 夜雨聆风
夜雨聆风





从英伟达的新神器到华为的新突破,这波 AI 芯片升级超有料
不知道大家有没有发现,最近的AI体验越来越“丝滑”了:和AI智能体聊天再也不用等半天,聊上几十轮也不会“断片”;文生图、文生视频的生成速度翻了倍,细节还更精致;刷短视频、逛电商时,推荐的内容好像比自己还懂自己……
这些藏在日常里的小美好,背后其实是AI芯片的底层革命。作为AI技术的“算力心脏”,芯片的每一次升级,都在悄悄改变我们和AI交互的方式。就在最近一周,全球AI芯片圈迎来了一波“大动作”:英伟达甩出了新一代推理“神器”,直接把AI实时交互的效率拉满;三星砸下5041亿人民币豪赌未来,要做AI芯片的“全能选手”;华为则带着全新的昇腾950PR算力芯片重磅商用,让国产算力在高端推理赛场稳稳站住了脚跟。
不用怕被满屏的技术参数劝退,今天就用最通俗的话,聊聊这波AI芯片升级的“硬核干货”:英伟达的新芯片到底强在哪?三星的五千亿投资要花在哪?华为的国产芯突破了哪些难关?这波升级又会给AI行业和我们的生活带来什么新变化?
✨ 英伟达甩出「推理王牌」,开启AI实时交互新时代
如果说AI训练芯片是“打造AI大脑的工程师”,那推理芯片就是“让AI大脑高效干活的执行者”。随着大模型从“研发阶段”走向“全民使用阶段”,低延迟、高效率的推理芯片,成了各大厂商的必争之地。而在刚刚结束的GTC 2026大会上,英伟达再次拿出了“王炸产品”,直接定义了新一代AI推理芯片的天花板。
此次英伟达的核心发布是Vera Rubin超级计算平台,这是一个包含7款芯片的“算力全家桶”,涵盖了Vera CPU、Rubin GPU、Groq 3 LPU(语言处理单元)、NVLink 6交换机等核心产品,而其中最受关注的,就是被黄仁勋称为“AI推理终极神器”的Groq 3 LPU芯片——它的出现,直接把AI推理的吞吐量/功耗比提升了35倍,让AI真正进入了“实时交互时代”。

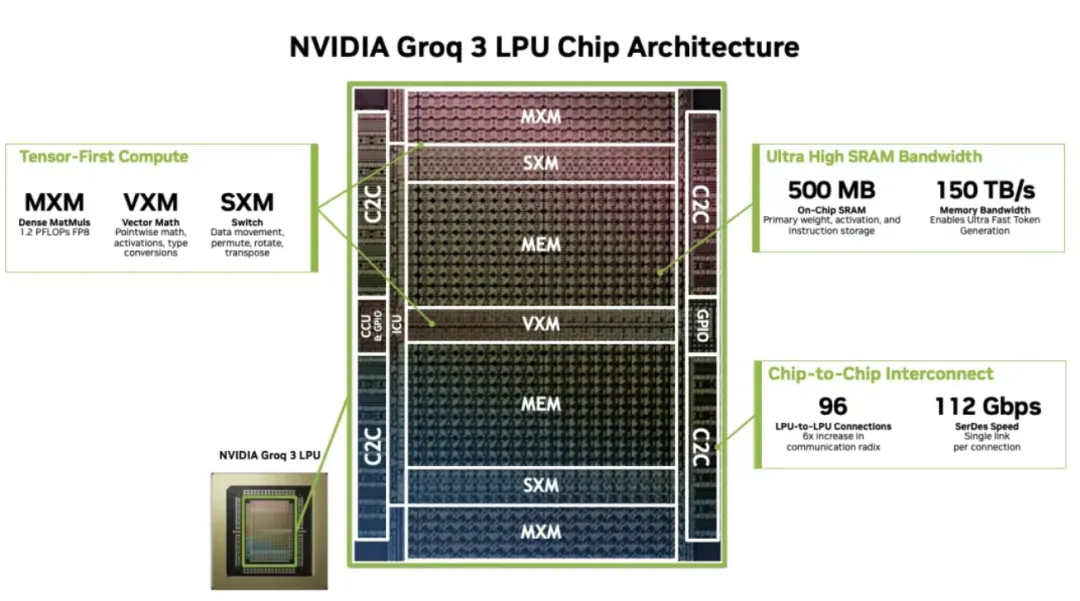
核心亮点1:确定性架构,从“毫秒级延迟”到“无抖动响应”
和传统GPU相比,Groq 3 LPU最大的创新,在于采用了确定性流水线架构。简单来说,传统GPU就像一个“多任务的杂工”,会做很多“猜测性”的硬件设计,比如缓存管理、指令重排,这就导致数据处理时容易出现“抖动”,哪怕是毫秒级的延迟,在自动驾驶、高频交易、实时语音交互等场景中,都可能导致决策失效。
而LPU则把这些复杂的硬件设计彻底剥离到编译器层,让数据在芯片内的流动像“精密的传送带”一样,没有任何不可控的波动。举个例子,对于需要数百次模型调用的复杂AI智能体对话,原本需要数分钟的串联思考,LPU能直接缩短至数秒,让我们和AI聊天时,就像和真人对话一样自然流利,再也不会出现“答非所问”或“加载半天”的情况。
核心亮点2:LPX机架落地,打造“推理算力集群”
为了让LPU的性能发挥到极致,英伟达还推出了配套的Groq 3 LPX机架,一个机架就集成了256个LPU处理器,拥有128GB的片上SRAM(高速缓存)和40PB/s的推理加速带宽,还能通过640TB/s的专用接口实现机架间的无缝连接。
更贴心的是,LPX机架采用了全液冷设计,能有效解决高算力带来的散热问题,同时基于MGX基础设施构建,可以无缝融入英伟达的AI算力工厂。黄仁勋表示,这款机架将于2026年下半年正式出货,届时将和Vera Rubin平台的其他产品一起,构成完整的AI超级计算体系。
