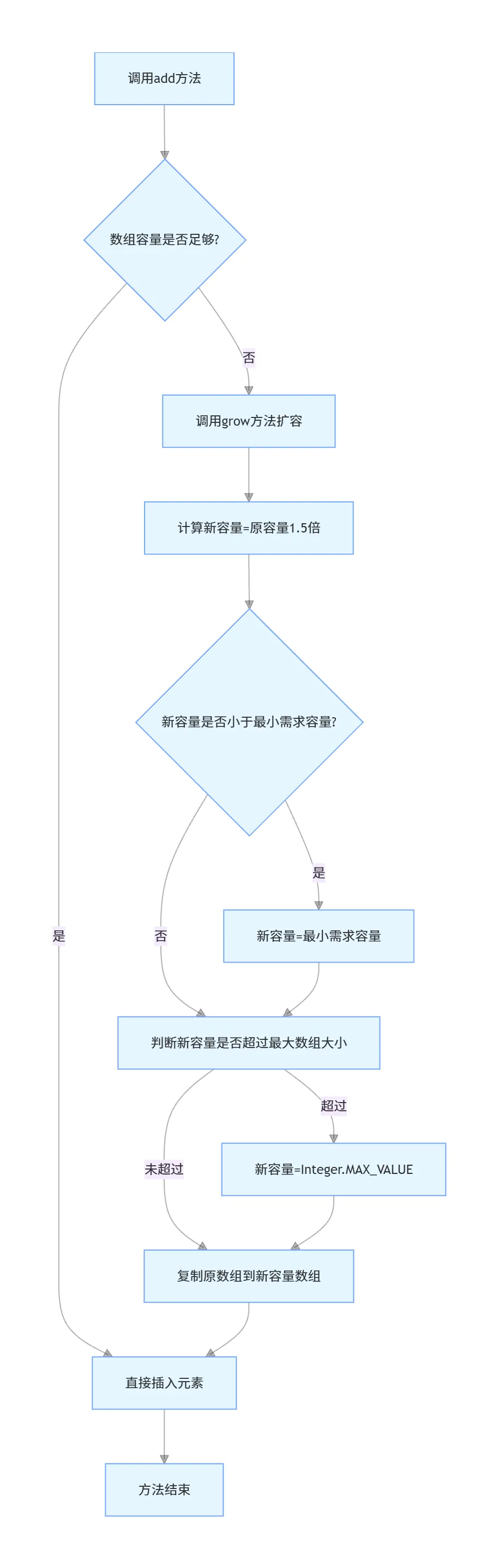
当添加元素时,若底层数组剩余容量不足以容纳新元素,会触发grow()方法执行扩容,核心逻辑如下:
-
默认扩容为原容量的1.5倍( oldCapacity + (oldCapacity >> 1),位运算效率远高于除法) -
若1.5倍扩容后的容量仍小于本次添加所需的最小容量,则直接使用所需最小容量 -
若新容量超过最大数组阈值 Integer.MAX_VALUE - 8,则直接扩容至Integer.MAX_VALUE -
通过 Arrays.copyOf()复制原数组到新容量数组,完成扩容
扩容流程如下:
核心特性总结
-
随机访问时间复杂度O(1),通过下标直接定位元素,效率极高 -
尾部插入/删除时间复杂度O(1),中间插入/删除需要移动数组元素,时间复杂度O(n) -
线程不安全,多线程并发修改会触发 ConcurrentModificationException,甚至出现数据丢失、数组越界 -
适合读多写少、随机访问频繁的单线程场景
2.1.2 LinkedList 源码核心逻辑
LinkedList底层基于双向链表实现,每个元素被封装为Node节点,包含prev前驱指针、item元素值、next后继指针。
核心成员变量
// 链表头节点transient Node<E> first;// 链表尾节点transient Node<E> last;// 链表实际元素数量transientint size;核心特性纠正
多数开发者存在误区:认为LinkedList所有插入/删除操作都是O(1)。实际上:
-
仅首尾节点的插入/删除操作时间复杂度为O(1),无需移动元素 -
中间位置的插入/删除,需要先遍历链表找到对应节点,时间复杂度为O(n) -
随机访问需要从链表头/尾开始遍历,时间复杂度O(n),效率远低于ArrayList
核心特性总结
-
实现了 List和Deque双接口,既可以作为有序列表,也可以作为双端队列、栈使用 -
无扩容机制,每个节点单独存储,通过指针关联,内存不连续 -
线程不安全,多线程并发修改会触发并发修改异常 -
适合频繁首尾插入/删除、无需随机访问的场景,实际开发中绝大多数场景可被 ArrayDeque替代
2.1.3 线程安全List实现对比
Vector是JDK 1.0推出的古老线程安全List,所有方法都添加了synchronized全表锁,并发度极低、性能极差,官方已明确不推荐使用。CopyOnWriteArrayList是JUC包提供的线程安全List,核心思想是写时复制:
-
读操作无锁,直接访问底层数组,性能极高 -
写操作(add/remove/set)时,先复制一份全新的数组,在新数组上执行修改,完成后将底层数组引用指向新数组 -
整个写操作全程加 ReentrantLock独占锁,避免并发复制导致的数据混乱
核心特性:
-
线程安全,读无锁写加锁,适合读多写少的高并发场景 -
遍历操作不会触发并发修改异常,遍历的是快照数组,不会随原集合修改而变化 -
写操作内存开销大,频繁写会导致频繁数组复制,触发Full GC,绝对不适合写多读少的场景
2.2 Map体系源码核心拆解
Map是键值对(key-value)集合的根接口,核心特性:key不可重复,每个key对应唯一value,核心实现类包括HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap。
2.2.1 HashMap 源码核心逻辑
HashMap是日常开发中使用最广泛的KV集合,JDK 17中底层采用数组+链表+红黑树的混合结构实现,核心源码逻辑如下:
核心成员变量
// 默认初始容量,必须是2的幂staticfinalint DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16// 最大容量staticfinalint MAXIMUM_CAPACITY = 1 << 30;// 默认负载因子staticfinalfloat DEFAULT_LOAD_FACTOR = 0.75f;// 链表转红黑树的阈值staticfinalint TREEIFY_THRESHOLD = 8;// 红黑树转回链表的阈值staticfinalint UNTREEIFY_THRESHOLD = 6;// 链表转红黑树的最小数组容量staticfinalint MIN_TREEIFY_CAPACITY = 64;// 哈希桶数组,长度必须是2的幂transient Node<K,V>[] table;// 实际键值对数量transientint size;// 扩容阈值,threshold = 容量 * 负载因子int threshold;// 负载因子finalfloat loadFactor;哈希函数设计
