 夜雨聆风
夜雨聆风





收藏!全面接管分子对接与分子动力学,最新AI工具仅靠一句话跑通全流程!


以下为各大热门专题介绍


01.AI蛋白质设计
02.AI蛋白质设计(前沿、进阶)
03.AI抗体设计
04.合成生物学与基因线路设计
05.AI抗菌肽设计
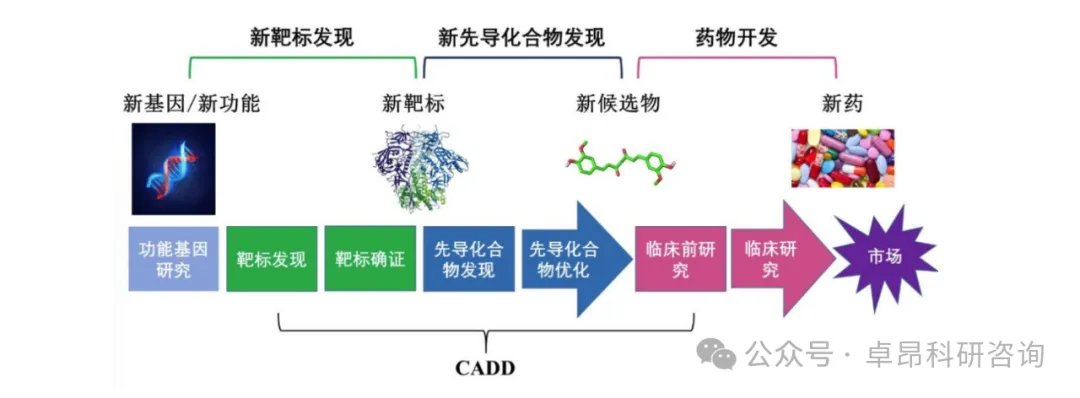
06.CADD计算机辅助药物设计
07.AIDD药物设计(录播)
08.AIDD药物设计进阶(录播)
09.OpenClaw(龙虾)




第一天:熟悉超算环境与蛋白质从头设计实践
1.环境搭建:Linux,VS code,Jupyter notebook*
a)超算的登录
b)Linux系统的常用shell命令:vim, ls, cd, less, rm等;
c)一些package安装的常用命令:pip, conda, source等。
d)Jupyter notebook的安装和使用。
e)VS code的基本配置:连接服务器;选择不同python版本的Interpreter;debug模式的使用等。
2.基础知识讲解
a)三类方法在不同程度上探索蛋白质序列空间:
i.蛋白质定向进化(directed evolution)
ii.固定蛋白质主链的序列设计(Fix-backbone protein design)
iii.蛋白质的从头设计(De novo protein design)
b)关键数据库:RCSB PDB, SCOPe, CATH, UniRef, BFD等
c)常见概念和名词: rotamer, scaffold, motif,domain,backbone,side-chain,apo和holo结构,
d)使用的不同模型的原理,transformer,diffusion模型,Flow Matching等。
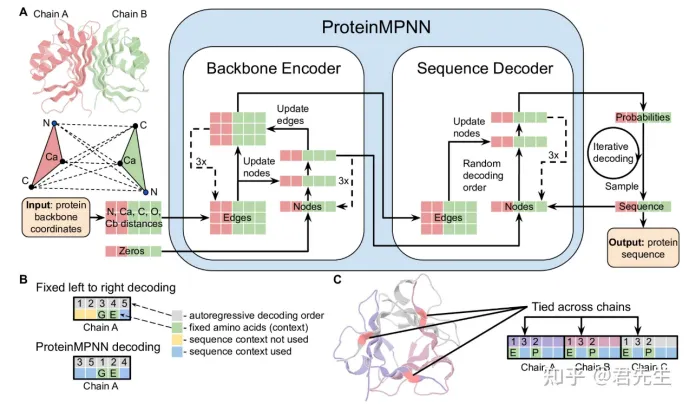
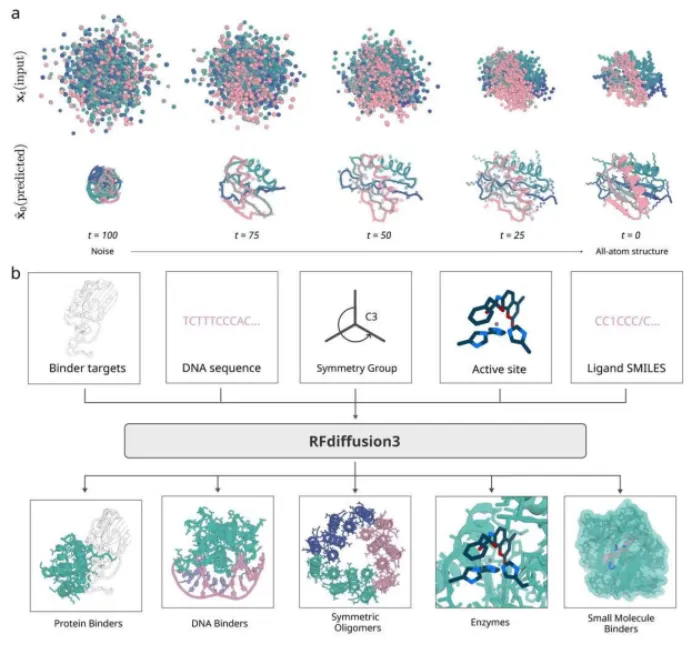
3. Rfdiffusion3+ProteinMPNN生成序列
a)Rfdiffusion3生成蛋白质骨架结构,ProteinMPNN精细的生成氨基酸序列。
b)Rfdiffusion3的安装实操
c)Rfdiffusion3的使用实操
d)ProteinMPNN的安装实操
e)ProteinMPNN的使用实操
f)Rfdiffusion+ProteinMPNN生成序列,AphaFold2筛选序列。整体实操流程:
i.计算SAP(Spatial Aggregation Propensity)的值,选择3-6个氨基酸作为hotspot,即结合位点;这里需要使用Rosetta进行计算,首先将安装rosetta,准备蛋白,再计算每一个氨基酸的SAP值,将SAP数值映射到结构上。选择hotspot位点。
ii. Rfdiffusion结构设计,生成~10000个蛋白质主链结构;
根据上面挑选得到的hotspot位点,更改相应的hotspot参数,生成新的结构
iii.ProteinMPNN-FastRelax进行序列设计,每一个主链结构两个对应的序列,共设计~20000个序列;
iv.筛选:使用AlphaFold2预测设计结构,预测的置信度pAE<10,预测结构与设计结构的RMSD<1A,从中挑选95个进行实验验证。
4.其它的蛋白质设计方法的实操*
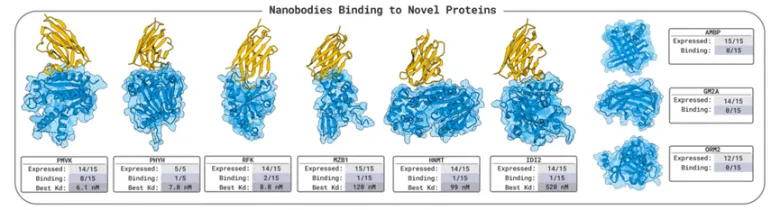
a)BindCraft——序列生成和筛选的自动化实现