核心亮点3:GPU+LPU混合算力,统治“训练+推理”全链路
英伟达的野心,从来都不是单一产品的突破,而是构建完整的算力生态。此次Vera Rubin平台的核心逻辑,是让GPU和LPU各司其职,打造混合算力帝国:GPU负责在后台深耕万亿参数大模型的训练,以及长文本、多模态数据的预处理;而LPU则在前端负责实时推理,以10倍于对手的能效比,处理海量的用户交互请求。
为了让两者协同工作,英伟达还通过NVFusion技术,将LPU无缝嵌入了自己的CUDA生态——要知道,CUDA是全球90%以上AI开发者的首选工具,这种生态整合,让开发者不用重新学习新的技术,就能直接调用LPU的算力,大幅降低了应用开发和部署的门槛。
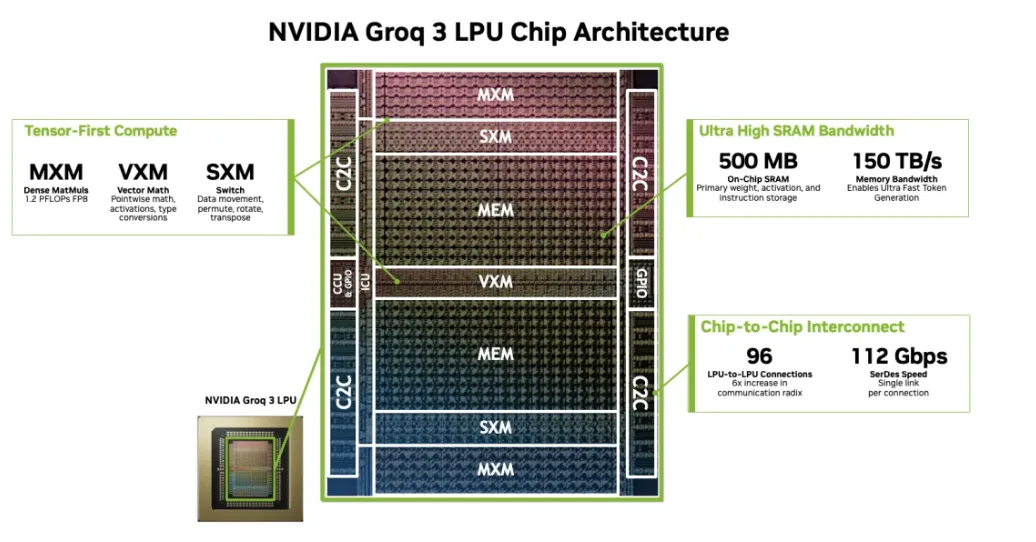
核心亮点4:牵手三星代工,卡位量产落地
值得一提的是,这款核心的Groq 3 LPU芯片,英伟达选择了由三星负责代工。这一合作,既解决了英伟达的产能问题,也让三星在先进制程代工领域拿到了关键订单。据知名分析师郭明錤预测,2026-2027年,Groq 3 LPU的总出货量将达到400万-500万颗,配套的LPX机架2026年出货300-500个,2027年将暴涨至15000-20000个,市场需求可见一斑。
表:英伟达Vera Rubin平台核心产品及功能
|
产品名称 |
核心定位 |
关键功能 |
|
Groq 3 LPU |
推理加速器 |
确定性流水线架构,35倍吞吐量/功耗比,适配实时交互、AI智能体 |
|
Vera CPU |
算力底座 |
单线程性能提升50%,高内存带宽,支撑大规模算力集群 |
|
Rubin GPU |
训练/推理双用 |
协同LPU处理模型计算,负责长文本、多模态数据预处理 |
|
NVLink 6交换机 |
算力连接器 |
640TB/s扩展带宽,实现机架间无缝连接 |
|
ConnectX-9超级网卡 |
数据传输 |
高速数据交互,降低集群内通信延迟 |
对于英伟达来说,Vera Rubin平台的发布,不仅是一次产品升级,更是对AI推理市场的“精准卡位”。随着AI从“感知智能”走向“智能体智能”,实时、低延迟的推理需求会呈指数级增长,而英伟达凭借技术和生态的双重优势,已经提前站在了这个风口的顶端。
✨ 三星5041亿重金布局,打造AI芯片「一站式解决方案」
就在英伟达发布新平台的同一天,三星也抛出了一枚“资本炸弹”:2026年计划在芯片设施投资和研发上投入110万亿韩元(折合人民币约5041亿元),这一数字较2025年的90.4万亿韩元激增21.7%,也是三星首次将年度投资突破百万亿韩元大关。
这笔钱是什么概念?它相当于台积电2026年预估资本支出(520-560亿美元)的1.3倍,甚至超过了美光科技全年的营收。三星明确表示,这笔巨资的核心目标只有一个:确保公司在AI半导体领域的领先地位。而三星的底气,来自于它“全球唯一”的身份——唯一能同时提供存储芯片、逻辑代工、先进封装一站式解决方案的半导体企业。

三大投资方向,瞄准AI芯片的“三大痛点”
三星的5041亿投资,并不是“撒胡椒面”,而是精准瞄准了当前AI芯片发展的三大核心痛点,每一笔都花在了“刀刃上”。
1. HBM军备竞赛:搞定AI芯片的“内存墙”
