Claude Code吞金兽?一个工具让你随便用!
如果你最近在用 Claude Code 写代码,大概率已经感受过一种很微妙的崩溃感。
你会觉得,太强了,这简直像请来了一个全天在线的全栈工程师。
开始前面刚说过的话,后面像没见过一样,乱七八糟开始胡言乱语。
有时候一个 session 还没跑多久,模型就已经“缩水”了,像是脑子突然被清空了一部分。
而且,账单还越来越长,coding plan也一下子就跑完了。
很多人会把这个问题理解成:Claude Code 太贵了。
但如果你往下看一层,你会发现,真正烧钱的地方,常常不在你以为的地方。
问题很可能出在一个大家平时不会特别注意的东西上——context,也就是上下文窗口。
最近看到一个关于Context Mode的技术讲解,里面把这个问题拆得很清楚。
Claude Code 真正贵在“搬运”
很多人平时用 Claude Code,会默认一件事:
它去读文件、抓网页、看 issue、分析日志,这些动作本来就是应该的。
可问题在于,Claude Code 处理这些工具调用的方式,本身就很吃上下文。
在 Claude Code 里,每一次 MCP tool call,工具返回的完整输出都会直接塞进模型的 200K context window 里。
也就是说,工具查回来的内容,并不会安安静静待在某个外部空间里,等需要时再调取;它会直接进入对话上下文,跟着整场会话一起被反复带上。
这个机制一旦遇到大文件、大网页、大量 issue,代价会非常夸张。
比如一个 Playwright 的网页 snapshot,大概是56KB。
读 20 个 GitHub issues,大概是59KB。
如果这些操作在规划阶段反复来几轮,模型在还没正式开始写代码之前,就可能已经吃掉了70% 的上下文窗口。
后面贵都已经不是事儿了,而是越聊越没“脑子”,从高智商变成小智障。你问它任务是什么?阿巴阿巴阿巴阿巴
一个 session 开始时,它思路清晰,记忆完整,改代码像一个专注的工程师。
在某些使用方式下,你可能只有30 分钟左右的活跃 agent 时间,之后上下文就会开始 compact。
一旦 compact 发生,很多之前积累下来的细节就会被压缩,甚至直接掉失。
这时候,AI 还在继续哼哧哼哧埋头干活,但你已经开始想ctrl D了。
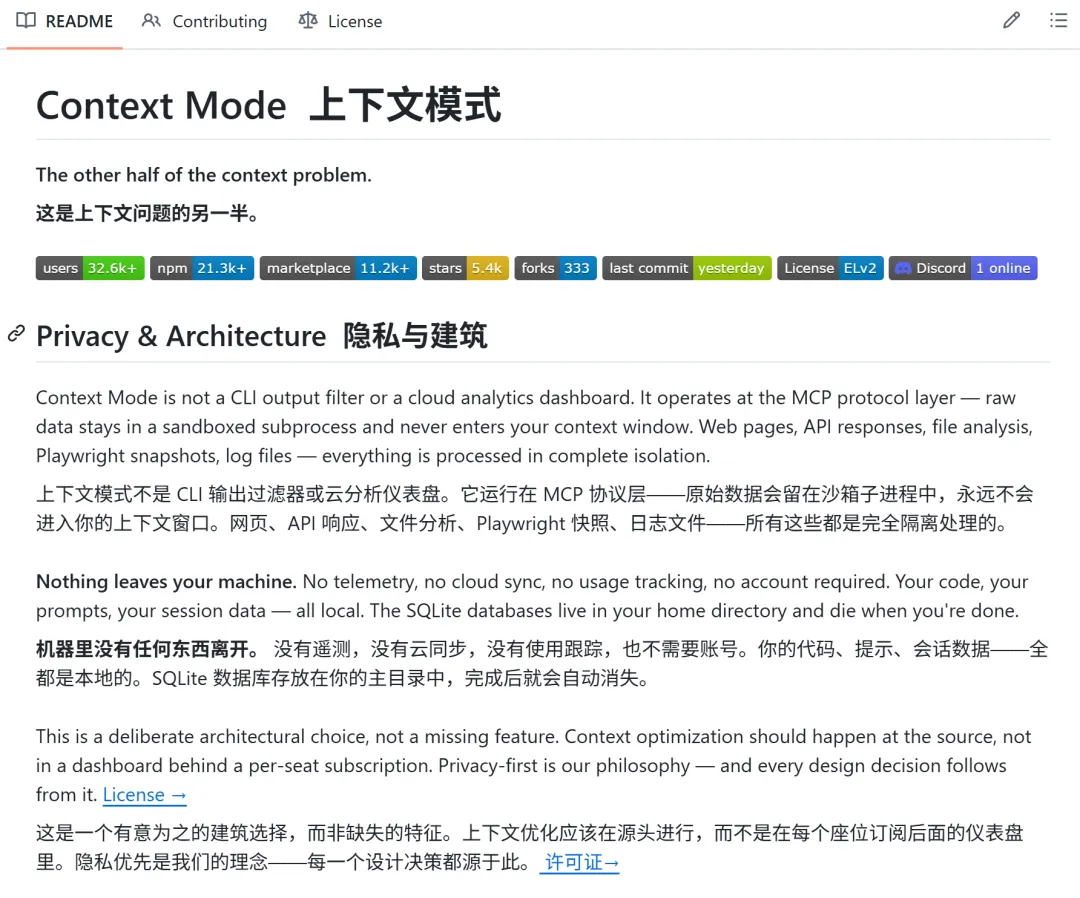
Context Mode ——在 Claude 和操作系统之间,加了一层“上下文虚拟化”的缓冲层。
有了它,AI 不再直接跟你的 OS 对话,而是先经过一个 sandbox。
工具输出也不再一股脑塞进上下文,而是先被收纳、索引、压缩,然后按需要再检索。