BindCraft相比于Rfdiffusion+ProteinMPNN更加用户友好,一站式设计流程,序列的生成和筛选自动化实现。将讲解其中参数的设计和选择,如过滤序列条件、生成氨基酸的偏好性等。使用包括置信度评分(如AlphaFold2预测得到的pLDDT、ipTM)、物理指标(如Rosetta界面能量)和序列特征(如疏水性比例)进行筛选。
b)MIT开发的Bolzgen方法原理、安装使用讲解。
安装和使用boltzgen讲解,将详细讲解yaml配置文件的写法,以一个靶点为例,从头生成VHH与该靶点结合。
c)PPIFlow:基于flow-matching的生成方法,原理,安装和使用方法。
二、蛋白质结构预测和分析
1.蛋白质结构预测方法
1)从CASP比赛结果来简述蛋白质结构预测方法的发展。基于能量函数 -> 接触图的应用 -> 端到端的预测结构(AlphaFold2)。
2)AlphaFold2的模型相比于以前的方法有什么改进
a)将基于MSA和基于模板的方法整合,使用注意力机制进行MSA信息和模板信息的相互交流。
b)以前提取MSA信息为计算协方差矩阵 ,AlphaFold2创造性的直接将MSA信息作为输入,将图像识别的算法转变成了自然语言处理算法,减少了中间处理过程中的信息损失。
3)AlphaFold3相比于AlphaFold2改进了什么,还有什么不足。
a)扩展到了多种生物分子的复合物结构预测,包括蛋白质-DNA、蛋白质-RNA、蛋白质-小分子,并使用扩散模型。
b)复合物组装与动态预测缺陷,抗体-抗原复合物结构准确度有待提高。
4)运行网页server上的AlphaFold3预测结构
5)如何使用AlphaFold3预测蛋白质的糖基化,不同糖基化的类型的输入方法。
6)AlphaFold3输出结果分析,各项置信度指标的含义,以及如何判断预测的准确度,如pLDDT,ipTM,PTM,PAE。
7)本地部署和运行ColabFold,由于AlphaFold3在安装过程中需要下载大量资源,且不能商用,因此不演示AlphaFold3的安装过程,如有问题可以帮助解决。
2.蛋白质结构分析和可视化
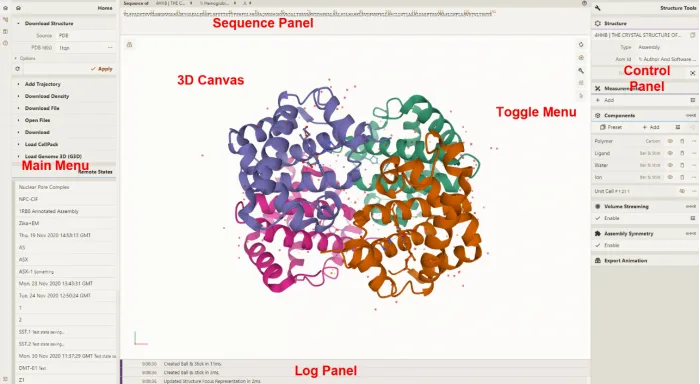
1)pdb文件的解读,每一行中的内容代表什么含义。
2)用 pymol 可视化蛋白质结构*
a)pymol的基础操作讲解
b)如何将实验值投影到结构图的颜色上,如何画出发表文章中好看的图
3)计算蛋白质结构中两个氨基酸的距离*
a)使用python的文本文件操作实现
b)使用python中biopython包实现
3.蛋白质结构相关物理性质的计算*
1)二级结构的分类和计算
2)溶剂可及表面积(SASA)的讲解及计算
三:蛋白质序列分析,数据挖掘和训练数据准备
讲解和实操:
1.获得同源序列
1)了解不同蛋白质序列库,如UniRef90,UniClust30,Pfam等
2)了解不同工具原理并使用:NCBI BLAST,Jackhmmer,HHblits
3)给定一条蛋白质序列,比对序列库,生成多序列比对(MSA)*
从AlphaFold2的经典代码仓库中找到它的生成MSA的代码并学习(alphafold/alphafold/data/tools/jackhmmer.py)。
运行示例:jackhmmer –cpu 8 -N 2 -E 1e-7 query.fasta uniprot_sprot.fasta -o output.sto
2.对MSA进行频率分析*
1)使用python的文本文件操作实现
2)使用python中biopython包实现
3)绘制序列Logo,可视化的展示每个位点的氨基酸频率和保守性
3.序列的同源性计算和进化树的绘制*
1)不同同源性的计算方法及应用情景,氨基酸序列的identity和Similarity,BLOSUM62的介绍。
2)进化树的绘制
4.基于序列相似性阈值划分训练集和测试集*
1)为什么要做?避免数据泄露
2)选择相似性度量方法
3)相似性矩阵的计算
4)划分数据集
5.大规模蛋白质序列的聚类分析和去冗余*
1)为什么要做?防止过度学习某一类序列特征,消除序列偏差;也能防止训练过程中数据泄露。
2)聚类方法的选择,CD-HIT、MMseq2和Linclust
3)选择代表序列,去冗余
4)实际复现S2ALM这一模型文章中的聚类方法。mmseqs easy-cluster examples/DB.fasta clusterRes tmp –min-seq-id 0.7 -c 0.8 –cov-mode 1
四、蛋白质的大语言模型及其应用
1.基础知识讲解
1)介绍蛋白质的语言模型(26字母语言模型->20氨基酸字母表,上下文依赖->氨基酸的共进化)
2)为什么要开发蛋白质大语言模型?1. 相比于结构或功能信息,序列信息更加海量;2. 蛋白质序列通过进化而来,可以学习蛋白质基本规律,折叠,共进化等
3)模型架构和基础理论:transformer,多头注意力机制,Bert,GPT,T5等
2.基于Bert架构的蛋白质语言模型
1) ESM系列(ESM-1b、ESM-1v、ESM2、ESM C)
2)ESMFold:无需MSA信息的结构预测
3)使用抗体序列库训练的语言模型:Ablang,AntiBERTy
3.类似GPT的生成模型ProGen
1)36层Transformer解码器架构,包含12亿参数
2)引入“控制标签”(如蛋白质家族ID、功能属性)作为输入,生成蛋白质序列空间以外的新的蛋白质序列
3)成功生成新的溶菌酶
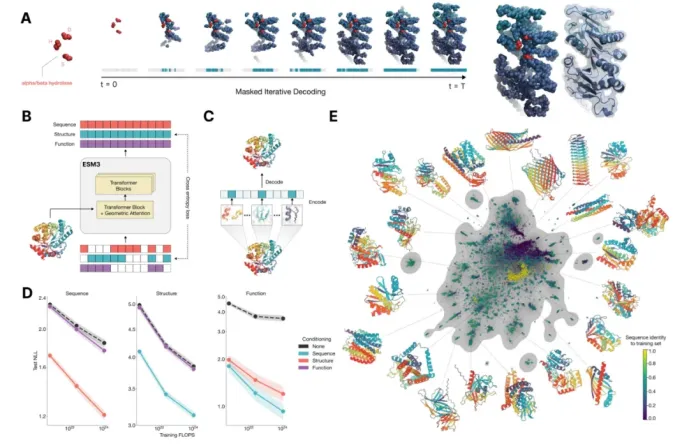
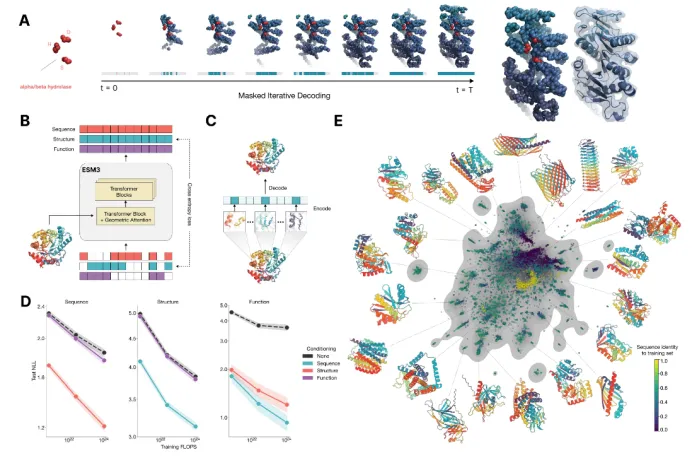
4.多模态的蛋白质语言模型ESM3
1)模型架构融合序列,结构和功能信息
2)相比于ESMFold,单体结构预测精度更好
3)基于多模态提示(序列、结构、功能关键词)设计新的蛋白质序列
4)ESM3的安装,生成序列,快速结构预测。*
5.蛋白质语言模型的应用和实战演练*
1)获得序列embedding以构建下游模型(Cell systmes文章举例),从文章github仓库中提炼序列embedding的代码并学习使用。
看懂代码中EncodingGenerator的类,将这个类方法用在我们自己的代码上,实现蛋白质序列的不同方式encoding,包括”onehot”, “georgiev”, “esm”系列模型。
2)使用不同的蛋白质语言模型,零样本的预测蛋白质突变效应。
3)给定少量的突变效应数据作为训练数据,训练模型,预测新的突变效应值。
五、深度学习辅助酶设计
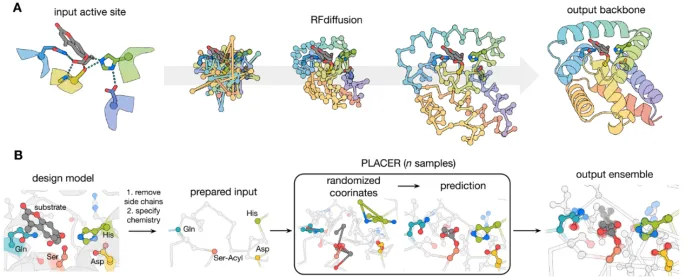
1.基础知识讲解
酶的过渡态理论,theozyme,fitness landscape,epistasis
2.酶学性质预测
1.DLKcat与GotEnzyme数据库介绍
2.UniKP:利用预训练模型挖掘、改造Kcat
3.CLEAN:基于对比学习的EC号预测挖掘稀有脱卤酶
3.蛋白质热稳定性改造
1.MutCompute介绍
2.利用MutCompute改造PETase(Nature)
3.ThermoMPNN介绍与使用*
4. Pythia介绍与使用*
4.从Frances H. Arnold(2018年因在酶的定向进化领域的贡献获得诺贝尔化学奖)的工作看酶的定向进化方法的发展
1.传统定向进化实验流程
2.MLDE(Mechine Learning Directed Evolution), 学习序列与酶性能之间的映射关系,推荐新的突变组合(PNAS文章)
3.ftMLDE(focused training MLDE),主动学习流程,构建informative的训练数据(Cell Systems文章)。零样本突变效应预测挑选数据集,再通过小样本数据训练的策略微调。
5.酶的从头设计
1.从头设计Diels-Alder催化酶
a)基于Rosetta的Inside-out策略(Science文章)
b)通过Foldit蛋白质折叠游戏改善结构问题(Nat. Biotechnol.文章);
c)Foldit蛋白质折叠游戏的实践*
2.从头设计荧光素酶,Family-wide hallucination,基于该酶家族的结构幻化出新的结构(Nature文章)
3.RFdiffusion+PLACER从头设计丝氨酸水解酶(Science文章)
6. 利用预测结构的相似性,挖掘序列的新酶功能(复现顶刊cell文章)*
1.InterPro数据库中下载数据
2.TM-score计算结构距离
3.UPGMA结构聚类,画出进化树
4.挑选序列
六、蛋白质功能与互作预测;实验验证与AI模型训练预测闭环
1.蛋白质功能预测:
1)基础知识:
a)基因本体论(Gene Ontology, GO),
b)MF/BP/CC,MF Molecular Function分子功能;BP Biological Process生物过程;CCCellular Component 细胞组分。
c)GAF (GO Annotation File) 文件。
d)本体文件来理解GO术语之间的层次关系。
e)解析GAF,提取蛋白质ID和GO ID。
2)DeepGO-SE,通过蛋白质的语言模型提取序列嵌入,预测蛋白质的功能
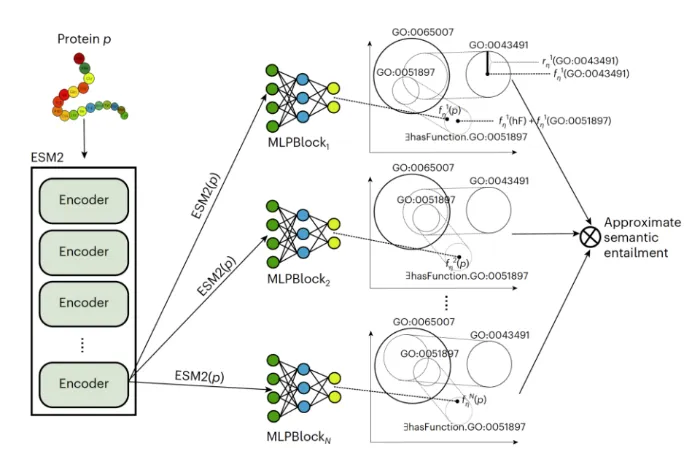
3)DPFunc:先用蛋白语言模型提取残基特征,再在接触图上用 GCN 学习结构信息,并引入结构域(domain)指导,最后把多层特征映射到 GO 图上,显著提升对罕见功能项和低序列相似蛋白的预测精度
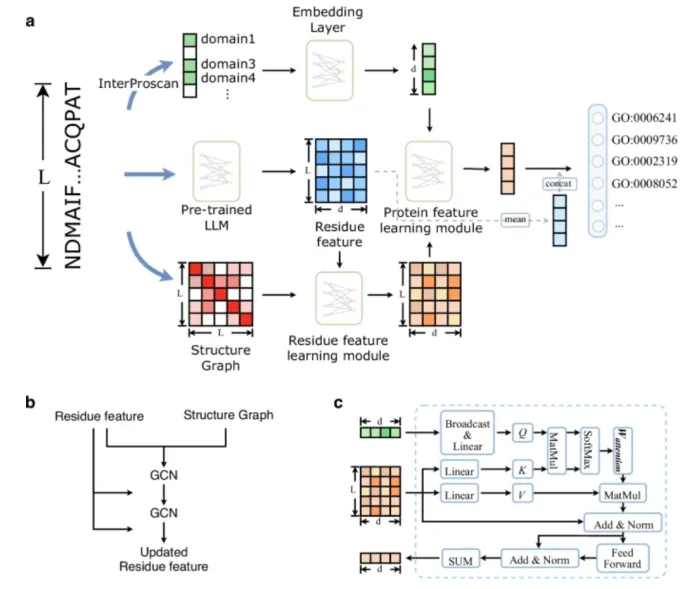
4)Prot2Text-V2模型。Prot2Text-V2将图神经网络(Graph Neural Network, GNN)与大型语言模型(Large Language Model, LLM)融合到同一个编码器-解码器框架中,有效整合了包括蛋白质序列、结构和文本注释在内的多种数据,以自由文本形式输出蛋白质功能预测结果
5)ProteinKG65构建蛋白质知识图谱,基于Gene Ontology (GO) 和 UniProt 等权威知识库,将蛋白质的功能、结构、相互作用等知识组织成图谱形式,支持下游的机器学习任务,如蛋白质功能预测、表示学习、药物靶点发现等
2.蛋白质相互作用预测:
Science文章:使用更深的进化信号:omicMSA+新的深度学习网络:RF2‑PPI。在全人类蛋白质组中筛出一批高置信度的互作,用于补齐人类互作图谱、解释疾病突变和蛋白功能。
1. 更深的进化信号:omicMSA
从约 30 PB 的未组装基因组/转录组数据里挖人类蛋白的同源序列,而不仅仅依赖 UniRef 等传统数据库。
构建omicMSA,使得每个蛋白的深度比常规模板 MSA 深 7 倍左右,协同进化信号显著增强。
2. 新的深度学习网络:RF2‑PPI
基于 RoseTTAFold2 框架开发了一个新的 PPI 预测网络 RF2‑PPI,用来快速估计两条蛋白是否互作以及界面大致形态。
为了训练 RF2‑PPI,构建了很大的数据集:从约 2 亿个预测蛋白结构中抽取各种结构域组合,构建了大规模的 DDI 训练样本,使训练集规模相比传统 PPI 结构数据扩大约 16 倍
筛选流程:
1. 人类蛋白集合
取约 19,500 个人类蛋白序列(UniProt 等),所有可能的配对约 2 亿对。文章中实际筛查约 2 亿对蛋白组合。
2. 构建深度 omicMSA
对每个蛋白,以及蛋白对,基于 30 PB 基因组/转录组数据构建 omicMSA,并对每个蛋白对生成配对 MSA(pMSA),用于协同进化分析和后续深度学习输入。
3. 快速预筛:共进化 / RF2‑PPI 粗打分
先用直接耦合分析(DCA)等共进化方法,结合 RF2‑PPI 对 2 亿对蛋白打一个“互作概率”分数(RFIntProb),过滤掉大部分不可能的组合。
从 4360 万对预筛后的蛋白对中,用 RF2‑PPI 进一步筛选出约 190 万对 RFIntProb > 0.3 的候选。
4. 精细建模:AlphaFold2 复合物结构
对这约 190 万对蛋白,用 AlphaFold2(多聚体/复合物模式)进行结构预测,得到每一对的三维复合物模型以及一个基于界面质量的互作概率(AFIntProb)。
根据 AFIntProb 以及界面大小等指标选择高置信度互作。
5. 高置信度集的定义
在所有蛋白对中,最终在“完全无先验”的全 2 亿对筛选中得到 6,763 个高置信度 PPI;
进一步结合已有数据库(STRING、BioGRID、UniProt 里有物理互作证据的 115 万对蛋白对),在有先验证据的集合上又识别出 21,960 个高置信度 PPI。
综合各种来源和精度阈值,共预测出 17,849 个 PPI,预期精度约90%,其中 3,631 个此前实验未报道的新互作。
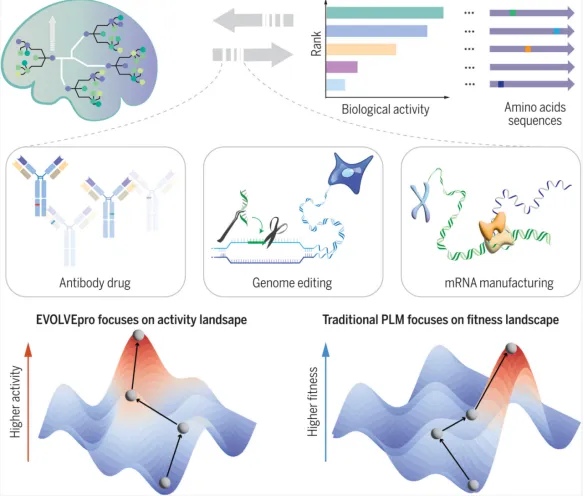
3. AI模型训练预测和实验闭环
以 EVOLVEpro 为例,实践计算–实验闭环:
1.初始化
●选取少量已测序列(野生型 + 文献或少量自设计突变),测定活性。
●用蛋白语言模型把序列编码成向量,训练一个初始的监督回归模型(序列向量→ 活性)。
2.生成候选序列
●设定允许的突变范围(允许 1–3 点突变、限定在特定位点/区域)。
●在该空间内大规模生成候选序列(10^3–10^5),可结合 embedding 空间附近搜索、局部扰动等策略。
3.预测与智能选样
●用回归模型对所有候选序列预测活性或综合评分。
●依据主动学习策略挑出一小批要做实验的序列:
●直接选预测值最高的 top‑k;或
●结合预测不确定性、序列多样性等,使样本既“高潜力”又“信息量大”。
4.实验验证
●合成/构建这批候选序列,利用高通量实验(如流式、板读、NGS 条形码筛选等)测定真实活性。
●得到新一轮“序列–活性”数据。
5.回流更新与迭代
●将新数据并入训练集,重新训练或微调回归模型(PLM 一般保持不变)。
●重复“生成候选 → 预测选样 → 实验验证 → 更新模型”的循环,通常 3–4 轮即可显著提升目标性能。