HashMap的哈希函数是核心优化点,JDK 17中哈希值计算逻辑为:
staticfinalinthash(Object key){int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}核心设计逻辑:
-
key为null时哈希值固定为0,因此HashMap允许key为null,且仅能有一个 -
将key的hashCode高16位与低16位异或,让高位也参与哈希计算,减少哈希碰撞 -
数组下标计算采用 (n - 1) & hash,等价于hash % n,但位运算效率远高于取模,这也是数组长度必须是2的幂的核心原因
put方法核心流程
put方法是HashMap的核心,完整流程如下:
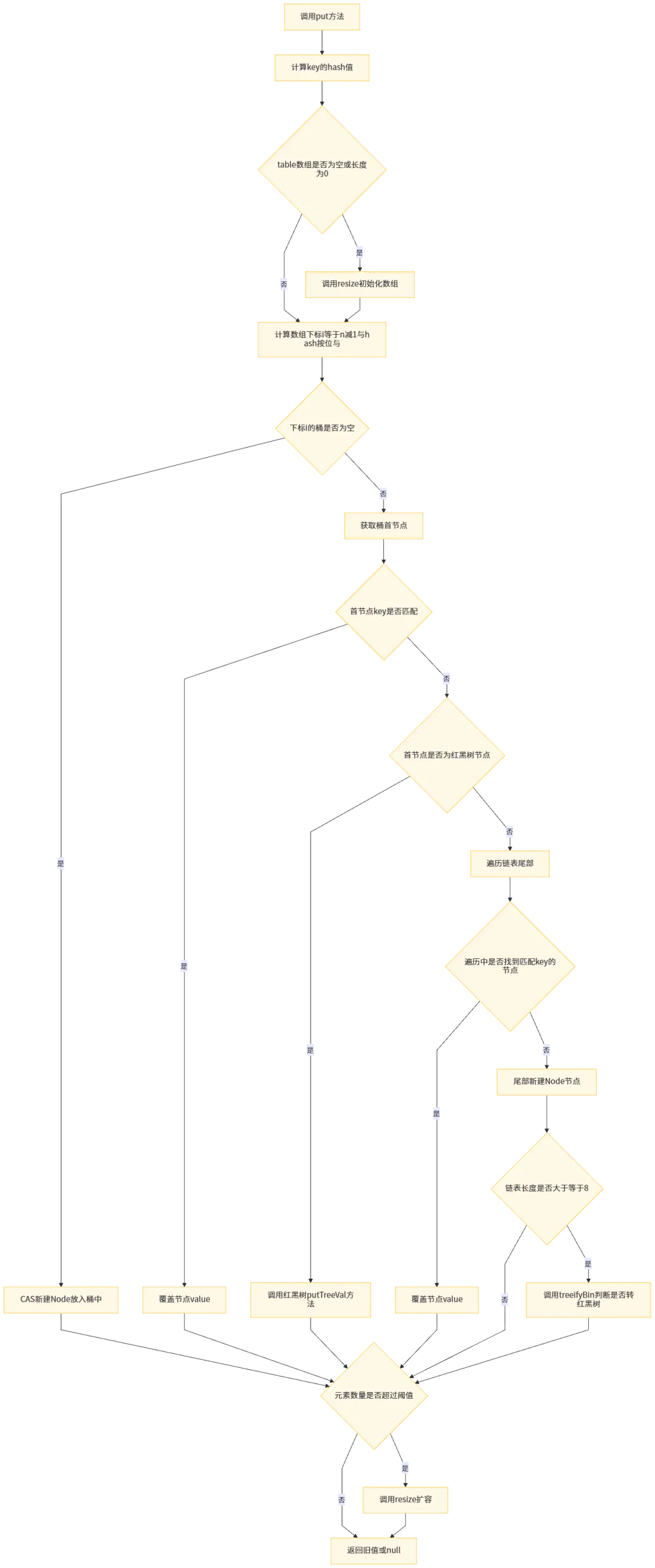 注:n减1与hash按位与 → (n-1) & hash
注:n减1与hash按位与 → (n-1) & hash
链表转红黑树机制
当同时满足以下两个条件时,链表会转换为红黑树:
-
链表节点数量大于等于 TREEIFY_THRESHOLD(8) -
哈希桶数组长度大于等于 MIN_TREEIFY_CAPACITY(64)
若仅链表长度达到8,但数组长度小于64,会优先触发扩容而非转红黑树。当红黑树节点数量小于等于UNTREEIFY_THRESHOLD(6)时,会自动转回链表。 核心设计目的:解决哈希碰撞导致的链表过长问题,将查询时间复杂度从O(n)优化到O(logn),提升极端场景下的性能。
扩容核心机制
当HashMap的元素数量size超过扩容阈值threshold时,会触发resize()扩容,核心逻辑:
-
新容量为原容量的2倍,保持2的幂特性,确保下标计算的正确性 -
扩容后,原数组中的节点只会被分配到原下标位置,或原下标+原容量的位置,无需重新计算hash值 -
JDK 17采用尾插法迁移节点,彻底解决了JDK 7及之前版本头插法导致的并发死循环问题
核心特性总结
-
无同步开销,单线程环境下put/get性能极高 -
无序,不保证元素插入顺序与取出顺序一致 -
线程不安全,多线程并发修改会导致数据覆盖、丢失、size计算错误,JDK 8+不会出现死循环 -
允许key和value为null,key为null仅能有一个,value为null可以有多个 -
适合单线程环境下无有序要求的KV存储场景
2.2.2 有序Map实现对比
LinkedHashMap
LinkedHashMap继承自HashMap,底层在HashMap结构基础上,额外维护了一条双向链表,记录元素的插入顺序或访问顺序,核心特性:
-
保证元素插入顺序与取出顺序一致,可通过构造参数 accessOrder设置为访问顺序(LRU缓存的核心实现) -
所有方法复用HashMap逻辑,仅重写了节点创建、访问、移除的回调方法维护双向链表 -
线程不安全,性能略低于HashMap,因需要额外维护双向链表 -
适合需要保证插入顺序的KV存储场景,或实现LRU缓存
TreeMap
TreeMap实现了SortedMap接口,底层基于红黑树实现,核心特性:
-
支持key的自然排序(实现Comparable接口)或定制排序(传入Comparator) -
支持范围查询,如 headMap、tailMap、subMap,这是HashMap无法实现的 -
put/get/remove操作时间复杂度均为O(logn),性能低于HashMap的O(1) -
线程不安全,key不能为null(需要排序,null无法比较),value可以为null -
适合需要按key排序、范围查询的KV存储场景
2.2.3 ConcurrentHashMap 线程安全Map核心逻辑
ConcurrentHashMap是JUC包提供的高并发线程安全Map,是高并发场景下KV存储的首选。JDK 17中,ConcurrentHashMap放弃了JDK 7的分段锁设计,采用CAS + synchronized实现,锁粒度为哈希桶的首节点,并发度大幅提升。
核心特性纠正与说明
-