AI芯片的算力再强,没有高速的内存支撑,也会变成“巧妇难为无米之炊”——这就是行业常说的“内存墙”。而HBM(高带宽内存)作为目前最先进的内存技术,能实现数倍于传统内存的数据传输速度,是高端AI芯片的“标配”。
目前在HBM领域,SK海力士占据主导地位,三星则处于追赶状态。此次投资,三星将重点用于加速HBM4及HBM4E的量产,同时扩大先进封装产能,目标是在高附加值存储市场“确立强劲且可持续的领先地位”,彻底打破AI芯片的“内存瓶颈”。
2. 晶圆代工良率攻坚:从“能做”到“做好”
在逻辑代工领域,三星虽然率先实现了2nm GAA(全环绕栅极)工艺的量产并贡献营收,但和台积电相比,良率差距依然是最大的短板。良率,简单来说就是生产芯片时,合格产品的比例,良率越低,生产成本越高,客户的信任度也越低。
此次投资,三星将重点用于平泽P4/P5工厂及美国泰勒工厂的产能爬坡,目标是在2026年底实现美国3nm/2nm产线的正式运营,通过持续的工艺优化,把良率提升到和台积电比肩的水平。而拿下英伟达Groq 3 LPU的4nm代工订单,就是三星在代工领域的一次重要突破。
3. 先进封装补短板:打破台积电的垄断
如果说芯片制程是“把晶体管做小”,那先进封装就是“把多个芯片拼好”。随着AI芯片的性能瓶颈从晶体管转向封装,先进封装技术已经成为AI芯片竞争的“下半场核心”。而目前在AI芯片封装领域,台积电的CoWoS技术占据了90%以上的市场份额,处于绝对垄断地位。
三星此次投资,将大力研发I-Cube、H-Cube等先进封装技术,重点解决多芯片集成、散热、互联等问题,试图打破台积电的垄断。而三星的优势在于,能实现“存储芯片+逻辑芯片+先进封装”的一体化设计,让芯片的整体性能发挥到极致。
表:三星110万亿韩元投资核心布局及目标
|
投资方向 |
核心举措 |
短期目标(2026) |
长期目标 |
|
HBM内存 |
加速HBM4/4E量产,扩大封装产能 |
缩小与SK海力士的差距,占据HBM市场30%以上份额 |
成为全球HBM市场第一 |
|
晶圆代工 |
平泽/美国工厂产能爬坡,优化2nm GAA工艺 |
美国3nm/2nm产线正式运营,良率提升至85%以上 |
先进制程代工市场份额突破15% |
|
先进封装 |
研发I-Cube/H-Cube技术,实现一体化封装 |
打破台积电CoWoS垄断,拿下10%以上AI芯片封装订单 |
成为全球先进封装领域核心玩家 |
机遇与挑战并存,三星的“资本换时间”豪赌
尽管投资额惊人,但三星要想在AI芯片领域反超台积电,依然面临着三道难以逾越的鸿沟。
首先是市场份额的绝对压制。根据TrendForce最新数据,2025年第四季度,台积电在全球晶圆代工市场的份额高达70.4%,而三星仅为7.1%;在决定AI算力上限的先进制程(7nm及以下)领域,台积电更是拿下了超过90%的订单,苹果、英伟达、AMD等顶级客户的核心产品,几乎都由台积电代工。
其次是客户信任的“隐形壁垒”。对于高端AI芯片来说,良率的稳定性比技术参数更重要——如果良率过低,不仅会增加生产成本,还可能导致供应链中断。而三星在过去的代工业务中,曾多次出现良率波动的问题,这让很多顶级客户仍持观望态度。
最后是技术追赶的“时间差”。台积电的2nm工艺(N2)预计在2025年正式量产,并已获得苹果、英伟达等大客户的提前预订;而三星虽然在GAA架构上抢先一步,但商业化的良率爬升需要时间,“投资额”并不等于“产出效率”。