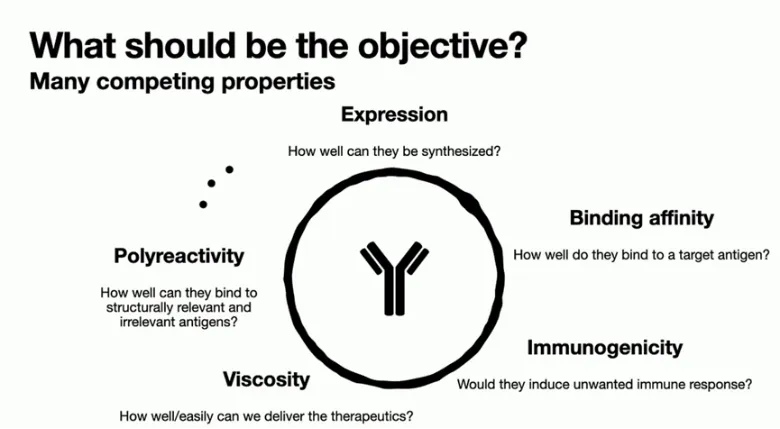
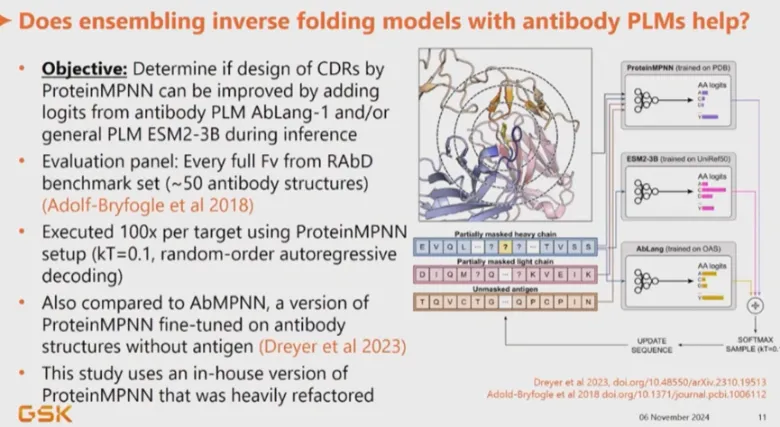
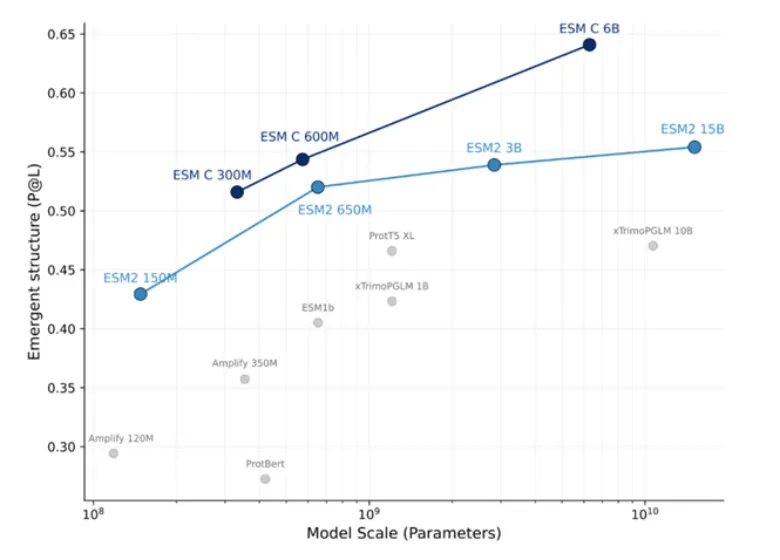
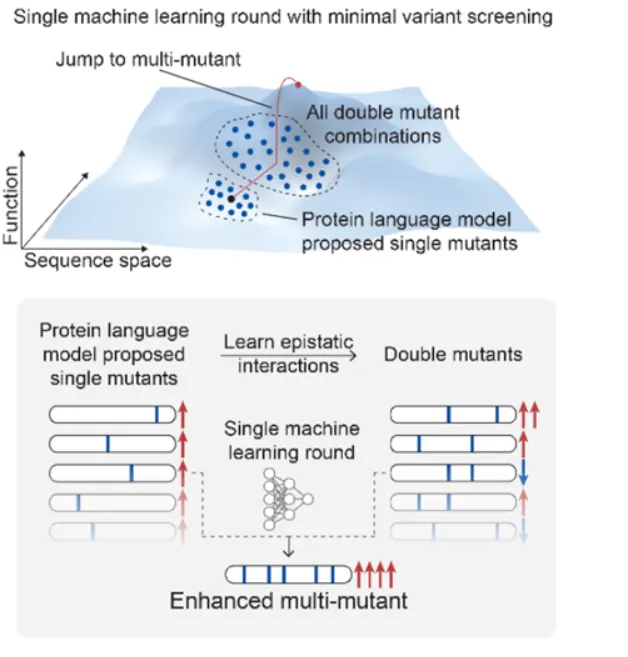