Context Mode 会把这些大块输出放进一个本地的SQLite 数据库里,并用FTS5(全文搜索)做索引。
这样一来,Claude 并不需要把整个网页快照、整个日志文件、整批 issues 全部背进上下文里。
它只需要知道:这些内容已经被索引好了,之后可以按需搜索。
一个56KB 的 Playwright snapshot,压到只剩299 bytes;
一个 analytics CSV,被压到222 bytes。
这基本就是99% 级别的缩减,这已经不是“小优化”了,这几乎是在重新定义上下文该怎么用。
以前的方式,是把东西全部塞进一个py, def一大堆,function乱窜,想改都找不到先改谁。
现在Context Mode 的做法,就是分层,把资料放进一个可搜索的仓库里,需要的时候再精准拿出来。
脑子里终于不再堆满杂物,真正的推理空间也就出来了。
但是,saving tokens is just one part of the fix。
真正让这个工具有价值的地方,在于它在想办法保护一场 coding session的连续性。
尤其在写代码这件事上,连续性一断,整个体验就会瞬间下滑。这也是为啥大厂裁员之后又喊回去,发现人重要的是后续的维护,写得不快,但是我维护给力、稳定啊。
AI一旦断档,总是选择rewrite,很难结构性长期性的保持同等状态。
Context Mode 在这方面做了一件很关键的事:
它会通过 hooks 去监控文件编辑、get 操作、subagent 任务等关键动作。
当上下文 compact 发生时,它会生成一个带优先级的 snapshot,通常控制在2KB 以内,然后再把这个“检查点”注入回去。
这就像游戏里的存档点,你走到一半,哪怕场景切换了、内存清了,关键进度还在,Claude 不至于一下子回到“只记得开头”的状态。
之前写过什么、哪一版尝试失败过、哪些决定已经做出过,这些信息可以被更有结构地保留下来。
在这种机制下,session 时间理论上可以从30 分钟延长到大约 3 小时。
我一直觉得,AI coding 到了今天,大家开始慢慢进入第二阶段了。
开始意识到,真正决定体验上限的,已经不只是“它会不会做”,而是“它能不能持续、稳定、低损耗地做”。
这时候,context management 这种东西的重要性就上来了。
因为 AI 编程里最昂贵的成本,很多时候并不是一次推理调用。
这些事情叠在一起,才是账单越来越高、体验越来越差的真正原因。
所以 Context Mode 的价值不仅仅是省钱、省时间,比如,给模型清掉噪音,留出真正思考的空间。更重要的是,让我们持续地使用AI作为partner,而不是一次性消耗品。
 夜雨聆风
夜雨聆风