不过,三星的这次豪赌,依然有着重要的行业意义。一方面,三星的奋起直追,将倒逼整个半导体产业链加速创新,台积电为了守住市场份额,势必会加大研发投入,推出更先进的技术;另一方面,三星的“一站式解决方案”,也为全球AI企业提供了供应链多元化的第二选择——在全球半导体供应链地缘政治博弈加剧的背景下,这种多元化,对整个行业来说尤为重要。
而和英伟达的合作,也让三星在AI芯片的生态中占据了一席之地。未来,随着英伟达LPX机架的大规模出货,三星的代工和存储业务也将迎来新的增长,形成“技术+制造”的双赢格局。
✨ 华为昇腾950PR重磅商用,国产算力实现高端推理突破
在英伟达和三星的“神仙打架”中,最让我们国人感到振奋的,还是华为带来的国产芯好消息。3月22日,在华为中国合作伙伴大会2026上,华为正式发布并展出了搭载全新昇腾950PR处理器的AI训练推理加速卡Atlas 350,标志着华为新一代AI算力芯片正式上市并进入商用阶段——这不仅是华为昇腾芯片路线图的关键落地,更是国产AI算力在高端推理场景的一次里程碑式突破。

在此之前,国产AI芯片在中低端推理场景已经有了一定的市场份额,但在高端推理场景,比如万亿参数大模型推理、高并发的互联网推荐、多模态生成等,一直被英伟达等海外厂商垄断。而昇腾950PR的出现,彻底打破了这一局面,让国产算力真正拥有了和国际主流产品“掰手腕”的能力。
四大核心升级,全是冲着“实际需求”来的
昇腾950PR是华为昇腾950系列的首发型号,定位为大模型推理Prefill阶段及推荐业务场景的深度优化,和前一代的昇腾910系列相比,它在四个核心维度实现了跨越式提升,每一个升级都精准解决了国产AI推理的实际痛点。
1. 低精度计算突破:用“精度换效率”,70B模型单卡加载
大模型推理的核心痛点之一,就是显存占用过高——一个700亿参数的大模型,用传统的FP16精度计算,需要上百GB的显存才能加载,这不仅增加了成本,还会导致推理延迟。而低精度计算,就是通过适当降低计算精度,来大幅减少显存占用,提升推理效率。
昇腾950PR此次新增支持FP8、MXFP8、MXFP4等业界标准低精度格式,还搭载了华为自研的HiF8格式——这种格式在保持FP8高效计算的同时,精度接近FP16,完美解决了低精度计算中的“精度损失”痛点。更值得一提的是,昇腾950PR是目前国内唯一支持FP4低精度的推理产品,支持FP4意味着,一个70B参数的大模型,仅需35GB显存就能单卡加载,推理延迟大幅降低。
2. 向量算力增强:2.5倍性能提升,适配碎片化数据处理
在互联网推荐、多模态推理等场景中,数据往往是离散、碎片化的,这对芯片的向量算力提出了很高的要求。昇腾950PR通过采用创新的SIMD/SIMT新同构设计,并将内存访问粒度从512字节细化至128字节,大幅强化了对碎片化数据的处理能力。
实测数据显示,在短视频推荐、电商广告推荐等场景中,昇腾950PR的性能较前代提升了2.5倍,能在更短的时间内处理海量的用户行为数据,实现更精准的个性化推荐。
3. 互联带宽跃升:2TB/s片间带宽,支撑大规模算力集群
对于AI算力来说,单芯片的性能再强,也需要通过高速的互联技术,组成大规模的算力集群,才能处理万亿参数的大模型。昇腾950PR的片间互联带宽达到了2TB/s,较前代提升了2.5倍,还支持华为自研的灵衢2.0协议及多种通信模式,能实现多个芯片之间的高速、低延迟数据交互,为构建大规模的国产算力集群奠定了坚实基础。