一、:合成生物学导论与入门
主题:从DNA组装到生命系统设计
一、合成生物学定义与发展简史(1小时)
定义与核心概念
合成生物学是通过工程化方法设计和构建生物系统,以解决实际问题的跨学科领域,融合生物学、工程学和信息学。
核心目标:改写生命遗传指令,实现定制化功能(如生产药物、能源)。
发展简史
起源:20世纪中叶,DNA双螺旋结构发现和蛋白质合成技术奠定基础。
里程碑:
2000年:基因网络开关设计(Collins团队)。
2002年:人工合成脊髓灰质炎病毒(Wimmer团队)。
2010年:首个人工合成基因组细胞(Venter团队)。
2014年:非天然碱基配对整合(Romesburg团队)。
现状:21世纪后快速发展,聚焦基因组设计、细胞工程和产业应用。
二、常用软件工具与网站介绍
基因设计工具
DNAWorks:免费在线软件,用于设计寡核苷酸链(适用小片段合成)。
商业软件:如Snapgene,GenBank(序列数据库)、EMBL(欧洲生物信息学资源),支持基因组全序列下载和分析。
功能:序列优化、引物设计、模拟基因表达。
代谢通路建模工具
KEGG(京都基因与基因组百科全书):可视化代谢通路,辅助设计合成生物学模块。
实践平台
iGEM(国际基因工程机器大赛)官网:提供标准化生物元件库和社区资源。
NCBI(美国国家生物技术信息中心):综合数据库,支持基因序列检索和功能注释。
三、代谢数据库与知识库
核心数据库
代谢组学数据库:如HMDB(人类代谢组数据库),整合代谢物结构和功能信息。
基因组数据库:GenBank、EMBL、DDBJ(日本DNA数据库),存储全基因组序列。
功能:通过序列比对和通路映射,预测基因功能和代谢网络。
知识库应用
设计阶段:利用数据库筛选标准化生物元件(如启动子、终止子),确保设计可行性。
测试阶段:比对实验数据与数据库,验证代谢通路效率(如酶活性分析)。
四、互动实践:常用软件使用
实践目标
掌握DNA序列设计、组装模拟。
步骤与工具
DNA设计:使用Snapgene输入目标序列,生成寡核苷酸链并模拟组装。
数据分析:通过NCBI BLAST比对序列相似性,评估设计准确性。
二、基因编辑与工具技术
eCRISPR技术、基因合成、生物元件设计(启动子/终止子)
一、基因编辑技术基础概念
基因编辑定义与核心原理
定义:通过人工干预修改生物体基因组,实现特定性状改变。
核心原理:
DNA断裂与修复:双链断裂(DSB)触发细胞修复机制(NHEJ或HDR)。
碱基编辑:直接修改单个碱基,无需断裂DNA。
基因编辑工具发展历程
第一代:ZFN(锌指核酸酶,2000年代初,靶向性差)。
第二代:TALEN(转录激活因子样效应核酸酶,2010年代,灵活性提升)。
第三代:CRISPR-Cas9(2012年诺贝尔奖,高效、低成本、可编程)。
二、CRISPR-Cas9系统详解
CRISPR系统组成与工作机制
核心组件:
Cas9蛋白:切割DNA的“剪刀”。
sgRNA(单导RNA):引导Cas9到目标位点(含20nt互补序列)。
PAM(原间隔序列):Cas9识别的短序列(如NGG)。
工作机制:
sgRNA与Cas9结合,形成复合物。
复合物识别PAM,切割DNA双链。
细胞通过NHEJ或HDR修复断裂。
CRISPR系统操作流程
步骤:
设计sgRNA:选择目标基因的PAM序列,设计20nt互补RNA。
构建载体:将sgRNA和Cas9基因插入质粒(如pCRISPR1)。
转化宿主:将载体导入细胞(如HEK293T细胞)。
筛选与验证:通过PCR、测序确认编辑效率。
CRISPR技术优化方向
提高特异性:使用高保真Cas9变体(如HF-Cas9)。
降低脱靶率:优化sgRNA浓度,避免非特异性切割。
扩展应用场景:开发CRISPR-Cas12(靶向单链DNA)和CRISPR-Cas13(靶向RNA)。
CRISPR实验注意事项
实验设计:设置阴性对照(如非靶向sgRNA)。
数据分析:使用NGS(下一代测序)评估编辑效率。
三、基因编辑实验设计实践
实验方案设计要点
明确目标:编辑单个基因(如敲除)或多基因(如代谢通路优化)。
选择宿主:根据基因功能选择模式生物(如大肠杆菌、酵母、人类细胞)。
优化条件:调整sgRNA浓度、Cas9表达量、转化方法(如电穿孔)。
不同微生物宿主SgRNA设计原则
原核生物(如大肠杆菌):
优先选择PAM序列(如NGG),避免CRISPR-Cas系统的天然防御机制。
真核生物:
避免设计在基因组重复区域或调控序列中的sgRNA。
筛选方法与验证
筛选:通过抗生素抗性或荧光标记(如GFP)筛选成功转化细胞。
验证:PCR扩增:设计引物跨越编辑位点,检测片段大小。
测序:对PCR产物进行Sanger测序,比对参考序列。
功能检测:如编辑后基因表达量(qPCR)、表型变化(如细胞生长速度)。
单基因编辑设计与多基因编辑设计
单基因编辑:
步骤:设计sgRNA→构建载体→转化细胞→筛选→验证。
多基因编辑:
示例:在酵母中同时编辑3个代谢基因(如ADH1、PGK1、GAPDH)。
三、基因线路工程与动态调控
主题:细胞内的“逻辑电路
基因电路设计原理
一、基因线路概述
1. 定义与功能
o基因线路:生物体内基因表达的调控网络,通过逻辑门(与门、或门、非门)实现特定功能(如代谢调控、信号响应)。
o核心功能:
§开关控制:基因表达的“开/关”(如乳糖操纵子)。
§信号处理:环境信号(如光、温度)的响应与转导。
§稳态维持:通过负反馈调节基因表达水平。
2. 应用领域
o生物制造:优化代谢通路。
o疾病治疗:基因疗法。
o环境监测:工程菌检测污染物。
3. 案例对比
o原核案例:大肠杆菌乳糖操纵子(LacI蛋白抑制转录,乳糖诱导表达)。
o真核案例:人类β-珠蛋白基因增强子(远端调控序列激活转录)。
二、基因线路设计原则
1. 模块化设计
o原则:将复杂功能拆解为独立模块(如启动子、转录因子、报告基因)。
o示例:设计“光控开关”线路,分离光敏蛋白与报告基因(如GFP)。
2. 稳定性与可预测性
o正交设计:减少模块间干扰(如避免共用转录因子)。
o鲁棒性:通过冗余设计(如双启动子)确保功能稳定。
3. 实验验证方法
o荧光报告基因:定量表达水平(如GFP荧光强度)。
oqPCR:检测转录效率(如mRNA量)。
三、实践操作:基因线路构建
1. 工具介绍
oCRISPR-Cas9:精准编辑基因(如敲除抑制子)。
o质粒载体:携带基因线路元件(如pCRISPRi)。
o电转化技术:将载体导入细胞(如大肠杆菌)。
2. 设计“光控开关”基因线路
o步骤:
1. 设计光敏蛋白:选择光敏离子通道(如ChR2)或光敏转录因子(如PhyB)。
2. 构建载体:将光敏蛋白基因与报告基因(如GFP)插入质粒。
3. 转化宿主:将载体导入大肠杆菌,筛选阳性克隆。
4. 验证功能:光照后检测GFP荧光(定性)或qPCR(定量)。
3. 实验
o阴性对照:使用非光敏蛋白(如GFP空载质粒)。
o优化条件:调整光强、曝光时间。
四、动态调控原理
1. 负反馈与正反馈
o负反馈:转录因子抑制自身表达(如乳糖操纵子中的LacI蛋白)。
o正反馈:转录因子激活自身表达(如噬菌体λ的CI蛋白)。
2. 时间延迟效应
o原因:基因表达与调控的滞后(如转录、翻译过程)。
o影响:导致系统振荡或稳态偏离。
3. 案例:大肠杆菌动态调控高产莽草酸
o背景:莽草酸是合成抗病毒药物的原料。
o调控机制:
§负反馈:莽草酸合成酶(如AroB)抑制自身表达。
§优化策略:通过CRISPR敲除抑制子(如AroB的负调控蛋白),提高产量。
五、系统集成与案例分析(
复杂线路设计策略
o振荡器:结合负反馈与时间延迟(如基因表达振荡)。
o开关:利用逻辑门(如与门)控制多基因表达。
o脉冲发生器:通过瞬时信号触发基因表达(如热激响应)。
1. 案例分析:合成生物学中的动态调控
四、代谢工程与生物制造
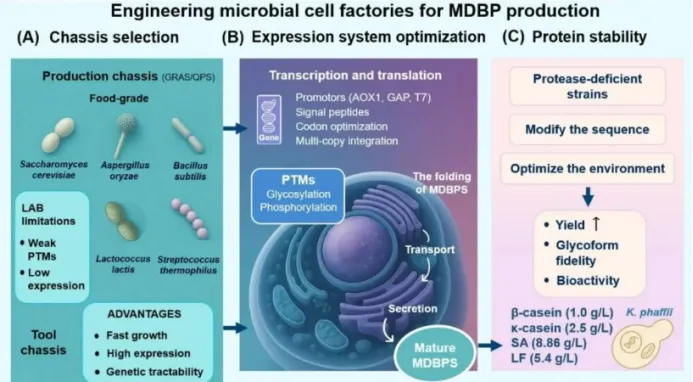
主题:微生物细胞工厂的理性设计与代谢通路设计与重构
一、细胞工厂与理性设计范式
1. 细胞工厂定义
o利用工程化微生物(如大肠杆菌、枯草芽孢杆菌、酵母)作为“生物反应器”,通过重构代谢网络生产高值化学品(如1,3-丙二醇、氨基酸、生物燃料)。
2. 范式转型
o传统模式:随机诱变+高通量筛选(低效、不可预测)。
o理性设计:基于基因组尺度模型 + 代谢通量分析 + AI预测(精准、可复现)。
3. 发展历程
o天然发酵(酿酒酵母产乙醇)→ 代谢工程(大肠杆菌产乳酸)→ AI驱动设计(AlphaFold辅助酶结构预测,优化限速步骤)。
4. 核心挑战
o鲁棒性:抗渗透压、高温、产物毒性(如1,3-丙二醇抑制生长)。
o效率:产物得率,需突破热力学极限。
o原料多样性:利用农业废弃物(如秸秆水解液)替代葡萄糖,降低碳源成本。
二、物质流-能量流-信息流协同设计
1. 热力学驱动:ATP/NADH平衡
o产物合成需消耗还原力(如NADPH用于脂肪酸合成)或产生还原力(如1,3-丙二醇生成消耗NADH)。
o策略:引入NADH再生系统(如甲酸脱氢酶)或切换碳源(甘油 vs 葡萄糖)调控辅因子比例。
2. 动力学驱动:酶活性调控
o限速酶(如AroE、DhaT)表达量不足导致通量瓶颈。
o优化方法:使用NCS文库(N端编码序列)精细调控翻译效率,提升酶活性3–8倍。
3. 代谢网络重构:通量平衡分析(FBA)
o原理:基于质量守恒与反应约束,求解最大生物量或产物产量的代谢流分布。
4. 案例:碳-氮比调控谷氨酸棒杆菌产谷氨酸
o高碳氮比(>20:1)激活谷氨酸脱氢酶,抑制TCA循环,使α-酮戊二酸积累并转化为谷氨酸。
三、底盘细胞开发策略
1. 设计原则
o鲁棒性底盘:引入热休克蛋白(如GroEL/ES)增强耐热性,提升高温发酵稳定性。
o稳定性底盘:基因组简化(删除非必需基因如 prophage、转座子),减少代谢负担与基因组不稳定性。
2. 技术方法
o智能抗逆元件:构建温度响应型启动子,在37°C以上激活抗逆基因表达。
o无诱导表达系统:利用组成型强启动子替代IPTG诱导,降低生产成本。
3. 案例:枯草芽孢杆菌底盘改造
o目标产物:N-乙酰神经氨酸(Neu5Ac)
o改造策略:
§引入唾液酸合成途径(neuA, neuB, neuC)
§构建NCS文库优化关键酶表达(GFP荧光强度提升8.47倍)
§删除竞争途径(如glcA)减少副产物
五、 合成生物学中高通量筛选技术
1、主题:传统高通量筛选技术
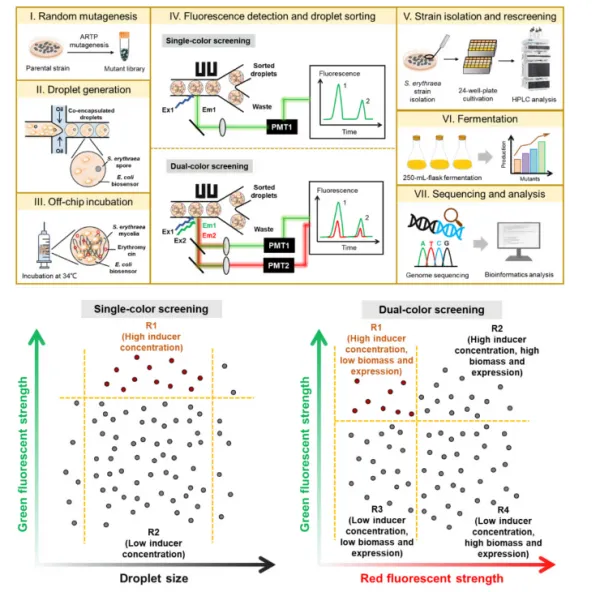
一、传统高通量筛选技术体系
1. 三大技术支柱
o机器人自动化系统:通过协作机器人(如Explorer G3)实现96/384孔板的自动加样、温孵与转移,日处理通量可达10⁵–10⁶样品。
o液体处理器:精准控制纳升–微升级液体分配(误差<2%),支持混合、稀释、分液一体化,消除人为操作偏差。
o检测系统:
§荧光检测:报告基因(GFP、LacZ)用于基因表达水平量化;
§细胞增殖检测:MTT/Resazurin法评估细胞代谢活性;
§离子通道筛选:膜片钳自动化平台检测神经靶点化合物活性。
2. 数据处理流程
o原始数据:荧光强度、吸光度、成像特征
o标准化:Z’因子评估(Z’>0.5为合格)
o分析工具:GraphPad Prism、Python(pandas + scikit-learn)进行剂量响应曲线拟合与Hit筛选。
3. 案例
o报告基因筛选:构建“GFP-乳糖操纵子”大肠杆菌库,用荧光酶标仪筛选强启动子变体。
二、微流控与液滴微流控技术
1. 技术原理
o微流控芯片:通过光刻/软光刻技术在PDMS芯片中构建微通道网络,集成样品制备、反应、分选、检测单元(尺寸<2 cm²)。
o液滴微流控:利用油水两相流生成皮升级(pL)单分散液滴,作为独立微反应器,实现:
§单细胞包裹与恒化培养
§酶基因表达产物的高通量筛选
§细胞裂解与代谢物捕获
2. 通量优势
o传统:10³–10⁴样品/天
o液滴系统:10⁵–10⁶液滴/小时(DropAI系统实测)
3. 实验设计
o非标记荧光分选:利用微生物自发荧光(NADH/FAD)检测生长速率,分选“高产”菌株。
o荧光编码系统:FluoreCode技术,通过不同荧光强度组合编码液滴组分,实现百万级组合并行筛选。
三、拉曼光谱在代谢物高通量筛选中的应用
1. 原理与优势
o拉曼散射:激光激发分子振动模式,产生特征“指纹光谱”,无需标记即可检测:
§脂肪酸(C-H伸缩峰:2850 cm⁻¹)
§聚羟基脂肪酸酯(PHAs,1240 cm⁻¹)
§蛋白质二级结构(Amide I, 1650 cm⁻¹)
o无损、快速、单细胞级:单细胞光谱采集<1秒,适用于活细胞动态监测。
2. 操作流程
o样品准备:细胞悬液滴于硅基片或微流控出口
o光谱采集:使用532 nm或785 nm激光,积分时间1–10 s
o数据分析:
§主成分分析(PCA)区分细胞表型
§支持向量机(SVM)分类高产/低产菌株
3. 应用
o油脂生产菌筛选:对产油酵母(如Yarrowia lipolytica)进行拉曼成像,识别高脂含量单细胞。
o液滴-拉曼联用:SERS增强基底嵌入微流控芯片,实现“生成-检测-分选”一体化。
4. 技术瓶颈
o信号弱(需SERS增强)
o数据维度高(>1000波数点/光谱),需AI降维分析
四、AI驱动的高通量筛选闭环
1. DBTL循环升级
oDesign:AI预测酶结构(AlphaFold)→ 优化催化位点
oBuild:自动化合成基因库(CRISPR-Cas9 + Golden Gate)
oTest:液滴微流控 + 拉曼/荧光检测 → 生成百万级表型数据
oLearn:机器学习模型(XGBoost、神经网络)训练预测模型,反向优化设计
2. 工业级平台案例
oSynGears™平台:AI驱动的“数字基座”,整合基因设计、通路模拟与筛选数据,实现“设计即优化”。