不允许key和value为null:并发场景下, get(key)返回null时,无法区分是key不存在还是value为null。单线程HashMap可通过containsKey区分,但并发场景下,get和containsKey之间可能有其他线程修改,存在竞态条件,因此禁止null值。 -
锁粒度优化:仅当哈希桶发生哈希冲突、桶内有节点时,才会对首节点加synchronized锁;无哈希冲突时采用CAS无锁操作,并发度远高于Hashtable和Collections.synchronizedMap的全表锁。 -
原子操作支持:提供了 putIfAbsent、compute、merge、replace等原子方法,解决复合操作的竞态问题。 -
安全的遍历:遍历过程中不会触发并发修改异常,遍历的是快照数据,支持弱一致性。
核心特性总结
-
线程安全,高并发场景下性能远超Hashtable和同步包装Map -
不允许key和value为null -
提供丰富的原子操作方法,解决复合操作的线程安全问题 -
适合高并发场景下的KV存储,是并发编程的首选Map实现
2.3 Set与Queue体系核心说明
2.3.1 Set体系核心逻辑
Set是无序、不可重复的集合,底层几乎全部基于对应的Map实现:
-
HashSet:底层基于HashMap实现,所有元素存储为HashMap的key,value为固定的Object常量,不可重复、无序、线程不安全 -
LinkedHashSet:底层基于LinkedHashMap实现,保证插入顺序、不可重复、线程不安全 -
TreeSet:底层基于TreeMap实现,支持元素排序、不可重复、线程不安全 -
CopyOnWriteArraySet:底层基于CopyOnWriteArrayList实现,线程安全,适合读多写少的并发场景
Set的不可重复特性完全依赖Map的key不可重复特性,因此存入Set的元素必须正确重写hashCode()和equals()方法,否则会导致去重失效。
2.3.2 Queue体系核心逻辑
Queue/Deque是用于实现队列、栈的集合接口,核心实现类:
-
ArrayDeque:底层基于循环数组实现的双端队列,无容量限制、自动扩容,首尾插入/删除O(1),随机访问O(n),线程不安全,性能远超LinkedList,是实现队列、栈的首选 -
PriorityQueue:底层基于堆实现的优先级队列,元素按自然排序或定制排序排列,入队/出队时间复杂度O(logn),线程不安全 -
BlockingQueue:JUC包提供的阻塞队列,线程安全,用于生产者-消费者模型,核心实现类包括ArrayBlockingQueue、LinkedBlockingQueue、DelayQueue等
三、集合架构选型黄金法则
基于源码特性和业务场景,总结出可直接落地的选型黄金法则,覆盖99%的业务场景,如下表所示:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
选型核心原则
-
单线程环境优先选非线程安全集合:线程安全集合的同步开销会导致性能下降30%以上,单线程环境无需使用线程安全集合 -
读多写少优先选数组实现的集合:数组内存连续,CPU缓存友好,随机访问性能远超链表实现 -
高并发场景优先选JUC并发集合:绝对不要使用Vector、Hashtable等古老同步集合,也不要优先使用Collections.synchronizedXXX同步包装类,JUC并发集合的性能和安全性都远超前者 -
禁止为了“未来可能的扩展”而过度选型:比如明明是单线程场景,却使用ConcurrentHashMap,导致不必要的性能开销
四、线程安全避坑全攻略
集合相关的线上Bug,90%都来自于线程安全问题,本节拆解最常见的核心坑点,给出错误示例、问题根源和正确解决方案,所有示例均可直接运行验证。
坑1:ArrayList并发修改触发ConcurrentModificationException
问题根源
ArrayList的迭代器遍历过程中,若通过集合自身的add/remove方法修改集合,会触发modCount(修改次数)和迭代器的expectedModCount不一致,抛出并发修改异常。多线程并发遍历和修改时,即使单线程内操作正确,也会触发该异常。
错误示例