4. 自研HBM内存:规避海外依赖,降低整体拥有成本
和英伟达、三星不同,华为在芯片研发中,始终面临着海外供应链卡脖子的问题,尤其是在HBM高带宽内存领域,海外厂商占据着主导地位。此次昇腾950PR首次搭载了华为自研的HiBL 1.0高带宽内存,这是一款针对推理场景优化的低成本HBM方案。
这款自研HBM,不仅能有效规避海外供应链的依赖,还能大幅降低推理场景的整体拥有成本(TCO)——对于AI企业来说,这意味着在获得高性能算力的同时,还能有效控制投入成本,提升商业化效率。
硬核制造工艺:用“钝刀刻米粒”,良率突破80%
昇腾950PR的成功,不仅是芯片设计的突破,更是中国高端芯片制造工艺的一次攻坚。这款芯片采用的是中芯国际的7纳米工艺(等效N+2/N+3),而由于无法获得最先进的EUV(极紫外)光刻机,中芯国际只能使用上一代的DUV(深紫外)设备,通过复杂的“多重曝光”技术来实现这一制程——这被行业形象地比喻为“用一把钝掉的雕刻刀在米粒上刻字”。
多重曝光技术,简单来说,就是对同一晶圆反复曝光四次或更多次,才能实现7nm的制程精度。这一过程不仅让生产成本比国际领先的EUV工艺高出40%-50%,更对良率控制构成了巨大挑战——每一次额外的曝光,都意味着出错概率的显著上升。
为了解决这一问题,华为和中芯国际展开了紧密的协同设计:华为主动放宽了芯片的设计密度,用“空间换良率”;中芯国际则持续优化曝光工艺,提升晶圆的加工精度。经过数百次的试验,最终昇腾950PR的良率成功突破80%,达到了商用的标准。
更难得的是,在制造过程中,华为还集成了自研的MCM(多芯片模块)封装技术、针对高功耗的先进散热方案,并实现了与国产HBM内存(如长鑫存储的HBM3)的高难度集成。可以说,昇腾950PR的成功制造,不是单一芯片的突破,而是中国在高端芯片设计、制造、封装、存储等全产业链环节协同攻坚的成果。
Atlas 350加速卡落地,性能比肩国际主流产品
作为昇腾950PR的首发载体,Atlas 350 AI训练推理加速卡的性能表现,让业界眼前一亮。根据华为公布的数据,这款加速卡的FP4精度算力达到1.56 PFLOPS,内存带宽达1.4TB/s,功耗仅为600W,还支持2卡、4卡灵衢互联,能灵活匹配不同的业务场景需求。
在和英伟达的主流产品对比中,Atlas 350的优势十分明显:单卡算力达到了英伟达H20的2.87倍,HBM容量为112GB,是H20的1.16倍,多模态生成速度可提升60%,内存访问颗粒度的优化,还让小算子访存效率提升了4倍。在实测场景中,Atlas 350在互联网推荐场景中时延更低、响应更快,在文生图、文生视频等多模态场景中,性能也与英伟达的L20显卡相当。
表:华为昇腾950PR/Atlas 350与前代、英伟达竞品核心参数对比
|
产品型号 |
制程工艺 |
FP4算力 |
片间互联带宽 |
HBM容量 |
多模态性能 |
适用场景 |
|
华为昇腾910 |
7nm(EUV) |
– |
800GB/s |
32GB |
– |
中低端推理、训练 |
|
华为昇腾950PR/Atlas 350 |
7nm(DUV多重曝光) |
1.56 PFLOPS |
2TB/s |
112GB |
比肩英伟达L20 |
高端推理、推荐、多模态 |
|
英伟达H20 |
4nm |