一、pymol的使用与一般蛋白-配体分子对接
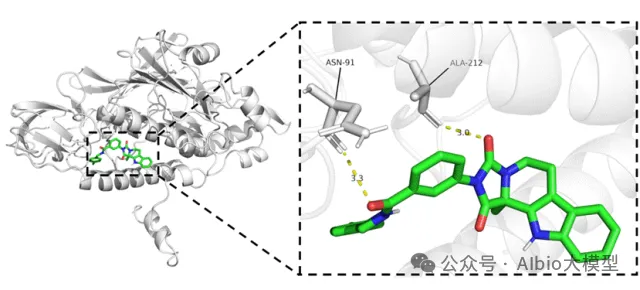

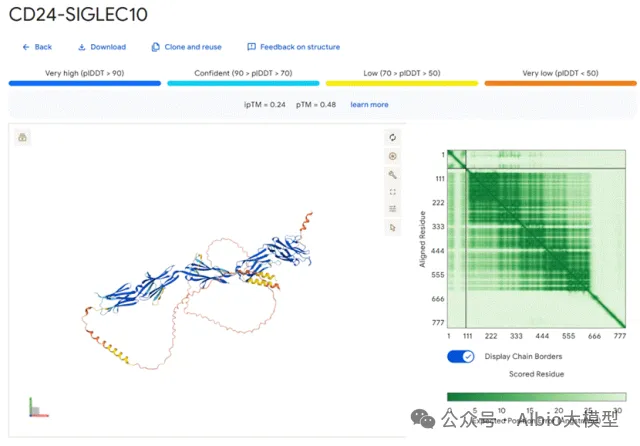
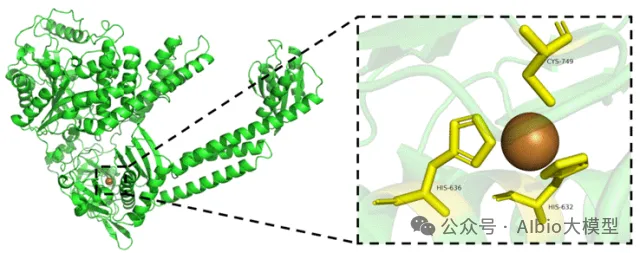
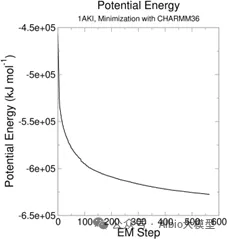
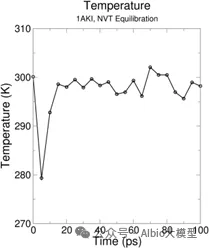
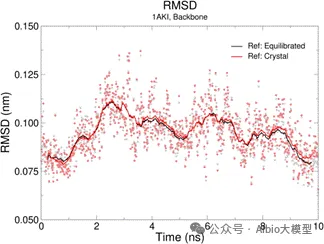
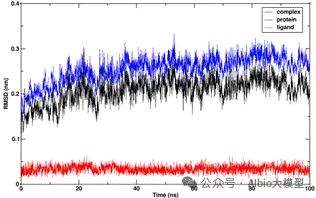
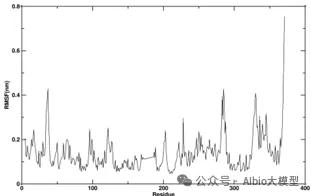
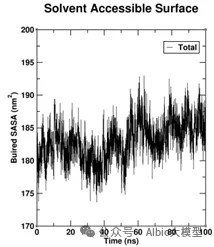
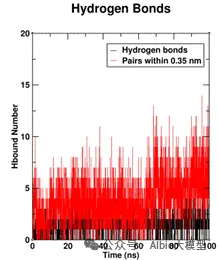
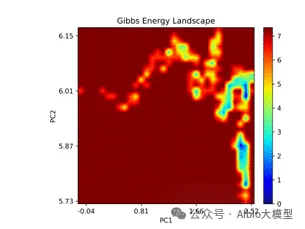


1.AIDD概述及药物综合数据库介绍
2.人工智能辅助药物设计AIDD概述
3.安装环境
(1)anaconda
(2)vscode
(3)pycharm
(4)虚拟环境
4.第三方库基本使用方法
(1)numpy
(2)pandas
(3)matplotlib
(4)requests
5.多种药物综合数据库的获取方式
(1)KEGG(requests爬虫)
(2)Chebi(libChEBIpy)
(3)PubChem(pubchempy / requests)
(4)ChEMBL(chembl_webresource_client)
(5)BiGG(curl)
(6)PDB(pypdb)
二、 ML-based AIDD
1.机器学习
(1)机器学习种类:
①监督学习
②无监督学习
③强化学习
(2)典型机器学习方法
①决策树
②支持向量机
③朴素贝叶斯
④神经网络
⑤卷积神经网络
(3)模型的评估与验证
(4)分类评估:准确率、精确率、召回率、F1分数、ROC曲线、AUC计算
(5)回归评估:平均绝对误差、均方差、R2分数、可释方差分数
(6)交叉验证
2.sklearn工具包基本使用
3.rdkit工具包的基本使用
4.化合物编码方式和化合物相似性理论知识
5.项目实战1:基于ADME和Ro5的分子筛选
6.项目实战2:基于化合物相似性的配体筛选
7.项目实战3:基于化合物相似性的分子聚类
8.项目实战4: 基于机器学习的生物活性预测
9.项目实战5:基于机器学习的分子毒性预测
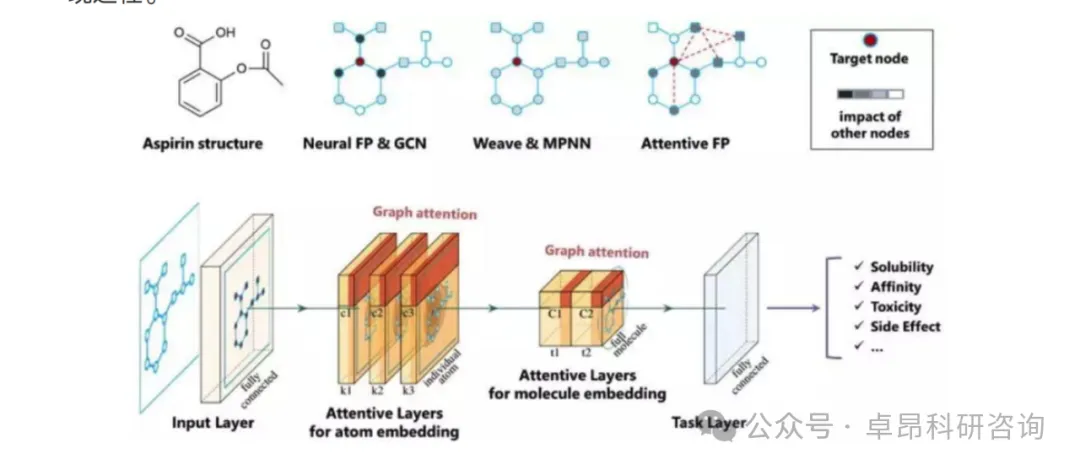
三、 GNN-based AIDD
1.图神经网络
(1)框架介绍: PyG,DGL,TorchDrug
(2)图神经网络消息传递机制
(3)图神经网络数据集设计
(4)图神经网络节点预测、图预测任务和边预测任务实战
2.论文精讲:DeepTox: Toxicity Prediction using Deep Learning
3.项目实战1:基于图神经网络的分子毒性预测
(1)SMILES分子数据集构建PyG图数据集
(2)基于GNN进行分子毒性预测
4.项目实战2:基于图神经网络的蛋白质-配体相互作用预测
(1)蛋白质分子图形化,构建PyG图数据集
(2)基于GIN进行网络搭建及相互作用预测
四、 NLP-based AIDD
1.自然语言处理
(1)Encoder-Decoder模型
(2)循环神经网络 RNN
(3)Seq2seq
(4)Attention
(5)Transformer
2.项目实战1:基于自然语言的分子毒性预测
(1)SMILES分子数据集词向量表示方法
(2)基于NLP模型进行分子毒性预测
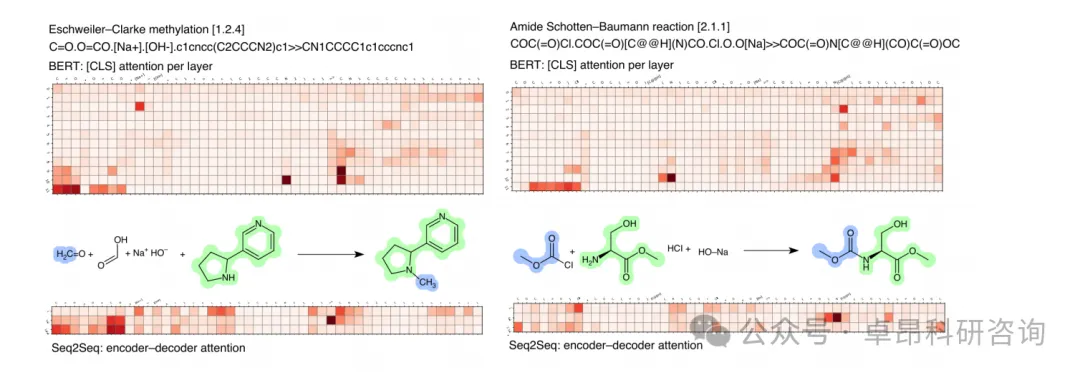
3.项目实战2:基于Transformer的有机化学反应产量预测 (Prediction of chemical reaction yields using deep learning)
4.论文精读及代码讲解:《Mapping the space of chemical reactions using attention-based neural networks》
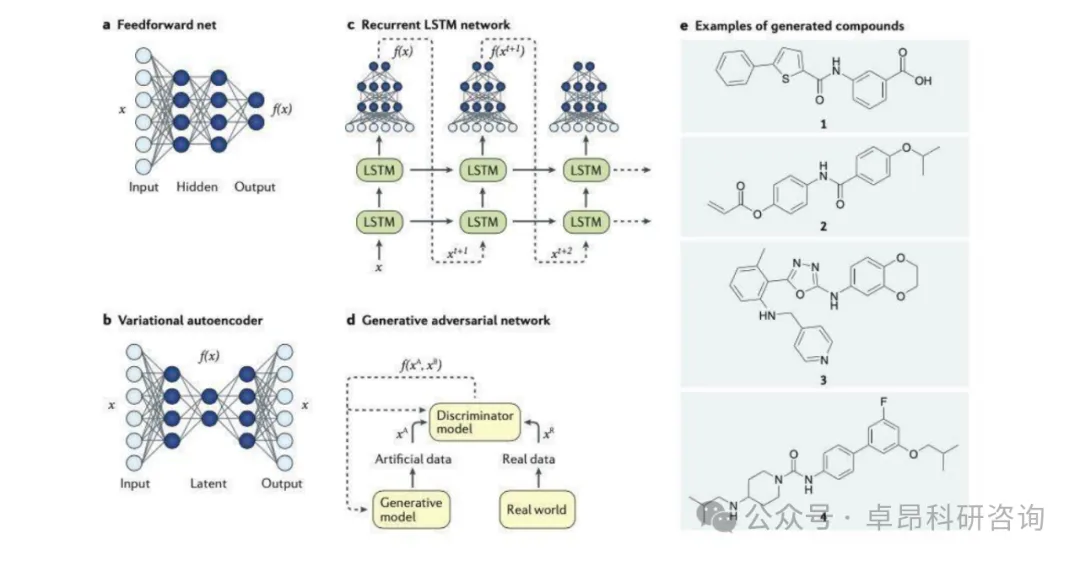
五、分子生成与药物设计
1.分子生成模型
(1)循环神经网络RNN
(2)变分自动编码器VAE
(3)生成对抗网络GAN
(4)强化学习RL
2.项目实战1: 基于图数据的小分子化合物生成模型《A Graph to Graphs Framework for Retrosynthesis Prediction》
3.项目实战2: 基于NLP的抗体生成模型《Generative language modeling for antibody design》