package com.jam.demo.collection.pitfall;import lombok.extern.slf4j.Slf4j;import java.util.ArrayList;import java.util.List;/** * ArrayList并发修改异常错误示例 * @author ken */@Slf4jpublicclassArrayListModificationPitfall{publicstaticvoidmain(String[] args){ List<String> list = new ArrayList<>();for (int i = 0; i < 10; i++) { list.add("元素" + i); }// 错误用法:迭代器遍历中用集合的remove方法try {for (String s : list) {if ("元素5".equals(s)) { list.remove(s); } } } catch (Exception e) { log.error("单线程迭代器修改触发并发修改异常", e); } }}正确解决方案
-
单线程场景:使用迭代器的 remove()方法,而非集合自身的方法 -
多线程场景:使用线程安全的CopyOnWriteArrayList,或遍历过程中加锁
package com.jam.demo.collection.pitfall;import lombok.extern.slf4j.Slf4j;import java.util.ArrayList;import java.util.Iterator;import java.util.List;import java.util.concurrent.CopyOnWriteArrayList;/** * ArrayList并发修改异常正确示例 * @author ken */@Slf4jpublicclassArrayListModificationCorrect{publicstaticvoidmain(String[] args){// 单线程正确用法:使用迭代器的remove方法 List<String> list = new ArrayList<>();for (int i = 0; i < 10; i++) { list.add("元素" + i); } Iterator<String> iterator = list.iterator();while (iterator.hasNext()) { String s = iterator.next();if ("元素5".equals(s)) { iterator.remove(); } } log.info("单线程正确操作后集合:{}", list);// 多线程正确用法:使用CopyOnWriteArrayList CopyOnWriteArrayList<String> concurrentList = new CopyOnWriteArrayList<>();for (int i = 0; i < 10; i++) { concurrentList.add("元素" + i); }// 遍历过程中修改不会触发异常for (String s : concurrentList) {if ("元素3".equals(s)) { concurrentList.remove(s); } } log.info("多线程正确操作后集合:{}", concurrentList); }}坑2:Collections.synchronizedXXX同步包装类的迭代器非线程安全
问题根源
Collections.synchronizedList/synchronizedMap的所有方法都加了synchronized锁,但迭代器方法没有加锁,并发遍历和修改时,依然会触发并发修改异常,这是最常见的误区之一。
错误示例
package com.jam.demo.collection.pitfall;import lombok.extern.slf4j.Slf4j;import java.util.ArrayList;import java.util.Collections;import java.util.List;import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;/** * 同步包装类迭代器线程不安全错误示例 * @author ken */@Slf4jpublicclassSynchronizedListPitfall{privatestaticfinal List<String> SYNC_LIST = Collections.synchronizedList(new ArrayList<>());privatestaticfinal CountDownLatch LATCH = new CountDownLatch(2);publicstaticvoidmain(String[] args)throws InterruptedException {for (int i = 0; i < 1000; i++) { SYNC_LIST.add("元素" + i); }// 线程1:遍历集合 ExecutorService executor = Executors.newFixedThreadPool(2); executor.execute(() -> {try {for (String s : SYNC_LIST) {// 模拟业务处理 Thread.sleep(1); } } catch (Exception e) { log.error("同步包装类遍历触发并发修改异常", e); } finally { LATCH.countDown(); } });// 线程2:修改集合 executor.execute(() -> {try {for (int i = 0; i < 100; i++) { SYNC_LIST.add("新增元素" + i); Thread.sleep(10); } } finally { LATCH.countDown(); } }); LATCH.await(); executor.shutdown(); }}正确解决方案
遍历同步包装类时,必须手动对集合对象加锁,确保遍历和修改的原子性:
// 正确用法:遍历过程中对集合对象加锁synchronized (SYNC_LIST) {for (String s : SYNC_LIST) {// 业务处理 }}坑3:ConcurrentHashMap复合操作非原子性
问题根源
ConcurrentHashMap的单个put/get方法是原子的,但if (!map.containsKey(key)) { map.put(key, value); }这类复合操作,不是原子的,containsKey和put之间可能有其他线程插入,导致数据覆盖、计数错误等问题。
错误示例与正确示例
package com.jam.demo.collection.pitfall;import lombok.extern.slf4j.Slf4j;import java.util.concurrent.ConcurrentHashMap;import java.util.concurrent.CountDownLatch;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;/** * ConcurrentHashMap复合操作非原子性示例 * @author ken */@Slf4jpublicclassConcurrentHashMapAtomicPitfall{privatestaticfinal ConcurrentHashMap<String, Integer> COUNT_MAP = new ConcurrentHashMap<>();privatestaticfinalint THREAD_COUNT = 100;publicstaticvoidmain(String[] args)throws InterruptedException { ExecutorService executor = Executors.newFixedThreadPool(THREAD_COUNT); CountDownLatch wrongLatch = new CountDownLatch(THREAD_COUNT);// 错误用法:get+put复合操作非原子for (int i = 0; i < THREAD_COUNT; i++) { executor.execute(() -> {try { wrongAddCount("test"); } finally { wrongLatch.countDown(); } }); } wrongLatch.await(); log.info("错误用法最终计数:{},预期值:{}", COUNT_MAP.get("test"), THREAD_COUNT);// 重置 COUNT_MAP.clear(); CountDownLatch