0.54 PFLOPS |
1.6TB/s |
96GB |
基础多模态 |
中高端推理 |
|
英伟达L20 |
4nm |
1.4 PFLOPS |
2TB/s |
112GB |
主流多模态 |
高端推理、多模态 |
规模化商用落地,国产算力迎来“黄金时代”
昇腾950PR和Atlas 350的发布,最关键的意义在于正式开启了国产高端推理算力的规模化商用阶段。在发布会上,昆仑、华鲲振宇、神州鲲泰、长江计算等七家华为核心伙伴,同步发布了基于Atlas 350的服务器整机产品。
比如软通动力旗下的软通华方,发布了“超强A860 A5”AI服务器,这款服务器搭载鲲鹏920处理器,可支持8块Atlas 350加速卡,被业内形容为赋能大模型时代的“核武级”算力,能满足互联网、金融、政务等领域的大规模AI算力需求。
在应用层,各大厂商也在迅速跟进:科大讯飞宣布,其新一代星火大模型将与昇腾910/950系列算力底座进行充分适配,打造更高效的国产大模型生态;华为还联合20家行业头部伙伴,发布了覆盖辅助办公、AI实训、电子病历、智能客服等核心场景的2026昇腾AI应用解决方案,让国产算力能快速落地到各行各业。
更值得期待的是,华为已经公布了清晰的昇腾芯片路线图:将以“一年一代,算力翻倍”的速度推进,2026年第四季度将推出昇腾950DT,2027年推出昇腾960,2028年推出昇腾970。这意味着,国产AI算力的升级,将进入“快车道”,未来在更多高端场景中,都能看到国产芯片的身影。
华为昇腾950PR研发与制造产业链协同示意
(核心节点包括:华为芯片设计(昇腾950PR)→中芯国际7nm DUV多重曝光制造→华为自研MCM封装+散热方案→长鑫存储国产HBM内存配套→华为Atlas 350加速卡集成→伙伴服务器整机生产→各行业应用落地)
这波升级背后,AI芯片赛道的三大核心趋势
英伟达的技术创新、三星的重金布局、华为的国产突破,这三家大厂的动作,看似是各自的战略选择,实则折射出了当前全球AI芯片赛道的三大核心趋势。而这些趋势,将决定未来3-5年AI行业的发展方向,也会悄悄改变我们的生活。
趋势1:推理芯片成绝对主力,AI产业从“研发驱动”转向“应用驱动”
根据中国报告大厅的最新数据,2026年全球AI芯片市场规模预计将突破2800亿美元,同比增长40%,而其中推理芯片的市场规模将达到1450亿美元,占比52%,首次超过训练芯片,成为AI芯片市场的绝对主力。
这一数据的背后,是AI产业的结构性转变:经过几年的发展,大模型的研发已经进入了相对成熟的阶段,而大模型的商业化落地,成为了行业的核心目标。从AI智能体、实时语音交互,到互联网推荐、多模态生成,再到自动驾驶、工业质检,所有的应用场景,都需要低延迟、高效率的推理芯片来支撑。
未来,随着AI应用的不断下沉,推理芯片的市场需求还将持续爆发,预计到2030年,全球AI推理芯片市场规模将突破3万亿元人民币,其中云端推理、端侧推理将同步增长,AI能力将从“云端”走向“终端”,融入我们的手机、汽车、智能家居等每一个设备。
表:2026年全球AI芯片市场规模及结构分布
|
芯片类型 |
市场规模(亿美元) |
占比 |
核心驱动因素 |
|
推理芯片 |
1450 |
52% |
大模型商用落地、实时交互需求爆发 |
|
训练芯片 |
950 |
34% |
万亿参数大模型、多模态模型研发 |
|
边缘AI芯片 |