1.AIDD概述:从CADD到AIDD
2.软件安装与环境搭建
(1)anaconda
(2)vscode
(3)环境变量的配置
(4)切换pip和conda镜像源
(5)虚拟环境的创建
3.RDKIT工具包的使用
(1)基于RDKit的分子读写
(2)基于RDKit的分子绘制
(3)基于RDKit的分子指纹与分子描述符
(4)基于RDKit的化合物相似性与子结构
4.药物综合数据库的获取方法
(1)基于requests的基本爬虫操作
(2)小分子数据库PubChem数据获取(pubchempy / requests)
(3)蛋白质数据库PDB、UniProt数据获取
5.深度学习辅助药物设计
(1)神经网络基本概念与sklearn工具包介绍
(2)图神经网络与消息传递机制基本知识
(3)Transformer模型基本知识:分词、位置编码、注意力机制、编码器、解码器、预训练–微调框架、huggingface 生态介绍
(4)模型的评估与验证:准确率、精确率、召回率、F1分数、ROC曲线、AUC计算,平均绝对误差、均方差、R2分数、可释方差分数,交叉验证等
培训内容2:TOP期刊|基于深度学习的生化反应产量预测《Prediction of chemical reaction yields using deep learning》
1.数据。研究使用了三类数据:
1.1.Buchwald-Hartwig HTE数据集:包含3955个Pd催化C-N偶联反应,涵盖15种卤化物、4种配体、3种碱和23种添加剂组合,产率通过统一实验测量,数据质量高。
1.2.Suzuki-Miyaura HTE数据集:包含5760个反应,涉及15对亲电/亲核试剂、12种配体、8种碱和4种溶剂的组合,产率分布均匀。
1.3.USPTO专利数据集:从公开专利中提取,包含不同规模(克级与亚克级)的反应产率,数据噪声大且分布不一致,需通过邻近反应产率平滑处理以提升模型表现。
2.模型。核心模型基于预训练的rxnfp(反应指纹)BERT架构,新增回归层构成Yield-BERT。输入为标准化反应SMILES,通过自注意力机制捕捉反应中心及关键试剂的上下文信息。模型无需手工特征(如DFT计算描述符),直接端到端预测产率。实验表明,其性能优于传统方法(如随机森林和分子指纹拼接),尤其在HTE数据上接近化学描述符的预测水平,且参数鲁棒性高(超参数调整影响小)。
3.训练。训练分为两步:
3.1.预训练:BERT通过掩码语言任务学习SMILES的通用表示。
3.2.微调:采用简单Transformers库和PyTorch框架,以MSE损失优化回归层,学习率(2×10⁻⁵)和dropout率(0.1–0.8)为主要调参对象。HTE数据采用随机/时间划分验证,USPTO数据通过邻近反应产率平滑缓解噪声影响。小样本实验(5%训练数据)显示模型能快速筛选高产反应,指导合成优化。
培训内容3:
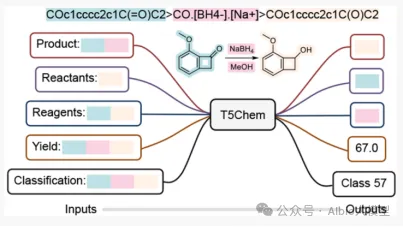
TOP期刊|基于T5Chem模型的生化反应表示学习与性质预测: 《Unified Deep Learning Model for Multitask Reaction Predictions with Explanation》
1.数据来源和处理。通过自监督预训练与PubChem分子数据集进行训练,以实现对四种不同类型的化学反应预测任务的优异性能。模型处理包括反应类型分类、正向反应预测、单步逆合成和反应产率预测。
2.模型架构和原理。T5Chem模型是基于自然语言处理中的“Text-to-Text Transfer Transformer”(T5)框架开发的统一深度学习模型,该模型通过适应T5框架来处理多种化学反应预测任务。T5Chem模型包含编码器–解码器结构,并根据任务类型引入了任务特定的提示和不同的输出层,如分子生成头、分类头和回归头,以处理序列到序列的任务、反应类型分类和产品产率预测。
3.训练过程和细节。
3.1.T5Chem模型首先在PubChem的97 million分子上进行自监督预训练,使用BERT类似的“masked language modeling”目标。
3.2.在预训练阶段,源序列中的tokens被随机掩蔽,模型的目标是预测被掩蔽的正确的tokens。
3.3.预训练完成后,模型在下游的监督任务中进行微调,使用不同的任务特定提示和输出层。
3.4.模型在测试阶段通过生成分子token by token的方式进行预测,直到生成“句子结束标记”或达到最大预测长度。
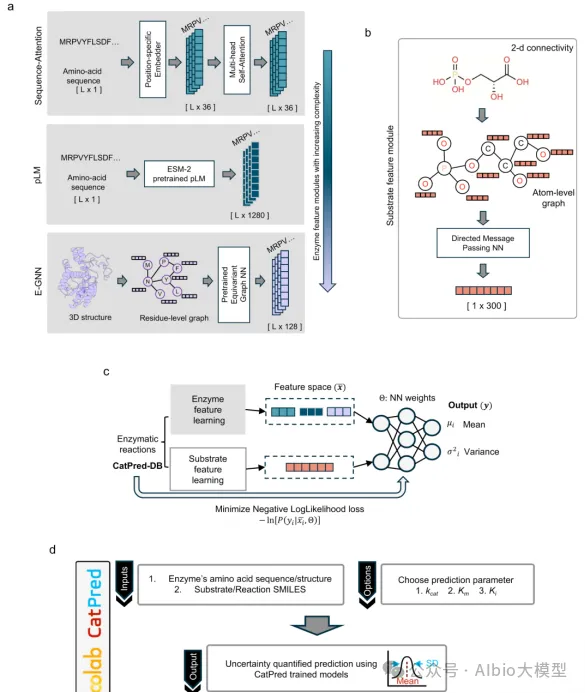
培训内容1:
Nature Communication|体外酶动力学参数深度学习的综合框架《CatPred: a comprehensive framework for deep learning in vitro enzyme kinetic parameters》
CatPred 提出了一种全面的深度学习框架,用于预测体外酶动力学参数(kcat、Km、Ki),以解决实验测定成本高、数据稀疏和泛化能力差的问题。该方法不仅提供了准确的预测,还引入了对预测不确定性的量化,支持对训练集外(out-of-distribution)酶序列的稳健预测。此外,作者还构建了新的标准化数据集(CatPred-DB),并对多种酶表示方法进行了系统比较。
1.数据:CatPred 使用的数据集来自 BRENDA 和 SABIO-RK 数据库,作者构建了 CatPred-DB,包括:23197 条 kcat,41174 条 Km和11929 条 Ki 数据,每条记录都包含酶的氨基酸序列、AlphaFold 或 ESMFold 预测的结构、底物的 SMILES 表达式。数据经过清洗和标准化处理,去除缺失值和重复值,并对参数取对数转换以符合正态分布。
2.模型:CatPred 采用模块化设计,酶和底物分别通过不同的神经网络模块进行表征学习,并采用 概率回归 输出(高斯分布形式的均值和方差),允许进行 不确定性估计(aleatoric + epistemic)。
3.训练
3.1.所有模型采用负对数似然损失函数(NLL)训练,以同时预测参数均值和不确定性。
3.2.使用训练–验证–测试三分法(80%-10%-10%),并设立“训练集外”的测试子集用于泛化能力评估。
3.3.为了评估不确定性,CatPred 使用 10个模型的集成,通过不同初始参数训练,以此量化 epistemic uncertainty。
3.4.模型训练时考虑了不同相似性(序列identity<99%、80%、60%、40%)的测试集,体现其鲁棒性。
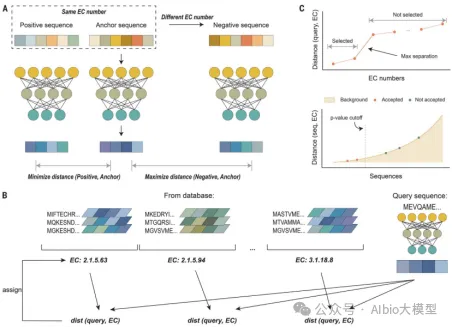
培训内容2:
Science|基于对比学习的蛋白质分类属性预测《Enzyme function prediction using contrastive learning》
1.数据来源和处理: CLEAN模型的训练基于UniProt数据库中的高质量数据,该数据库收录了约1.9亿个蛋白质序列。CLEAN模型以氨基酸序列作为输入,输出按可能性排序的酶功能列表(以EC编号为例)。为了验证CLEAN的准确性和鲁棒性,作者进行了广泛的in silico实验,并将CLEAN应用于内部收集的未表征的卤酶数据库(共36个)进行EC编号注释,随后通过案例研究进行体外实验验证。
2.模型架构和原理: CLEAN模型采用了对比学习框架,目标是学习一个酶的嵌入空间,其中欧几里得距离反映了功能相似性。嵌入是指蛋白质序列的数值表示,它由机器可读,同时保留了酶携带的重要特征和信息。在CLEAN的任务中,具有相同EC编号的氨基酸序列具有较小的欧几里得距离,而具有不同EC编号的序列则具有较大的距离。
3.训练过程和细节:
3.1.在训练过程中,CLEAN模型使用对比损失函数进行监督训练,通过优先选择与锚点(anchor)嵌入具有小欧几里得距离的负序列,以提高训练效率。
3.2.模型使用语言模型ESM1b获得的蛋白质表示作为前馈神经网络的输入,输出层产生细化的、功能感知的输入蛋白质嵌入。
3.3.预测时,通过计算查询序列与所有EC编号聚类中心之间的成对距离来预测输入蛋白质的EC编号。
3.4.CLEAN还开发了两种方法来从输出排名中预测自信的EC编号:一种是贪婪方法,另一种是基于P值的方法。
培训内容1:
Nature Communication|基于端到端的图生成框架的分子生成:《Retrosynthesis prediction using an end-to-end graph generative architecture for molecular graph editing》
1.数据来源和处理:Graph2Edits模型使用了公开可用的基准数据集USPTO-50k,包含50016个反应,这些反应被正确地原子映射并分类为10种不同的反应类型。数据集被分为40k、5k、5k的反应用于训练、验证和测试集。
2.模型架构和原理:Graph2Edits模型是一个端到端的图生成架构,基于图神经网络(GNN)预测产品图的编辑序列,并根据预测的编辑序列顺序生成中间体和最终反应物。该模型将半模板方法的两阶段过程(识别反应中心和完成合成子)合并为一锅学习,提高了在复杂反应中的适用性,并使预测结果更易于解释。模型的核心是图编码器和自回归模型,用于生成编辑序列,并应用这些编辑来推断中间体和反应物。
3.训练过程和细节:
3.1.Graph2Edits模型使用有向消息传递神经网络(D-MPNN)作为图编码器,以获取原子表示和全局图特征,并预测原子/键编辑和终止符号。
3.2.模型训练使用教师强制策略,即使用真实的编辑序列作为模型输入。在每个编辑步骤中,模型会计算所有可能的编辑的概率,并选择最高分的k个编辑,将这些编辑应用于输入图以获得k个中间体。
3.3.在生成过程中,如果达到最大步骤数或图表示指示终止,则生成分支将停止。
3.4.最终,根据可能性对前k个编辑序列和图进行排名,收集为最终预测结果。
培训内容2
Nature Computational Science|基于等变扩散模型的分子生成网络《Structure-based drug design with equivariant diffusion models》
1.简单介绍。这篇文献提出了一种基于结构的药物设计方法(SBDD),利用SE(3)-等变扩散模型(DiffSBDD)生成与蛋白质结合口条件匹配的新颖小分子配体。该方法通过将SBDD问题建模为三维条件生成任务,能够一次性生成所有原子位置,克服了传统自回归方法因顺序生成而丢失全局上下文的局限性。DiffSBDD不仅支持从头分子设计,还能通过属性优化、负向设计和分子局部修饰(inpainting)等多种任务灵活应用。
2.数据总结。该研究使用了CrossDocked和Binding MOAD两个数据集进行训练和评估。
2.1.CrossDocked数据集包含40,344个训练蛋白–配体对和130个测试对,验证集规模为246个,确保不同集合中的蛋白质来自不同的酶分类主类以避免过拟合。
2.2.Binding MOAD数据集经过筛选后用于测试,分析限于所有方法均能生成样本的78个CrossDocked和119个Binding MOAD目标。此外,数据集处理涉及移除损坏条目,并通过Zenodo公开提供处理后的数据和采样分子,确保研究可重复性。
3.模型总结。DiffSBDD是一个SE(3)-等变扩散模型,以蛋白质结合口为条件生成三维分子结构,采用3D图表示(原子坐标和类型),避免了传统方法中从密度图回推分子结构的复杂后处理。模型设计尊重三维空间的旋转和平
培训内容1:
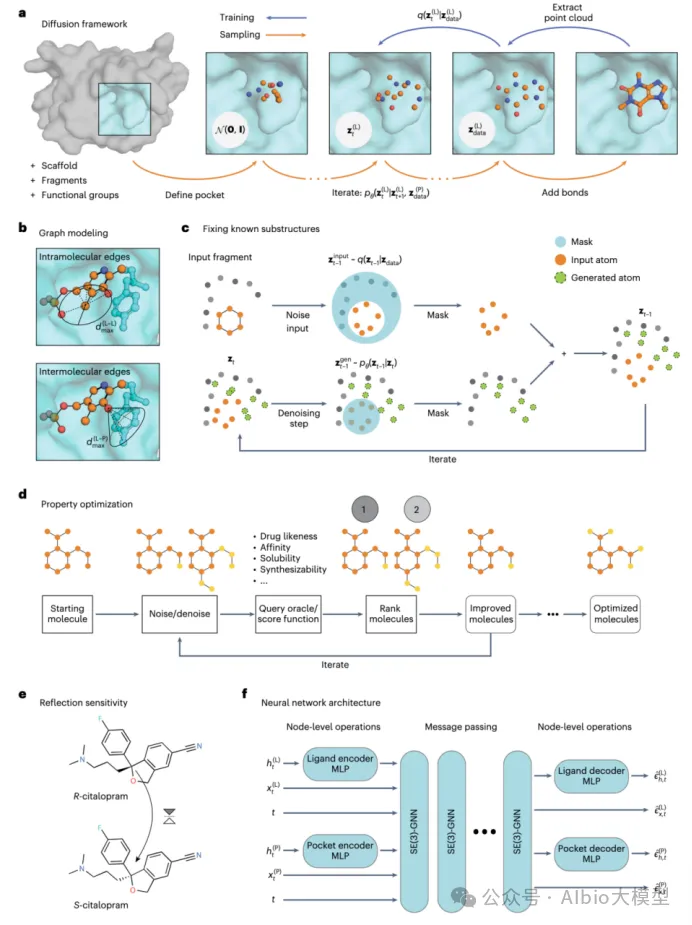
Nature Communication|交互作用感知的蛋白质–配体对接和亲和力预测模型《Interformer: an interaction-aware model for protein-ligand docking and affinity prediction》
1.简要介绍:本研究提出了一种名为Interformer的基于Graph-Transformer架构的统一模型,用于蛋白–配体对接和亲和力预测。针对现有深度学习模型忽略蛋白与配体原子间非共价相互作用建模的不足,Interformer引入了交互感知混合密度网络(MDN)来明确捕捉氢键和疏水相互作用,并结合负采样策略和伪Huber损失函数,通过对比学习优化相互作用分布,提升对接姿势的准确性和亲和力预测的鲁棒性。
2.数据集:研究使用了PDBBind时间分割测试集(333个样本)评估对接准确性,Posebusters基准测试验证物理合理性,以及内部真实世界数据集测试泛化能力。训练数据来源于PDBBind晶体结构数据库。
3.模型:Interformer基于Graph-Transformer架构,包括:(1) 图表示模块,将原子作为节点、邻近关系作为边;(2) 掩码自注意力(MSA)机制,通过Intra-Blocks和Inter-Blocks分别捕捉配体/蛋白内部及两者间的相互作用;(3) 交互感知MDN,融合四种高斯分布模拟常规力、疏水作用和氢键;(4) 边缘输出层整合节点和边特征预测能量;(5) 姿势评分和亲和力模块基于虚拟节点预测正确姿势和实验亲和力值。
4.训练细节:训练分两阶段:首先基于晶体结构训练能量模型生成负样本,随后联合正负样本训练姿势评分和亲和力模型。采用负对数似然损失优化MDN,二元交叉熵损失优化姿势评分,伪Huber损失(σ=4)优化亲和力预测(单位IC50、Kd、KI,经负对数归一化)。蒙特卡洛采样生成候选姿势,
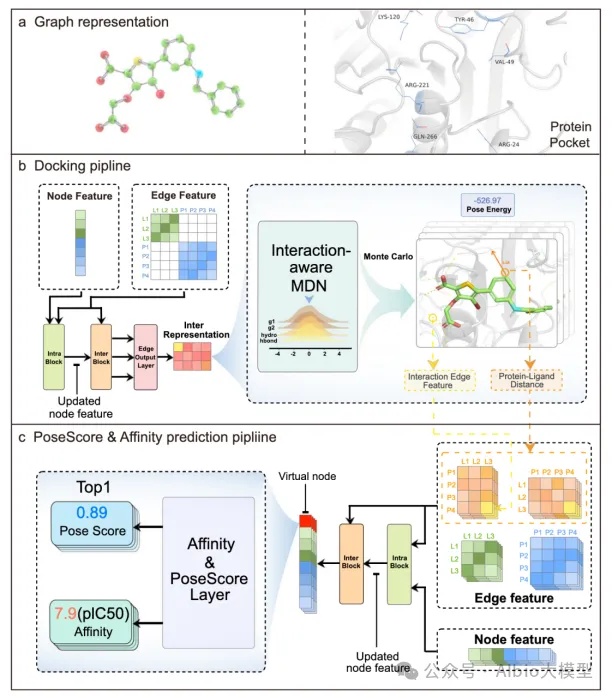
研究内容2:
Nature Communication|分子动力学驱动的蛋白质–配体复合物结构动态预测《DynamicBind: predicting ligand-specific protein-ligand complex structure with a deep equivariant generative model》
1.简单介绍:本研究提出了一种名为DynamicBind的深度学习方法,用于预测配体特异性的蛋白–配体复合物结构。传统分子对接方法通常将蛋白视为刚性或仅部分柔性,难以处理蛋白的大尺度构象变化,而分子动力学模拟虽然能捕捉动态构象,但计算成本高昂。DynamicBind通过等变几何扩散网络构建平滑的能量景观,高效模拟蛋白从无配体(apo)状态到配体结合(holo)状态的构象转变,无需依赖holo结构或大量采样。
2.数据集:研究基于PDBbind2020数据库(19,443个蛋白–配体复合物晶体结构),按时间划分:2019年前的数据用于训练和验证,2019年的数据用于测试。额外构建了Major Drug Targets (MDT)测试集(599对),聚焦激酶、GPCR等主要药物靶点,要求AlphaFold预测结构与晶体结构的pocket RMSD>2Å,确保测试难度。训练中通过AlphaFold预测结构与晶体结构插值生成蛋白部分的样本。
3.模型:DynamicBind是一个基于图神经网络的等变生成模型,使用粗粒化表示(蛋白以Cα节点和侧链二面角表示,配体以重原子节点表示),输出包括蛋白和配体的平移、旋转、扭转角更新,以及结合亲和力和cLDDT置信度评分。模型通过学习从apo到holo的“morph-like”变换,优化能量景观,包含63.67百万参数。
4.训练细节:训练在8块Nvidia A100 80GB GPU上进行5天,输入为添加morph变换的蛋白decoy构象和加高斯噪声的配体构象,目标是去噪操作。损失函数包括八项(配体和蛋白的平移、旋转、扭转等),通过Kabsch算法对齐apo和holo结构,结合扩散噪声调整构象过渡。推理时迭代20次更新初始结构。