correctLatch = new CountDownLatch(THREAD_COUNT);// 正确用法:使用原子方法mergefor (int i = 0; i < THREAD_COUNT; i++) { executor.execute(() -> {try { correctAddCount("test"); } finally { correctLatch.countDown(); } }); } correctLatch.await(); log.info("正确用法最终计数:{},预期值:{}", COUNT_MAP.get("test"), THREAD_COUNT); executor.shutdown(); }/** * 错误的计数累加方法,get+put非原子操作 * @param key 计数key */privatestaticvoidwrongAddCount(String key){ Integer count = COUNT_MAP.get(key); count = count == null ? 1 : count + 1; COUNT_MAP.put(key, count); }/** * 正确的计数累加方法,使用原子方法merge * @param key 计数key */privatestaticvoidcorrectAddCount(String key){ COUNT_MAP.merge(key, 1, Integer::sum); }}运行结果:错误用法的最终计数几乎永远小于100,而正确用法的计数永远等于100,完美验证了复合操作的非原子性。
坑4:CopyOnWriteArrayList写多读少场景的性能灾难
问题根源
CopyOnWriteArrayList的写操作会复制整个底层数组,数组越大,写操作的内存开销和CPU开销越大,频繁写会导致大量数组对象创建,触发频繁Full GC,甚至OOM。
避坑指南
CopyOnWriteArrayList仅适合读多写少、遍历远多于修改的场景,比如配置列表、白名单、黑名单等几乎不修改的场景,绝对不能用于写操作频繁的业务场景,比如日志收集、数据统计等。
坑5:Arrays.asList生成的List不支持add/remove操作
问题根源
Arrays.asList返回的是Arrays的内部类ArrayList,而非java.util.ArrayList,该内部类没有重写add/remove方法,直接继承了AbstractList的默认实现,会抛出UnsupportedOperationException。
错误示例与正确示例
package com.jam.demo.collection.pitfall;import lombok.extern.slf4j.Slf4j;import java.util.ArrayList;import java.util.Arrays;import java.util.List;/** * Arrays.asList坑示例 * @author ken */@Slf4jpublicclassArraysAsListPitfall{publicstaticvoidmain(String[] args){// 错误用法 List<String> wrongList = Arrays.asList("a", "b", "c");try { wrongList.add("d"); } catch (UnsupportedOperationException e) { log.error("Arrays.asList生成的List不支持add操作", e); }// 正确用法:转换为java.util.ArrayList List<String> correctList = new ArrayList<>(Arrays.asList("a", "b", "c")); correctList.add("d"); log.info("正确转换后的List操作成功,当前元素:{}", correctList); }}坑6:集合判空误用size() == 0,导致空指针异常
问题根源
很多开发者用if (list.size() == 0)判断集合为空,若list为null,会直接抛出NullPointerException。阿里巴巴Java开发手册明确规定:集合判空必须使用集合工具类。
正确用法
使用Spring框架的CollectionUtils工具类进行集合判空:
// 正确判空:同时判断null和空集合if (CollectionUtils.isEmpty(list)) { log.info("集合为空");}// 正确判断非空if (CollectionUtils.isNotEmpty(list)) { log.info("集合非空");}同理,字符串判空使用StringUtils.hasText(),对象判空使用ObjectUtils.isEmpty()。
五、最佳实践总结
-
优先使用JDK最新稳定版的集合实现:JDK 17对集合框架做了大量优化,性能和安全性都远超旧版本 -
初始化集合时指定初始容量:ArrayList、HashMap等集合初始化时,若已知元素数量,指定初始容量,避免频繁扩容带来的性能开销,这是阿里巴巴开发手册明确要求的最佳实践 -
正确重写hashCode()和equals()方法:存入HashMap、HashSet的元素,必须正确重写这两个方法,否则会导致去重失效、哈希碰撞严重等问题 -
高并发场景优先使用JUC并发集合:绝对不要使用Vector、Hashtable等古老同步集合,也不要滥用同步包装类,ConcurrentHashMap、CopyOnWriteArrayList等JUC集合是高并发场景的首选 -
遍历集合时不要进行元素的增删操作:若必须修改,使用迭代器的remove方法,或使用线程安全的并发集合 -
禁止使用null作为ConcurrentHashMap的key或value:会导致空指针异常和歧义问题 -
合理使用工具类:优先使用Spring工具类、Guava集合工具类,避免重复造轮子,同时减少空指针等低级错误
附录:项目依赖pom.xml
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.jam</groupId><artifactId>collection-demo</artifactId><version>1.0.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spring.version>6.1.5</spring.version><lombok.version>1.18.34</lombok.version><guava.version>33.1.0-jre</guava.version><fastjson2.version>2.0.52</fastjson2.version><mybatis-plus.version>3.5.6</mybatis-plus.version><mysql.version>8.4.0</mysql.version><swagger.version>2.5.0</swagger.version></properties><dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-core</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version><scope>provided</scope></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>${guava.version}</version></dependency><dependency><groupId>com.alibaba.fastjson2</groupId><artifactId>fastjson2</artifactId><version>${fastjson2.version}</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>${mybatis-plus.version}</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>${mysql.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-ui</artifactId><version>${swagger.version}</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>3.2.5</version><scope>test</scope></dependency></dependencies></project>