400 |
14% |
AI能力终端下沉、物联网设备普及 |
趋势2:全链路能力成竞争核心,“单打独斗”不如“协同作战”
从三星的“一站式解决方案”,到华为的“设计+制造+封装+存储”全产业链协同,再到英伟达的“GPU+LPU+生态”混合算力,这波升级都指向一个核心:AI芯片的竞争,早已从单一环节的比拼,变成了全链路能力的竞争。
在AI芯片的发展初期,企业可以依靠某一个环节的优势占据市场,比如台积电的制程优势、英伟达的GPU技术优势、SK海力士的HBM内存优势。但随着AI芯片的性能要求越来越高,单一环节的优势已经无法满足需求——一款高端AI芯片,需要设计、制造、封装、存储、互联等多个环节的协同优化,才能发挥出最佳性能。
未来,全球AI芯片市场的玩家,将分为两类:一类是像三星、台积电这样的全链路巨头,能提供一体化的解决方案;另一类是在某一细分领域拥有核心技术的专精特新企业,通过和巨头合作,在产业链中占据一席之地。而“单打独斗”的企业,将很难在市场中立足。
趋势3:国产算力加速突围,从“跟跑”到“并跑”,向“领跑”迈进
华为昇腾950PR的商用,是国产AI算力发展的一个重要里程碑,它标志着国产算力在高端推理场景,已经实现了从“跟跑”到“并跑”的跨越。而这一突破,不是偶然的,而是中国半导体产业多年来持续投入、协同攻坚的结果。
在芯片设计领域,华为、寒武纪等企业已经掌握了高端AI芯片的设计技术;在制造领域,中芯国际的7nm DUV工艺良率持续提升,14nm工艺已经实现规模化量产;在存储领域,长鑫存储、长江存储的DRAM、NAND闪存技术不断突破,国产HBM内存也开始落地;在封装领域,长电科技、通富微电的先进封装技术,已经接近国际领先水平。
尽管在最先进的EUV光刻机、高端制程等领域,国产半导体产业还存在差距,但在AI芯片这一赛道,我们已经找到了**“换道超车”的机会**——通过聚焦推理芯片、打造全产业链协同、构建自主的算力生态,国产算力正在逐步打破海外垄断,在全球AI芯片市场中占据一席之地。
未来,随着华为昇腾、百度昆仑芯、阿里平头哥等国产芯片的持续升级,以及国内算力集群的建设,国产算力将迎来“黄金时代”,不仅能满足国内AI产业的发展需求,还能走向全球,成为全球AI芯片市场的核心玩家。
最后:芯片的突破,最终都是为了让AI更贴近生活
回顾这波AI芯片的升级,从英伟达的35倍能效比提升,到三星的5041亿重金布局,再到华为的国产高端推理芯片商用,我们看到的不仅是技术的突破,更是AI产业的蓬勃发展。有人说,AI芯片的竞争是一场“零和博弈”,但事实上,这场竞争的最终受益者,是每一个普通人。
那些看似冰冷的技术参数,比如35倍的吞吐量/功耗比、2TB/s的互联带宽、80%的良率,最终都会变成我们身边的小美好:和AI聊天时的自然流利,刷视频时的精准推荐,文生图时的快速高效,自动驾驶时的安全可靠……芯片的每一次升级,都在让AI变得更智能、更贴心、更贴近生活。
而华为的国产突破,更让我们看到了中国科技企业的韧性和底气。在海外供应链卡脖子的背景下,华为没有放弃,而是联合国内的产业链伙伴,一步步攻克难关,最终实现了高端推理算力的商用。这份坚持,不仅为国产AI产业的发展奠定了基础,也为中国科技的自主创新树立了榜样。
未来,随着AI芯片技术的不断进步,以及AI应用的持续下沉,我们的生活还将迎来更多的惊喜。而我们也有理由相信,在全球AI芯片的赛道上,国产算力将走得更远、更稳。