第一天上午OpenClaw云端部署与运行环境搭建
本部分面向零基础或弱运维背景学员,介绍OpenClaw部署所需的最小环境与推荐配置,帮助学员建立“能够稳定跑起来”的基础条件。
1.服务器设备:
• 服务器系统要求:Ubuntu20.04+/Debian11+;
• 基础硬件配置建议:2核4GB起步,结合实际科研场景讨论何时需要更高配置;
• 云平台推荐:阿里云、腾讯云、AWS、GoogleCloud等;
• 网络准备:弹性IP、安全组端口开放(如SSH、WebUI端口等);
• 域名与访问方式:域名解析、DDNS与公网访问的基本思路;
• 科研团队实际部署建议:个人测试环境、实验室共享环境、长期在线服务环境的区别。
2.本地开发与连接环境准备
介绍部署前需要准备的本地工具链,确保学员具备最基本的连接和维护能力:
• Node.js安装与版本管理;
• nvm的使用方法;
• Git与SSH密钥配置;
• Docker作为可选隔离环境的使用场景;
• 本地终端连接远程服务器的方法与注意事项。
3.OpenClaw核心安装与初始化
带领学员完成OpenClaw的核心安装,并理解安装过程中的关键配置项:
• OpenClaw安装流程;
• 依赖检查与常见环境问题;
• 账户登录与认证;
• onboard初始化配置;
• 语言、时区、消息渠道等基础设置;
• WebUI的访问方式与账号设置。
4.Gateway启动、调试与验收
本部分强调装完能跑、跑了能查、出错能修的实际能力建设:
• 前台与后台启动方式;
• systemd服务化管理;
• 配置文件位置与修改方法;
• 端口映射与远程访问;
• 日志查看与状态检查;
• 常见问题排查:端口冲突、网络不通、认证失败、权限异常等;
• 最终完成安装验收与答疑。
第一天下午OpenClaw架构与Skill编写
1.OpenClaw整体架构解析
• Runtime:负责消息流转与运行时调度;
• Gateway:承担Web服务与接口网关功能;
• Skills:扩展OpenClaw能力的关键模块;
• Tools:底层工具调用能力;
• Memory:上下文与长期记忆管理机制;
• 配置文件与目录结构:包括config.yaml、skills/、memory/等组织方式。
2.Skill机制与目录结构
• 什么是Skill;
• Skill与一般脚本、插件、API封装的区别;
• Skill的典型组成:SKILL.md+代码+配置;
• 一个Skill是如何被识别、触发和调用的;
• 如何设计“可复用”的科研Skill,而不是一次性脚本。
3.Skill编写入门
• 第一个Skill示例;
• 消息输入与响应逻辑;
• 触发机制设计:关键词、正则、语义触发;
• 调用内置Tools与第三方API;
• 密钥与认证信息管理;
• 输出结果的组织方式:文本、结构化数据、图片、卡片等。
4.小练习:完成第一个科研Skill
• 文献助手:输入DOI返回论文基本信息;
• 单位换算:实现温度、压力、浓度等科研常用单位转换;
• 期刊查询:输入期刊名称返回影响因子或基本信息。
练习内容包括:
• 创建Skill目录;
• 编写SKILL.md;
• 完成核心逻辑;
• 本地测试与效果验证。
第二天上午 面向科研场景的Skills设计
1.科研场景拆解:从通用智能体到科研专用助手
本部分是课程的核心之一。课程将围绕科研日常工作的真实任务,把OpenClaw的能力映射到可落地的科研场景中,帮助学员理解:科研自动化不是抽象概念,而是一个个具体任务的组合。
2.文献与知识类Skills
围绕科研中最常见的信息处理需求,介绍如何构建文献与知识管理类Skills:
• 文献检索:arXiv、PubMed、Crossref、DOI、SemanticScholar等;
• 文献元数据整理:作者、机构、关键词、引用信息抽取;
• 文献阅读辅助:PDF解析、关键信息提取、摘要生成、跨语言翻译;
• 知识沉淀:飞书Wiki、Notion、本地Markdown文档等知识库集成。
现场演示一个典型案例:
“输入DOI,自动检索并总结论文内容”的Skill设计与实现思路。
3.计算流程类Skills
围绕计算生物与计算化学中的高频任务,介绍如何用Skill封装常用科研工具:
3.1计算化学方向
• 分子对接任务封装(如AutoDockVina);
• 分子动力学任务提交(如GROMACS);
• 量子化学计算任务管理(如Gaussian);
• 参数输入、任务脚本生成、结果回传的基本模式。
3.2生物信息方向
• 序列分析任务(如BLAST、Clustal);
• 数据表处理与自动分析;
• 结果提取与结构化输出。
3.3机器学习方向
• 模型训练任务封装;
• 参数管理与自动调参;
• 训练结果统计;
• 图表生成与可视化输出。
4.项目管理与协作类Skills
• 待办事项创建与提醒;
• 里程碑与进度追踪;
• 日历与会议提醒;
• 会议纪要自动生成;
• 文件同步与归档;
• Git操作辅助;
• 仪器预约、库存管理、数据备份等实验室事务支持。
第二天下午 科研工作流设计与原型搭建
1.工作流设计原理
在学员理解Skill之后,课程进一步上升到工作流层面,帮助大家从单个功能模块走向多步骤自动化协作。
重点包括:
• 何时调用Skill,何时调用Tool;
• 用户意图识别与能力匹配;
• 结果的结构化组织方式;
• 单轮任务与多轮任务的区别;
• 后台长任务与异步通知思路;
• 错误处理与异常反馈机制。
同时介绍科研场景中推荐的结构化输出格式,例如:
• 状态信息;
• 数据主体;
• 下一步建议;
• 日志与执行记录。
2.工作流拆解方法
通过具体案例,讲解如何从“一个模糊需求”拆解成可执行的工作流。
拆解路径包括:
1. 明确目标与最终产出;
2. 细化步骤与前后依赖;
3. 确定每一步所需Skill或Tool;
4. 设计输入与交互方式;
5. 规划错误处理与回退逻辑。
示例流程包括:
• 文献检索;
• 高质量论文筛选;
• 摘要获取与解析;
• 自动总结;
• Markdown报告输出。
3.典型科研工作流设计
最后进入最具实战价值的部分,围绕生物医药计算方向给出三类代表性工作流原型:
案例一:化合物虚拟筛选工作流
输入:靶点蛋白+化合物库
流程:分子对接→结果排序→可视化→报告生成
工具组合:AutoDockVina+PyMOL+消息通知
案例二:文献追踪与自动摘要工作流
输入:研究兴趣关键词
流程:定时检索→新论文筛选→自动摘要→飞书推送
工具组合:arXiv/PubMedAPI+大模型总结+飞书消息
案例三:计算任务管理工作流
输入:计算参数+邮箱/消息渠道
流程:任务提交→队列监控→结果下载→通知反馈
工具组合:SSH+Slurm/Gaussian+文件传输+邮件/飞书通知
两天结束后,你能独立做什么
|
能力 |
具体描述 |
|
独立安装和部署 |
能从零开始,在云服务器或本地Linux/Mac环境中完成OpenClaw的安装、配置、启动与基础维护,让系统稳定运行起来 |
|
独立完成环境配置 |
能配置模型接口、渠道接入、基础参数、运行目录与依赖环境,具备基本的部署排错和日志查看能力 |
|
理解系统架构 |
能理解OpenClaw的核心组成,包括Runtime、Gateway、Skills、Tools、Memory等模块的作用及协同关系 |
|
编写基础Skill |
能根据具体任务需求,编写结构清晰、可调用的基础Skill,实现输入解析、任务触发、结果返回等流程 |
|
封装科研工具 |
能把常用Python脚本、命令行程序或第三方API封装成Agent可调用的工具,服务实际科研任务 |
|
设计Agent行为 |
能根据业务或科研需求,编写有效的配置文件与规则说明,定义Agent的角色、边界、调用习惯与输出风格 |
|
管理记忆与知识 |
能完成结构化信息的写入、检索与调用,理解记忆系统在多轮对话和任务连续性中的作用 |
|
平台接入与集成 |
能将Agent接入飞书、钉钉等常用协作平台,实现消息收发、卡片交互和基础自动回复 |
|
构建科研专用助手 |
能围绕文献检索、数据整理、实验记录、结果汇总、任务提醒等场景,搭建面向科研工作的专用Agent |
|
搭建自动化工作流 |
能把多个Skill和Tool串联起来,设计多步骤工作流,实现“输入任务—自动执行—输出结果”的流程闭环 |
|
多Agent协同设计 |
能初步设计多个Agent分工协作的任务机制,用于处理较复杂的科研或业务流程 |






01、AI蛋白质设计
02、AI蛋白质设计(前沿、进阶)
主讲老师在学术界和工业界都有丰富算法开发和应用经验,博士毕业于国内顶尖课题组,从事蛋白质结构预测和蛋白质设计的研究工作,相关工作成果已在Cell Systems、Angew. Chem. Int. Ed.、JCIM等国际知名期刊发表论文。目前在知名药企担任高级研究员,主导AI驱动的大分子药物设计平台开发与团队管理。
03、AI抗体设计
主讲老师在学术界和工业界都有丰富算法开发和应用经验,博士毕业于国内顶尖课题组,从事蛋白质结构预测和蛋白质设计的研究工作,相关工作成果已在Cell Systems、Angew. Chem. Int. Ed.、JCIM等国际知名期刊发表论文。目前在知名药企担任高级研究员,主导AI驱动的大分子药物设计平台开发与团队管理。
04、合成生物学与基因线路设计
主讲老师来自合成生物学专业顶尖双一流高校,主要从事合成生物学工具开发,基因电路设计与动态调控,高附加值天然产物化学品合成路径挖掘与高水平合成,精通大肠杆菌,酿酒酵母,毕赤酵母,解脂酵母等微生物细胞工厂的基因编辑和构建,具备完整的从上游菌株改造到下游放大生产的产业化经验,已经实现多个产品的产业化落地,在Metabolic Engineering,Bioresour Technol,Appl Microbiol Biotechnol,J Agric Food Chem,ACS Synthetic Biology等杂志共发表SCI文章16篇,申请发明专利8项
05、AI抗菌肽设计
主讲老师在学术界和工业界都有丰富算法开发和应用经验,来自南开大学院士课题组,从事AI抗菌肽设计和蛋白质设计的研究工作,相关工作成果已在New England、Plos one等国际知名期刊发。
06、CADD计算机辅助药物设计
主讲老师来自江南大学,从事CADD及分子模拟相关工作,积累了大量项目经验,涵盖靶点结构准备、虚拟筛选、分子对接、分子动力学模拟、结合能计算等完整流程。在此过程中,熟练掌握了多种主流药物设计与模拟工具,包括 AutoDock Vina、Schrödinger、GROMACS、AmberTools、AlphaFold3、RFdiffusion、ProteinMPNN 等,并具备扎实的 Python 编程与 Linux 系统操作能力,能够高效完成计算流程自动化与高性能并行计算。
07、AIDD药物设计
主讲老师来自天津大学,有十余年的计算机算法研究和程序设计经验。研究方向涉及深度学习药物发现,药物合成路径设计等。发表SCI高水平论文10篇,包括BMC Bioinformatics, Journal of Biomedical Informatics, International Journal of Molecular Sciences等知名期刊!讲课一致受到学员极高评价
08、AIDD药物设计进阶
主讲老师来自天津大学,有十余年的计算机算法研究和程序设计经验。研究方向涉及深度学习药物发现,药物合成路径设计等。发表SCI高水平论文10篇,包括BMC Bioinformatics, Journal of Biomedical Informatics, International Journal of Molecular Sciences等知名期刊!讲课一致受到学员极高评价
09、OpenClaw(龙虾)
主讲老师AI应用算法工程师,长期专注于大模型应用部署、Agent系统搭建、企业知识库接入、多平台协同与自动化流程设计,拥有丰富的一线项目实施与交付经验。曾参与多类智能助手、业务自动化平台与科研辅助系统的方案设计与落地,擅长将大模型能力与真实业务流程结合,快速构建可运行、可扩展、可维护的Agen

授课时间及地点



培训费用超值福利
课程报名费用:
AI蛋白质设计,AI蛋白质设计(前沿、进阶)、AI抗体设计直播课:
公费价:每人每班¥6380元 (含报名费、培训费、资料费、提供课后全程回放资料)
自费价:每人每班¥6080元 (含报名费、培训费、资料费、提供课后全程回放资料)
AI抗菌肽设计,CADD计算机辅助药物设计直播课,合成生物学与基因线路设计直播课:
公费价:每人每班¥5880元 (含报名费、培训费、资料费、提供课后全程回放资料)
自费价:每人每班¥5580元 (含报名费、培训费、资料费、提供课后全程回放资料)
AIDD药物设计录播与AIDD药物设计进阶录播:
重磅优惠:
特惠一:参加AI蛋白质设计培训可免费参加AI蛋白质设计(前沿、进阶)培训
特惠二:报二送一(同时报名两个班赠送一个学习班,赠送班任选)
两班同报:10880元
三班同报:14880元
四班同报:18880元
特惠一:24880元 (可免费学习一整年本单位举办的任意课程)
特惠二:28880元(可免费学习两整年本单位举办的任意课程)
报名直播课程可赠送往期课程回放
(报名一个直播课可以赠送两个回放)
(报名三个直播课赠送下面全部课程回放)
(可点击跳转详情链接):
回放五: 本课程为视频课!CRISPR-Cas9基因编辑培训!
回放六:本课程为视频课!蛋白质晶体结构解析培训!
证书办理:参加培训并通过考试的学员,可以申请获得工业和信息化部工业文化发展中心颁发的“工业强国建设素质素养提升尚工行动”岗位能力适应评测证书。名称为“人工智能开发高级工程师”该证书可在中心官网查询,可作为能力评价,考核和任职的重要依据。评测证书查询网址:www.miit-icdc.org(自愿申请,须另行缴纳考试费500元/人)



报名咨询方式(请二维码扫描下方微信)

微信:766728764
电子邮箱:m15238680799@163.com
电话:15238680799
引用本次参会学员的一句话:
发现真的是脚踏实地的同时 需要偶尔仰望星空非常感谢各位对我们培训的认可!祝愿各位心想事成
引用本次参会学员的一句话: